Recognition: unknown
Beyond the Training Distribution: Mapping Generalization Boundaries in Neural Program Synthesis
Pith reviewed 2026-05-07 08:18 UTC · model grok-4.3
The pith
Diverse sampling over syntactic and semantic spaces enables robust out-of-distribution generalization in program synthesis, while transformers show over 30 percent performance drop on syntactically novel programs and only log-linear gains,
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
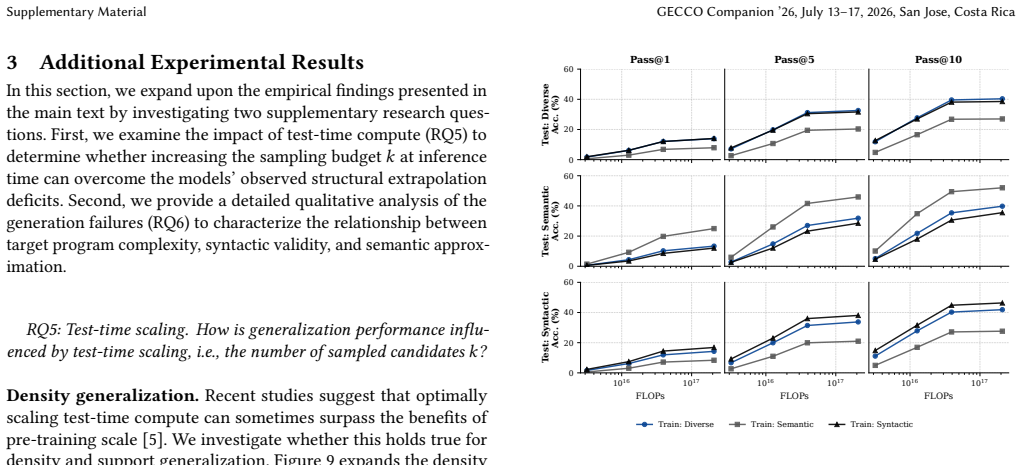
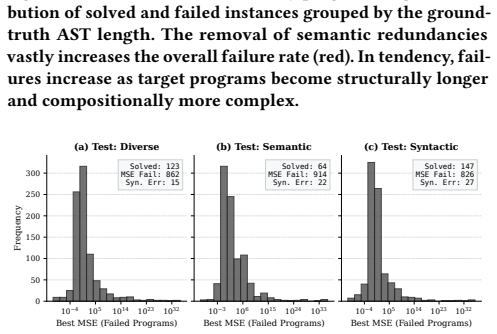
By systematically enumerating programs from the arithmetic grammar and mapping them in syntactic and semantic metric spaces, the authors isolate density generalization (diverse sampling within observed manifolds) from support generalization (extrapolation beyond observed syntactic structures). Density optimization yields robust out-of-distribution performance, while support evaluation reveals transformers lose more than 30 percent accuracy on syntactically novel programs. Compute scaling improves generalization along a strictly log-linear curve, leading to the conclusion that robust generalization requires training diversity across multiple manifolds and that current scaling will not suffice
What carries the argument
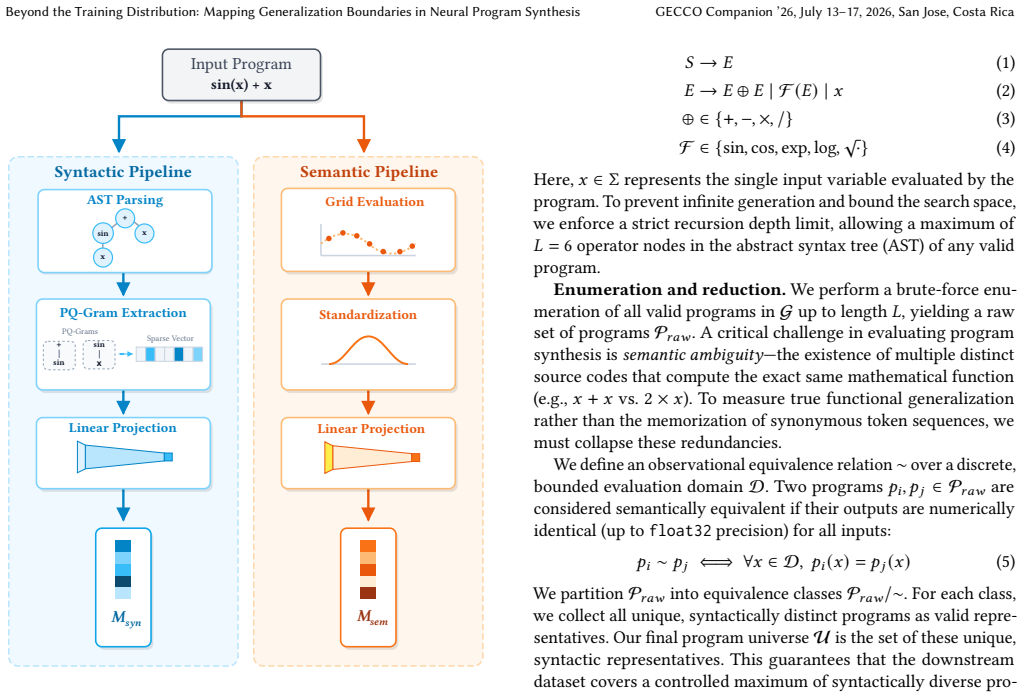
Syntactic and semantic metric spaces derived from the domain-specific arithmetic grammar, used to enumerate programs and sample controlled train-test splits that separate specific distributional shifts
If this is right
- Diverse sampling across both semantic and syntactic spaces produces robust out-of-distribution generalization.
- Transformers experience a performance drop exceeding 30 percent when required to generate syntactically novel programs.
- Increasing compute yields steady but strictly log-linear improvements in generalization.
- Robust generalization demands maximizing training diversity across multiple manifolds rather than relying on scale alone.
Where Pith is reading between the lines
- If the grammar-based metric spaces capture essential structure, then real program synthesis systems will likewise need explicit diversity mechanisms to avoid template retrieval.
- The observed log-linear scaling implies that purely transformer-based synthesis will hit a ceiling unless combined with search or enumeration methods that can reach outside the training manifold.
- The same controlled-mapping approach could be applied to other code-generation domains to locate their own density-versus-support boundaries.
Load-bearing premise
The domain-specific arithmetic grammar and the metric spaces built from it are representative of the generalization problems that appear in real-world program synthesis tasks.
What would settle it
Train a model with the most diverse sampling the grammar allows and then test it on programs that introduce syntactic forms or semantic combinations never present in the grammar or its metric spaces; if accuracy remains high the central claim holds, otherwise the claim is falsified.
Figures



















read the original abstract
Large-scale transformers achieve impressive results on program synthesis benchmarks, yet their true generalization capabilities remain obscured by data contamination and opaque training corpora. To rigorously assess whether models are truly generalizing or merely retrieving memorized templates, we introduce a strictly controlled program synthesis environment based on a domain-specific arithmetic grammar. By systematically enumerating and evaluating millions of unique programs, we construct interpretable syntactic and semantic metric spaces. This allows us to precisely map data distributions and sample train and test splits that isolate specific distributional shifts. Our experiments demonstrate that optimizing density generalization -- through diverse sampling over both semantic and syntactic spaces -- induces robust out-of-distribution generalization. Conversely, evaluating support generalization reveals that transformers severely struggle with extrapolation, experiencing a performance drop of over 30% when forced to generate syntactically novel programs. While steadily scaling up compute improves generalization, the gains follow a strictly log-linear relationship. We conclude that robust generalization requires maximizing training diversity across multiple manifolds, and our findings indicate the necessity for novel search-based approaches to break through current log-linear scaling bottlenecks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a strictly controlled program synthesis environment based on a domain-specific arithmetic grammar. By enumerating millions of unique programs, the authors construct interpretable syntactic and semantic metric spaces to define train/test splits that isolate specific distributional shifts. Experiments show that diverse sampling over both semantic and syntactic spaces (density generalization) yields robust out-of-distribution performance, whereas support generalization—requiring extrapolation to syntactically novel programs—produces performance drops exceeding 30%. Compute scaling improves results but follows a strictly log-linear relationship. The authors conclude that robust generalization requires maximizing training diversity across multiple manifolds and that search-based methods are needed to overcome current scaling bottlenecks.
Significance. If the empirical findings hold under the reported controls, the work offers a reproducible, interpretable benchmark for dissecting generalization boundaries in neural program synthesis, moving beyond contaminated real-world benchmarks. The explicit enumeration of millions of programs and construction of metric spaces constitute a clear methodological strength, enabling precise isolation of density versus support shifts. The log-linear scaling observation, if replicated, would provide a concrete quantitative target for future architectural or algorithmic interventions. However, the restricted arithmetic grammar (lacking variables, control flow, or side effects) limits the external validity of the broader claims about program synthesis in general.
major comments (3)
- [§4] §4 (Experiments): The reported >30% performance drop for support generalization is presented without error bars, multiple random seeds, or statistical significance tests. Given the stochastic training of transformers and the dependence on specific split constructions, this omission makes it impossible to assess whether the drop is robust or sensitive to implementation details.
- [§3.1] §3.1 (Metric Spaces and Split Construction): The paper states that millions of programs were enumerated to build syntactic and semantic metric spaces, yet provides no pseudocode, complexity analysis, or exact procedure for generating the train/test splits that isolate density versus support generalization. These details are load-bearing for reproducing the central empirical claims.
- [§5] §5 (Discussion and Conclusions): The claim that 'novel search-based approaches' are necessary to break log-linear scaling is extrapolated from results on a narrow arithmetic grammar. No ablation or comparison is provided on whether the same scaling law persists in grammars that include variables or control flow, which directly affects the generality of the recommendation.
minor comments (2)
- [§2] The definition of 'density generalization' versus 'support generalization' is introduced in the abstract and §2 but would benefit from an explicit mathematical formulation (e.g., a set-theoretic or distributional notation) to avoid ambiguity when readers attempt to replicate the splits.
- Model architecture details (number of layers, hidden size, attention heads, training hyperparameters) are referenced only at a high level; a table summarizing the exact configurations used for each scaling experiment would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, indicating where revisions will be made to improve clarity, reproducibility, and scoping of claims.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The reported >30% performance drop for support generalization is presented without error bars, multiple random seeds, or statistical significance tests. Given the stochastic training of transformers and the dependence on specific split constructions, this omission makes it impossible to assess whether the drop is robust or sensitive to implementation details.
Authors: We agree that the absence of error bars and multi-seed statistics limits assessment of robustness. In the revised version we will rerun the support-generalization experiments across five independent random seeds, report means with standard deviations as error bars, and include paired t-test p-values comparing density versus support conditions to establish statistical significance of the performance drop. revision: yes
-
Referee: [§3.1] §3.1 (Metric Spaces and Split Construction): The paper states that millions of programs were enumerated to build syntactic and semantic metric spaces, yet provides no pseudocode, complexity analysis, or exact procedure for generating the train/test splits that isolate density versus support generalization. These details are load-bearing for reproducing the central empirical claims.
Authors: We accept that additional implementation details are required for reproducibility. The revised manuscript will include (i) pseudocode for the enumeration routine, (ii) a complexity analysis showing linear scaling in program depth, and (iii) a precise algorithmic description of how syntactic and semantic distances are used to construct the density and support splits. These will appear in Section 3.1 and a new appendix. revision: yes
-
Referee: [§5] §5 (Discussion and Conclusions): The claim that 'novel search-based approaches' are necessary to break log-linear scaling is extrapolated from results on a narrow arithmetic grammar. No ablation or comparison is provided on whether the same scaling law persists in grammars that include variables or control flow, which directly affects the generality of the recommendation.
Authors: The paper deliberately restricts the grammar to arithmetic expressions to isolate density versus support shifts under full enumeration and interpretable metrics; extending the grammar would introduce new confounding factors and require substantial additional compute. We will revise the discussion to explicitly scope the log-linear scaling observation and the call for search-based methods to the arithmetic setting studied, while noting richer grammars as an important direction for future work. No new ablations will be added. revision: partial
Circularity Check
No circularity: purely empirical measurements in a constructed testbed
full rationale
The paper introduces a controlled arithmetic grammar, enumerates millions of programs, builds syntactic/semantic metric spaces, and samples train/test splits to measure transformer performance under density vs. support generalization shifts. All central claims (robust OOD from diverse sampling, >30% drop on syntactic extrapolation, log-linear scaling) are direct experimental outcomes from running models on these splits. No equations, derivations, fitted parameters renamed as predictions, or self-citations are invoked to justify the results; the metric spaces and splits are defined once from the grammar and then used for independent evaluation. This is self-contained empirical work with no reduction of outputs to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The domain-specific arithmetic grammar and the syntactic/semantic metric spaces derived from it constitute a representative model of the distributional shifts that matter for program synthesis generalization.
Reference graph
Works this paper leans on
-
[1]
Mark Chen. 2021. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374(2021)
work page internal anchor Pith review arXiv 2021
-
[2]
Nouha Dziri, Ximing Lu, Melanie Sclar, Xiang Lorraine Li, Liwei Jiang, Bill Yuchen Lin, Sean Welleck, Peter West, Chandra Bhagavatula, Ronan Le Bras, et al. 2023. Faith and fate: Limits of transformers on compositionality.Advances in neural information processing systems36 (2023), 70293–70332
2023
-
[3]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023. Visual in- struction tuning.Advances in neural information processing systems36 (2023), 34892–34916
2023
-
[4]
Smith, Mateusz Paprocki, Ondřej Čertík, Sergey B
Aaron Meurer, Christopher P. Smith, Mateusz Paprocki, Ondřej Čertík, Sergey B. Kirpichev, Matthew Rocklin, AMiT Kumar, Sergiu Ivanov, Jason K. Moore, Sar- taj Singh, Thilina Rathnayake, Sean Vig, Brian E. Granger, Richard P. Muller, Francesco Bonazzi, Harsh Gupta, Shivam Vats, Fredrik Johansson, Fabian Pe- dregosa, Matthew J. Curry, Andy R. Terrel, Štěpán...
2017
-
[5]
Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. 2024. Scaling llm test- time compute optimally can be more effective than scaling model parameters. arXiv preprint arXiv:2408.03314(2024)
work page internal anchor Pith review arXiv 2024
-
[6]
Kaizhong Zhang and Dennis Shasha. 1989. Simple fast algorithms for the editing distance between trees and related problems.SIAM J. Comput.18, 6 (1989), 1245– 1262
1989
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.