Human-in-the-Loop Benchmarking of Heterogeneous LLMs for Automated Competency Assessment in Secondary Level Mathematics
Pith reviewed 2026-05-07 13:19 UTC · model grok-4.3
The pith
Mixture-of-experts LLMs reach fair agreement with human graders on secondary math competencies while a 70B model shows none
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
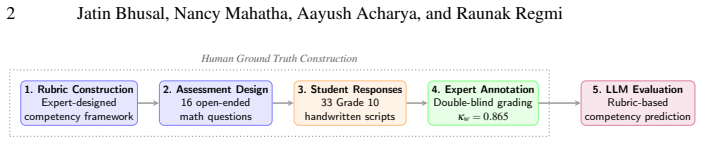
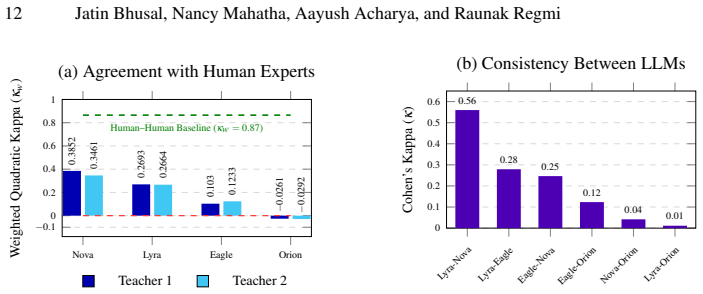
Gemini-based Mixture-of-Experts models achieved fair agreement (weighted kappa approximately 0.38) with senior faculty ground truth on a rubric covering four topics and four competencies, whereas the larger Orion 70B model achieved no agreement (weighted kappa of -0.0261), indicating that architectural compliance with assessment instructions outweighs model scale in constrained educational evaluation tasks.
What carries the argument
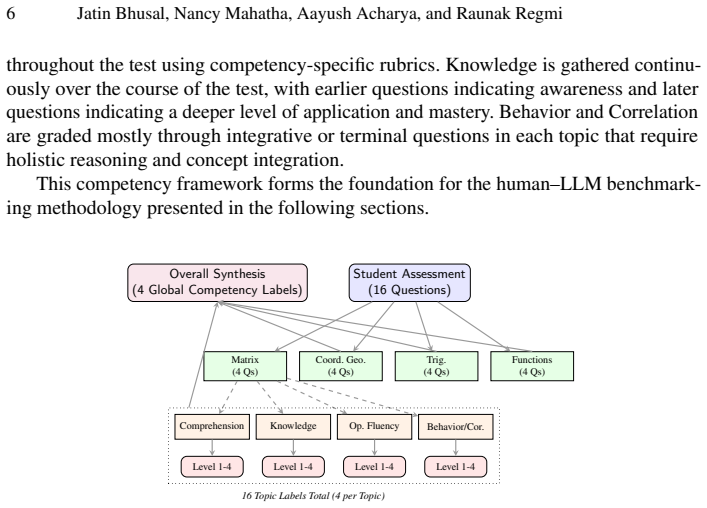
The multi-dimensional rubric for four curriculum topics and four cross-cutting competencies (Comprehension, Knowledge, Operational Fluency, Behavior and Correlation) applied inside a human-in-the-loop benchmarking setup that compares heterogeneous LLMs against faculty consensus ground truth.
If this is right
- LLMs can accelerate preliminary evidence extraction from student work but cannot yet support autonomous competency certification.
- Instruction-following architecture is a stronger predictor of success on rubric tasks than parameter count alone.
- The high faculty inter-rater reliability of 0.8652 confirms the rubric as a stable benchmark for future model testing.
- Mixed ensembles of open-weight and proprietary models can be practically deployed for assistive grading support.
Where Pith is reading between the lines
- Future LLM training for education applications could emphasize constraint adherence over continued scaling.
- Comparable benchmarks in other subjects or countries could identify which architectures suit specific assessment styles.
- Widespread adoption of such assistive systems might lower barriers to implementing competency-based education where teacher time is limited.
Load-bearing premise
The two senior faculty assessments form a reliable ground truth and that performance gaps between models are caused by architectural differences rather than unstated variations in prompting or configuration.
What would settle it
Repeating the full benchmark under identical prompts, temperature settings, and adaptation procedures for every model and finding that the 70B model then reaches fair or higher agreement with the faculty raters.
Figures
read the original abstract
As Competency-Based Education (CBE) is gaining traction around the world, the shift from marks-based assessment to qualitative competency mapping is a manual challenge for educators. This paper tackles the bottleneck issue by suggesting a "Human-in-the-Loop" benchmarking framework to assess the effectiveness of multiple LLMs in automating secondary-level mathematics assessment. Based on the Grade 10 Optional Mathematics curriculum in Nepal, we created a multi-dimensional rubric for four topics and four cross-cutting competencies: Comprehension, Knowledge, Operational Fluency, and Behavior and Correlation. The multi-provider ensemble, consisted of open-weight models -- Eagle (Llama 3.1-8B) and Orion (Llama 3.3-70B) -- and proprietary frontier models Nova (Gemini 2.5 Flash) and Lyra (Gemini 3 Pro), was benchmarked against a ground truth defined by two senior mathematics faculty members (kappa_w = 0.8652). The findings show a marked "Architecture-compatibility gap". Although the Gemini-based Mixture-of-Experts (Sparse MoE) models achieved "Fair Agreement" (kappa_w ~ 0.38), the larger Orion (70B) model exhibited "No Agreement" (kappa_w = -0.0261), suggesting that architectural compliance with instruction constraints outweighs the scale of raw parameters in rubric-constrained tasks. We conclude that while LLMs are not yet suitable for autonomous certification, they provide high-value assistive support for preliminary evidence extraction within a "Human-in-the-Loop" framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. This paper presents a human-in-the-loop benchmarking framework for assessing the performance of heterogeneous LLMs in automating competency-based evaluation of secondary-level mathematics. Using a rubric derived from Nepal's Grade 10 Optional Mathematics curriculum that evaluates four topics across competencies of Comprehension, Knowledge, Operational Fluency, and Behavior and Correlation, the authors compare open-weight models (Eagle 8B, Orion 70B) and Gemini-based models (Nova, Lyra) against ratings from two senior faculty members (inter-rater kappa_w = 0.8652). Key findings include fair agreement for the Gemini MoE models (kappa_w ~ 0.38) contrasted with no agreement for the larger Orion model (kappa_w = -0.0261), supporting the claim of an 'Architecture-compatibility gap' where model architecture influences rubric adherence more than parameter count. The authors conclude that LLMs offer value in assistive roles within human-in-the-loop systems but are not ready for autonomous certification.
Significance. Should the results prove robust to controls for prompting and hyperparameter standardization, the work offers a timely contribution to AI applications in education by demonstrating that larger models do not necessarily excel in structured, constraint-heavy tasks like rubric-based assessment. The explicit use of weighted kappa against human ground truth provides a transparent and falsifiable basis for comparison, and the human-in-the-loop emphasis aligns with practical deployment realities in competency-based education. This could inform both model developers and educators on the selection of LLMs for assessment support, particularly highlighting potential advantages of certain architectures like sparse MoE in following complex instructions.
major comments (2)
- [Methods] The experimental protocol does not specify whether a single shared prompt template, output format, temperature, and sampling parameters were applied uniformly to all models (Eagle, Orion, Nova, Lyra). Absent a verbatim prompt example or per-model configuration table, the causal link between the observed kappa_w gap (Gemini MoE ~0.38 vs. Orion -0.0261) and architectural differences cannot be isolated from possible implementation variations, which directly undermines the central 'Architecture-compatibility gap' conclusion.
- [Evaluation and Results] While the ground-truth kappa_w of 0.8652 between the two faculty raters is reported, the manuscript provides no details on the total number of student responses assessed, the sampling method, or any measures of rater consistency beyond the single kappa value. This makes it challenging to evaluate the statistical power and reliability of the model comparisons.
minor comments (2)
- [Abstract] The phrasing 'The multi-provider ensemble, consisted of' is grammatically incorrect and should be revised to 'The multi-provider ensemble consisted of' or 'consisting of' for improved readability.
- [Throughout] The term 'kappa_w' should be explicitly defined as weighted Cohen's kappa upon first mention to aid readers unfamiliar with the metric.
Simulated Author's Rebuttal
We are grateful to the referee for their insightful comments, which will help improve the clarity and robustness of our paper. We address the major comments below and will make the necessary revisions to the manuscript.
read point-by-point responses
-
Referee: [Methods] The experimental protocol does not specify whether a single shared prompt template, output format, temperature, and sampling parameters were applied uniformly to all models (Eagle, Orion, Nova, Lyra). Absent a verbatim prompt example or per-model configuration table, the causal link between the observed kappa_w gap (Gemini MoE ~0.38 vs. Orion -0.0261) and architectural differences cannot be isolated from possible implementation variations, which directly undermines the central 'Architecture-compatibility gap' conclusion.
Authors: We confirm that a single shared prompt template, consistent output format, and standardized parameters including temperature and sampling were applied uniformly across all models to ensure fair comparison and isolate architectural effects. The observed differences are thus attributable to model architecture rather than implementation variations. We will add a verbatim example of the prompt template and a table detailing the configuration for each model in the revised Methods section. revision: yes
-
Referee: [Evaluation and Results] While the ground-truth kappa_w of 0.8652 between the two faculty raters is reported, the manuscript provides no details on the total number of student responses assessed, the sampling method, or any measures of rater consistency beyond the single kappa value. This makes it challenging to evaluate the statistical power and reliability of the model comparisons.
Authors: We acknowledge the need for greater transparency in the evaluation details. We will revise the manuscript to include the total number of student responses assessed, a description of the sampling method, and additional measures of rater consistency beyond the single kappa value. This will allow readers to better evaluate the statistical power and reliability of the comparisons. revision: yes
Circularity Check
No circularity: empirical benchmarking against external human ground truth
full rationale
The paper performs an empirical comparison of LLM outputs to independent senior faculty ratings on a fixed rubric, computing weighted kappa agreement (human-human kappa_w = 0.8652). No equations, fitted parameters, self-citations, or ansatzes are invoked that reduce any claim to quantities defined by the paper's own inputs or prior author work. The architecture-vs-scale interpretation is an observational inference from the external benchmark results rather than a self-referential derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Weighted Cohen's kappa is an appropriate and sufficient measure for quantifying agreement between LLM-generated rubric scores and human expert scores on ordinal competency scales.
invented entities (1)
-
Architecture-compatibility gap
no independent evidence
Reference graph
Works this paper leans on
-
[1]
In: Understanding adult education and training, pp
Chappell, C., Gonczi, A., Hager, P.: Competency-based education. In: Understanding adult education and training, pp. 191–205. Routledge (2020)
work page 2020
-
[2]
Curriculum Development Centre: Optional Mathematics Grade 10. Ministry of Education, Science and Technology, Government of Nepal, Sanothimi, Bhaktapur, Nepal (2019)
work page 2019
-
[3]
Do, S.T., To, C.L., Huynh, Q.K.V ., Huynh, D.T., Nguyen, S.T.T., Le, P.T.L.: Trends and applications of artificial intelligence in competency-based education in medical programs: A scoping review. MedPharmRes (2025)
work page 2025
-
[4]
Journal of Midwifery & Women’s Health70(6), 865–881 (2025)
Faucher, M.A., Sing, E., Harris, S., Hutson, E., Hoelscher, S.H.: Artificial intelligence and competency-based education: A rapid scoping review. Journal of Midwifery & Women’s Health70(6), 865–881 (2025)
work page 2025
-
[5]
Computers in Human Behavior Reports14, 100412 (2024)
Fundi, M., Sanusi, I.T., Oyelere, S.S., Ayere, M.: Advancing AI education: Assessing kenyan in-service teachers’ preparedness for integrating artificial intelligence in competence-based curriculum. Computers in Human Behavior Reports14, 100412 (2024)
work page 2024
-
[6]
Sustainability17(13), 6098 (2025)
Hochstetter-Diez, J., Negrier-Seguel, M., Diéguez-Rebolledo, M., Candia-Garrido, E., Vidal, E.: From mapping to action: SmartRubrics, an AI tool for competency-based assessment in engineering education. Sustainability17(13), 6098 (2025)
work page 2025
-
[7]
Artificial Intelligence Education Studies1(3), 14–27 (2025)
Huang, X.: Designing human-AI orchestrated classrooms: Mechanisms, protocols, and gover- nance for competency-based education. Artificial Intelligence Education Studies1(3), 14–27 (2025)
work page 2025
-
[8]
Department for International Development (DFID) (2006)
Leach, J., Ahmed, A., Makalima, S., Power, T.: Deep impact: An investigation of the use of information and communication technologies for teacher education in the global south: Researching the issues. Department for International Development (DFID) (2006)
work page 2006
-
[9]
World Journal of Engineering and Technology4(3), 193–199 (2016)
Hernández-de Menéndez, M., Morales-Menendez, R.: Competency based education – current global practices. World Journal of Engineering and Technology4(3), 193–199 (2016)
work page 2016
-
[10]
Higher Education Studies15(4), 333–353 (2025)
Nammanee, M., Jantakoon, T., Laoha, R.: AI assistant framework on competency-based learning for digital competency development. Higher Education Studies15(4), 333–353 (2025)
work page 2025
-
[11]
EURASIA Journal of Mathematics, Science and Technology Education19(8), em2307 (2023)
Owan, V .J., Abang, K.B., Idika, D.O., Etta, E.O., Bassey, B.A.: Exploring the potential of artificial intelligence tools in educational measurement and assessment. EURASIA Journal of Mathematics, Science and Technology Education19(8), em2307 (2023)
work page 2023
-
[12]
Amfiteatru Economic26(65), 220–240 (2024)
Radu, C., Ciocoiu, C.N., Veith, C., C˘at˘alin, R.: Artificial intelligence and competency-based education: A bibliometric analysis. Amfiteatru Economic26(65), 220–240 (2024)
work page 2024
-
[13]
In: 2023 7th International Conference on Information Technology (InCIT)
Wangwiwattana, C., Tongvivat, Y .: Automating academic assessment: a large language model approach. In: 2023 7th International Conference on Information Technology (InCIT). pp. 330–334. IEEE (2023)
work page 2023
-
[14]
In: 2024 13th International Conference on Computer Technologies and Development (TechDev)
Xu, Q., Gu, J., Lu, J.: Leveraging artificial intelligence and large language models for enhanced teaching and learning: A systematic literature review. In: 2024 13th International Conference on Computer Technologies and Development (TechDev). pp. 73–77. IEEE (2024)
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.