Grounding vs. Compositionality: On the Non-Complementarity of Reasoning in Neuro-Symbolic Systems
Pith reviewed 2026-05-07 11:39 UTC · model grok-4.3
The pith
Symbol grounding is necessary but not sufficient for compositional reasoning in neuro-symbolic systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
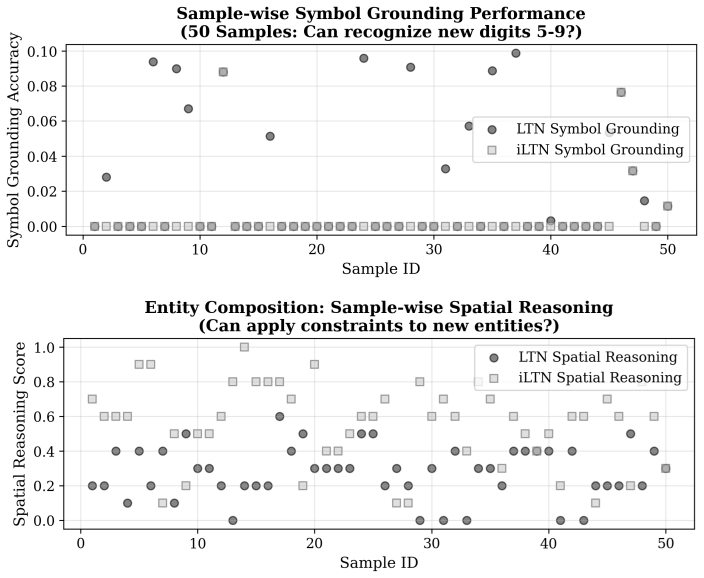
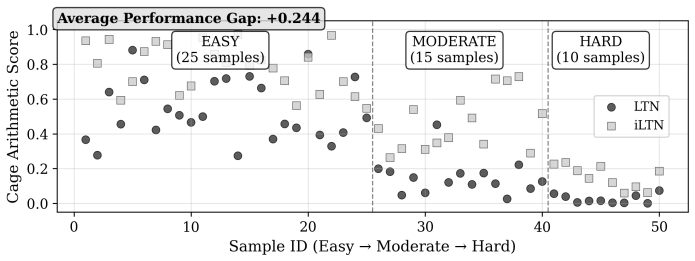
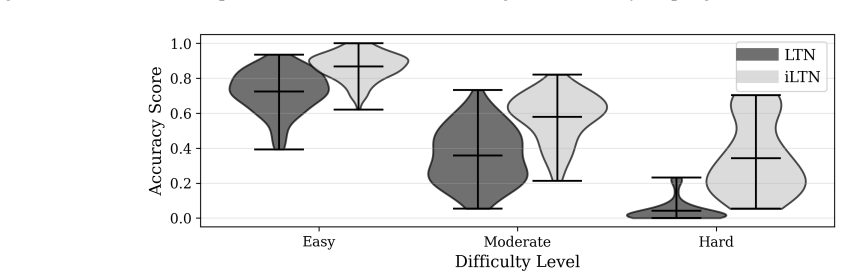
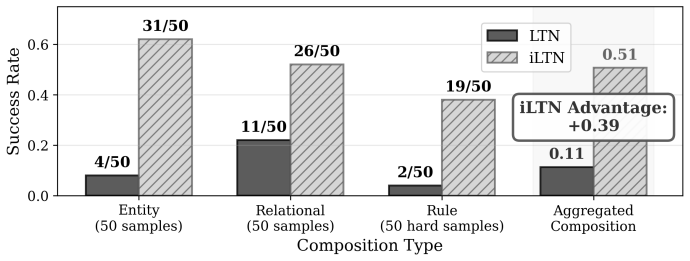
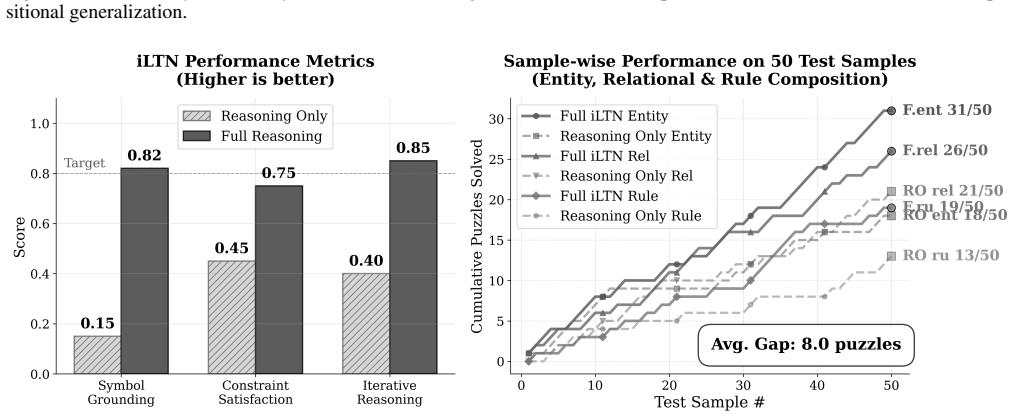
Using the iLTN architecture designed for multi-step deduction, the analysis demonstrates that models optimized solely for symbol grounding fail to generalize to novel entities, unseen relations, and complex rule compositions. The full model, trained jointly on perceptual grounding and reasoning, achieves high zero-shot accuracy on all tested generalization types. This provides evidence that symbol grounding, while necessary, is insufficient on its own for enabling compositional reasoning.
What carries the argument
The Iterative Logic Tensor Network (iLTN), a fully differentiable architecture that integrates perceptual symbol grounding with explicit multi-step logical deduction.
Load-bearing premise
The specific design of the iLTN and the taxonomy of generalization tasks are sufficient to separate the effects of grounding from those of reasoning without model-specific biases.
What would settle it
A replication experiment in which a grounding-only trained model achieves comparable zero-shot accuracy to the jointly trained model on the complex rule composition tasks would falsify the claim that grounding is insufficient.
Figures
read the original abstract
Compositional generalization remains a foundational weakness of modern neural networks, limiting their robustness and applicability in domains requiring out-of-distribution reasoning. A central, yet unverified, assumption in neuro-symbolic AI is that compositional reasoning will emerge as a byproduct of successful symbol grounding. This work presents the first systematic empirical analysis to challenge this assumption by disentangling the contributions of grounding and reasoning. To operationalize this investigation, we introduce the Iterative Logic Tensor Network ($i$LTN), a fully differentiable architecture designed for multi-step deduction. Using a formal taxonomy of generalization -- probing for novel entities, unseen relations, and complex rule compositions -- we demonstrate that a model trained solely on a grounding objective fails to generalize. In contrast, our full $i$LTN, trained jointly on perceptual grounding and multi-step reasoning, achieves high zero-shot accuracy across all tasks. Our findings provide conclusive evidence that symbol grounding, while necessary, is insufficient for generalization, establishing that reasoning is not an emergent property but a distinct capability that requires an explicit learning objective.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the Iterative Logic Tensor Network (iLTN), a fully differentiable architecture for multi-step deduction, and uses a taxonomy of generalization tasks (novel entities, unseen relations, complex rule compositions) to empirically compare a grounding-only training regime against joint training on perceptual grounding plus reasoning. It claims that grounding-only training fails to generalize while the full iLTN succeeds, providing evidence that symbol grounding is necessary but insufficient for compositional reasoning and that reasoning requires an explicit learning objective rather than emerging automatically.
Significance. If the results are robust, the work would be significant for neuro-symbolic AI by challenging the widespread assumption that successful symbol grounding will automatically yield compositional generalization. The introduction of iLTN and the formal generalization taxonomy offer concrete tools for future disentanglement studies; the empirical contrast between training regimes, if properly controlled, could shift design priorities toward explicit reasoning objectives.
major comments (2)
- [§4 (Experimental Setup) and §5 (Results)] The central experimental contrast (grounding-only vs. joint training) is load-bearing for the claim that reasoning 'is not an emergent property.' The manuscript does not specify whether the grounding-only variant applies loss only to perceptual components or still runs the full iLTN forward pass (including iterative deduction steps) with gradients blocked from the reasoning layers. If the latter, the observed generalization failure may reflect under-activation of the architecture's multi-step mechanism rather than a general insufficiency of grounding; this must be clarified with explicit training diagrams or pseudocode to support the conclusion.
- [Abstract and §5 (Results)] The abstract asserts 'conclusive evidence' and 'high zero-shot accuracy across all tasks,' yet the text supplies no quantitative details on dataset sizes, number of independent runs, statistical significance tests, or ablation controls that isolate the contribution of the iterative logic component. Without these, the claim that grounding-only 'fails to generalize' across the taxonomy cannot be evaluated for robustness.
minor comments (2)
- [Throughout] Notation for the architecture alternates between 'iLTN' and '$i$LTN'; standardize to one form for consistency.
- [§3] The formal taxonomy of generalization is introduced but not cross-referenced to specific task definitions or example instances in the main text; adding a table mapping taxonomy categories to concrete examples would improve clarity.
Simulated Author's Rebuttal
We appreciate the referee's insightful comments on our manuscript. We address each major concern below and commit to revising the paper to enhance clarity and provide supporting details.
read point-by-point responses
-
Referee: [§4 (Experimental Setup) and §5 (Results)] The central experimental contrast (grounding-only vs. joint training) is load-bearing for the claim that reasoning 'is not an emergent property.' The manuscript does not specify whether the grounding-only variant applies loss only to perceptual components or still runs the full iLTN forward pass (including iterative deduction steps) with gradients blocked from the reasoning layers. If the latter, the observed generalization failure may reflect under-activation of the architecture's multi-step mechanism rather than a general insufficiency of grounding; this must be clarified with explicit training diagrams or pseudocode to support the conclusion.
Authors: We thank the referee for this precise observation. Upon review, the manuscript indeed does not explicitly detail the training procedure for the grounding-only variant. In our experiments, the grounding-only model executes the full forward pass of iLTN but applies the loss exclusively to the perceptual grounding outputs, preventing gradient flow into the reasoning layers. This isolates the effect of grounding without training the deduction mechanism. We will add training diagrams and pseudocode to §4 in the revision to eliminate any ambiguity. revision: yes
-
Referee: [Abstract and §5 (Results)] The abstract asserts 'conclusive evidence' and 'high zero-shot accuracy across all tasks,' yet the text supplies no quantitative details on dataset sizes, number of independent runs, statistical significance tests, or ablation controls that isolate the contribution of the iterative logic component. Without these, the claim that grounding-only 'fails to generalize' across the taxonomy cannot be evaluated for robustness.
Authors: We agree that the presentation would benefit from more explicit quantitative information. The current manuscript focuses on qualitative descriptions in §5, but the underlying experiments include specific dataset configurations, multiple runs, and controls. To address this directly, we will expand the results section with tables reporting dataset sizes, run counts, standard deviations, significance tests, and ablations on the iterative logic component. We will also revise the abstract to use more measured language, such as 'empirical evidence' instead of 'conclusive evidence'. revision: yes
Circularity Check
Empirical comparison of training regimes shows no circularity
full rationale
The paper introduces the iLTN architecture and reports direct empirical measurements of generalization performance under grounding-only versus joint training objectives across a taxonomy of held-out tasks. No mathematical derivations, predictions, or first-principles claims are present that reduce to their own inputs by construction. The central finding is framed as an experimental outcome rather than a self-referential definition, fitted parameter renamed as prediction, or load-bearing self-citation chain. This is the expected non-circular result for a purely empirical neuro-symbolic study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The formal taxonomy of generalization (novel entities, unseen relations, complex rule compositions) accurately isolates compositional reasoning capabilities.
invented entities (1)
-
Iterative Logic Tensor Network (iLTN)
no independent evidence
Reference graph
Works this paper leans on
- [1]
-
[2]
Conklin, H.; Wang, B.; Smith, K.; and Titov, I
Neuro-symbolic artificial intelligence: a survey.Neu- ral Computing and Applications, 1–36. Conklin, H.; Wang, B.; Smith, K.; and Titov, I. 2021. Meta-learning to compositionally generalize.arXiv preprint arXiv:2106.04252. Ellis, K.; Ritchie, D.; Solar-Lezama, A.; and Tenenbaum, J
-
[3]
Learning to infer graphics programs from hand-drawn images.Advances in neural information processing systems, 31. Feldstein, J.; Dilkas, P.; Belle, V .; and Tsamoura, E. 2024. Mapping the Neuro-Symbolic AI Landscape by Architec- tures: A Handbook on Augmenting Deep Learning Through Symbolic Reasoning.arXiv preprint arXiv:2410.22077. Fodor, J. A.; and Pyly...
-
[4]
Softened symbol grounding for neuro-symbolic sys- tems.arXiv preprint arXiv:2403.00323. Lightman, H.; Kosaraju, V .; Burda, Y .; Edwards, H.; Baker, B.; Lee, T.; Leike, J.; Schulman, J.; Sutskever, I.; and Cobbe, K. 2023. Let’s verify step by step. InThe Twelfth Interna- tional Conference on Learning Representations. Lin, B.; Bouneffouf, D.; and Rish, I. ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.