Recognition: unknown
AirFM-DDA: Air-Interface Foundation Model in the Delay-Doppler-Angle Domain for AI-Native 6G
Pith reviewed 2026-05-10 06:57 UTC · model grok-4.3
The pith
Reparameterizing channel state information into the delay-Doppler-angle domain lets a foundation model learn universal wireless representations with far lower cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
AirFM-DDA reparameterizes CSI from the STF domain into the DDA domain to explicitly resolve multipath components along physically meaningful axes, employs a window-based attention module augmented with frame-structure-aware positional encoding to align with locally clustered multipath dependencies, and thereby achieves superior zero-shot generalization on channel prediction and estimation tasks while reducing training and inference costs by nearly an order of magnitude relative to global attention.
What carries the argument
DDA-domain reparameterization of CSI paired with window-based attention and frame-structure-aware positional encoding.
Load-bearing premise
That reparameterizing CSI into the delay-Doppler-angle domain will separate multipath components along physically distinct axes and thereby expose a universal channel structure that windowed attention can capture without loss of essential information.
What would settle it
A controlled dataset in which known multipath components remain entangled even after DDA transformation, where AirFM-DDA then loses its reported generalization advantage over STF-based models on the same prediction and estimation tasks.
Figures




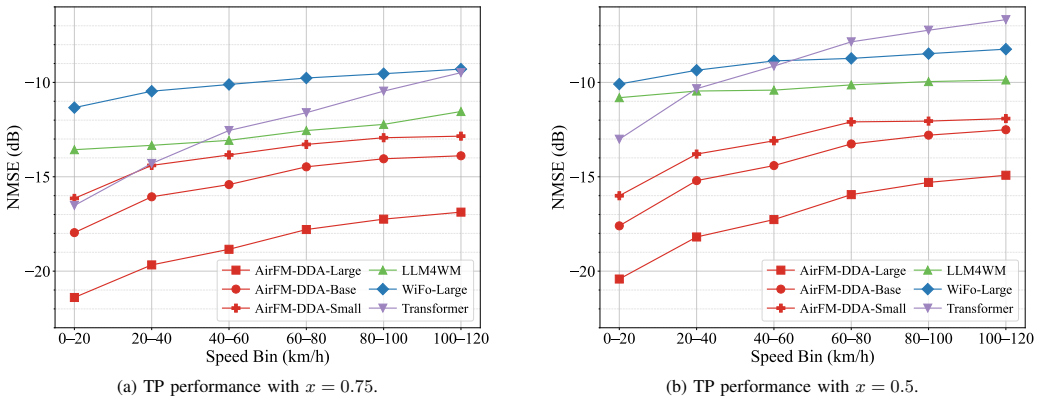
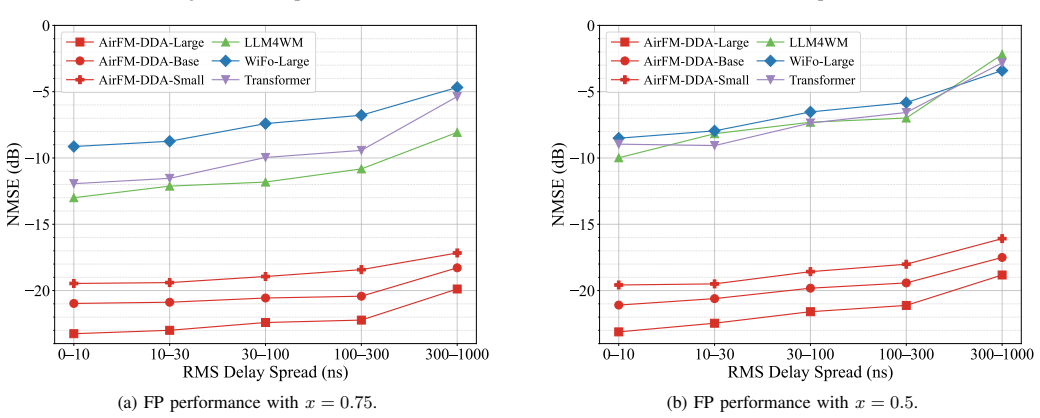



read the original abstract
The success of large foundation models is catalyzing a new paradigm for AI-native 6G network design: wireless foundation models for physical layer design. However, existing models often operate on channel state information (CSI) in the space-time-frequency (STF) domain, where distinct multipath components are inherently superimposed and structurally entangled. This hinders the learning of universal channel representation. Meanwhile, their reliance on global attention mechanisms incurs prohibitive computational overhead. In this paper, we propose AirFM-DDA, an Air-interface Foundation Model operating in the Delay-Doppler-Angle (DDA) domain for physicallayer tasks. Specifically, AirFM-DDA reparameterizes CSI from the STF domain into the DDA domain to explicitly resolve multipath components along physically meaningful axes. It employs a window-based attention module augmented with framestructure-aware positional encoding (FS-PE). This window-based attention aligns with locally clustered multipath dependencies while avoiding quadratic-complexity global attention, and FS-PE injects frame-structure priors into network. Extensive experiments demonstrate that AirFM-DDA achieves superior zero-shot generalization across unseen scenarios and datasets, consistently outperforming the baselines on channel prediction and estimation tasks. Compared to the global attention, its window-based attention reduces training and inference costs by nearly an order of magnitude. Moreover, AirFM-DDA maintains robustness under high mobility, large delay spreads, severe noise, and extreme aliasing conditions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AirFM-DDA, an air-interface foundation model for AI-native 6G physical-layer tasks. It reparameterizes channel state information (CSI) from the space-time-frequency (STF) domain into the delay-Doppler-angle (DDA) domain to disentangle multipath components along physically interpretable axes, replaces global attention with a window-based attention module augmented by frame-structure-aware positional encoding (FS-PE), and reports superior zero-shot generalization across unseen scenarios, consistent outperformance on channel prediction and estimation, nearly order-of-magnitude reductions in training/inference cost relative to global attention, and robustness under high mobility, large delay spreads, severe noise, and extreme aliasing.
Significance. If the central claims are substantiated, the work would represent a meaningful step toward efficient, generalizable wireless foundation models by exploiting the physical structure of multipath propagation in the DDA domain and by replacing quadratic global attention with a cheaper windowed alternative. The combination of domain reparameterization and structure-aware positional encoding could influence subsequent designs of AI-native 6G physical-layer algorithms, provided the claimed lossless information preservation and locality assumptions hold.
major comments (3)
- [Abstract] Abstract: the manuscript asserts 'superior zero-shot generalization across unseen scenarios and datasets' and 'consistently outperforming the baselines' yet supplies no quantitative metrics, dataset descriptions, baseline specifications, or error bars. Without these, it is impossible to assess whether the experimental evidence supports the stated claims.
- [Proposed method] Proposed method (DDA reparameterization): the central claim that transforming CSI from STF to DDA 'explicitly resolve[s] multipath components along physically meaningful axes' and yields a 'universal channel representation' requires explicit verification that the 2-D Fourier mapping is invertible and free of leakage or aliasing artifacts. The manuscript does not analyze resolution limits or information loss under the high-mobility and extreme-aliasing regimes highlighted in the abstract; if leakage occurs, the claimed robustness and superiority over STF baselines would not follow.
- [Proposed method] Proposed method (window-based attention): the paper states that window-based attention 'aligns with locally clustered multipath dependencies' and reduces cost by nearly an order of magnitude 'without loss of critical information.' No ablation is described that quantifies performance degradation relative to global attention when non-local dependencies are discarded, nor is it shown that FS-PE compensates for any lost long-range correlations.
minor comments (2)
- [Abstract] Abstract: 'physicallayer' is missing a space; 'framestructure-aware' should be hyphenated as 'frame-structure-aware'.
- [Abstract] Abstract: the final sentence fragment 'FS-PE injects frame-structure priors into network' is grammatically incomplete.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below and will revise the manuscript accordingly to strengthen the presentation of results and analyses.
read point-by-point responses
-
Referee: [Abstract] Abstract: the manuscript asserts 'superior zero-shot generalization across unseen scenarios and datasets' and 'consistently outperforming the baselines' yet supplies no quantitative metrics, dataset descriptions, baseline specifications, or error bars. Without these, it is impossible to assess whether the experimental evidence supports the stated claims.
Authors: We agree that the abstract would benefit from including key quantitative metrics to support the claims. In the revised manuscript, we will update the abstract to report specific performance numbers (e.g., NMSE reductions on prediction and estimation tasks), briefly describe the datasets and baselines, and reference the error bars shown in the main experimental figures. This change will make the abstract self-contained for initial assessment while preserving its brevity. revision: yes
-
Referee: [Proposed method] Proposed method (DDA reparameterization): the central claim that transforming CSI from STF to DDA 'explicitly resolve[s] multipath components along physically meaningful axes' and yields a 'universal channel representation' requires explicit verification that the 2-D Fourier mapping is invertible and free of leakage or aliasing artifacts. The manuscript does not analyze resolution limits or information loss under the high-mobility and extreme-aliasing regimes highlighted in the abstract; if leakage occurs, the claimed robustness and superiority over STF baselines would not follow.
Authors: The DDA reparameterization uses the standard 2D DFT, which is invertible under the assumed sampling conditions of the channel model. We acknowledge that the current manuscript lacks explicit discussion of leakage, aliasing, and resolution limits in extreme regimes. In the revision, we will add a new subsection analyzing invertibility, finite-resolution effects, and information preservation, supported by additional simulations under high-mobility and severe-aliasing conditions to quantify any artifacts and confirm that the DDA advantages persist. revision: yes
-
Referee: [Proposed method] Proposed method (window-based attention): the paper states that window-based attention 'aligns with locally clustered multipath dependencies' and reduces cost by nearly an order of magnitude 'without loss of critical information.' No ablation is described that quantifies performance degradation relative to global attention when non-local dependencies are discarded, nor is it shown that FS-PE compensates for any lost long-range correlations.
Authors: We agree that a dedicated ablation would strengthen the justification for window-based attention. In the revised manuscript, we will add an ablation study comparing window attention (with and without FS-PE) against global attention. This will quantify performance differences arising from restricting to local windows and demonstrate how FS-PE recovers long-range dependencies via frame-structure priors, thereby supporting the claim of negligible critical information loss alongside the reported complexity reduction. revision: yes
Circularity Check
No significant circularity; architecture is a self-contained design choice
full rationale
The paper's central steps consist of (1) applying a standard invertible Fourier-based reparameterization from STF to DDA domain and (2) adopting windowed attention plus frame-structure positional encoding as an architectural prior. Neither step reduces to a fitted parameter renamed as a prediction, nor to a self-citation chain, nor to a self-definitional loop. The DDA transform is presented as a physically motivated coordinate change whose invertibility is presupposed by signal-processing fundamentals external to the model; the attention modification is justified by empirical clustering of multipath components rather than by any equation that equates the output to the input by construction. Experiments are reported as validation, not as the source of the claimed representation. The derivation chain therefore remains independent of its own fitted outputs.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Reparameterization of CSI into DDA domain resolves multipath components along physically meaningful axes
- domain assumption Window-based attention aligns with locally clustered multipath dependencies
invented entities (1)
-
Frame-structure-aware positional encoding (FS-PE)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
AirMIND: Air-interface foundation model in the delay–doppler–angle domain,
K. Bianet al., “AirMIND: Air-interface foundation model in the delay–doppler–angle domain,” inProc. IEEE Int. Conf. Commun. Work- shops (ICC Workshops), 2026, accepted
2026
-
[2]
Language models are unsupervised multitask learn- ers,
A. Radfordet al., “Language models are unsupervised multitask learn- ers,”OpenAI blog, vol. 1, no. 8, p. 9, 2019
2019
-
[3]
Segment anything,
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Loet al., “Segment anything,” inProceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 4015–4026
2023
-
[4]
ChannelGPT: A large model toward real-world channel foundation model for 6G environment intelligence communication,
L. Yuet al., “ChannelGPT: A large model toward real-world channel foundation model for 6G environment intelligence communication,” IEEE Commun. Mag., vol. 63, no. 10, pp. 68–74, 2025
2025
-
[5]
Towards channel foundation models (CFMs): Motivations, methodologies and opportunities,
J. Jianget al., “Towards channel foundation models (CFMs): Motivations, methodologies and opportunities,”arXiv preprint arXiv:2507.13637, 2025
-
[6]
Towards wireless native big AI model: the mission and approach differ from large language model,
Z. Chenet al., “Towards wireless native big AI model: the mission and approach differ from large language model,”Sci. China Inf. Sci., vol. 68, no. 7, p. 170303, 2025
2025
-
[7]
A comprehensive survey of large AI models for fu- ture communications: Foundations, applications, and challenges,
F. Jianget al., “A comprehensive survey of large AI models for fu- ture communications: Foundations, applications, and challenges,”IEEE Commun. Surv. Tutor., vol. 28, pp. 4731–4764, 2026
2026
-
[8]
Foundation model empowered synesthesia of machines (SoM): Ai-native intelligent multi-modal sensing-communication inte- gration,
X. Chenget al., “Foundation model empowered synesthesia of machines (SoM): Ai-native intelligent multi-modal sensing-communication inte- gration,”IEEE Trans. Netw. Sci. Eng., vol. 13, pp. 762–782, 2026
2026
-
[9]
From large AI models to agentic AI: A tutorial on future intelligent communications,
F. Jianget al., “From large AI models to agentic AI: A tutorial on future intelligent communications,”IEEE J. Sel. Areas Commun., vol. 44, pp. 3507–3540, 2026
2026
-
[10]
Large language models for wireless communications: From adaptation to autonomy,
L. Lianget al., “Large language models for wireless communications: From adaptation to autonomy,”IEEE Commun. Mag., pp. 1–8, 2026
2026
-
[11]
LLM4WM: Adapting LLM for wireless multi-tasking,
X. Liuet al., “LLM4WM: Adapting LLM for wireless multi-tasking,” IEEE Trans. Mach. Learn. Commun. Networking, vol. 3, pp. 835–847, 2025
2025
-
[12]
Large language model enabled multi-task physical layer network,
T. Zheng and L. Dai, “Large language model enabled multi-task physical layer network,”IEEE Trans. Commun., vol. 74, pp. 307–321, 2026
2026
-
[13]
LLM4CP: Adapting large language models for channel prediction,
B. Liuet al., “LLM4CP: Adapting large language models for channel prediction,”J. Commun. Inf. Netw., vol. 9, no. 2, pp. 113–125, 2024
2024
-
[14]
2DLAM: Joint Delay-Doppler estimation in UA V mmWave system via large AI model,
D. Xieet al., “2DLAM: Joint Delay-Doppler estimation in UA V mmWave system via large AI model,” inAAAI workshop on AI4WCN, Mar. 2025, pp. 1–9
2025
-
[15]
Exploring the Potential of Large Language Models for Massive MIMO CSI Feedback,
Y . Cuiet al., “Exploring the potential of large language models for massive MIMO CSI feedback,”arXiv preprint arXiv:2501.10630, 2025
-
[16]
LVM4CSI: Enabling direct application of pre-trained large vision models for wireless channel tasks,
J. Guoet al., “LVM4CSI: Enabling direct application of pre-trained large vision models for wireless channel tasks,”arXiv preprint arXiv:2507.05121, 2025
-
[17]
LWM: A pre-trained wireless foundation model for universal feature extraction,
S. Alikhaniet al., “LWM: A pre-trained wireless foundation model for universal feature extraction,” inProc. IEEE Int. Conf. Mach. Learn. Commun. Netw. (ICMLCN), Barcelona, Spain, May 2025, pp. 1–6
2025
-
[18]
F. O. Cataket al., “BERT4MIMO: A foundation model using BERT architecture for massive MIMO channel state information prediction,” arXiv preprint arXiv:2501.01802, 2025
-
[19]
WiFo: Wireless foundation model for channel prediction,
B. Liu, S. Gao, X. Liu, X. Cheng, and L. Yang, “WiFo: Wireless foundation model for channel prediction,”Sci. China Inf. Sci., vol. 68, no. 6, p. 162302, 2025
2025
-
[20]
WirelessGPT: A generative foundation model for multi-task integrated sensing and communication,
T. Yanget al., “WirelessGPT: A generative foundation model for multi-task integrated sensing and communication,”IEEE J. Sel. Areas Commun., vol. 44, pp. 2259–2273, 2026
2026
-
[21]
DeepMIMO: A generic deep learning dataset for mil- limeter wave and massive MIMO applications,
A. Alkhateeb, “DeepMIMO: A generic deep learning dataset for mil- limeter wave and massive MIMO applications,” inProc. Inf. Theory Appl. Workshop (ITA), San Diego, CA, USA, Feb. 2019, pp. 1–8
2019
-
[22]
Study on channel model for frequencies from 0.5 to 100 GHz,
3rd Generation Partnership Project (3GPP), “Study on channel model for frequencies from 0.5 to 100 GHz,” 3rd Generation Partnership Project (3GPP), Technical Report TR 38.901, Jan. 2026, Version 19.2.0, Release
2026
-
[23]
Available: https://www.3gpp.org/dynareport/38901.htm
[Online]. Available: https://www.3gpp.org/dynareport/38901.htm
-
[24]
B. Guleret al., “A multi-task foundation model for wireless channel representation using contrastive and masked autoencoder learning,” arXiv preprint arXiv:2505.09160, 2025
-
[25]
Addressing the curse of scenario and task generalization in AI-6G: A multi-modal paradigm,
T. Jiaoet al., “Addressing the curse of scenario and task generalization in AI-6G: A multi-modal paradigm,”IEEE Trans. Wireless Commun., vol. 24, no. 9, pp. 7377–7391, 2025
2025
-
[26]
Wair-d: Wireless ai research dataset,
Y . Huangfuet al., “W AIR-D: Wireless AI research dataset,”arXiv preprint arXiv:2212.02159, 2022
-
[27]
CSI-MAE: A Masked Autoencoder-based Channel Foundation Model,
J. Jianget al., “CSI-MAE: A masked autoencoder-based channel foun- dation model,”arXiv preprint arXiv:2601.03789, 2026
-
[28]
Sionna RT: Differentiable ray tracing for radio prop- agation modeling,
J. Hoydiset al., “Sionna RT: Differentiable ray tracing for radio prop- agation modeling,” inProc. IEEE Globecom Workshops (GC Wkshps), Dec. 2023, pp. 317–321
2023
-
[29]
ICWLM: A multi-task wireless large model via in-context learning,
Y . Wenet al., “ICWLM: A multi-task wireless large model via in-context learning,”IEEE Trans. Commun., 2026
2026
-
[30]
MUSE-FM: Multi-task environment-aware foundation model for wireless communications,
T. Zhenget al., “MUSE-FM: Multi-task environment-aware foundation model for wireless communications,”arXiv preprint arXiv:2509.01967, 2025
-
[31]
Sensiverse: A dataset for ISAC study,
J. Luoet al., “Sensiverse: A dataset for ISAC study,”arXiv preprint arXiv:2308.13789, 2023
-
[32]
WiFo-2: a generalist foundation model unifies heterogeneous wireless system design
B. Liuet al., “Foundation model for intelligent wireless communica- tions,”arXiv preprint arXiv:2511.22222, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
C. Zhanget al., “HeterCSI: Channel-adaptive heterogeneous CSI pre- training framework for generalized wireless foundation models,”arXiv preprint arXiv:2601.18200, 2026
-
[34]
A wireless foundation model for multi-task prediction,
Y . Shenget al., “A wireless foundation model for multi-task prediction,” arXiv preprint arXiv:2507.05938, 2025
-
[35]
A multi-source dataset of urban life in the city of milan and the province of trentino,
G. Barlacchiet al., “A multi-source dataset of urban life in the city of milan and the province of trentino,”Sci. Data, vol. 2, no. 1, pp. 1–15, Oct. 2015
2015
-
[36]
A MIMO wireless channel foundation model via CIR- CSI consistency,
J. Jianget al., “A MIMO wireless channel foundation model via CIR- CSI consistency,” inProc. IEEE Int. Conf. Mach. Learn. Commun. Netw. (ICMLCN), 2025, pp. 1–6
2025
-
[37]
Large wireless localization model (LWLM): A foundation model for positioning in 6G networks,
G. Panet al., “Large wireless localization model (LWLM): A foundation model for positioning in 6G networks,”arXiv preprint arXiv:2505.10134, 2025
-
[38]
Attention is all you need,
A. Vaswaniet al., “Attention is all you need,” inProc. Adv. Neural Inf. Process. Syst. (NeurIPS), vol. 30, 2017
2017
-
[39]
Swin Transformer: Hierarchical vision Transformer using shifted windows,
Z. Liuet al., “Swin Transformer: Hierarchical vision Transformer using shifted windows,” inProc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Oct. 2021, pp. 10 012–10 022
2021
-
[40]
SwinIR: Image restoration using swin transformer,
J. Lianget al., “SwinIR: Image restoration using swin transformer,” inProc. IEEE/CVF Int. Conf. Comput. Vis. Workshops (ICCVW), Oct. 2021, pp. 1833–1844
2021
-
[41]
A survey on curriculum learning,
X. Wanget al., “A survey on curriculum learning,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 44, no. 9, pp. 4555–4576, 2022
2022
-
[42]
NR; physical channels and modulation,
3GPP, “NR; physical channels and modulation,” 3rd Generation Partnership Project (3GPP), TS 38.211 V15.4.0, Sep. 2018. [Online]. Available: https://www.3gpp.org/ftp/Specs
2018
-
[43]
Accurate channel prediction based on Transformer: Making mobility negligible,
H. Jianget al., “Accurate channel prediction based on Transformer: Making mobility negligible,”IEEE J. Sel. Areas Commun., vol. 40, no. 9, pp. 2717–2732, Sep. 2022
2022
-
[44]
Orthogonal time frequency space modulation,
R. Hadaniet al., “Orthogonal time frequency space modulation,” inProc. IEEE Wireless Commun. Netw. Conf. (WCNC), Mar. 2017, pp. 1–6
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.