Recognition: unknown
How Language Models Process Out-of-Distribution Inputs: A Two-Pathway Framework
Pith reviewed 2026-05-09 19:41 UTC · model grok-4.3
The pith
Language models detect out-of-distribution inputs through separate pathways for semantic content and processing dynamics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that after removing length-based confounds from prior detectors, genuine out-of-distribution signals split along two pathways: embeddings capture semantic content and succeed on vocabulary-distinctive shifts, while processing trajectories capture hidden-state evolution across layers and succeed on covert-intent inputs that share vocabulary with normal text. Support comes from observed crossovers in method performance across tasks, per-layer breakdowns that isolate length artifacts in early embeddings, and circuit attributions that link adversarial inputs to greater attention engagement.
What carries the argument
The two-pathway framework, where embeddings represent semantic content and hidden-state trajectories represent processing dynamics.
If this is right
- Detection strategies must be chosen according to whether OOD text overlaps in vocabulary with normal text.
- Processing trajectories provide signals for covert-intent cases that embeddings overlook.
- Early-layer embeddings largely reflect length rather than true distributional properties.
- Adversarial OOD tasks engage attention circuits more strongly than semantic shifts.
Where Pith is reading between the lines
- Hybrid detectors that combine both pathways could improve robustness across varied OOD scenarios.
- The pathway distinction may extend to diagnosing other LLM issues such as hallucinations.
- Length-matching deconfounding could apply to evaluations of model behaviors beyond OOD detection.
- Trajectory features offer a new angle for mechanistic studies of how models handle unexpected inputs.
Load-bearing premise
That length-matched evaluation fully isolates genuine OOD signals without new biases and that performance differences reflect a vocabulary-transparency spectrum rather than other factors.
What would settle it
A length-matched experiment in which embedding and trajectory methods show no consistent crossover or differential performance across OOD types.
Figures


read the original abstract
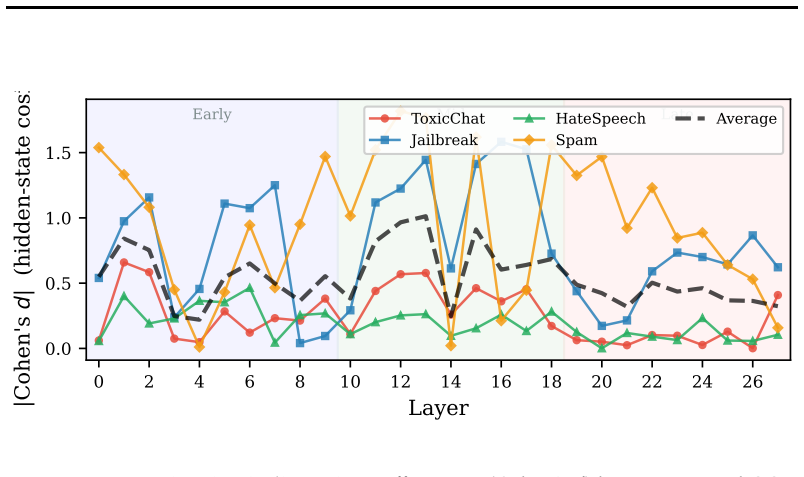
Recent white-box OOD detection methods for LLMs -- including CED, RAUQ, and WildGuard confidence scores -- appear effective, but we show they are structurally confounded by sequence length (|r| >= 0.61) and collapse to near-chance under length-matched evaluation. Even raw attention entropy (mean H(alpha) across heads and layers), a natural baseline we include for completeness, shows the same confound. The confound stems from attention's Theta(log T) dependence on input length. To identify genuine OOD signals after deconfounding, we propose a two-pathway framework: embeddings capture what text is about (effective for topic shifts), while the processing trajectory -- hidden-state evolution across layers -- captures how the model processes input. The relative power of each pathway varies along a vocabulary-transparency spectrum: embedding methods excel on vocabulary-distinctive OOD, while trajectory features detect covert-intent inputs that share vocabulary with normal text (0.721 avg AUROC; Jailbreak: 0.850). Three evidence lines support this framework: (1) a crossover between k-NN and trajectory scoring across 6 tasks, where each pathway wins on different OOD types; (2) a per-layer analysis showing that layer-0 k-NN signal is almost entirely a length artifact (Jailbreak: 0.759 raw -> 0.389 matched) -- processing constructs genuine OOD signal from near-chance embeddings; and (3) circuit attribution showing adversarial tasks engage attention circuits more than semantic tasks (p = 0.022; Jailbreak patching p < 0.001), with partial cross-model replication. Code release upon publication.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that white-box OOD detection methods for LLMs (CED, RAUQ, WildGuard, attention entropy) are structurally confounded by sequence length (|r| >= 0.61) and drop to near-chance under length-matched evaluation due to attention's Theta(log T) dependence. It proposes a two-pathway framework in which embeddings capture semantic content (effective for topic shifts and vocabulary-distinctive OOD) while processing trajectories (hidden-state evolution across layers) capture how the model processes input (effective for covert-intent OOD sharing vocabulary with ID text). The relative strength of each pathway is said to vary along a vocabulary-transparency spectrum, supported by three lines of evidence: crossover in k-NN vs. trajectory AUROC across 6 tasks (avg 0.721; Jailbreak 0.850), per-layer analysis showing layer-0 embeddings are largely length artifacts, and circuit attribution linking adversarial tasks to attention circuits (p=0.022; patching p<0.001) with partial cross-model replication.
Significance. If the central claims hold after addressing definitional and methodological gaps, the work would provide a useful mechanistic lens on LLM OOD processing that distinguishes content-based from trajectory-based signals. This could inform more reliable detectors for safety applications (e.g., jailbreak detection) and clarify why certain white-box scores succeed or fail. The convergent evidence from crossover, layer-wise, and circuit analyses is a strength if the spectrum can be shown to be independently predictive rather than descriptive.
major comments (2)
- [Abstract (framework and spectrum description)] Abstract (framework and spectrum description): the claim that pathway power 'varies along a vocabulary-transparency spectrum' lacks an a priori, independent metric for vocabulary transparency (such as pre-computed token-overlap statistics with ID data or embedding cosine distance to ID centroid). Tasks are instead labeled 'vocabulary-distinctive' or 'covert-intent' after observing which pathway wins, rendering the spectrum post-hoc and risking circularity in the central claim that the framework captures distinct mechanistic regimes.
- [Evidence line (2) (per-layer analysis)] Evidence line (2) (per-layer analysis): the reported length-matched drops (Jailbreak layer-0 k-NN: 0.759 raw to 0.389 matched) are used to argue that trajectories construct genuine OOD signal from near-chance embeddings, but the manuscript provides no explicit protocol for length-matching (pairing criteria, tolerance, impact on OOD diversity). Without this, it is unclear whether the procedure isolates genuine signals or introduces new selection biases that affect the interpretation of later-layer trajectory features.
minor comments (2)
- [Abstract] Abstract: 'partial cross-model replication' of circuit attribution is stated without naming the models, the fraction of results that replicate, or the exact attribution method, reducing the ability to assess robustness.
- [Abstract] Abstract: full definitions of trajectory features, exact AUROC computation details, and the six tasks are omitted, which hinders evaluation of the reported metrics (0.721 avg AUROC, p-values) even though the abstract supplies concrete numbers.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below, agreeing where revisions are needed to strengthen methodological transparency and reduce potential circularity. We believe these changes will clarify the framework without altering the core empirical findings.
read point-by-point responses
-
Referee: the claim that pathway power 'varies along a vocabulary-transparency spectrum' lacks an a priori, independent metric for vocabulary transparency (such as pre-computed token-overlap statistics with ID data or embedding cosine distance to ID centroid). Tasks are instead labeled 'vocabulary-distinctive' or 'covert-intent' after observing which pathway wins, rendering the spectrum post-hoc and risking circularity in the central claim that the framework captures distinct mechanistic regimes.
Authors: We acknowledge the risk of circularity noted here. The six OOD tasks were chosen a priori to represent distinct regimes (topic shifts with vocabulary differences versus covert-intent inputs sharing surface forms with ID text), and the spectrum was introduced to organize the observed crossover in pathway performance. However, to make the spectrum independently verifiable rather than derived solely from results, we will add pre-computed vocabulary-transparency metrics in the revision: average token overlap with the ID corpus and mean embedding cosine distance to the ID centroid, computed for each task prior to any detection experiments. These will be reported alongside the AUROC results to validate the spectrum. revision: yes
-
Referee: the reported length-matched drops (Jailbreak layer-0 k-NN: 0.759 raw to 0.389 matched) are used to argue that trajectories construct genuine OOD signal from near-chance embeddings, but the manuscript provides no explicit protocol for length-matching (pairing criteria, tolerance, impact on OOD diversity). Without this, it is unclear whether the procedure isolates genuine signals or introduces new selection biases that affect the interpretation of later-layer trajectory features.
Authors: We agree that the absence of an explicit length-matching protocol is a methodological gap that could affect interpretability. In the revised manuscript we will insert a dedicated subsection detailing the procedure: exact length pairing where possible (or within a tolerance of 5 tokens), the algorithm used to select matched subsets while preserving OOD category diversity, and quantitative checks on resulting dataset statistics. We will also add a sensitivity analysis showing that trajectory AUROCs remain stable across alternative tolerances, confirming that later-layer signals are not artifacts of the matching process. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper first demonstrates a length confound in prior OOD detectors via direct correlation measurements (|r| >= 0.61) and length-matched collapse to chance, then introduces the two-pathway framework as a deconfounded alternative motivated by that empirical observation. Support comes from three independent evidence lines (task-wise crossover in k-NN vs. trajectory AUROC, per-layer length-matched ablation, and circuit attribution with p-values), none of which reduce the reported AUROCs or the vocabulary-transparency description to quantities defined by the framework itself. No equations, fitted parameters, or self-citations are invoked to force the central claims; the spectrum is presented as a post-observation summary of where each pathway empirically excels rather than a definitional premise that tautologically produces the results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Attention mechanisms exhibit Theta(log T) dependence on sequence length T
invented entities (1)
-
Processing trajectory (hidden-state evolution across layers)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
The Bell System Technical Journal , volume=
A mathematical theory of communication , author=. The Bell System Technical Journal , volume=
-
[2]
The information bottleneck method
The information bottleneck method , author=. arXiv preprint physics/0004057 , year=
work page internal anchor Pith review arXiv
-
[3]
Opening the Black Box of Deep Neural Networks via Information
Opening the black box of deep neural networks via information , author=. arXiv preprint arXiv:1703.00810 , year=
-
[4]
ICLR , year=
Deep variational information bottleneck , author=. ICLR , year=
-
[5]
ACL , pages=
Analyzing multi-head self-attention: Specialized heads do the heavy lifting, the rest can be pruned , author=. ACL , pages=
-
[6]
Tenney, Ian and Das, Dipanjan and Pavlick, Ellie , booktitle=
-
[7]
ICML , pages=
On calibration of modern neural networks , author=. ICML , pages=
-
[8]
NeurIPS , year=
A simple unified framework for detecting out-of-distribution samples and adversarial attacks , author=. NeurIPS , year=
-
[9]
ICLR , year=
A baseline for detecting misclassified and out-of-distribution examples in neural networks , author=. ICLR , year=
-
[10]
ICML , year=
Out-of-distribution detection with deep nearest neighbors , author=. ICML , year=
-
[11]
NeurIPS , year=
Energy-based out-of-distribution detection , author=. NeurIPS , year=
-
[12]
NeurIPS , year=
Beyond Mahalanobis-Based Scores for Textual OOD Detection , author=. NeurIPS , year=
-
[13]
ICLR , year=
Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation , author=. ICLR , year=
-
[14]
Language Models (Mostly) Know What They Know
Language models (mostly) know what they know , author=. arXiv preprint arXiv:2207.05221 , year=
work page internal anchor Pith review arXiv
-
[15]
ACL Workshop BlackboxNLP , year=
What does BERT look at? An analysis of BERT's attention , author=. ACL Workshop BlackboxNLP , year=
-
[16]
ICLR , year=
Efficient Streaming Language Models with Attention Sinks , author=. ICLR , year=
-
[18]
Visualizing Data using t-
van der Maaten, Laurens and Hinton, Geoffrey , journal=. Visualizing Data using t-
-
[19]
2006 , publisher=
Gaussian processes for machine learning , author=. 2006 , publisher=
2006
-
[20]
ACM Computing Surveys , volume=
Survey of hallucination in natural language generation , author=. ACM Computing Surveys , volume=
-
[21]
A survey on uncertainty quantification of large language models,
A Survey on Uncertainty Quantification of Large Language Models: Taxonomy, Open Research Challenges, and Future Directions , author=. arXiv preprint arXiv:2412.05563 , year=
-
[22]
A survey of uncertainty estimation methods on large language models , author=. arXiv preprint arXiv:2503.00172 , year=
-
[24]
International Conference on Computational Science (ICCS) , year=
AggTruth: Contextual Hallucination Detection Using Aggregated Attention Scores in LLMs , author=. International Conference on Computational Science (ICCS) , year=
-
[25]
arXiv preprint arXiv:2601.03600 , year=
ALERT: Zero-shot LLM Jailbreak Detection via Internal Discrepancy Amplification , author=. arXiv preprint arXiv:2601.03600 , year=
-
[26]
Proceedings of the First Workshop on LLM Security , year=
Bypassing LLM guardrails: An empirical analysis of evasion attacks against prompt injection and jailbreak detection systems , author=. Proceedings of the First Workshop on LLM Security , year=
-
[27]
ACL , year=
ToxiGen: A Large-Scale Machine-Generated Dataset for Adversarial and Implicit Hate Speech Detection , author=. ACL , year=
-
[28]
NeurIPS Datasets and Benchmarks Track , year=
JailbreakBench: An Open Robustness Benchmark for Jailbreaking Large Language Models , author=. NeurIPS Datasets and Benchmarks Track , year=
-
[29]
ICML , year=
Using Pre-Training Can Improve Model Robustness and Uncertainty , author=. ICML , year=
-
[30]
EMNLP , year=
Contrastive Out-of-Distribution Detection for Pretrained Transformers , author=. EMNLP , year=
-
[31]
Ask me anything: A simple strategy for prompting language models,
Ask Me Anything: A simple strategy for prompting language models , author=. arXiv preprint arXiv:2210.02441 , year=
-
[32]
Representation Engineering: A Top-Down Approach to AI Transparency
Representation Engineering: A Top-Down Approach to AI Transparency , author=. arXiv preprint arXiv:2310.01405 , year=
work page internal anchor Pith review arXiv
-
[33]
ICLR , year=
Discovering Latent Knowledge in Language Models Without Supervision , author=. ICLR , year=
-
[34]
WWW , pages=
HSF: Defending against Jailbreak Attacks with Hidden State Filtering , author=. WWW , pages=
-
[35]
USENIX Security , year=
JBShield: Defending Large Language Models from Jailbreak Attacks through Activated Concept Analysis and Manipulation , author=. USENIX Security , year=
-
[36]
ICLR , year=
Calibrating Transformers via Sparse Gaussian Processes , author=. ICLR , year=
-
[37]
UAI , year=
Revisiting Kernel Attention with Correlated Gaussian Process Representation , author=. UAI , year=
-
[38]
EMNLP-IJCNLP , pages=
An Evaluation Dataset for Intent Classification and Out-of-Scope Prediction , author=. EMNLP-IJCNLP , pages=
-
[39]
EMNLP Findings , year=
ToxicChat: Unveiling Hidden Challenges of Toxicity Detection in Real-World User-AI Conversation , author=. EMNLP Findings , year=
-
[40]
ICWSM , pages=
Automated hate speech detection and the problem of offensive language , author=. ICWSM , pages=
-
[41]
ICML , pages=
Newsweeder: Learning to filter netnews , author=. ICML , pages=
-
[42]
Theory of Probability & Its Applications , volume=
On Estimating Regression , author=. Theory of Probability & Its Applications , volume=
-
[43]
Smooth Regression Analysis , author=. Sankhy
-
[44]
NeurIPS , year=
Toxicity Detection for Free , author=. NeurIPS , year=
-
[45]
EMNLP , year=
Comparing Embedding Differences for Detecting OOD and Hallucinated Text , author=. EMNLP , year=
-
[46]
NAACL , year=
A Survey of OOD Detection and Uncertainty Quantification for LLMs: From Hallucination to Safety , author=. NAACL , year=
-
[47]
arXiv preprint arXiv:2510.05991 , year=
Internal Layers for Jailbreak Detection in Large Language Models , author=. arXiv preprint arXiv:2510.05991 , year=
-
[48]
Transformer Circuits Thread , year=
A Mathematical Framework for Transformer Circuits , author=. Transformer Circuits Thread , year=
-
[49]
Transformer Circuits Thread , year=
In-context learning and induction heads , author=. Transformer Circuits Thread , year=
-
[50]
arXiv preprint arXiv:2401.12299 , year=
Universal Neurons in GPT2 Language Models , author=. arXiv preprint arXiv:2401.12299 , year=
-
[51]
ICLR , year=
DoLa: Decoding by Contrasting Layers Improves Factuality in Large Language Models , author=. ICLR , year=
-
[52]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Residual Stream Analysis of Overfitting and Structural Disruptions , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[53]
Ding, Yue and Zhu, Xiaofang and Xia, Tianze and Wu, Junfei and Chen, Xinlong and Liu, Qiang and Wang, Liang , journal=
-
[54]
Ettori, Lucas and Darabi, Sajjad and Tayebati, Fatemeh Haji Agha and Krishnan, Ramyar Saeedi and others , journal=
-
[55]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Embedding Trajectory for Out-of-Distribution Detection in Mathematical Reasoning , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[56]
Bailey, Luke and Ong, Alex and Batlle, Clement and Casper, Stephen and Grinsztajn, L. Obfuscated Activations Bypass. arXiv preprint arXiv:2412.09565 , year=
-
[57]
2025 , note=
Zhang, Ruotong and Bai, Yu and Zhang, Yanhao and Wang, Qibin and others , journal=. 2025 , note=
2025
-
[58]
arXiv preprint arXiv:2505.16562 , year=
Rethinking Jailbreak Detection with Representational Contrastive Scoring , author=. arXiv preprint arXiv:2505.16562 , year=
-
[59]
What features in prompts jailbreak
Kirch, Simon and Nolasco, Ioana Sas and Holtermann, Charissa and De Melo, Gerard , booktitle=. What features in prompts jailbreak. 2025 , note=
2025
-
[60]
Benchmarking
Vashurin, Roman and Fadeeva, Ekaterina and Vazhentsev, Artem and Tsvigun, Akim and Balagansky, Artem and Panov, Maxim and Petiushko, Alexander and Panchenko, Alexander and Shelmanov, Artem , journal=. Benchmarking. 2024 , note=
2024
-
[61]
Output Length Bias in
Ielanskyi, Sergei and others , journal=. Output Length Bias in. 2025 , note=
2025
-
[62]
ACM Computing Surveys , volume=
Bias and Fairness in Large Language Models: A Survey , author=. ACM Computing Surveys , volume=. 2024 , note=
2024
-
[63]
ACL , year=
Revisiting Uncertainty Quantification Evaluation in Language Models: Spurious Interactions with Response Length Bias Results , author=. ACL , year=
-
[64]
arXiv preprint , year=
X-Mahalanobis: Transformer Feature Mixing for Out-of-Distribution Detection , author=. arXiv preprint , year=
-
[65]
WildGuard: Open One-Stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of
Han, Seungju and Kim, Taesun and Kim, Hyunwoo and others , journal=. WildGuard: Open One-Stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of. 2024 , note=
2024
-
[66]
Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
Transformer Feed-Forward Layers Are Key-Value Memories , author=. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP) , pages=
2021
-
[67]
Locating and Editing Factual Associations in
Meng, Kevin and Bau, David and Andonian, Alex and Belinkov, Yonatan , booktitle=. Locating and Editing Factual Associations in
-
[68]
EMNLP , pages=
Types of Out-of-Distribution Texts and How to Detect Them , author=. EMNLP , pages=. 2021 , note=
2021
-
[69]
NeurIPS , year=
Exploring the Limits of Out-of-Distribution Detection , author=. NeurIPS , year=
-
[70]
arXiv preprint arXiv:2602.07253 , year=
From Out-of-Distribution Detection to Hallucination Detection: A Geometric View , author=. arXiv preprint arXiv:2602.07253 , year=
-
[71]
ICLR , year=
Enhancing the Reliability of Out-of-distribution Image Detection in Neural Networks , author=. ICLR , year=
-
[72]
NeurIPS , year=
Towards Automated Circuit Discovery for Mechanistic Interpretability , author=. NeurIPS , year=
-
[73]
2025 , note=
Zhang, Ziru and Hu, Xuchao and Zhang, Hanjie and Zhang, Jingwei and Chen, Xin and Liu, Qi , booktitle=. 2025 , note=
2025
-
[74]
Dissecting Attention and
Sharma, Kunal and Nema, Owais and Bharangar, Abhishek and Singh, Mohit and Tiwari, Shashank , booktitle=. Dissecting Attention and. 2024 , note=
2024
-
[75]
ACM CCS , year=
``Do Anything Now'': Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models , author=. ACM CCS , year=
-
[76]
Almeida, Tiago A. and G. Contributions to the study of. Proceedings of the 2011 ACM Symposium on Document Engineering , year=
2011
-
[77]
Advances in Neural Information Processing Systems , volume=
Character-level Convolutional Networks for Text Classification , author=. Advances in Neural Information Processing Systems , volume=
-
[78]
Almeida, Jos \'e Mar \'i a G \'o mez Hidalgo, and Akebo Yamakami
Tiago A. Almeida, Jos \'e Mar \'i a G \'o mez Hidalgo, and Akebo Yamakami. Contributions to the study of SMS spam filtering: New collection and results. Proceedings of the 2011 ACM Symposium on Document Engineering, 2011
2011
-
[79]
Types of out-of-distribution texts and how to detect them
Udit Arora, William Huang, and He He. Types of out-of-distribution texts and how to detect them. In EMNLP, pp.\ 10687--10701, 2021. Taxonomy of OOD text types (background shift, semantic shift) showing different types need different detection
2021
-
[80]
Automated hate speech detection and the problem of offensive language
Thomas Davidson, Dana Warmsley, Michael Macy, and Ingmar Weber. Automated hate speech detection and the problem of offensive language. In ICWSM, pp.\ 512--515, 2017
2017
-
[81]
arXiv preprint arXiv:2509.11569 (2025)
Yue Ding, Xiaofang Zhu, Tianze Xia, Junfei Wu, Xinlong Chen, Qiang Liu, and Liang Wang. D ^2 HScore : Reasoning-aware hallucination detection via semantic breadth and depth analysis in LLMs . arXiv preprint arXiv:2509.11569, 2025
-
[82]
A mathematical framework for transformer circuits
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, et al. A mathematical framework for transformer circuits. Transformer Circuits Thread, 2021. URL https://transformer-circuits.pub/2021/framework/index.html
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.