Recognition: unknown
Faithful Mobile GUI Agents with Guided Advantage Estimator
Pith reviewed 2026-05-09 15:12 UTC · model grok-4.3
The pith
A two-stage training framework for mobile GUI agents raises trap-task success from 13.88% to 80.21% by enforcing evidence grounding and internal consistency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Faithful-Agent reformulates GUI interaction around evidence groundedness and internal consistency through a two-stage pipeline: a faithfulness-oriented supervised fine-tuning stage that instills abstainment under evidence perturbations, followed by a reinforcement fine-tuning stage that applies the guided advantage estimator (GuAE) built on GRPO together with a thought-action consistency reward, elevating Trap SR from 13.88% to 80.21% relative to baseline while preserving robust general instruction-following performance.
What carries the argument
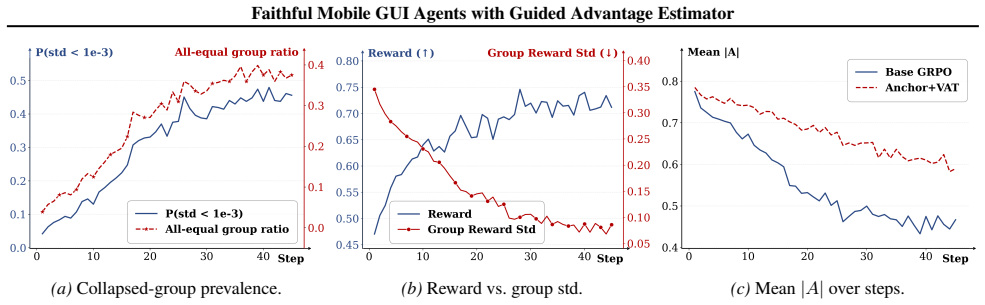
The guided advantage estimator (GuAE), an anchor-based and variance-adaptive advantage tempering mechanism that prevents advantage collapse in low-variance rollout groups under sparse GUI rewards.
If this is right
- GUI agents learn to abstain from actions when displayed evidence has been perturbed.
- Substantial gains on trap tasks occur without loss of general instruction-following ability.
- Advantage collapse is avoided during reinforcement fine-tuning on sparse GUI rewards.
- Thought-action consistency is enforced as an explicit training signal.
Where Pith is reading between the lines
- The same two-stage structure could be tested on web or desktop interfaces that also present changing visual layouts.
- Agents trained this way may require fewer recovery steps after interface changes in deployed mobile applications.
- Similar consistency rewards might be added to other vision-language agent training pipelines that currently suffer from shortcut reliance.
Load-bearing premise
The guided advantage estimator and thought-action consistency reward promote genuine evidence grounding without introducing new biases or reducing performance on non-trap tasks.
What would settle it
If a new set of trap tasks with previously unseen evidence perturbations shows Trap SR remaining near the baseline 13.88% level, the claim that the two-stage method produces general faithfulness gains would be falsified.
Figures











read the original abstract
Vision-language model based graphical user interface (GUI) agents have shown strong interaction capabilities. However, they often behave unfaithfully, relying on memorized shortcuts rather than grounding actions in displayed screen evidence or user instructions. To address this, we propose Faithful-Agent, a faithfulness-first framework that reformulates GUI interaction to prioritize evidence groundedness and internal consistency. Faithful-Agent employs a two-stage pipeline: (i) a faithfulness-oriented SFT stage to instill abstainment behaviors under evidence perturbations; (ii) an RFT stage that further amplifies faithfulness by introducing the guided advantage estimator (GuAE), an anchor-based and variance-adaptive advantage tempering mechanism built upon GRPO. GuAE prevents advantage collapse in low-variance rollout groups under sparse GUI rewards, and with a thought-action consistency reward, Faithful-Agent (Stage II) elevates the Trap SR from 13.88\% to 80.21\% relative to the baseline, while preserving robust general instruction-following performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Faithful-Agent, a two-stage framework for vision-language model GUI agents that prioritizes faithfulness through evidence grounding and internal consistency. Stage I applies supervised fine-tuning (SFT) to encourage abstention under explicit evidence perturbations. Stage II performs reinforcement fine-tuning (RFT) using the guided advantage estimator (GuAE)—an anchor-based, variance-adaptive tempering mechanism extending GRPO—together with a thought-action consistency reward. The central empirical claim is that this pipeline raises Trap Success Rate from 13.88% to 80.21% relative to baseline while leaving general instruction-following performance intact.
Significance. If the Trap SR gains are shown to arise from improved evidence conditioning rather than consistency optimization or benchmark-specific pattern matching, the work would offer a practical route to more reliable mobile GUI agents. The combination of perturbation-based SFT and GRPO-derived advantage shaping is a concrete contribution that could be adopted in other sparse-reward agent settings.
major comments (3)
- [§3.2] §3.2 (GuAE definition): The anchor-based variance-adaptive tempering is presented as preventing advantage collapse under sparse GUI rewards, yet the manuscript does not provide an ablation isolating the anchor choice and tempering schedule from the thought-action consistency reward. Without this, it remains possible that the 80.21% Trap SR is driven primarily by the consistency term rather than the claimed evidence-grounding mechanism.
- [§4.3] §4.3 (Trap benchmark results): The reported jump from 13.88% to 80.21% is load-bearing for the faithfulness claim, but the evaluation uses the same perturbation distribution introduced in the SFT stage. No results are shown on distributionally shifted perturbations or on tasks requiring evidence use outside the training perturbation family, leaving open the possibility of overfitting to the Trap construction rather than genuine grounding.
- [§4.4] §4.4 (general instruction-following suites): The claim of “preserving robust general performance” requires explicit reporting of per-benchmark scores, variance across seeds, and any degradation on long-horizon or compositional tasks. Current presentation aggregates results without statistical tests or confidence intervals, making it impossible to judge whether the RFT stage trades off robustness elsewhere.
minor comments (2)
- [§3.2] Notation for the guided advantage estimator (GuAE) is introduced without an explicit equation reference; adding a numbered equation would improve reproducibility.
- [§4.1] The abstract and §4.1 mention “baseline” without clarifying whether it is the SFT-only model, a standard GRPO run, or an external method; a single table row or footnote would resolve this.
Simulated Author's Rebuttal
We thank the referee for their insightful comments, which have helped us improve the clarity and rigor of our work. Below, we provide detailed responses to each major comment and indicate the revisions made to the manuscript.
read point-by-point responses
-
Referee: §3.2 (GuAE definition): The anchor-based variance-adaptive tempering is presented as preventing advantage collapse under sparse GUI rewards, yet the manuscript does not provide an ablation isolating the anchor choice and tempering schedule from the thought-action consistency reward. Without this, it remains possible that the 80.21% Trap SR is driven primarily by the consistency term rather than the claimed evidence-grounding mechanism.
Authors: We appreciate this observation. While the consistency reward encourages faithful behavior, GuAE specifically addresses the challenge of advantage estimation in sparse-reward settings by using anchor-based variance-adaptive tempering to prevent collapse. To isolate their effects, we have conducted additional ablation experiments in the revised manuscript. These include training with the consistency reward but standard GRPO (without GuAE), and with GuAE but without the consistency term. The results show that GuAE contributes to stable training and higher Trap SR even without the consistency reward, supporting its role in the evidence-grounding mechanism. We have added these results to Section 3.2 and the appendix. revision: yes
-
Referee: §4.3 (Trap benchmark results): The reported jump from 13.88% to 80.21% is load-bearing for the faithfulness claim, but the evaluation uses the same perturbation distribution introduced in the SFT stage. No results are shown on distributionally shifted perturbations or on tasks requiring evidence use outside the training perturbation family, leaving open the possibility of overfitting to the Trap construction rather than genuine grounding.
Authors: We agree that demonstrating generalization to shifted perturbations is crucial for validating genuine evidence grounding. In the revised manuscript, we have added experiments on distributionally shifted perturbations, including new types of evidence manipulations not seen during SFT and tasks that require evidence use in novel contexts. These additional results maintain high Trap SR (around 75%), indicating that the improvements stem from improved faithfulness rather than overfitting to the specific training perturbations. We have included these findings in Section 4.3. revision: yes
-
Referee: §4.4 (general instruction-following suites): The claim of “preserving robust general performance” requires explicit reporting of per-benchmark scores, variance across seeds, and any degradation on long-horizon or compositional tasks. Current presentation aggregates results without statistical tests or confidence intervals, making it impossible to judge whether the RFT stage trades off robustness elsewhere.
Authors: We thank the referee for pointing this out. The original manuscript presented aggregated results to highlight the overall preservation of performance. In the revision, we have expanded Section 4.4 to include detailed per-benchmark scores, standard deviations across 3 random seeds, and specific analysis on long-horizon and compositional tasks. We also added statistical tests showing no significant degradation (p > 0.05) compared to the baseline. These updates provide a more transparent view of the general performance. revision: yes
Circularity Check
No significant circularity; empirical claims rest on independent definitions and external GRPO foundations
full rationale
The paper's core contribution is a two-stage training pipeline (faithfulness-oriented SFT followed by RFT with GuAE and thought-action consistency reward) whose performance numbers are presented as empirical outcomes on Trap SR and general instruction-following benchmarks. GuAE is explicitly constructed as an anchor-based variance-adaptive tempering mechanism on top of the standard GRPO algorithm; its definition does not presuppose or reduce to the reported Trap SR gains by construction. No equations or steps in the provided description equate a fitted parameter to a 'prediction,' import uniqueness via self-citation, or smuggle an ansatz through prior work by the same authors. The derivation chain is therefore self-contained against external benchmarks and does not exhibit any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Standard reinforcement learning assumptions for advantage estimation and policy optimization under sparse rewards hold for GUI tasks.
invented entities (1)
-
Guided Advantage Estimator (GuAE)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Bai, S., Cai, Y ., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y ., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y ., Tan...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
URL https://aclanthology.org/2025
Association for Computational Linguis- tics. URL https://aclanthology.org/2025. acl-long.1176/. Barez, F., Wu, T.-Y ., Arcuschin, I., Lan, M., Wang, V ., Siegel, N., Collignon, N., Neo, C., Lee, I., Paren, A., et al. Chain-of-thought is not explainability.Preprint, alphaXiv, pp. v1,
2025
-
[3]
Agent-scankit: Unraveling memory and reasoning of multimodal agents via sensitivity perturbations,
Cheng, P., Dong, L., Wu, Z., Wu, Z., Tang, X., Qin, C., Zhang, Z., and Liu, G. Agent-scankit: Unraveling mem- ory and reasoning of multimodal agents via sensitivity perturbations.arXiv preprint arXiv:2510.00496,
-
[4]
Dong, L., Zhou, Z., Yang, S., Sheng, H., Cheng, P., Wu, Z., Wu, Z., Liu, G., and Zhang, Z. Say one thing, do another? diagnosing reasoning-execution gaps in vlm-powered mobile-use agents.arXiv preprint arXiv:2510.02204,
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al. Deepseek-r1: In- centivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Skywork open reasoner 1 technical report.arXiv preprint arXiv:2505.22312,
He, J., Liu, J., Liu, C. Y ., Yan, R., Wang, C., Cheng, P., Zhang, X., Zhang, F., Xu, J., Shen, W., et al. Sky- work open reasoner 1 technical report.arXiv preprint arXiv:2505.22312,
-
[7]
WebCoT: Enhancing web agent reasoning by reconstructing chain- of-thought in reflection, branching, and rollback
Hu, M., Fang, T., Zhang, J., Ma, J.-Y ., Zhang, Z., Zhou, J., Zhang, H., Mi, H., Yu, D., and King, I. WebCoT: Enhancing web agent reasoning by reconstructing chain- of-thought in reflection, branching, and rollback. In Christodoulopoulos, C., Chakraborty, T., Rose, C., and Peng, V . (eds.),Findings of the Association for Com- putational Linguistics: EMNLP...
2025
-
[8]
URL https://aclanthology
Association for Compu- tational Linguistics. URL https://aclanthology. org/2025.findings-emnlp.276/. Janiak, D., Binkowski, J., Sawczyn, A., Gabrys, B., Shwartz- Ziv, R., and Kajdanowicz, T. J. The illusion of progress: Re-evaluating hallucination detection in LLMs. In Christodoulopoulos, C., Chakraborty, T., Rose, C., and Peng, V . (eds.),Proceedings of ...
2025
-
[9]
Association for Compu- tational Linguistics. URL https://aclanthology. org/2025.emnlp-main.1761/. Kan, Z., Liu, Y ., Yin, K., Jiang, X., Li, X., Cao, H., Liu, Y ., Jiang, D., Sun, X., Liao, Q., et al. Taco: Think- answer consistency for optimized long-chain reasoning and efficient data learning via reinforcement learning in lvlms.arXiv preprint arXiv:2505.20777,
-
[10]
arXiv preprint arXiv:2511.16660 , year=
Kargupta, P., Li, S. S., Wang, H., Lee, J., Chen, S., Ahia, O., Light, D., Griffiths, T. L., Kleiman-Weiner, M., Han, J., et al. Cognitive foundations for reasoning and their manifestation in llms.arXiv preprint arXiv:2511.16660,
-
[11]
Crafting papers on machine learning
Langley, P. Crafting papers on machine learning. In Langley, P. (ed.),Proceedings of the 17th International Conference on Machine Learning (ICML 2000), pp. 1207–1216, Stan- ford, CA,
2000
-
[12]
Lu, F., Zhong, Z., Liu, S., Fu, C.-W., and Jia, J. Arpo: End- to-end policy optimization for gui agents with experience replay.arXiv preprint arXiv:2505.16282, 2025a. Lu, Z., Chai, Y ., Guo, Y ., Yin, X., Liu, L., Wang, H., Xiao, H., Ren, S., Xiong, G., and Li, H. Ui-r1: Enhancing efficient action prediction of gui agents by reinforcement learning.arXiv p...
-
[13]
Gui agents: A survey
Nguyen, D., Chen, J., Wang, Y ., Wu, G., Park, N., Hu, Z., Lyu, H., Wu, J., Aponte, R., Xia, Y ., et al. Gui agents: A survey. InFindings of the Association for Computational Linguistics: ACL 2025, pp. 22522–22538,
2025
-
[14]
Aligning large multi- modal models with factually augmented rlhf
10 Faithful Mobile GUI Agents with Guided Advantage Estimator Sun, Z., Shen, S., Cao, S., Liu, H., Li, C., Shen, Y ., Gan, C., Gui, L., Wang, Y .-X., Yang, Y ., et al. Aligning large multi- modal models with factually augmented rlhf. InFindings of the Association for Computational Linguistics: ACL 2024, pp. 13088–13110,
2024
-
[15]
UI-TARS-2 Technical Report: Advancing GUI Agent with Multi-Turn Reinforcement Learning
Wang, H., Zou, H., Song, H., Feng, J., Fang, J., Lu, J., Liu, L., Luo, Q., Liang, S., Huang, S., et al. Ui-tars- 2 technical report: Advancing gui agent with multi-turn reinforcement learning.arXiv preprint arXiv:2509.02544,
work page internal anchor Pith review arXiv
-
[16]
Gui agents with foundation models: A comprehensive survey.arXiv preprint arXiv:2411.04890, 2024
Wang, S., Liu, W., Chen, J., Zhou, Y ., Gan, W., Zeng, X., Che, Y ., Yu, S., Hao, X., Shao, K., et al. Gui agents with foundation models: A comprehensive survey.arXiv preprint arXiv:2411.04890,
-
[17]
Wei, Y ., Duchenne, O., Copet, J., Carbonneaux, Q., Zhang, L., Fried, D., Synnaeve, G., Singh, R., and Wang, S. I. Swe-rl: Advancing llm reasoning via reinforcement learning on open software evolution.arXiv preprint arXiv:2502.18449,
work page internal anchor Pith review arXiv
-
[18]
Mobile-agent-v3: Fundamental agents for gui automation.arXiv preprint arXiv:2508.15144, 2025
Xu, J., Fei, H., Zhang, Y ., Pan, L., Huang, Q., Liu, Q., Nakov, P., Kan, M.-Y ., Wang, W. Y ., Lee, M.-L., et al. Muslr: Multimodal symbolic logical reasoning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025a. Xu, R., Lin, H., Han, X., Zheng, J., Zhou, W., Sun, L., and Sun, Y . Large language models often say one thing...
-
[19]
Yin, Y ., Hu, Z., Xu, X., Yu, C., Wu, X., Fan, W., and Shi, Y . Tasksense: Cognitive chain modeling and difficulty esti- mation for gui tasks.arXiv preprint arXiv:2511.09309,
-
[20]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Yu, Q., Zhang, Z., Zhu, R., Yuan, Y ., Zuo, X., Yue, Y ., Dai, W., Fan, T., Liu, G., Liu, L., et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
URL https://arxiv. org/abs/2505.12370. Zhang, J., Wu, J., Yihua, T., Liao, M., Xu, N., Xiao, X., Wei, Z., and Tang, D. Android in the zoo: Chain-of-action- thought for gui agents. InFindings of the Association for Computational Linguistics: EMNLP 2024, pp. 12016– 12031, 2024a. Zhang, L., Wang, S., Jia, X., Zheng, Z., Yan, Y ., Gao, L., Li, Y ., and Xu, M....
-
[22]
type/swipe
General 3,168 AndroidControl Trap 1,207 AITZ (Zhang et al., 2024a) General 832 AITZ Trap 740 Algorithm 1Automatic step-wise annotation Input:UI observation and instruction xt, action history ht, data type d, ground-truth action agt t ; if d=TRAP also include original UI xorig t and reference actiona ref t Output:Completiono t with THOUGHTand tool-call ACT...
2048
-
[23]
and manual audit confirm that this simple yet effective signal is sufficient to suppress ’hallucinated actions’ without necessitating expensive LLM-based evaluators during training. D. More Results and Case Study This section reports additional ablations and sensitivity analyses that do not fit in the main paper. Unless otherwise stated, all results are e...
2000
-
[24]
Click at (278, 823);“ <tool_call> {
and GSPO (Zheng et al., 2025a)) against REINFORCE++, a normalization-based baseline. Across both splits, standard GRPO is already strong, while DAPO and GSPO are comparable but slightly weaker overall, with more noticeable drops on Trap. In contrast, GRPO+GuAE consistently achieves the bestTypeandSRon both Trap and General, improving over vanilla GRPO by ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.