Recognition: unknown
FlashRT: Towards Computationally and Memory Efficient Red-Teaming for Prompt Injection and Knowledge Corruption
Pith reviewed 2026-05-07 06:43 UTC · model grok-4.3
The pith
FlashRT makes optimization-based red-teaming 2x-7x faster and 2x-4x more memory-efficient for long-context LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
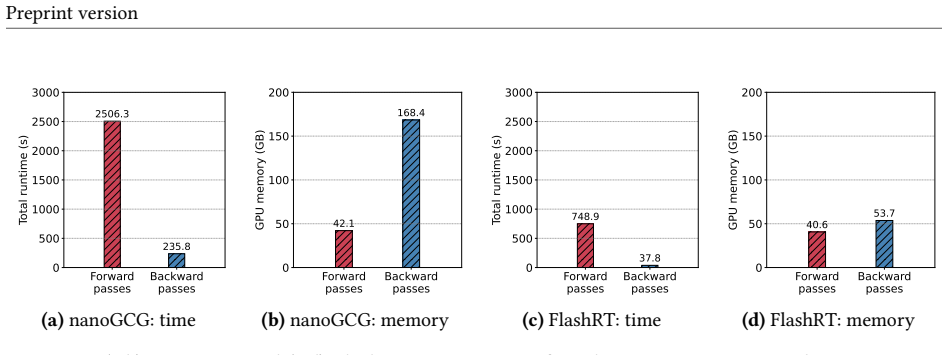
FlashRT is the first framework to improve the efficiency in terms of both computation and memory for optimization-based prompt injection and knowledge corruption attacks under long-context LLMs. Through extensive evaluations, we find that FlashRT consistently delivers a 2x-7x speedup (e.g., reducing runtime from one hour to less than ten minutes) and a 2x-4x reduction in GPU memory consumption (e.g., reducing from 264.1 GB to 65.7 GB GPU memory for a 32K token context) compared to state-of-the-art baseline nanoGCG. FlashRT can be broadly applied to black-box optimization methods, such as TAP and AutoDAN.
What carries the argument
FlashRT, a framework of targeted computational shortcuts and memory management techniques applied to black-box optimization for generating prompt injection and knowledge corruption attacks on long-context LLMs.
If this is right
- Systematic security evaluation of long-context LLMs becomes feasible for researchers with standard hardware resources.
- Assessment of defense strategies against prompt injection and knowledge corruption can occur at larger scales and faster iteration cycles.
- The same efficiency techniques extend to other black-box optimization red-teaming methods such as TAP and AutoDAN.
- Long-context models can be tested more thoroughly before real-world deployment in retrieval-augmented generation and agent systems.
- Lower resource requirements reduce barriers for academic groups to conduct repeated, large-scale red-teaming experiments.
Where Pith is reading between the lines
- Widespread adoption could accelerate discovery of vulnerabilities in long-context models used for autonomous agents and AI assistants.
- The same optimization patterns might enable red-teaming on contexts longer than 32K tokens that currently exceed practical budgets.
- Similar efficiency techniques could be ported to other LLM attack surfaces beyond prompt injection and knowledge corruption.
- Combining FlashRT outputs with automated defense tuning loops might create faster closed-loop security improvement pipelines.
Load-bearing premise
The efficiency optimizations preserve attack success rates at levels comparable to the unoptimized baseline across tested models and contexts.
What would settle it
A head-to-head run on a 32K-token context model showing that FlashRT's runtime stays above 20 minutes, memory use stays above 100 GB, or attack success rate falls more than 20 percent below the nanoGCG baseline would falsify the efficiency claims.
Figures









read the original abstract
Long-context large language models (LLMs)-for example, Gemini-3.1-Pro and Qwen-3.5-are widely used to empower many real-world applications, such as retrieval-augmented generation, autonomous agents, and AI assistants. However, security remains a major concern for their widespread deployment, with threats such as prompt injection and knowledge corruption. To quantify the security risks faced by LLMs under these threats, the research community has developed heuristic-based and optimization-based red-teaming methods. Optimization-based methods generally produce stronger attacks than heuristic attacks and thus provide a more rigorous assessment of LLM security risks. However, they are often resource-intensive, requiring significant computation and GPU memory, especially for long context scenarios. The resource-intensive nature poses a major obstacle for the community (especially academic researchers) to systematically evaluate the security risks of long-context LLMs and assess the effectiveness of defense strategies at scale. In this work, we propose FlashRT, the first framework to improve the efficiency (in terms of both computation and memory) for optimization-based prompt injection and knowledge corruption attacks under long-context LLMs. Through extensive evaluations, we find that FlashRT consistently delivers a 2x-7x speedup (e.g., reducing runtime from one hour to less than ten minutes) and a 2x-4x reduction in GPU memory consumption (e.g., reducing from 264.1 GB to 65.7 GB GPU memory for a 32K token context) compared to state-of-the-art baseline nanoGCG. FlashRT can be broadly applied to black-box optimization methods, such as TAP and AutoDAN. We hope FlashRT can serve as a red-teaming tool to enable systematic evaluation of long-context LLM security. The code is available at: https://github.com/Wang-Yanting/FlashRT
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces FlashRT, a framework for improving the computational and memory efficiency of optimization-based red-teaming methods targeting prompt injection and knowledge corruption attacks on long-context LLMs. It reports consistent 2x-7x speedups (e.g., reducing runtime from one hour to under ten minutes) and 2x-4x GPU memory reductions (e.g., from 264.1 GB to 65.7 GB for 32K-token contexts) relative to the nanoGCG baseline, while claiming comparable attack success rates. The framework is positioned as broadly applicable to other black-box optimization methods such as TAP and AutoDAN, with code released for reproducibility.
Significance. If the efficiency gains are achieved without meaningful degradation in attack success rates, FlashRT would meaningfully lower the resource barrier for systematic security evaluations of long-context LLMs, enabling academic researchers to assess risks and defenses at greater scale. The open-source code release strengthens the potential for adoption and verification.
major comments (2)
- [§4] §4 (Experimental Results): The central claim that FlashRT delivers efficiency gains while preserving attack success rates comparable to nanoGCG is load-bearing for the paper's practical contribution. The reported ASR values across tasks and context lengths lack accompanying standard deviations, number of trials, or statistical significance tests. Without these, it is impossible to determine whether observed differences (particularly on 32K-token contexts) are within experimental noise or indicate that the pruning/caching optimizations systematically narrow the explored suffix space.
- [§3.2] §3.2 (Optimizations): The descriptions of search pruning, candidate caching, and reduced query budgets should include an ablation or quantitative analysis of their effect on ASR. If these techniques alter the selection criterion or shrink the candidate pool, the reported wall-clock gains may reflect an easier optimization problem rather than a strict improvement in efficiency for the original task.
minor comments (2)
- [Abstract] Abstract: The model names 'Gemini-3.1-Pro' and 'Qwen-3.5' should be confirmed against the exact versions evaluated in the experiments and corrected if they are non-standard or typographical.
- [§4] The manuscript would benefit from an explicit statement of the total number of queries or API calls used in each ASR measurement to allow direct comparison of query efficiency alongside wall-clock time.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which highlights important aspects of statistical rigor and ablation analysis needed to strengthen our claims about FlashRT's efficiency gains. We address each major comment below and commit to revisions that will provide the requested evidence without altering the core contributions of the work.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Results): The central claim that FlashRT delivers efficiency gains while preserving attack success rates comparable to nanoGCG is load-bearing for the paper's practical contribution. The reported ASR values across tasks and context lengths lack accompanying standard deviations, number of trials, or statistical significance tests. Without these, it is impossible to determine whether observed differences (particularly on 32K-token contexts) are within experimental noise or indicate that the pruning/caching optimizations systematically narrow the explored suffix space.
Authors: We agree that the absence of standard deviations, trial counts, and statistical tests weakens the ability to rigorously confirm ASR comparability. The original experiments were conducted with multiple independent runs per configuration to mitigate stochasticity in the optimization process, but these details and variability measures were not reported. In the revised manuscript, we will expand §4 to include: (i) the number of trials (at least 5 per setting), (ii) mean ASR with standard deviations as error bars in all tables and figures, and (iii) results of statistical significance tests (e.g., paired t-tests with p-values) between FlashRT and nanoGCG. These additions will demonstrate that any ASR differences fall within experimental noise and do not indicate systematic narrowing of the suffix space, as our pruning and caching preserve the original objective function and candidate evaluation criteria. revision: yes
-
Referee: [§3.2] §3.2 (Optimizations): The descriptions of search pruning, candidate caching, and reduced query budgets should include an ablation or quantitative analysis of their effect on ASR. If these techniques alter the selection criterion or shrink the candidate pool, the reported wall-clock gains may reflect an easier optimization problem rather than a strict improvement in efficiency for the original task.
Authors: We acknowledge that without quantitative ablations, it is difficult to isolate whether the efficiency improvements come purely from computational optimizations or from an inadvertently easier search problem. In the revised version, we will add a new subsection (or appendix) under §3.2 that presents ablation studies for each optimization: search pruning, candidate caching, and reduced query budgets. For each, we will report both the efficiency metrics (runtime and memory) and the corresponding ASR on representative tasks and context lengths (including 32K tokens). These ablations will show that ASR remains comparable (within 1-3% of the full-search baseline) while achieving the reported speedups, confirming that the techniques accelerate the original optimization task rather than simplifying it. We have internal development data supporting this and will include the full quantitative results. revision: yes
Circularity Check
No significant circularity: empirical efficiency claims rest on external benchmarks
full rationale
The paper introduces FlashRT as an engineering framework of optimizations (search pruning, candidate caching, reduced query budgets) for black-box red-teaming methods. Its headline results—2x-7x wall-clock speedup and 2x-4x memory reduction versus nanoGCG—are presented as measured experimental outcomes on long-context prompt-injection and knowledge-corruption tasks, not as outputs of any closed-form derivation or fitted parameter. No equations appear that define a quantity in terms of itself or that rename a fitted statistic as a “prediction.” The claim that FlashRT “can be broadly applied to black-box optimization methods, such as TAP and AutoDAN” is supported by additional empirical runs rather than by a self-citation chain or uniqueness theorem. Because the central claims are falsifiable by direct replication against the stated external baseline and do not reduce to the paper’s own inputs by construction, the derivation chain contains no load-bearing circular steps.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Ignore Previous Prompt: Attack Techniques For Language Models
F. Perez and I. Ribeiro, “Ignore previous prompt: Attack techniques for language models, ”arXiv preprint arXiv:2211.09527, 2022
work page internal anchor Pith review arXiv 2022
-
[2]
Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection,
K. Greshake, S. Abdelnabi, S. Mishra, C. Endres, T. Holz, and M. Fritz, “Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection, ” inAISec Workshop, 2023
2023
-
[3]
Formalizing and benchmarking prompt injection attacks and defenses,
Y. Liu, Y. Jia, R. Geng, J. Jia, and N. Z. Gong, “Formalizing and benchmarking prompt injection attacks and defenses, ” inUSENIX Security Symposium, 2024
2024
-
[4]
Prompt Injection attack against LLM-integrated Applications
Y. Liu, G. Deng, Y. Li, K. Wang, Z. Wang, X. Wang, T. Zhang, Y. Liu, H. Wang, Y. Zhenget al., “Prompt injection attack against llm-integrated applications, ”arXiv preprint arXiv:2306.05499, 2023
work page internal anchor Pith review arXiv 2023
-
[5]
Neural exec: Learning (and learning from) execution triggers for prompt injection attacks,
D. Pasquini, M. Strohmeier, and C. Troncoso, “Neural exec: Learning (and learning from) execution triggers for prompt injection attacks, ” inAI Sec Workshop, 2024
2024
-
[6]
X. Liu, Z. Yu, Y. Zhang, N. Zhang, and C. Xiao, “Automatic and universal prompt injection attacks against large language models, ”arXiv preprint arXiv:2403.04957, 2024
-
[7]
A critical evaluation of defenses against prompt injection attacks,
Y. Jia, Z. Shao, Y. Liu, J. Jia, D. Song, and N. Z. Gong, “A critical evaluation of defenses against prompt injection attacks, ”arXiv preprint arXiv:2505.18333, 2025
-
[8]
Secalign: De- fending against prompt injection with preference optimization,
S. Chen, A. Zharmagambetov, S. Mahloujifar, K. Chaudhuri, D. Wagner, and C. Guo, “Secalign: De- fending against prompt injection with preference optimization, ” inCCS, 2025
2025
-
[9]
Datasentinel: A game-theoretic detection of prompt injection attacks,
Y. Liu, Y. Jia, J. Jia, D. Song, and N. Z. Gong, “Datasentinel: A game-theoretic detection of prompt injection attacks, ” inIEEE S&P, 2025
2025
-
[10]
Poisonedrag: Knowledge corruption attacks to retrieval- augmented generation of large language models,
W. Zou, R. Geng, B. Wang, and J. Jia, “Poisonedrag: Knowledge corruption attacks to retrieval- augmented generation of large language models, ” inUSENIX Security, 2025
2025
-
[11]
Phantom: General trigger attacks on retrieval augmented language generation,
H. Chaudhari, G. Severi, J. Abascal, M. Jagielski, C. A. Choquette-Choo, M. Nasr, C. Nita-Rotaru, and A. Oprea, “Phantom: General trigger attacks on retrieval augmented language generation, ”arXiv, 2024
2024
-
[12]
Certifiably robust rag against retrieval corruption,
C. Xiang, T. Wu, Z. Zhong, D. Wagner, D. Chen, and P. Mittal, “Certifiably robust rag against retrieval corruption, ”arXiv preprint arXiv:2405.15556, 2024
-
[13]
Trojanrag: Retrieval-augmented generation can be backdoor driver in large language models,
P. Cheng, Y. Ding, T. Ju, Z. Wu, W. Du, P. Yi, Z. Zhang, and G. Liu, “Trojanrag: Retrieval-augmented generation can be backdoor driver in large language models, ”arXiv preprint arXiv:2405.13401, 2024
-
[14]
Machine against the {RAG}: Jamming {Retrieval- Augmented}generation with blocker documents,
A. Shafran, R. Schuster, and V. Shmatikov, “Machine against the {RAG}: Jamming {Retrieval- Augmented}generation with blocker documents, ” inUSENIX Security, 2025
2025
-
[15]
Y. Gong, Z. Chen, M. Chen, F. Yu, W. Lu, X. Wang, X. Liu, and J. Liu, “Topic-fliprag: Topic-orientated adversarial opinion manipulation attacks to retrieval-augmented generation models, ”arXiv preprint arXiv:2502.01386, 2025. Preprint version
-
[16]
Graphrag under fire,
J. Liang, Y. Wang, C. Li, R. Zhu, T. Jiang, N. Gong, and T. Wang, “Graphrag under fire, ” inIEEE S&P, 2026
2026
-
[17]
Universal and transferable adversarial attacks on aligned language models,
A. Zou, Z. Wang, N. Carlini, M. Nasr, J. Z. Kolter, and M. Fredrikson, “Universal and transferable adversarial attacks on aligned language models, ”arXiv, 2023
2023
-
[18]
nanogcg,
GraySwanAI, “nanogcg, ” https://github.com/GraySwanAI/nanoGCG, 2024, accessed: 2025-11-06
2024
-
[19]
Autodan: Generating stealthy jailbreak prompts on aligned large language models,
X. Liu, N. Xu, M. Chen, and C. Xiao, “Autodan: Generating stealthy jailbreak prompts on aligned large language models, ” inICLR, 2024
2024
-
[20]
M. Nasr, N. Carlini, C. Sitawarin, S. V. Schulhoff, J. Hayes, M. Ilie, J. Pluto, S. Song, H. Chaudhari, I. Shumailovet al., “The attacker moves second: Stronger adaptive attacks bypass defenses against llm jailbreaks and prompt injections, ”arXiv preprint arXiv:2510.09023, 2025
-
[21]
Y. Wen, A. Zharmagambetov, I. Evtimov, N. Kokhlikyan, T. Goldstein, K. Chaudhuri, and C. Guo, “Rl is a hammer and llms are nails: A simple reinforcement learning recipe for strong prompt injection, ” arXiv preprint arXiv:2510.04885, 2025
-
[22]
Piarena: A platform for prompt injection evaluation,
R. Geng, C. Yin, Y. Wang, Y. Chen, and J. Jia, “Piarena: A platform for prompt injection evaluation, ” in ACL, 2026
2026
-
[23]
Pismith: Reinforcement learning-based red teaming for prompt injection defenses,
C. Yin, R. Geng, Y. Wang, and J. Jia, “Pismith: Reinforcement learning-based red teaming for prompt injection defenses, ”arXiv preprint arXiv:2603.13026, 2026
-
[24]
Tree of attacks: Jailbreaking black-box llms automatically,
A. Mehrotra, M. Zampetakis, P. Kassianik, B. Nelson, H. Anderson, Y. Singer, and A. Karbasi, “Tree of attacks: Jailbreaking black-box llms automatically, ”NeurIPS, 2024
2024
-
[25]
Meta secalign: A secure foundation llm against prompt injection attacks,
S. Chen, A. Zharmagambetov, D. Wagner, and C. Guo, “Meta secalign: A secure foundation llm against prompt injection attacks, ”arXiv preprint arXiv:2507.02735, 2025
-
[26]
AutoDAN: Generating Stealthy Jailbreak Prompts on Aligned Large Language Models
X. Liu, N. Xu, M. Chen, and C. Xiao, “Autodan: Generating stealthy jailbreak prompts on aligned large language models, ”arXiv preprint arXiv:2310.04451, 2023
work page internal anchor Pith review arXiv 2023
-
[27]
Autograd mechanics,
PyTorch Contributors, “Autograd mechanics, ” https://docs.pytorch.org/docs/stable/notes/autograd. html, 2025, accessed 2025-10-05
2025
-
[28]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need, ”Advances in neural information processing systems, vol. 30, 2017
2017
-
[29]
Making a sota adversarial attack on llms 38×faster,
Haize Labs, “Making a sota adversarial attack on llms 38×faster, ” https://www.haizelabs.com/ technology/making-a-sota-adversarial-attack-on-llms-38x-faster, 2024, accessed: 2025-11-06
2024
-
[30]
Jailbreaking leading safety-aligned llms with simple adaptive attacks,
M. Andriushchenko, F. Croce, and N. Flammarion, “Jailbreaking leading safety-aligned llms with simple adaptive attacks, ” inICLR, 2025
2025
-
[31]
Lessons from defending gemini against indirect prompt injections,
C. Shi, S. Lin, S. Song, J. Hayes, I. Shumailov, I. Yona, J. Pluto, A. Pappu, C. A. Choquette-Choo, M. Nasret al., “Lessons from defending gemini against indirect prompt injections, ”arXiv preprint arXiv:2505.14534, 2025
-
[32]
Black-box optimization of llm outputs by asking for directions,
J. Zhang, M. Ding, Y. Liu, J. Hong, and F. Tramèr, “Black-box optimization of llm outputs by asking for directions, ”arXiv preprint arXiv:2510.16794, 2025
-
[33]
GPTFUZZER: Red Teaming Large Language Models with Auto-Generated Jailbreak Prompts
J. Yu, X. Lin, Z. Yu, and X. Xing, “Gptfuzzer: Red teaming large language models with auto-generated jailbreak prompts, ”arXiv preprint arXiv:2309.10253, 2023
work page internal anchor Pith review arXiv 2023
-
[34]
Pleak: Prompt leaking attacks against large language model applications,
B. Hui, H. Yuan, N. Gong, P. Burlina, and Y. Cao, “Pleak: Prompt leaking attacks against large language model applications, ” inCCS, 2024
2024
-
[35]
Z. Liao and H. Sun, “Amplegcg: Learning a universal and transferable generative model of adversarial suffixes for jailbreaking both open and closed llms, ”arXiv preprint arXiv:2404.07921, 2024. Preprint version
-
[36]
Tao-attack: Toward advanced optimization-based jailbreak attacks for large language models,
Z. Xu, J. Li, X. Zhang, H. Yu, and H. Liu, “Tao-attack: Toward advanced optimization-based jailbreak attacks for large language models, ”arXiv preprint arXiv:2603.03081, 2026
-
[37]
Claude code: An ai coding assistant,
Anthropic, “Claude code: An ai coding assistant, ” https://www.anthropic.com/claude-code, 2025, accessed: 2026
2025
-
[38]
Jailbreaking leading safety-aligned llms with simple adaptive attacks
M. Andriushchenko, F. Croce, and N. Flammarion, “Jailbreaking leading safety-aligned llms with simple adaptive attacks, ”arXiv preprint arXiv:2404.02151, 2024
-
[39]
Pal: Proxy-guided black-box attack on large language models
C. Sitawarin, N. Mu, D. Wagner, and A. Araujo, “Pal: Proxy-guided black-box attack on large language models, ”arXiv preprint arXiv:2402.09674, 2024
-
[40]
Flashattention-2: Faster attention with better parallelism and work partitioning,
T. Dao, “Flashattention-2: Faster attention with better parallelism and work partitioning, ”arXiv, 2023
2023
-
[41]
Smoothquant: Accurate and efficient post-training quantization for large language models,
G. Xiao, J. Lin, M. Seznec, H. Wu, J. Demouth, and S. Han, “Smoothquant: Accurate and efficient post-training quantization for large language models, ” inInternational conference on machine learning. PMLR, 2023, pp. 38 087–38 099
2023
-
[42]
Efficient memory management for large language model serving with pagedattention,
W. Kwon, Z. Li, S. Zhuang, Y. Sheng, L. Zheng, C. H. Yu, J. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for large language model serving with pagedattention, ” inProceedings of the 29th symposium on operating systems principles, 2023, pp. 611–626
2023
-
[43]
Efficiently scaling transformer inference,
R. Pope, S. Douglas, A. Chowdhery, J. Devlin, J. Bradbury, J. Heek, K. Xiao, S. Agrawal, and J. Dean, “Efficiently scaling transformer inference, ”Proceedings of machine learning and systems, vol. 5, pp. 606–624, 2023
2023
-
[44]
Positive review only’: Researchers hide ai prompts in papers,
Nikkei Asia, “Positive review only’: Researchers hide ai prompts in papers, ” https://asia.nikkei.com/Business/Technology/Artificial-intelligence/ Positive-review-only-Researchers-hide-AI-prompts-in-papers, 2025
2025
-
[45]
Openai’s approach to external red teaming for ai models and systems,
L. Ahmad, S. Agarwal, M. Lampe, and P. Mishkin, “Openai’s approach to external red teaming for ai models and systems, ”arXiv preprint arXiv:2503.16431, 2025
-
[46]
HarmBench: A Standardized Evaluation Framework for Automated Red Teaming and Robust Refusal
M. Mazeika, L. Phan, X. Yin, A. Zou, Z. Wang, N. Mu, E. Sakhaee, N. Li, S. Basart, B. Liet al., “Harmbench: A standardized evaluation framework for automated red teaming and robust refusal, ”arXiv preprint arXiv:2402.04249, 2024
work page internal anchor Pith review arXiv 2024
-
[47]
Hotflip: White-box adversarial examples for text classifica- tion,
J. Ebrahimi, A. Rao, D. Lowd, and D. Dou, “Hotflip: White-box adversarial examples for text classifica- tion, ”arXiv preprint arXiv:1712.06751, 2017
-
[48]
Learning to attribute with attention,
B. Cohen-Wang, Y.-S. Chuang, and A. Madry, “Learning to attribute with attention, ”arXiv preprint arXiv:2504.13752, 2025
-
[49]
AttnTrace: Contextual Attribution of Prompt Injection and Knowledge Corruption
Y. Wang, R. Geng, Y. Chen, and J. Jia, “Attntrace: Attention-based context traceback for long-context llms, ”arXiv preprint arXiv:2508.03793, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[50]
Analyzing the Structure of Attention in a Transformer Language Model
J. Vig and Y. Belinkov, “Analyzing the structure of attention in a transformer language model, ”arXiv preprint arXiv:1906.04284, 2019
work page Pith review arXiv 1906
-
[51]
Hotflip: White-box adversarial examples for text classifica- tion,
J. Ebrahimi, A. Rao, D. Lowd, and D. Dou, “Hotflip: White-box adversarial examples for text classifica- tion, ” inACL, 2018
2018
-
[52]
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
Y. Bai, X. Lv, J. Zhang, H. Lyu, J. Tang, Z. Huang, Z. Du, X. Liu, A. Zeng, L. Houet al., “Longbench: A bilingual, multitask benchmark for long context understanding, ”arXiv preprint arXiv:2308.14508, 2023
work page internal anchor Pith review arXiv 2023
-
[53]
Tracllm: A generic framework for attributing outputs of long context llms,
Y. Wang, W. Zou, R. Geng, and J. Jia, “Tracllm: A generic framework for attributing outputs of long context llms, ” inUSENIX Security Symposium, 2025
2025
-
[54]
Musique: Multihop questions via single- hop question composition,
H. Trivedi, N. Balasubramanian, T. Khot, and A. Sabharwal, “Musique: Multihop questions via single- hop question composition, ”Transactions of the Association for Computational Linguistics, vol. 10, pp. 539–554, 2022. Preprint version
2022
-
[55]
The narrativeqa reading comprehension challenge,
T. Kočisk`y, J. Schwarz, P. Blunsom, C. Dyer, K. M. Hermann, G. Melis, and E. Grefenstette, “The narrativeqa reading comprehension challenge, ”Transactions of the Association for Computational Linguistics, vol. 6, pp. 317–328, 2018
2018
-
[56]
Efficient attentions for long document summarization,
L. Huang, S. Cao, N. Parulian, H. Ji, and L. Wang, “Efficient attentions for long document summarization, ” arXiv preprint arXiv:2104.02112, 2021
-
[57]
Natural questions: a benchmark for question answering research,
T. Kwiatkowski, J. Palomaki, O. Redfield, M. Collins, A. Parikh, C. Alberti, D. Epstein, I. Polosukhin, J. Devlin, K. Leeet al., “Natural questions: a benchmark for question answering research, ”TACL, 2019
2019
-
[58]
Hotpotqa: A dataset for diverse, explainable multi-hop question answering,
Z. Yang, P. Qi, S. Zhang, Y. Bengio, W. Cohen, R. Salakhutdinov, and C. D. Manning, “Hotpotqa: A dataset for diverse, explainable multi-hop question answering, ” inEMNLP, 2018
2018
-
[59]
Ms marco: A human generated machine reading comprehension dataset,
T. Nguyen, M. Rosenberg, X. Song, J. Gao, S. Tiwary, R. Majumder, and L. Deng, “Ms marco: A human generated machine reading comprehension dataset, ”choice, vol. 2640, p. 660, 2016
2016
-
[60]
Prompt injection attacks against gpt-3,
S. Willison, “Prompt injection attacks against gpt-3, ” https://simonwillison.net/2022/Sep/12/ prompt-injection/, 2022
2022
-
[61]
Evaluating the susceptibility of pre-trained language models via handcrafted adversarial examples,
H. J. Branch, J. R. Cefalu, J. McHugh, L. Hujer, A. Bahl, D. d. C. Iglesias, R. Heichman, and R. Darwishi, “Evaluating the susceptibility of pre-trained language models via handcrafted adversarial examples, ” arXiv preprint arXiv:2209.02128, 2022
-
[62]
Delimiters won’t save you from prompt injection,
S. Willison, “Delimiters won’t save you from prompt injection, ” https://simonwillison.net/2023/May/ 11/delimiters-wont-save-you, 2023
2023
-
[63]
all-MiniLM-L6-v2: A compact sentence embedding model,
N. Reimers, I. Gurevych, and the SentenceTransformers community, “all-MiniLM-L6-v2: A compact sentence embedding model, ” 2021, 384-dimensional sentence embeddings, trained on 1 billion sentence pairs. [Online]. Available: https://huggingface.co/sentence-transformers/all-MiniLM-L6-v2
2021
-
[64]
Llama Prompt Guard 2: A Classifier for Detecting Prompt Injection and Jailbreak Attacks,
Meta, “Llama Prompt Guard 2: A Classifier for Detecting Prompt Injection and Jailbreak Attacks, ” https://huggingface.co/meta-llama/Llama-Prompt-Guard-2-86M, 2025, accessed: 2025
2025
-
[65]
Jailbreaking black box large language models in twenty queries,
P. Chao, A. Robey, E. Dobriban, H. Hassani, G. J. Pappas, and E. Wong, “Jailbreaking black box large language models in twenty queries, ” in2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML). IEEE, 2025, pp. 23–42
2025
-
[66]
Scaled dot-product attention in pytorch,
PyTorch Contributors, “Scaled dot-product attention in pytorch, ” https://pytorch.org/docs/stable/ generated/torch.nn.functional.scaled_dot_product_attention.html, 2023, accessed: 2026-04-17
2023
-
[67]
Hugging face transformers,
Hugging Face Inc., “Hugging face transformers, ” https://github.com/huggingface/transformers, 2023, accessed: 2026-04-17
2023
-
[68]
Long code arena: a set of benchmarks for long-context code models
E. Bogomolov, A. Eliseeva, T. Galimzyanov, E. Glukhov, A. Shapkin, M. Tigina, Y. Golubev, A. Kovrigin, A. Van Deursen, M. Izadiet al., “Long code arena: a set of benchmarks for long-context code models, ” arXiv preprint arXiv:2406.11612, 2024
-
[69]
lca-baselines: Baselines for all tasks from long code arena benchmarks,
JetBrains-Research, “lca-baselines: Baselines for all tasks from long code arena benchmarks, ” https: //github.com/JetBrains-Research/lca-baselines, 2025, gitHub repository, accessed 1 Nov 2025
2025
-
[70]
Agentpoison: Red-teaming llm agents via poisoning memory or knowledge bases,
Z. Chen, Z. Xiang, C. Xiao, D. Song, and B. Li, “Agentpoison: Red-teaming llm agents via poisoning memory or knowledge bases, ”arXiv, 2024
2024
-
[71]
Pymupdf – python bindings for mupdf (version 1.26.3),
Artifex Software Inc. and contributors, “Pymupdf – python bindings for mupdf (version 1.26.3), ” https://pymupdf.readthedocs.io/, released July 2, 2025; high-performance PDF/text extraction library
2025
-
[72]
Piarena: A platform for prompt injection evaluation,
R. Geng, C. Yin, Y. Wang, Y. Chen, and J. Jia, “Piarena: A platform for prompt injection evaluation, ” https://github.com/sleeepeer/PIArena, 2026, gitHub repository. Preprint version Figure 3:Influence scores of individual tokens on the hidden states of the target output ˆY at the 300-th iteration, when the malicious text is injected in the middle of the ...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.