Recognition: unknown
Adaptive 3D-RoPE: Physics-Aligned Rotary Positional Encoding for Wireless Foundation Models
Pith reviewed 2026-05-09 18:44 UTC · model grok-4.3
The pith
Adaptive 3D-RoPE makes positional encoding dynamic and aligned with wireless channel physics to improve extrapolation and generalization in CSI models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
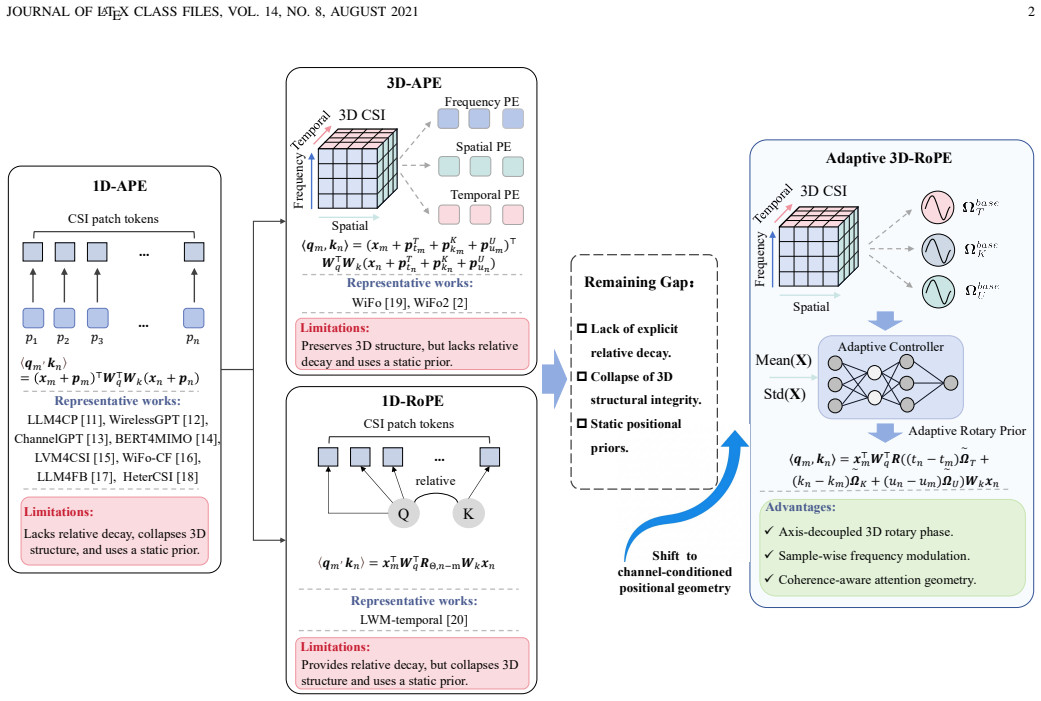
Adaptive 3D-RoPE integrates a learnable, axis-decoupled 3D frequency bank that disentangles multi-dimensional phase dependencies with a lightweight channel-conditioned controller that dynamically modulates the prior using global CSI descriptors, thereby converting positional encoding from a static component into a coherence-aware mechanism that better resolves heterogeneous channel physics.
What carries the argument
A learnable axis-decoupled 3D frequency bank coupled with a lightweight channel-conditioned controller that adjusts the positional prior from compact global CSI descriptors.
If this is right
- Achieves up to 10.7 dB lower NMSE when extrapolating CSI models to eight times larger antenna arrays.
- Improves zero-shot NMSE by 1.07 dB across unseen mobility scenarios at fixed input scales.
- Delivers 0.90 dB better zero-shot NMSE when transferring from low-frequency to millimeter-wave bands.
- Supports more robust wireless foundation models for CSI modeling, latent characterization, and task prediction across heterogeneous conditions.
Where Pith is reading between the lines
- The same axis-decoupled adaptive mechanism could be tested on other multi-dimensional physical signals such as radar returns or acoustic fields.
- Replacing static positional priors with physics-conditioned ones may prove necessary for foundation models applied to engineering domains beyond wireless communications.
- An explicit comparison of the learned frequency bank against closed-form electromagnetic decay laws would clarify how much of the gain comes from data-driven adaptation versus built-in structure.
Load-bearing premise
A learnable axis-decoupled 3D frequency bank together with a lightweight channel-conditioned controller can capture the intrinsic physics of wireless channels and generalize without overfitting or scenario-specific retraining.
What would settle it
Performance on a held-out dataset with channel statistics outside the training distribution shows no reduction in NMSE compared with static RoPE baselines when antenna scale or mobility parameters are increased.
Figures





read the original abstract
Positional encoding plays a pivotal role in determin?ing the extrapolation and generalization performance of wireless foundation models for channel state information (CSI) modeling, latent characterization, and task-specific prediction. However, existing CSI models inherit static or one-dimensional positional priors from natural language and vision architectures, which fundamentally misalign with the intrinsic physics of wireless channels by lacking explicit relative decay, collapsing the 3D spatio-temporal-frequency structure, and remaining scenario?rigid. This paper proposes Adaptive 3D-RoPE, a physics-aligned rotary positional encoding that establishes the structural corner?stone for wireless foundation models. The framework integrates a learnable, axis-decoupled 3D frequency bank to explicitly disentangle multi-dimensional phase dependencies, coupled with a lightweight channel-conditioned controller that dynamically modulates the prior via compact global CSI descriptors. This sample-adaptive mechanism transforms positional encoding from a static transformer component into a dynamic, coherence-aware inductive bias to resolve heterogeneous channel physics. Extensive experiments across 100 datasets demonstrate the superiority of the proposed scheme in both scale extrapolation and zero-shot generalization. Compared to the state-of-the-art, our method achieves up to a 10.7 dB reduction in normalized mean square error (NMSE) under 8 times antenna scale extrapolation. Given the same CSI input scales, our method can also improve zero-shot NMSE by 1.07 dB across unseen mobility scenarios and 0.90 dB in low-frequency-to-millimeter-wave tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Adaptive 3D-RoPE, a physics-aligned rotary positional encoding for wireless foundation models applied to CSI modeling. It replaces static 1D priors with a learnable axis-decoupled 3D frequency bank that disentangles spatio-temporal-frequency phase dependencies, combined with a lightweight channel-conditioned controller that modulates the encoding using compact global CSI descriptors. Experiments across 100 datasets report up to 10.7 dB NMSE reduction versus SOTA under 8x antenna scale extrapolation, plus 1.07 dB and 0.90 dB zero-shot gains in unseen mobility and low-to-mmWave frequency tasks.
Significance. If the empirical gains hold under the reported conditions, the work supplies a concrete inductive bias for wireless foundation models that directly targets the 3D structure and relative decay of wireless channels. The scale of validation (100 datasets) and the focus on extrapolation/zero-shot settings make the result potentially impactful for CSI prediction and related tasks, provided the architecture remains stable when the controller and frequency bank are deployed outside the training distribution.
major comments (2)
- [§4] §4 (Adaptive 3D-RoPE formulation): the claim that the frequency bank supplies an 'independent physics prior' is not fully supported by the description, because both the bank and the controller are optimized end-to-end on the same CSI data used for the downstream task. A concrete test (e.g., freezing the bank after pre-training on a physics simulator and measuring degradation on real data) would strengthen the distinction between learned parameters and genuine inductive bias.
- [Table 2, §5.3] Table 2 and §5.3 (zero-shot mobility and frequency-band results): the 1.07 dB and 0.90 dB improvements are reported without error bars or dataset-exclusion criteria. Because the controller receives CSI descriptors at inference time, it is essential to document that the 'unseen' scenarios truly lie outside the support of the training distribution; otherwise the gains could partly reflect interpolation rather than extrapolation.
minor comments (2)
- [Abstract] Abstract contains apparent typographical artifacts ('determ?ining', 'corner?stone', 'scenario?rigid'); these should be cleaned before publication.
- [§3-4] Notation for the 3D frequency bank (e.g., symbols for per-axis frequencies and the modulation function) should be introduced once and used consistently in equations and prose.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive overall assessment of our work. We address each major comment point-by-point below, indicating where revisions will be made to improve clarity and rigor.
read point-by-point responses
-
Referee: [§4] §4 (Adaptive 3D-RoPE formulation): the claim that the frequency bank supplies an 'independent physics prior' is not fully supported by the description, because both the bank and the controller are optimized end-to-end on the same CSI data used for the downstream task. A concrete test (e.g., freezing the bank after pre-training on a physics simulator and measuring degradation on real data) would strengthen the distinction between learned parameters and genuine inductive bias.
Authors: We appreciate this observation. The physics-aligned aspect of the frequency bank lies in its axis-decoupled 3D structure, which explicitly disentangles phase dependencies along the spatial, temporal, and frequency dimensions that are physically independent in wireless propagation (as opposed to the collapsed 1D priors in prior CSI models). While the specific frequency values are indeed learned jointly with the controller and downstream task, this structural inductive bias remains distinct from purely data-driven encodings. We agree the manuscript description can be strengthened on this point. In the revision we will expand §4 to clarify that the 'independent physics prior' refers to the axis-decoupled formulation rather than claiming the learned values are frozen or simulator-derived. The suggested freezing experiment after simulator pre-training would provide valuable additional evidence but requires new high-fidelity simulation infrastructure and compute not available in the present study; we will note it as future work. revision: partial
-
Referee: [Table 2, §5.3] Table 2 and §5.3 (zero-shot mobility and frequency-band results): the 1.07 dB and 0.90 dB improvements are reported without error bars or dataset-exclusion criteria. Because the controller receives CSI descriptors at inference time, it is essential to document that the 'unseen' scenarios truly lie outside the support of the training distribution; otherwise the gains could partly reflect interpolation rather than extrapolation.
Authors: We agree that reporting error bars and explicit exclusion criteria is necessary to substantiate the zero-shot claims. In the revised manuscript we will add standard-deviation error bars (computed over multiple random seeds and dataset folds) to the 1.07 dB and 0.90 dB entries in Table 2 and the accompanying text in §5.3. We will also append a dedicated paragraph detailing the dataset partitioning: the 100 datasets were split such that unseen mobility scenarios use velocity and trajectory distributions with no overlap to training, and the low-to-mmWave frequency shifts use carrier frequencies outside the training band support. This documentation will confirm that the controller operates on truly out-of-distribution CSI descriptors at inference. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's central claims rest on empirical validation across 100 datasets, reporting specific NMSE gains in antenna scale extrapolation and zero-shot generalization tasks. The learnable frequency bank and channel-conditioned controller are architectural components trained end-to-end on CSI data, but the reported performance improvements are measured on held-out test conditions (unseen scales, mobility scenarios, frequency bands) rather than being algebraically forced by the training inputs or by self-citation. No equations or derivation steps in the abstract reduce the claimed physics-aligned inductive bias to a tautological fit; the method is presented as an inductive bias whose value is demonstrated externally.
Axiom & Free-Parameter Ledger
free parameters (2)
- learnable 3D frequency bank
- channel-conditioned controller parameters
axioms (1)
- domain assumption Existing CSI models inherit static or one-dimensional positional priors that fundamentally misalign with wireless channel physics by lacking explicit relative decay and collapsing the 3D structure.
invented entities (1)
-
channel-conditioned controller
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Towards 6G wireless communication networks: Vision, enabling technologies, and new paradigm shifts,
X. You, C.-X. Wang, J. Huang, X. Gao, Z. Zhang, M. Wang, Y . Huang, C. Zhang, Y . Jiang, J. Wanget al., “Towards 6G wireless communication networks: Vision, enabling technologies, and new paradigm shifts,” Science China Information Sciences, vol. 64, no. 1, p. 110301, 2021
2021
-
[2]
WiFo-2: a generalist foundation model unifies heterogeneous wireless system design
B. Liu, X. Liu, S. Gao, X. Cheng, and L. Yang, “Foundation model for intelligent wireless communications,”arXiv preprint arXiv:2511.22222, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
AI-driven channel state information (CSI) extrapolation for 6G: Current situations, challenges and future research,
Y . Gao, Z. Lu, X. Wu, W. Yu, S. Liu, J. Du, Y . Jin, S. Zhang, X. Chu, and S. Xu, “AI-driven channel state information (CSI) extrapolation for 6G: Current situations, challenges and future research,”IEEE Commu- nications Surveys & Tutorials, 2026
2026
-
[4]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” inAdvances in Neural Information Processing Systems (NeurIPS), vol. 30, 2017
2017
-
[5]
Self-attention with relative position representations,
P. Shaw, J. Uszkoreit, and A. Vaswani, “Self-attention with relative position representations,” inProceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), 2018, pp. 464–468
2018
-
[6]
Exploring the limits of transfer learning with a unified text-to-text transformer,
C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y . Zhou, W. Li, and P. J. Liu, “Exploring the limits of transfer learning with a unified text-to-text transformer,”Journal of Machine Learning Research (JMLR), vol. 21, no. 140, pp. 1–67, 2020
2020
-
[7]
RoFormer: En- hanced transformer with rotary position embedding,
J. Su, M. Ahmed, Y . Lu, S. Pan, W. Bo, and Y . Liu, “RoFormer: En- hanced transformer with rotary position embedding,”Neurocomputing, vol. 568, p. 127063, 2024
2024
-
[8]
Rotary position embedding for vision transformer,
B. Heo, S. Park, D. Han, and S. Yun, “Rotary position embedding for vision transformer,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 289–305
2024
-
[9]
VideoRoPE: What makes for good video rotary position embedding?
X. Wei, X. Liu, Y . Zang, X. Dong, P. Zhang, Y . Cao, J. Tong, H. Duan, Q. Guo, J. Wanget al., “VideoRoPE: What makes for good video rotary position embedding?”arXiv preprint arXiv:2502.05173, 2025
-
[10]
Learning the RoPEs: Better 2D and 3D position encodings with STRING,
C. Schenck, P. Agrawal, P. Isola, and A. Torralba, “Learning the RoPEs: Better 2D and 3D position encodings with STRING,”arXiv preprint arXiv:2502.02324, 2025
-
[11]
LLM4CP: Adapting large language models for channel prediction,
B. Liu, X. Liu, S. Gao, X. Cheng, and L. Yang, “LLM4CP: Adapting large language models for channel prediction,”Journal of Communica- tions and Information Networks, vol. 9, no. 2, pp. 113–125, 2024
2024
-
[12]
WirelessGPT: A generative pre-trained multi-task learning framework for wireless communication,
T. Yang, P. Zhang, M. Zheng, Y . Shi, L. Jing, J. Huang, and N. Li, “WirelessGPT: A generative pre-trained multi-task learning framework for wireless communication,”IEEE Network, 2025
2025
-
[13]
ChannelGPT: A large model to generate digital twin chan- nel for 6G environment intelligence,
L. Yu, L. Shi, J. Zhang, J. Wang, Z. Zhang, Y . Zhang, and G. Liu, “ChannelGPT: A large model to generate digital twin channel for 6G environment intelligence,”arXiv preprint arXiv:2410.13379, 2024
-
[14]
F. O. Catak, M. Kuzlu, and U. Cali, “BERT4MIMO: A foundation model using BERT architecture for massive MIMO channel state information (CSI) prediction,”arXiv preprint arXiv:2501.01802, 2025
-
[15]
LVM4CSI: Enabling direct application of pre-trained large vision models for wireless channel tasks,
J. Guo, P. Jiang, C.-K. Wen, S. Jin, and J. Zhang, “LVM4CSI: Enabling direct application of pre-trained large vision models for wireless channel tasks,”arXiv preprint arXiv:2507.05121, 2025
-
[16]
WiFo-CF: Wireless foundation model for CSI feedback,
X. Liu, S. Gao, B. Liu, X. Cheng, and L. Yang, “WiFo-CF: Wireless foundation model for CSI feedback,”arXiv preprint arXiv:2508.04068, 2025
-
[17]
LLM4FB: A one-sided CSI feedback and prediction framework for lightweight UEs via large language models,
X. Xie, X. Ning, Y . Liu, H. Wang, J. Jin, and H. Yang, “LLM4FB: A one-sided CSI feedback and prediction framework for lightweight UEs via large language models,”Sensors, vol. 26, no. 2, p. 691, 2026
2026
-
[18]
C. Zhang, X. Lyu, C. Ren, S. Liu, Q. Cui, and X. Tao, “HeterCSI: Channel-adaptive heterogeneous CSI pretraining framework for gener- alized wireless foundation models,”arXiv preprint arXiv:2601.18200, 2026
-
[19]
WiFo: Wireless foundation model for channel prediction,
B. Liu, S. Gao, X. Liu, X. Cheng, and L. Yang, “WiFo: Wireless foundation model for channel prediction,”Science China Information Sciences, vol. 68, no. 6, p. 162302, 2025
2025
-
[20]
Lwm- temporal: Sparse spatio-temporal attention for wireless channel represen- tation learning,
S. Alikhani, A. Malhotra, S. Hamidi-Rad, and A. Alkhateeb, “LWM- Temporal: Sparse spatio-temporal attention for wireless channel repre- sentation learning,”arXiv preprint arXiv:2603.10024, 2026
-
[21]
Towards massive MIMO 2.0: Understanding spatial correlation, interference suppression, and pilot contamination,
L. Sanguinetti, E. Bj ¨ornson, and J. Hoydis, “Towards massive MIMO 2.0: Understanding spatial correlation, interference suppression, and pilot contamination,”IEEE Transactions on Communications, vol. 68, no. 1, pp. 232–257, 2020
2020
-
[22]
Characterization of randomly time-variant linear channels,
P. Bello, “Characterization of randomly time-variant linear channels,” IEEE Transactions on Communications Systems, vol. 11, no. 4, pp. 360– 393, 1963
1963
-
[23]
A statistical theory of mobile-radio reception,
R. H. Clarke, “A statistical theory of mobile-radio reception,”Bell System Technical Journal, vol. 47, no. 6, pp. 957–1000, 1968
1968
-
[24]
Tse and P
D. Tse and P. Viswanath,Fundamentals of Wireless Communication. Cambridge University Press, 2005
2005
-
[25]
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
O. Press, N. A. Smith, and M. Lewis, “Train short, test long: Attention with linear biases enables input length extrapolation,”arXiv preprint arXiv:2108.12409, 2022
work page internal anchor Pith review arXiv 2022
-
[26]
A length-extrapolatable transformer,
Y . Sun, L. Dong, B. Patra, S. Ma, S. Huang, A. Benhaim, V . Chaudhary, X. Song, and F. Wei, “A length-extrapolatable transformer,” inProceed- ings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Toronto, Canada: Association for Computational Linguistics, 2023, pp. 14 590–14 604
2023
-
[27]
Round and round we go! what makes rotary positional encodings useful?, 2025
F. Barbero, A. Vitvitskyi, C. Perivolaropoulos, R. Pascanu, and P. Veliˇckovi´c, “Round and round we go! what makes rotary positional encodings useful?”arXiv preprint arXiv:2410.06205, 2024
-
[28]
HoPE: A novel posi- tional encoding without long-term decay for enhanced context awareness and extrapolation,
Y . Chen, A. Lv, J. Luan, B. Wang, and W. Liu, “HoPE: A novel posi- tional encoding without long-term decay for enhanced context awareness and extrapolation,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 2025, pp. 23 044–23 057
2025
-
[29]
Extending Context Window of Large Language Models via Positional Interpolation
S. Chen, S. Wong, L. Chen, and Y . Tian, “Extending context window of large language models via positional interpolation,”arXiv preprint arXiv:2306.15595, 2023
work page internal anchor Pith review arXiv 2023
-
[30]
YaRN: Efficient context window extension of large language models,
B. Peng, J. Quesnelle, H. Fan, and E. Shippole, “YaRN: Efficient context window extension of large language models,” inInternational Conference on Learning Representations (ICLR), 2024
2024
-
[31]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Geet al., “Qwen2-VL: Enhancing vision-language models’ perception of the world at any resolution,”arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
VRoPE: Rotary position embedding for video large language models,
Z. Liu, L. Guo, Y . Tang, T. Yue, J. Cai, K. Ma, Q. Liu, X. Chen, and J. Liu, “VRoPE: Rotary position embedding for video large language models,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing. Suzhou, China: Association for Computational Linguistics, 2025, pp. 14 460–14 472
2025
-
[33]
H. Li, Y . Qin, B. Ou, L. Xu, and R. Xu, “HoPE: Hybrid of position embedding for length generalization in vision-language models,”arXiv preprint arXiv:2505.20444, 2025
-
[34]
Liere: Lie rotational positional encodings.arXiv preprint arXiv:2406.10322, 2024
S. Ostmeier, S. Chanda, M. Tancik, K. Saab, A. Gu, and C. R ´e, “LieRE: Lie rotational positional encodings,”arXiv preprint arXiv:2406.10322, 2024
-
[35]
LongRoPE: Extending LLM Context Window Beyond 2 Million Tokens
Y . Ding, L. L. Zhang, C. Zhang, Y . Xu, N. Shang, J. Xu, F. Yang, and M. Yang, “LongRoPE: Extending LLM context window beyond 2 million tokens,”arXiv preprint arXiv:2402.13753, 2024
work page internal anchor Pith review arXiv 2024
-
[36]
Context-Aware rotary position embedding,
A. Veisi, D. Fartoot, and H. Amirzadeh, “Context-Aware rotary position embedding,”arXiv preprint arXiv:2507.23083, 2025
-
[37]
Least square estimation-based different fast fading channel models in MIMO-OFDM systems,
W. Hussein, K. Audah, N. Noordin, H. Kraiem, A. Flah, M. Fadlee, and A. Ismail, “Least square estimation-based different fast fading channel models in MIMO-OFDM systems,”International Transactions on Electrical Energy Systems, vol. 2023, no. 1, p. 5547634, 2023
2023
-
[38]
MMSE channel estima- tion in large-scale MIMO: Improved robustness with reduced complex- ity,
G. Bacci, A. A. D’Amico, and L. Sanguinetti, “MMSE channel estima- tion in large-scale MIMO: Improved robustness with reduced complex- ity,”IEEE Transactions on Wireless Communications, vol. 23, no. 12, pp. 18 563–18 575, 2024. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 13
2024
-
[39]
Machine learning versus Kalman filtering for channel prediction in vehicular communica- tions,
M. Kim, J. Zhang, A. F. Molisch, and S.-C. Kwon, “Machine learning versus Kalman filtering for channel prediction in vehicular communica- tions,”IEEE Open Journal of the Communications Society, vol. 2, pp. 3–18, 2021
2021
-
[40]
Deep learning for fading channel prediction,
W. Jiang and H. D. Schotten, “Deep learning for fading channel prediction,”IEEE Open Journal of the Communications Society, vol. 1, pp. 320–332, 2020
2020
-
[41]
Machine learning-based channel prediction in massive MIMO with channel aging,
J. Yuan, H. Q. Ngo, and M. Matthaiou, “Machine learning-based channel prediction in massive MIMO with channel aging,”IEEE Transactions on Wireless Communications, vol. 19, no. 5, pp. 2960–2973, 2020
2020
-
[42]
Accurate channel prediction based on transformer: Making mobility negligible,
H. Jiang, M. Cui, D. W. K. Ng, and L. Dai, “Accurate channel prediction based on transformer: Making mobility negligible,”IEEE Journal on Selected Areas in Communications, vol. 40, no. 9, pp. 2717–2732, 2022
2022
-
[43]
Transformer network based channel prediction for CSI feedback en- hancement in AI-Native air interface,
T. Zhou, X. Liu, Z. Xiang, H. Zhang, B. Ai, L. Liu, and X. Jing, “Transformer network based channel prediction for CSI feedback en- hancement in AI-Native air interface,”IEEE Transactions on Wireless Communications, vol. 23, no. 9, pp. 11 154–11 167, 2024
2024
-
[44]
Big AI models for 6G wireless networks: Opportunities, challenges, and research directions,
Z. Chen, Z. Zhang, and Z. Yang, “Big AI models for 6G wireless networks: Opportunities, challenges, and research directions,”IEEE wireless communications, vol. 31, no. 5, pp. 164–172, 2024
2024
-
[45]
Z. Li, Q. Yang, Z. Xiong, Z. Shi, and T. Q. Quek, “Bridging the modality gap: Enhancing channel prediction with semantically aligned LLMs and knowledge distillation,”arXiv preprint arXiv:2505.12729, 2025
-
[46]
An image is worth 16x16 words: Trans- formers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Trans- formers for image recognition at scale,” inInternational Conference on Learning Representations (ICLR), 2021
2021
-
[47]
Masked au- toencoders are scalable vision learners,
K. He, X. Chen, S. Xie, Y . Li, P. Doll ´ar, and R. Girshick, “Masked au- toencoders are scalable vision learners,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 16 000–16 009
2022
-
[48]
PyTorch: An imperative style, high-performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lereret al., “PyTorch: An imperative style, high-performance deep learning library,” inAdvances in Neural Information Processing Systems, vol. 32, 2019, pp. 8024–8035
2019
-
[49]
QuaDRiGa: A 3-D multi-cell channel model with time evolution for enabling virtual field trials,
S. Jaeckel, L. Raschkowski, K. B ¨orner, and L. Thiele, “QuaDRiGa: A 3-D multi-cell channel model with time evolution for enabling virtual field trials,”IEEE Transactions on Antennas and Propagation, vol. 62, no. 6, pp. 3242–3256, 2014
2014
-
[50]
Deep learning for massive MIMO CSI feedback,
C.-K. Wen, W.-T. Shih, and S. Jin, “Deep learning for massive MIMO CSI feedback,”IEEE Wireless Communications Letters, vol. 7, no. 5, pp. 748–751, 2018
2018
-
[51]
Millimeter wave mobile communications for 5G cellular: It will work!
T. S. Rappaport, S. Sun, R. Mayzus, H. Zhao, Y . Azar, K. Wang, G. N. Wong, J. K. Schulz, M. Samimi, and F. Gutierrez, “Millimeter wave mobile communications for 5G cellular: It will work!”IEEE Access, vol. 1, pp. 335–349, 2013
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.