Recognition: unknown
Rethinking KV Cache Eviction via a Unified Information-Theoretic Objective
Pith reviewed 2026-05-07 16:37 UTC · model grok-4.3
The pith
KV cache eviction can be reframed as selecting the subset that maximizes retained predictive information under a linear-Gaussian attention model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under a linear-Gaussian surrogate of attention, the authors derive a closed-form mutual information objective that characterizes the effective information capacity of a retained KV cache subset. This formulation reveals that a wide range of existing eviction strategies can be interpreted as different approximations of the same capacity-maximization principle. Guided by this insight, they introduce CapKV, a capacity-aware eviction method that directly targets information preservation via a log-determinant approximation using statistical leverage scores.
What carries the argument
The closed-form mutual information objective derived from the linear-Gaussian attention surrogate, which serves as a unified measure of the predictive information capacity retained by any KV cache subset.
If this is right
- Existing heuristic eviction policies succeed to the extent they approximate the same information-capacity objective.
- Directly optimizing the capacity objective via leverage scores yields a selection rule that preserves more predictive signal than prior heuristics.
- The resulting method improves the memory-quality trade-off on long-context generation tasks across multiple models and benchmarks.
- Future cache-management designs can start from the capacity-maximization principle rather than trial-and-error rules.
Where Pith is reading between the lines
- If the surrogate holds, then any new eviction heuristic can be evaluated by how closely its ranking matches the mutual-information ordering.
- The same capacity view might be used to decide when to recompute rather than evict entries during very long generations.
- The leverage-score approximation could be replaced by other tractable estimators if the Gaussian assumption is relaxed in future work.
Load-bearing premise
The linear-Gaussian surrogate provides a valid model for the information-theoretic properties of attention inside actual large language models.
What would settle it
Computing the closed-form objective on real attention activations from a transformer layer and checking whether the subset it ranks highest actually produces higher next-token prediction accuracy than a lower-ranked subset on held-out continuations.
Figures


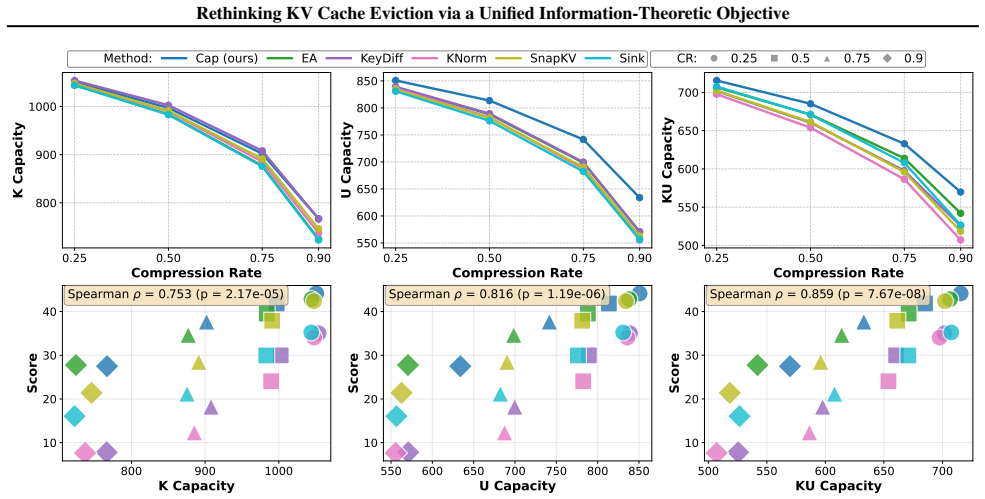



read the original abstract
Key-value (KV) caching is essential for large language model inference, yet its memory overhead poses a critical bottleneck for long-context generation. Existing eviction policies predominantly rely on empirical heuristics, lacking a rigorous theoretical foundation. This work rethinks KV cache eviction through the lens of the Information Bottleneck principle. Under a linear-Gaussian surrogate of attention, we derive a closed-form mutual information objective that characterizes the effective information capacity of a retained KV cache subset. This formulation reveals that a wide range of existing eviction strategies can be interpreted as different approximations of the same capacity-maximization principle. Guided by this insight, we introduce CapKV, a capacity-aware eviction method that directly targets information preservation via a log-determinant approximation using statistical leverage scores. This approach replaces heuristic selection with a theoretically grounded mechanism that preserves the maximum predictive signal. Extensive experiments across multiple models and long-context benchmarks show that CapKV consistently outperforms prior methods, achieving a better trade-off between memory efficiency and generational fidelity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper rethinks KV cache eviction for long-context LLM inference through the Information Bottleneck principle. Under a linear-Gaussian surrogate model of attention, it derives a closed-form mutual information objective characterizing the information capacity of retained KV subsets. This unifies a range of existing eviction heuristics as approximations to capacity maximization and motivates CapKV, a new method using log-determinant leverage scores for direct information preservation. Experiments across models and benchmarks report that CapKV improves the memory-fidelity trade-off over prior approaches.
Significance. If the linear-Gaussian surrogate is shown to preserve the relevant predictive mutual information quantities from real softmax attention, the work supplies a principled theoretical foundation for KV eviction. The unification of heuristics and the capacity-aware CapKV could replace ad-hoc policies with a reproducible, information-theoretic mechanism, with direct implications for efficient long-context generation.
major comments (2)
- [Theoretical derivation (linear-Gaussian surrogate and MI objective)] The linear-Gaussian surrogate (derivation in the main theoretical section) is load-bearing for both the closed-form MI objective and the claim that existing policies approximate capacity maximization. Real attention is query-dependent, uses softmax normalization, and exhibits heavy-tailed behavior absent from the surrogate; without explicit validation that the surrogate induces similar token-importance orderings or capacity estimates as deployed transformers, the unification and CapKV superiority rest on an untested modeling assumption rather than properties of actual LLMs.
- [Experiments and results] Table of experimental results: while CapKV is reported to outperform baselines, the paper does not report whether the surrogate parameters are estimated from data or fixed, nor does it include an ablation measuring how closely the surrogate's leverage-score ordering matches empirical attention scores on the same inputs. This gap directly affects whether the observed gains can be attributed to the information-theoretic principle.
minor comments (2)
- [Notation and equations] Notation for the mutual information objective and log-determinant approximation could be cross-referenced more explicitly to the relevant equations to improve readability.
- [Abstract] The abstract states 'extensive experiments across multiple models and long-context benchmarks' but does not name the specific models or benchmarks; adding these details would help readers assess scope.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important aspects of the surrogate model's validity and experimental reporting that we will address in the revision. Below we respond point by point to the major comments.
read point-by-point responses
-
Referee: [Theoretical derivation (linear-Gaussian surrogate and MI objective)] The linear-Gaussian surrogate (derivation in the main theoretical section) is load-bearing for both the closed-form MI objective and the claim that existing policies approximate capacity maximization. Real attention is query-dependent, uses softmax normalization, and exhibits heavy-tailed behavior absent from the surrogate; without explicit validation that the surrogate induces similar token-importance orderings or capacity estimates as deployed transformers, the unification and CapKV superiority rest on an untested modeling assumption rather than properties of actual LLMs.
Authors: We agree that the linear-Gaussian surrogate is a simplifying assumption whose fidelity to real softmax attention merits explicit checking. The unification of eviction policies and the derivation of the capacity objective are formally valid under this surrogate, as stated in the theoretical section; they do not claim to be exact for deployed transformers. To strengthen the link to practice, we will add a new subsection that compares token-importance rankings produced by the surrogate's leverage scores against empirical attention scores on representative long-context inputs from the evaluation benchmarks. This analysis will quantify the alignment (or divergence) in ordering and will be used to qualify the scope of the unification claim. revision: yes
-
Referee: [Experiments and results] Table of experimental results: while CapKV is reported to outperform baselines, the paper does not report whether the surrogate parameters are estimated from data or fixed, nor does it include an ablation measuring how closely the surrogate's leverage-score ordering matches empirical attention scores on the same inputs. This gap directly affects whether the observed gains can be attributed to the information-theoretic principle.
Authors: We will clarify in the revised experimental section that the surrogate parameters (means and covariances of the linear-Gaussian model) are fixed according to the theoretical derivation rather than estimated from data. We will also add the requested ablation: for a subset of evaluation sequences we will report the Spearman rank correlation between the surrogate leverage scores and the actual attention weights, together with the resulting performance difference when eviction is performed using the empirical attention scores instead of the surrogate scores. These additions will make the attribution of gains to the information-theoretic objective more transparent. revision: yes
Circularity Check
Derivation from IB principle under linear-Gaussian surrogate is independent
full rationale
The paper derives a closed-form mutual information objective directly from the Information Bottleneck principle applied to a linear-Gaussian surrogate model of attention. This is a first-principles theoretical step with no fitting to data or renaming of empirical patterns. Existing eviction policies are interpreted as approximations only after the derivation is complete, and CapKV is proposed from the resulting log-determinant leverage scores. No load-bearing equation reduces by construction to its inputs, and the central claim does not rely on self-citations or fitted parameters presented as predictions. Empirical results function solely as validation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Attention mechanism can be accurately approximated by a linear-Gaussian model for the purpose of information capacity calculation
Reference graph
Works this paper leans on
-
[1]
write newline
" write newline "" before.all 'output.state := FUNCTION n.dashify 't := "" t empty not t #1 #1 substring "-" = t #1 #2 substring "--" = not "--" * t #2 global.max substring 't := t #1 #1 substring "-" = "-" * t #2 global.max substring 't := while if t #1 #1 substring * t #2 global.max substring 't := if while FUNCTION format.date year duplicate empty "emp...
-
[2]
Opencodereasoning: Advancing data distillation for competitive coding
Ahmad, W. U., Narenthiran, S., Majumdar, S., Ficek, A., Jain, S., Huang, J., Noroozi, V., and Ginsburg, B. Opencodereasoning: Advancing data distillation for competitive coding. CoRR, abs/2504.01943, 2025. doi:10.48550/ARXIV.2504.01943. URL https://doi.org/10.48550/arXiv.2504.01943
-
[3]
Longbench: A bilingual, multitask benchmark for long context understanding, 2023
Bai, Y., Lv, X., Zhang, J., Lyu, H., Tang, J., Huang, Z., Du, Z., Liu, X., Zeng, A., Hou, L., Dong, Y., Tang, J., and Li, J. Longbench: A bilingual, multitask benchmark for long context understanding, 2023
2023
-
[4]
Information bottleneck for gaussian variables
Chechik, G., Globerson, A., Tishby, N., and Weiss, Y. Information bottleneck for gaussian variables. Advances in Neural Information Processing Systems, 16, 2003
2003
-
[5]
Exploring deepseek: A survey on advances, applications, challenges and future directions
Deng, Z., Ma, W., Han, Q.-L., Zhou, W., Zhu, X., Wen, S., and Xiang, Y. Exploring deepseek: A survey on advances, applications, challenges and future directions. IEEE/CAA Journal of Automatica Sinica, 12 0 (5): 0 872--893, 2025
2025
-
[6]
A simple and effective l\_2 norm-based strategy for kv cache compression
Devoto, A., Zhao, Y., Scardapane, S., and Minervini, P. A simple and effective l\_2 norm-based strategy for kv cache compression. arXiv preprint arXiv:2406.11430, 2024
-
[7]
Devoto, A., Jeblick, M., and J \'e gou, S. Expected attention: Kv cache compression by estimating attention from future queries distribution. arXiv preprint arXiv:2510.00636, 2025
- [8]
-
[9]
Forney, G. D. and Ungerboeck, G. Modulation and coding for linear gaussian channels. IEEE Transactions on Information Theory, 44 0 (6): 0 2384--2415, 2002
2002
-
[10]
W., Shao, Y
Hooper, C., Kim, S., Mohammadzadeh, H., Mahoney, M. W., Shao, Y. S., Keutzer, K., and Gholami, A. Kvquant: Towards 10 million context length llm inference with kv cache quantization. Advances in Neural Information Processing Systems, 37: 0 1270--1303, 2024
2024
-
[11]
Jiang, A. Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D. S., de Las Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L. R., Lachaux, M., Stock, P., Scao, T. L., Lavril, T., Wang, T., Lacroix, T., and Sayed, W. E. Mistral 7b. CoRR, abs/2310.06825, 2023. doi:10.48550/ARXIV.2310.06825. URL https://doi.org/10.48550/arXiv.2310.06825
-
[12]
Optimization of an alkaline peroxide interstage treatment of jack pine (pinus banksiana lamb.) using a d-optimal design
Lanouette, R., Valade, J., and Thibault, J. Optimization of an alkaline peroxide interstage treatment of jack pine (pinus banksiana lamb.) using a d-optimal design. The Canadian Journal of Chemical Engineering, 75 0 (1): 0 70--78, 1997
1997
-
[13]
arXiv preprint arXiv:2412.19442 , year =
Li, H., Li, Y., Tian, A., Tang, T., Xu, Z., Chen, X., Hu, N., Dong, W., Li, Q., and Chen, L. A survey on large language model acceleration based on kv cache management. arXiv preprint arXiv:2412.19442, 2024 a
-
[14]
Snapkv: Llm knows what you are looking for before generation
Li, Y., Huang, Y., Yang, B., Venkitesh, B., Locatelli, A., Ye, H., Cai, T., Lewis, P., and Chen, D. Snapkv: Llm knows what you are looking for before generation. Advances in Neural Information Processing Systems, 37: 0 22947--22970, 2024 b
2024
-
[15]
arXiv preprint arXiv:2412.10319 , year =
Li, Y., Jiang, H., Wu, Q., Luo, X., Ahn, S., Zhang, C., Abdi, A. H., Li, D., Gao, J., Yang, Y., and Qiu, L. Scbench: A KV cache-centric analysis of long-context methods. CoRR, abs/2412.10319, 2024 c . doi:10.48550/ARXIV.2412.10319. URL https://doi.org/10.48550/arXiv.2412.10319
-
[16]
Minicache: Kv cache compression in depth dimension for large language models
Liu, A., Liu, J., Pan, Z., He, Y., Haffari, G., and Zhuang, B. Minicache: Kv cache compression in depth dimension for large language models. Advances in Neural Information Processing Systems, 37: 0 139997--140031, 2024 a
2024
-
[17]
Liu, H., Zhang, X., Xu, H., Wanyan, Y., Wang, J., Yan, M., Zhang, J., Yuan, C., Xu, C., Hu, W., and Huang, F. Pc-agent: A hierarchical multi-agent collaboration framework for complex task automation on pc. arXiv preprint arXiv:2502.14282, 2025 a
-
[18]
Aligning cyber space with physical world: A comprehensive survey on embodied ai
Liu, Y., Chen, W., Bai, Y., Liang, X., Li, G., Gao, W., and Lin, L. Aligning cyber space with physical world: A comprehensive survey on embodied ai. IEEE/ASME Transactions on Mechatronics, 2025 b
2025
-
[19]
KIVI: A Tuning-Free Asymmetric 2bit Quantization for KV Cache
Liu, Z., Yuan, J., Jin, H., Zhong, S., Xu, Z., Braverman, V., Chen, B., and Hu, X. Kivi: A tuning-free asymmetric 2bit quantization for kv cache. arXiv preprint arXiv:2402.02750, 2024 b
work page internal anchor Pith review arXiv 2024
-
[20]
d-optimal
Mitchell, T. J. Computer construction of “d-optimal” first-order designs. Technometrics, 16 0 (2): 0 211--220, 1974
1974
-
[21]
J., Goel, R., Lee, M., and Lott, C
Park, J., Jones, D., Morse, M. J., Goel, R., Lee, M., and Lott, C. KeyDiff : Key Similarity-Based KV Cache Eviction for Long-Context LLM Inference in Resource-Constrained Environments , May 2025
2025
-
[22]
Efficiently scaling transformer inference
Pope, R., Douglas, S., Chowdhery, A., Devlin, J., Bradbury, J., Levskaya, A., Heek, J., Xiao, K., Agrawal, S., and Dean, J. Efficiently scaling transformer inference, 2022. URL https://arxiv.org/abs/2211.05102
-
[23]
G., Agullo, F., Zhu, Y., Wang, C., Lee, E
Recasens, P. G., Agullo, F., Zhu, Y., Wang, C., Lee, E. K., Tardieu, O., Torres, J., and Berral, J. L. Mind the memory gap: Unveiling gpu bottlenecks in large-batch llm inference. arXiv preprint arXiv:2503.08311, 2025
-
[24]
Sparq attention: Bandwidth-efficient LLM inference
Ribar, L., Chelombiev, I., Hudlass - Galley, L., Blake, C., Luschi, C., and Orr, D. Sparq attention: Bandwidth-efficient LLM inference. In Forty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024 . OpenReview.net, 2024. URL https://openreview.net/forum?id=OS5dqxmmtl
2024
-
[25]
R., and Stein, S
Schwartz, M., Bennett, W. R., and Stein, S. Communication systems and techniques. John Wiley & Sons, 1995
1995
-
[26]
arXiv preprint arXiv:2407.18003
Shi, L., Zhang, H., Yao, Y., Li, Z., and Zhao, H. Keep the cost down: A review on methods to optimize llm' s kv-cache consumption. CoRR, abs/2407.18003, 2024. doi:10.48550/ARXIV.2407.18003. URL https://doi.org/10.48550/arXiv.2407.18003
-
[27]
Siddiky, M. N. A., Badhon, R. H., Rahman, M. E., Salman, M., and Sohag, M. S. H. The information bottleneck method in deep learning: Principles, applications and challenges. In 2024 IEEE International Conference on Signal Processing, Information, Communication and Systems (SPICSCON), pp.\ 01--06. IEEE, 2024
2024
-
[28]
Team, L. The llama 3 herd of models. CoRR, abs/2407.21783, 2024. doi:10.48550/ARXIV.2407.21783. URL https://doi.org/10.48550/arXiv.2407.21783
work page internal anchor Pith review doi:10.48550/arxiv.2407.21783 2024
-
[29]
Team, Q. Qwen3 technical report, 2025. URL https://arxiv.org/abs/2505.09388
work page internal anchor Pith review arXiv 2025
-
[30]
Tian, Y., Wang, Z., Peng, Y., Yuan, A., Wang, Z., Yi, B., Liu, X., Cui, Y., and Yang, T. Keepkv: Eliminating output perturbation in kv cache compression for efficient llms inference. arXiv preprint arXiv:2504.09936, 2025
-
[31]
Tishby, N. and Zaslavsky, N. Deep learning and the information bottleneck principle. In 2015 IEEE Information Theory Workshop, ITW 2015, Jerusalem, Israel, April 26 - May 1, 2015 , pp.\ 1--5. IEEE , 2015. doi:10.1109/ITW.2015.7133169. URL https://doi.org/10.1109/ITW.2015.7133169
-
[32]
The information bottleneck method
Tishby, N., Pereira, F. C., and Bialek, W. The information bottleneck method. arXiv preprint physics/0004057, 2000
work page internal anchor Pith review arXiv 2000
-
[33]
and Roth, V
Wieczorek, A. and Roth, V. On the difference between the information bottleneck and the deep information bottleneck. Entropy, 22 0 (2): 0 131, 2020
2020
-
[34]
Efficient Streaming Language Models with Attention Sinks
Xiao, G., Tian, Y., Chen, B., Han, S., and Lewis, M. Efficient streaming language models with attention sinks. arXiv preprint arXiv:2309.17453, 2023
work page internal anchor Pith review arXiv 2023
-
[35]
On-device language models: A comprehensive review.arXiv preprint arXiv:2409.00088, 2024
Xu, J., Li, Z., Chen, W., Wang, Q., Gao, X., Cai, Q., and Ling, Z. On-device language models: A comprehensive review. arXiv preprint arXiv:2409.00088, 2024
-
[36]
and Math-AI, T
Zhang, Y. and Math-AI, T. American invitational mathematics examination (aime) 2025, 2025
2025
-
[37]
Cam: Cache merging for memory-efficient llms inference
Zhang, Y., Du, Y., Luo, G., Zhong, Y., Zhang, Z., Liu, S., and Ji, R. Cam: Cache merging for memory-efficient llms inference. In Forty-first international conference on machine learning, 2024
2024
-
[38]
H2o: Heavy-hitter oracle for efficient generative inference of large language models
Zhang, Z., Sheng, Y., Zhou, T., Chen, T., Zheng, L., Cai, R., Song, Z., Tian, Y., R \'e , C., Barrett, C., et al. H2o: Heavy-hitter oracle for efficient generative inference of large language models. Advances in Neural Information Processing Systems, 36: 0 34661--34710, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.