Recognition: unknown
Lucid-XR: An Extended-Reality Data Engine for Robotic Manipulation
Pith reviewed 2026-05-09 19:46 UTC · model grok-4.3
The pith
Lucid-XR produces synthetic multi-modal data from web-based XR physics simulations that trains robot visual policies for zero-shot transfer to real cluttered and dimly lit environments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Lucid-XR is a generative data engine whose core is an on-device physics simulation environment called vuer that runs directly in an XR headset over the web, integrated with human-to-robot pose retargeting and a physics-guided video generation pipeline that accepts natural-language specifications; training visual policies exclusively on the resulting synthetic multi-modal data produces zero-shot transfer to previously unseen real-world evaluation scenes that are cluttered and badly lit.
What carries the argument
vuer, the web-based physics simulation environment that runs directly on the XR headset to provide latency-free immersive data collection and interaction at internet scale.
If this is right
- Visual policies for dexterous manipulation can be trained entirely in simulation and deployed without real-world adaptation.
- Data collection for soft-material, particle, and rigid-contact tasks becomes scalable through web-based XR access rather than physical hardware.
- Natural-language steering of the video generation step allows targeted creation of training distributions for specific manipulation challenges.
- Internet-scale access to the simulation removes the need for specialized lab equipment when gathering diverse multi-modal robot data.
Where Pith is reading between the lines
- The approach could make it practical to retrain policies frequently as robot hardware or task requirements change, since new data can be generated on demand without physical setup.
- Language steerability opens the possibility that domain experts outside robotics could create custom datasets for narrow industrial or home tasks.
- If the physics simulation in vuer proves accurate for contact dynamics, similar web-based engines might accelerate data generation for other embodied AI domains such as navigation or assembly.
Load-bearing premise
The synthetic data generated by the XR physics simulation and language-steerable video pipeline is realistic and diverse enough in physics and appearance to bridge the sim-to-real gap for visual policies without any real-world fine-tuning.
What would settle it
Deploy the same policy trained only on Lucid-XR data onto a physical robot and measure success rate on a standardized set of dexterous tasks in a cluttered, dimly lit room; if performance collapses relative to a policy that received even modest real data, the zero-shot claim is falsified.
Figures












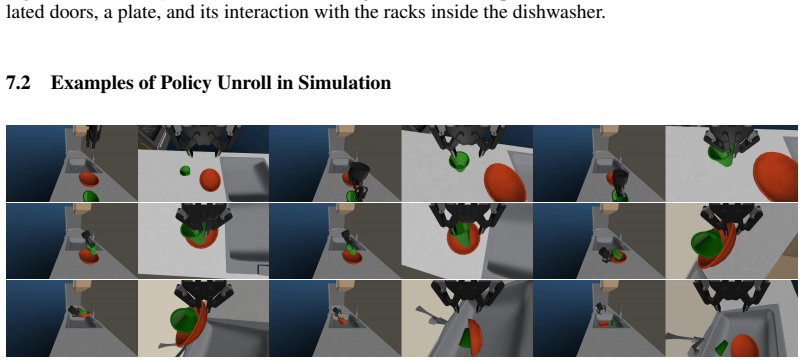






read the original abstract
We introduce Lucid-XR, a generative data engine for creating diverse and realistic-looking multi-modal data to train real-world robotic systems. At the core of Lucid-XR is vuer, a web-based physics simulation environment that runs directly on the XR headset, enabling internet-scale access to immersive, latency-free virtual interactions without requiring specialized equipment. The complete system integrates on-device physics simulation with human-to-robot pose retargeting. Data collected is further amplified by a physics-guided video generation pipeline steerable via natural language specifications. We demonstrate zero-shot transfer of robot visual policies to unseen, cluttered, and badly lit evaluation environments, after training entirely on Lucid-XR's synthetic data. We include examples across dexterous manipulation tasks that involve soft materials, loosely bound particles, and rigid body contact. Project website: https://lucidxr.github.io
Editorial analysis
A structured set of objections, weighed in public.
Circularity Check
No circularity: empirical system demonstration with no derivations, fitted parameters, or self-referential predictions
full rationale
The paper introduces an engineering system (Lucid-XR with vuer on-device physics, pose retargeting, and language-steerable video generation) and reports an empirical demonstration of zero-shot policy transfer from synthetic data. No equations, parameter-fitting procedures, uniqueness theorems, or derivation chains are present in the provided text. The central claim is a direct empirical assertion about real-world performance after training on generated data; it does not reduce to any input by construction, self-citation, or renaming. Self-citations, if any, are not load-bearing for a mathematical result. This matches the default case of a non-circular engineering paper whose validity rests on external validation rather than internal tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The physics simulation running on the XR headset accurately captures contact dynamics, soft-body behavior, and particle interactions relevant to manipulation.
invented entities (1)
-
vuer
no independent evidence
Reference graph
Works this paper leans on
-
[1]
J.-H. Ryu. Reality & effect: A cultural history of visual effects.Communication Dissertations, 2007
2007
-
[2]
J. Turnock. Before Industrial Light and Magic: the independent Hollywood special effects business, 1968–75: Research Article.New Rev. Film Telev. Stud., 7(2):133–156, June 2009
1968
-
[3]
S. Das. The evolution of visual effects in cinema: A journey from practical effects to CGI. Journal of Emerging Technologies and Innovative Research, 10(11):303–309, 2023
2023
-
[4]
Murodillayev
B. Murodillayev. The impact of visual effects on the cinema experience: A comprehensive analysis.Art Des. Rev., 2024
2024
-
[5]
Todorov, T
E. Todorov, T. Erez, and Y . Tassa. Mujoco: A physics engine for model-based control. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, pages 5026–
2012
-
[6]
IEEE, 2012. doi:10.1109/IROS.2012.6386109
-
[8]
Fluid forces.https://mujoco.readthedocs.io/en/latest/ computation/fluid.html, 2025
MuJoCo Documentation. Fluid forces.https://mujoco.readthedocs.io/en/latest/ computation/fluid.html, 2025. Accessed: 2025-August-29
2025
-
[9]
R. Ban, K. Matsumoto, and T. Narumi. Hitchhiking hands: Remote interaction by switching multiple hand avatars with gaze. InSIGGRAPH Asia 2023 Emerging Technologies, pages 1–2. 2023
2023
-
[10]
Expressive whole-body control for humanoid robots,
X. Cheng, Y . Ji, J. Chen, R. Yang, G. Yang, and X. Wang. Expressive whole-body control for humanoid robots, 2024. URLhttps://arxiv.org/abs/2402.16796
-
[11]
Open-television: Teleoperation with immersive active visual feedback,
X. Cheng, J. Li, S. Yang, G. Yang, and X. Wang. Open-television: Teleoperation with immer- sive active visual feedback.arXiv preprint arXiv:2407.01512, 2024
-
[12]
A. Yu, G. Yang, R. Choi, Y . Ravan, J. Leonard, and P. Isola. Learning visual parkour from generated images. In8th Annual Conference on Robot Learning, 2024
2024
-
[13]
Mandlekar, S
A. Mandlekar, S. Nasiriany, B. Wen, I. Akinola, Y . Narang, L. Fan, Y . Zhu, and D. Fox. Mimicgen: A data generation system for scalable robot learning using human demonstrations,
- [14]
-
[15]
Y . Zhou, C. Barnes, J. Lu, J. Yang, and H. Li. On the continuity of rotation representations in neural networks. In2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). IEEE, June 2019
2019
-
[16]
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn. Learning fine-grained bimanual manipulation with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review arXiv 2023
-
[17]
N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko. End-to-end object detection with transformers, 2020. URLhttps://arxiv.org/abs/2005.12872. 9
-
[18]
T. Garipov, S. D. Peuter, G. Yang, V . Garg, S. Kaski, and T. Jaakkola. Compositional sculpting of iterative generative processes, 2023. URLhttps://arxiv.org/abs/2309.16115
-
[19]
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion.The International Journal of Robotics Research, 2024
2024
-
[20]
Planning with Diffusion for Flexible Behavior Synthesis
M. Janner, Y . Du, J. B. Tenenbaum, and S. Levine. Planning with diffusion for flexible behavior synthesis, 2022. URLhttps://arxiv.org/abs/2205.09991
work page internal anchor Pith review arXiv 2022
-
[21]
FiLM: Visual Reasoning with a General Conditioning Layer
E. Perez, F. Strub, H. de Vries, V . Dumoulin, and A. Courville. Film: Visual reasoning with a general conditioning layer, 2017. URLhttps://arxiv.org/abs/1709.07871
work page Pith review arXiv 2017
- [22]
-
[23]
N. Nechyporenko, R. Hoque, C. Webb, M. Sivapurapu, and J. Zhang. Armada: Augmented reality for robot manipulation and robot-free data acquisition, 2024. URLhttps://arxiv. org/abs/2412.10631
-
[24]
Jiang, P
X. Jiang, P. Mattes, X. Jia, N. Schreiber, G. Neumann, and R. Lioutikov. A comprehensive user study on augmented reality-based data collection interfaces for robot learning. In2024 19th ACM/IEEE International Conference on Human-Robot Interaction (HRI), pages 333–342, 2024
2024
- [25]
-
[26]
J. Duan, Y . R. Wang, M. Shridhar, D. Fox, and R. Krishna. Ar2-d2: Training a robot without a robot. 2023
2023
-
[27]
J. Wang, C.-C. Chang, J. Duan, D. Fox, and R. Krishna. Eve: Enabling anyone to train robots using augmented reality, 2024. URLhttps://arxiv.org/abs/2404.06089
-
[28]
J. van Haastregt, M. C. Welle, Y . Zhang, and D. Kragic. Puppeteer your robot: Augmented reality leader-follower teleoperation, 2024. URLhttps://arxiv.org/abs/2407.11741
-
[29]
A. Iyer, Z. Peng, Y . Dai, I. Guzey, S. Haldar, S. Chintala, and L. Pinto. Open teach: A versatile teleoperation system for robotic manipulation, 2024. URLhttps://arxiv.org/abs/2403. 07870
2024
-
[30]
A. Naceri, D. Mazzanti, J. Bimbo, Y . T. Tefera, D. Prattichizzo, D. G. Caldwell, L. S. Mat- tos, and N. Deshpande. The vicarios virtual reality interface for remote robotic teleopera- tion: Teleporting for intuitive tele-manipulation.J. Intell. Robotics Syst., 101(4), Apr. 2021. ISSN 0921-0296. doi:10.1007/s10846-021-01311-7. URLhttps://doi.org/10.1007/ ...
- [31]
- [32]
-
[33]
P. Katara, Z. Xian, and K. Fragkiadaki. Gen2sim: Scaling up robot learning in simulation with generative models, 2023. URLhttps://arxiv.org/abs/2310.18308. 10
- [34]
- [35]
- [36]
- [37]
-
[38]
Cacti: A framework for scal- able multi-task multi-scene visual imitation learning,
Z. Mandi, H. Bharadhwaj, V . Moens, S. Song, A. Rajeswaran, and V . Kumar. Cacti: A framework for scalable multi-task multi-scene visual imitation learning.arXiv preprint arXiv:2212.05711, 2022
-
[39]
J. Jang, S. Ye, Z. Lin, J. Xiang, J. Bjorck, Y . Fang, F. Hu, S. Huang, K. Kundalia, Y .-C. Lin, L. Magne, A. Mandlekar, A. Narayan, Y . L. Tan, G. Wang, J. Wang, Q. Wang, Y . Xu, X. Zeng, K. Zheng, R. Zheng, M.-Y . Liu, L. Zettlemoyer, D. Fox, J. Kautz, S. Reed, Y . Zhu, and L. Fan. Dreamgen: Unlocking generalization in robot learning through video world...
- [40]
-
[41]
O. X.-E. Collaboration, A. O’Neill, A. Rehman, A. Gupta, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jain, A. Tung, A. Bewley, A. Her- zog, A. Irpan, A. Khazatsky, A. Rai, A. Gupta, A. Wang, A. Kolobov, A. Singh, A. Garg, A. Kembhavi, A. Xie, A. Brohan, A. Raffin, A. Sharma, A. Yavary, A. Jain, A. Balakr- ishna, A. W...
work page internal anchor Pith review arXiv 2023
-
[42]
H.-S. Fang, H. Fang, Z. Tang, J. Liu, J. Wang, H. Zhu, and C. Lu. Rh20t: A robotic dataset for learning diverse skills in one-shot. InRSS 2023 Workshop on Learning for Task and Motion Planning, 2023
2023
-
[43]
" " 5< actuator > 6< adhesion body =
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karamcheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Ellis, P. D. Fagan, J. Hejna, M. Itkina, M. Lepert, Y . J. Ma, P. T. Miller, J. Wu, S. Belkhale, S. Dass, H. Ha, A. Jain, A. Lee, Y . Lee, M. Memmel, S. Park, I. Radosavovic, K. Wang, A. Zhan, K. Black, C. Chi, K. B. Hatch, S. Lin, J. ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.