Recognition: unknown
InpaintSLat: Inpainting Structured 3D Latents via Initial Noise Optimization
Pith reviewed 2026-05-09 19:54 UTC · model grok-4.3
The pith
Optimizing the initial noise in structured 3D latent diffusion enables high-fidelity inpainting without training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
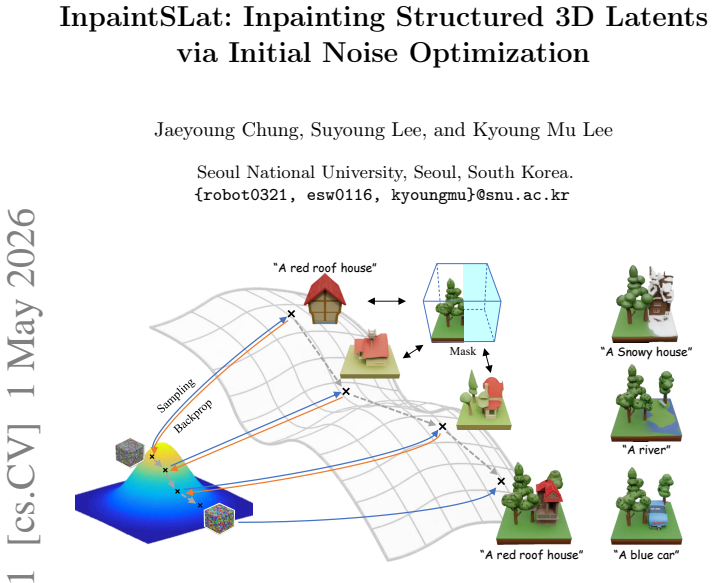
In the structured 3D latent diffusion framework, the underlying geometric structure is established during the early stages of the diffusion process and exhibits high sensitivity to the initial noise. We introduce a strategy to optimize the initial noise within the structured 3D latent diffusion framework, ensuring high-fidelity 3D inpainting. Specifically, we update the initial noise by leveraging a backpropagation approximation grounded in the rectified flow model, with the spectral parameterization specially designed for robust and efficient structured 3D latent optimization. Experiments demonstrate consistent improvements in contextual consistency and prompt alignment over representative
What carries the argument
Initial noise optimization that uses a backpropagation approximation from the rectified flow model together with spectral parameterization of the noise for structured 3D latents.
If this is right
- The method yields higher contextual consistency between the inpainted region and the existing 3D context.
- Prompt alignment improves without any model retraining.
- Initial noise optimization operates as a control dimension that is orthogonal to conventional changes in the diffusion sampling path.
Where Pith is reading between the lines
- The same early-structure sensitivity might be exploited for controllable 3D editing tasks beyond simple inpainting.
- Different 3D object categories could show varying degrees of benefit, suggesting a way to test how early geometry locking depends on scene complexity.
Load-bearing premise
The geometric structure of the 3D scene forms in the earliest diffusion steps and is so sensitive to the starting noise that adjusting that noise alone can force the inpainted region to match the surrounding context.
What would settle it
Quantitative metrics on 3D inpainting benchmarks show that the optimized initial noise produces no measurable gain in contextual consistency or prompt alignment compared with standard training-free baselines that only alter the sampling trajectory.
Figures









read the original abstract
We present a training-free approach for controllable 3D inpainting based on initial noise optimization. In the structured 3D latent diffusion framework, we observe that the underlying geometric structure is established during the early stages of the diffusion process and exhibits high sensitivity to the initial noise. Such characteristics compromise stability in tasks like inpainting and editing, where the model must ensure strict alignment with the existing context while synthesizing a new structure. In this paper, we introduce a strategy to optimize the initial noise within the structured 3D latent diffusion framework, ensuring high-fidelity 3D inpainting. Specifically, we update the initial noise by leveraging a backpropagation approximation grounded in the rectified flow model, with the spectral parameterization specially designed for robust and efficient structured 3D latent optimization. Experiments demonstrate consistent improvements in contextual consistency and prompt alignment over representative training-free inpainting baselines, establishing initial noise control as an independent dimension for 3D inpainting, orthogonal to conventional sampling trajectory manipulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents InpaintSLat, a training-free method for controllable 3D inpainting in structured latent diffusion models. It observes that geometric structure forms early in the diffusion process and is sensitive to initial noise, then proposes optimizing this noise via a backpropagation approximation derived from rectified flow models together with a spectral parameterization for efficient structured 3D latent updates. The central claim is that this yields high-fidelity inpainting with strict contextual alignment, shown via experiments to improve consistency and prompt adherence over representative training-free baselines.
Significance. If the approximation and optimization procedure are validated, the work would usefully identify initial-noise control as an orthogonal axis to sampling-trajectory manipulation for 3D inpainting and editing. The training-free character and focus on early-stage geometric sensitivity are potentially valuable for structured 3D tasks. However, the absence of any reported quantitative metrics, error analysis, or ablation results makes it impossible to assess whether the claimed gains are real or practically significant.
major comments (3)
- [Abstract and §3] Abstract and §3 (method): the claim that the backpropagation approximation 'ensures high-fidelity 3D inpainting' and 'strict alignment with existing context' rests on an un-derived and un-verified approximation; no error bounds, convergence analysis, or empirical check against non-linear denoising steps in high-dimensional structured latents are supplied, which is load-bearing for the central claim.
- [Abstract and §4] Abstract and §4 (experiments): 'consistent improvements in contextual consistency and prompt alignment' are asserted without any quantitative metrics, tables, error bars, or statistical comparisons; this directly undermines evaluation of whether the method outperforms baselines or merely matches them.
- [§2 and §3] §2 and §3: the key assumption that 'the underlying geometric structure is established during the early stages of the diffusion process and exhibits high sensitivity to the initial noise' is stated without supporting ablation, sensitivity analysis, or verification on 3D structured data, leaving the motivation for initial-noise optimization ungrounded.
minor comments (2)
- [§3] Notation for the spectral parameterization and the precise form of the backpropagation approximation should be defined with explicit equations rather than descriptive prose.
- [Abstract and §1] The abstract and introduction would benefit from a short related-work paragraph distinguishing the proposed initial-noise optimization from prior noise-perturbation or inversion techniques in 2D/3D diffusion.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive criticism. We respond to each major comment below and outline the revisions we will make to address the concerns raised.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method): the claim that the backpropagation approximation 'ensures high-fidelity 3D inpainting' and 'strict alignment with existing context' rests on an un-derived and un-verified approximation; no error bounds, convergence analysis, or empirical check against non-linear denoising steps in high-dimensional structured latents are supplied, which is load-bearing for the central claim.
Authors: We appreciate the referee pointing out the need for stronger justification of the approximation. In §3, we derive the backpropagation approximation from the rectified flow formulation by linearizing the denoising process. However, we concur that error bounds and convergence analysis are missing. We will revise §3 to include a formal error analysis of the approximation and add empirical checks by comparing the approximated updates to those obtained via full backpropagation on representative 3D latent samples. This will be presented in a new subsection on approximation validation. revision: yes
-
Referee: [Abstract and §4] Abstract and §4 (experiments): 'consistent improvements in contextual consistency and prompt alignment' are asserted without any quantitative metrics, tables, error bars, or statistical comparisons; this directly undermines evaluation of whether the method outperforms baselines or merely matches them.
Authors: We acknowledge the validity of this criticism. The current experiments focus on visual comparisons and qualitative assessments of consistency and alignment. To provide a more objective evaluation, we will expand §4 with quantitative results, including metrics for contextual consistency (such as masked region reconstruction error) and prompt alignment (using CLIP-based scores), along with tables, error bars from multiple runs, and comparisons to baselines. These additions will be included in the revised manuscript. revision: yes
-
Referee: [§2 and §3] §2 and §3: the key assumption that 'the underlying geometric structure is established during the early stages of the diffusion process and exhibits high sensitivity to the initial noise' is stated without supporting ablation, sensitivity analysis, or verification on 3D structured data, leaving the motivation for initial-noise optimization ungrounded.
Authors: We agree that the motivation would benefit from explicit supporting evidence. While this observation motivated our approach and was verified informally during method development, we did not include a dedicated ablation in the original submission. In the revision, we will add a sensitivity analysis in §2, demonstrating how early diffusion steps affect geometric structure in 3D latents through controlled experiments varying the initial noise and measuring structural divergence. revision: yes
Circularity Check
No significant circularity; method builds on external rectified flow concepts
full rationale
The paper proposes a training-free 3D inpainting technique that optimizes initial noise in structured latent diffusion models using a backpropagation approximation grounded in the rectified flow framework plus a custom spectral parameterization. No load-bearing step reduces by construction to a fitted parameter inside the paper, a self-citation chain, or a renamed known result; the central claim rests on an empirical observation about early diffusion stages and is validated against external baselines rather than being tautological with its own inputs. The derivation therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
In: CVPR (2022)
Avrahami, O., Lischinski, D., Fried, O.: Blended diffusion for text-driven editing of natural images. In: CVPR (2022)
2022
-
[2]
arXiv preprint arXiv:2511.19985 (2025)
Baek, S., Dong, E., Namazifard, S., Matthews, M.J., Yi, K.M.: Sonic: Spectral op- timization of noise for inpainting with consistency. arXiv preprint arXiv:2511.19985 (2025)
-
[3]
ICML (2023)
Bar-Tal, O., Yariv, L., Lipman, Y., Dekel, T.: Multidiffusion: Fusing diffusion paths for controlled image generation. ICML (2023)
2023
-
[4]
Bińkowski, M., Sutherland, D.J., Arbel, M., Gretton, A.: Demystifying mmd gans. arXiv preprint arXiv:1801.01401 (2018)
work page internal anchor Pith review arXiv 2018
-
[5]
ICCV (2021)
Choi, J., Kim, S., Jeong, Y., Gwon, Y., Yoon, S.: Ilvr: Conditioning method for denoising diffusion probabilistic models. ICCV (2021)
2021
-
[6]
ICLR (2023)
Chung, H., Kim, J., Mccann, M.T., Klasky, M.L., Ye, J.C.: Diffusion posterior sampling for general noisy inverse problems. ICLR (2023)
2023
-
[7]
In: CVPR (2022)
Collins, J., Goel, S., Deng, K., Luthra, A., Xu, L., Gundogdu, E., Zhang, X., Vicente, T.F.Y., Dideriksen, T., Arora, H., et al.: Abo: Dataset and benchmarks for real-world 3d object understanding. In: CVPR (2022)
2022
-
[8]
Advances in neural information processing systems30(2017)
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., Hochreiter, S.: Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems30(2017)
2017
-
[9]
In: CVPR (2024)
Khanna, M., Mao, Y., Jiang, H., Haresh, S., Shacklett, B., Batra, D., Clegg, A., Undersander, E., Chang, A.X., Savva, M.: Habitat synthetic scenes dataset (hssd- 200): An analysis of 3d scene scale and realism tradeoffs for objectgoal navigation. In: CVPR (2024)
2024
-
[10]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Lin, C.H., Gao, J., Tang, L., Takikawa, T., Zeng, X., Huang, X., Kreis, K., Fidler, S., Liu, M.Y., Lin, T.Y.: Magic3d: High-resolution text-to-3d content creation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 300–309 (2023)
2023
-
[11]
In: CVPR (2022)
Lugmayr, A., Danelljan, M., Romero, A., Yu, F., Timofte, R., Van Gool, L.: Repaint: Inpainting using denoising diffusion probabilistic models. In: CVPR (2022)
2022
-
[12]
ICLR (2022)
Meng, C., He, Y., Song, Y., Song, J., Wu, J., Zhu, J.Y., Ermon, S.: Sdedit: Guided image synthesis and editing with stochastic differential equations. ICLR (2022)
2022
-
[13]
In: CVPR (2023)
Mokady, R., Hertz, A., Aberman, K., Pritch, Y., Cohen-Or, D.: Null-text inversion for editing real images using guided diffusion models. In: CVPR (2023)
2023
-
[14]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
DreamFusion: Text-to-3D using 2D Diffusion
Poole, B., Jain, A., Barron, J.T., Mildenhall, B.: Dreamfusion: Text-to-3d using 2d diffusion. arXiv preprint arXiv:2209.14988 (2022)
work page internal anchor Pith review arXiv 2022
-
[16]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[17]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ren, X., Huang, J., Zeng, X., Museth, K., Fidler, S., Williams, F.: Xcube: Large- scale 3d generative modeling using sparse voxel hierarchies. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 4209–4219 (2024)
2024
-
[18]
In: CVPR (2021) Title Suppressed Due to Excessive Length 15
Stojanov, S., Thai, A., Rehg, J.M.: Using shape to categorize: Low-shot learning with an explicit shape bias. In: CVPR (2021) Title Suppressed Due to Excessive Length 15
2021
-
[19]
Advances in neural information processing systems36, 8406–8441 (2023)
Wang, Z., Lu, C., Wang, Y., Bao, F., Li, C., Su, H., Zhu, J.: Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation. Advances in neural information processing systems36, 8406–8441 (2023)
2023
-
[20]
In: CVPR (2025)
Xiang, J., Lv, Z., Xu, S., Deng, Y., Wang, R., Zhang, B., Chen, D., Tong, X., Yang, J.: Structured 3d latents for scalable and versatile 3d generation. In: CVPR (2025)
2025
-
[21]
In: 2018 international conference on 3D vision (3DV)
Yuan, W., Khot, T., Held, D., Mertz, C., Hebert, M.: Pcn: Point completion network. In: 2018 international conference on 3D vision (3DV). pp. 728–737. IEEE (2018)
2018
-
[22]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Yuan, Y.J., Sun, Y.T., Lai, Y.K., Ma, Y., Jia, R., Gao, L.: Nerf-editing: geometry editing of neural radiance fields. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 18353–18364 (2022) Supplementary Materials for InpaintSLat: Inpainting Structured 3D Latents via Noise Optimization S1 Additional Experiment Results...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.