Medmarks: A Comprehensive Open-Source LLM Benchmark Suite for Medical Tasks
Pith reviewed 2026-05-09 14:30 UTC · model grok-4.3
The pith
Medmarks supplies a fully open benchmark suite of 30 medical tasks to evaluate LLMs on question answering, extraction, calculations, and clinical reasoning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Medmarks is an open-source suite that standardizes evaluation across 30 tasks in question answering, information extraction, medical calculations, and open-ended clinical reasoning, with results from 61 models showing frontier reasoning systems at the top, proprietary models more token-efficient, fine-tuned medical models stronger than generalist counterparts, and widespread susceptibility to answer-order bias.
What carries the argument
The Medmarks benchmark suite itself, built from 30 verifiable tasks divided into question answering, information extraction, medical calculations, and open-ended clinical reasoning, scored with exact metrics plus LLM-as-a-Judge for the reasoning subset.
If this is right
- Frontier reasoning models such as Gemini 3 Pro Preview, GPT-5.1 and GPT-5.2 lead performance across the full set of tasks.
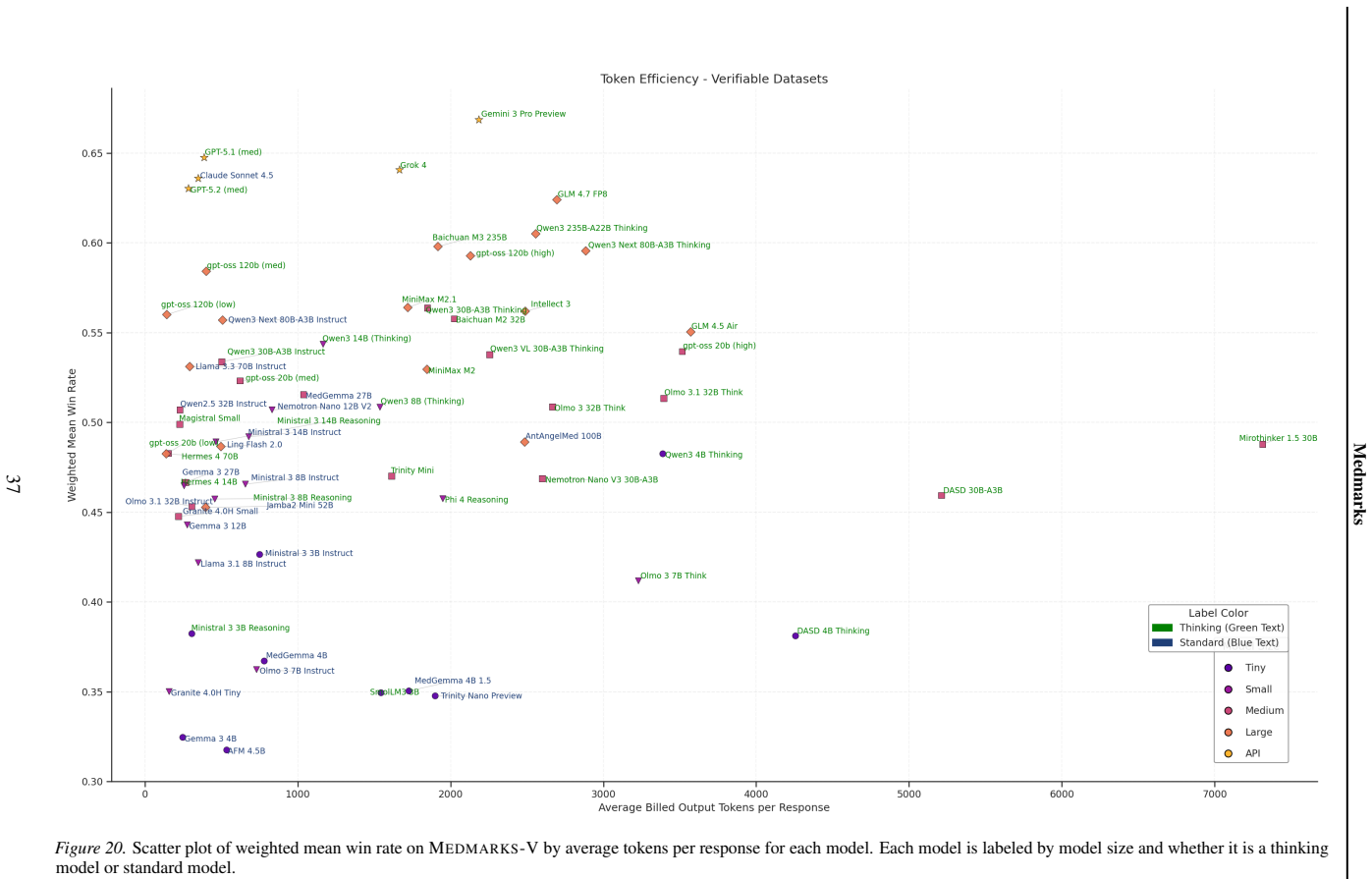
- Most proprietary frontier models consume significantly fewer tokens than open-weight alternatives on the same inputs.
- Models that have been fine-tuned on medical data outperform their generalist base versions on the benchmarks.
- Answer-order bias appears in many models, with smaller ones and Grok 4 showing it most clearly.
- The Medmarks-T subset supplies ready reinforcement-learning environments for post-training medical reasoning.
Where Pith is reading between the lines
- Standardized open benchmarks like this could let independent groups compare medical LLMs without depending on private datasets.
- Token-efficiency differences may become a practical selection criterion when deploying models in cost-sensitive clinical settings.
- Answer-order bias could be mitigated by randomizing option order or using chain-of-thought prompting that does not rely on multiple-choice formats.
Load-bearing premise
The 30 selected tasks together give a representative picture of the medical capabilities needed in real clinical use, and that LLM-as-a-Judge scoring is reliable enough for the open-ended reasoning tasks.
What would settle it
A new model that scores near the top on all 30 Medmarks tasks yet performs poorly when tested by human clinicians on the same task types in live settings would show the suite fails to capture essential medical performance.
Figures





















read the original abstract
Evaluating large language models (LLMs) for medical applications remains challenging due to benchmark saturation, limited data accessibility, and insufficient coverage of relevant tasks. Existing suites have either saturated, heavily depend on restricted datasets, or lack comprehensive model coverage. We introduce Medmarks, a fully open-source evaluation suite with 30 benchmarks spanning question answering, information extraction, medical calculations, and open-ended clinical reasoning. We perform a systematic evaluation of 61 models across 71 configurations using verifiable metrics and LLM-as-a-Judge. Our results show that frontier reasoning models (Gemini 3 Pro Preview, GPT-5.1, & GPT-5.2) achieve the highest performance across both benchmarks, most frontier proprietary models are significantly more token efficient than open-weight alternatives, medically fine-tuned models outperform their generalist counterparts, and that models are susceptible to answer-order bias (particularly smaller models and Grok 4). A subset of our evals (Medmarks-T) can be directly used as reinforcement learning environments to post-train LLMs for medical reasoning. Code is available at https://github.com/MedARC-AI/Medmarks
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Medmarks, a fully open-source benchmark suite consisting of 30 tasks spanning question answering, information extraction, medical calculations, and open-ended clinical reasoning. It reports a systematic evaluation of 61 models across 71 configurations using verifiable metrics and LLM-as-a-Judge, with key findings that frontier reasoning models (Gemini 3 Pro Preview, GPT-5.1, GPT-5.2) achieve the highest performance, proprietary frontier models are more token-efficient than open-weight alternatives, medically fine-tuned models outperform generalist counterparts, and models (especially smaller ones and Grok 4) exhibit answer-order bias. A subset of the benchmarks (Medmarks-T) is positioned for direct use as reinforcement learning environments.
Significance. If the central claims hold, Medmarks would constitute a useful, accessible addition to the medical LLM evaluation landscape by addressing benchmark saturation and data-access restrictions in prior suites. The open-source release, public code repository, and framing of a subset as RL environments are concrete strengths that could support reproducible research and post-training work. The scale of the model evaluation (61 models) also provides a broad snapshot of current capabilities.
major comments (2)
- [Abstract] Abstract: The primary results on model rankings for open-ended clinical reasoning tasks rest on LLM-as-a-Judge scores, yet no information is supplied on the specific judge model, prompt template, calibration procedure against expert physicians, or agreement statistics (e.g., Cohen's kappa or correlation with human ratings). In a safety-critical medical domain, this leaves open the possibility that scores reward stylistic features rather than clinical correctness, directly undermining the comparative claims.
- [Abstract] Abstract: The assertion that the 30 benchmarks provide comprehensive coverage of medical tasks is presented without supporting analysis of task selection criteria, overlap with existing saturated benchmarks, or gaps in clinical reasoning categories (e.g., differential diagnosis or longitudinal patient management). This choice is load-bearing for the claim of a 'comprehensive' suite.
minor comments (1)
- [Abstract] The abstract refers to 'verifiable metrics' for some tasks but does not enumerate which tasks use which metrics or provide example implementations; adding a brief table or reference to the code repository in the main text would improve clarity.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment below and outline the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: The primary results on model rankings for open-ended clinical reasoning tasks rest on LLM-as-a-Judge scores, yet no information is supplied on the specific judge model, prompt template, calibration procedure against expert physicians, or agreement statistics (e.g., Cohen's kappa or correlation with human ratings). In a safety-critical medical domain, this leaves open the possibility that scores reward stylistic features rather than clinical correctness, directly undermining the comparative claims.
Authors: We agree that transparency regarding the LLM-as-a-Judge is critical in a medical context to ensure scores reflect clinical correctness rather than style. The manuscript references LLM-as-a-Judge for open-ended tasks but does not supply the specific details requested. We will revise the Methods section to explicitly describe the judge model, the prompt template, any calibration steps against expert physicians, and quantitative agreement statistics (such as Cohen's kappa or correlation with human ratings). This addition will directly address the concern and allow readers to evaluate the reliability of the comparative claims. revision: yes
-
Referee: [Abstract] Abstract: The assertion that the 30 benchmarks provide comprehensive coverage of medical tasks is presented without supporting analysis of task selection criteria, overlap with existing saturated benchmarks, or gaps in clinical reasoning categories (e.g., differential diagnosis or longitudinal patient management). This choice is load-bearing for the claim of a 'comprehensive' suite.
Authors: We acknowledge that the 'comprehensive' framing requires explicit justification to be fully convincing. While the manuscript describes the 30 tasks as spanning question answering, information extraction, medical calculations, and open-ended clinical reasoning, it does not include a dedicated analysis of selection criteria, overlaps with prior benchmarks, or remaining gaps. In the revised manuscript, we will add a subsection (likely in the Introduction or a new 'Benchmark Design' section) that details the task selection process, compares coverage against saturated benchmarks (e.g., MedQA, PubMedQA, MMLU medical subsets), and explicitly discusses gaps such as differential diagnosis and longitudinal patient management. This will provide a clearer rationale for the suite's scope. revision: yes
Circularity Check
Empirical benchmark suite release with no derivations or self-referential predictions
full rationale
The paper presents Medmarks as an open-source collection of 30 benchmarks and reports empirical evaluations of 61 models using verifiable metrics and LLM-as-a-Judge. No equations, fitted parameters, uniqueness theorems, or derivation chains are claimed or present in the provided text. All results follow directly from running external models on the released benchmarks rather than reducing to internal definitions or self-citations. This is a standard data-release and evaluation paper whose central claims rest on observable model outputs, not on any circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
URL https://aclanthology.org/2025. naacl-long.182/. Chen, H., Fang, Z., Singla, Y ., and Dredze, M. Benchmark- ing large language models on answering and explaining challenging medical questions. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume...
-
[2]
URL https://aclanthology.org/2024. emnlp-main.759/. Loshchilov, I. and Hutter, F. Decoupled weight decay reg- ularization. InInternational Conference on Learning Representations, 2019. McCoy, L. G., Swamy, R., Sagar, N., Wang, M., Bacchi, S., Fong, J. M. N., Tan, N. C., Tan, K., Buckley, T. A., Brodeur, P., et al. Assessment of large language models in cl...
work page 2024
-
[3]
URL https://www.arcee.ai/blog/ deep-dive-afm-4-5b-the-first-arcee-foundational-model . Metlay, J. P., Waterer, G. W., Long, A. C., Anzueto, A., Brozek, J., Crothers, K., Cooley, L. A., Dean, N. C., Fine, M. J., Flanders, S. A., Griffin, M. R., Meter- sky, M. L., Musher, D. M., Restrepo, M. I., and Whit- ney, C. G. Diagnosis and Treatment of Adults with Co...
-
[4]
doi: 10.48550/arXiv.2503.07459. URL https: //arxiv.org/abs/2503.07459. Team, A. Antangelmed: A high-performance medical lan- guage model with efficient moe-powered clinical rea- soning, 2025a. URL https://huggingface.co/ MedAIBase/AntAngelMed. Team, B. M. Baichuan-m3: Modeling clinical in- quiry for reliable medical decision-making, 2025b. URL https://git...
-
[5]
MedConceptsQA (Shoham & Rappoport, 2024) and MedDialog (He et al., 2020) have 819K and 25k examples, respectively, so we only evaluate on a subset of these datasets. MedConceptsQA tests the model’s knowledge of 20 Medmarks Table 7.Medical benchmark datasets in MEDMARKSfor LLM evaluation. “–” indicates no dedicated training split. Dataset Description #Eval...
work page 2024
-
[6]
We only perform one run of HeadQA-v2 (Correa-Guill´en et al., 2025), MedCalc-Bench (Khandekar et al., 2024), and Med-HALT (Pal et al., 2023) instead of three. 21 Medmarks G. Models Table 8.Models evaluated in MEDMARKS. Size categories: Tiny ( <7B), Small (7–19B), Medium (20–40B), Large (>40B on single node), API (proprietary or multi-node). Model Size Sam...
work page 2025
-
[7]
Semantically Correct (true/false) - True if the assistant expresses the same core claim(s) as the reference. - Allow synonyms, paraphrasing, acronyms, and reasonable generalizations that still unambiguously answer the question correctly. - False if the main concept/mechanism/entity/relationship differs or if the answer is too vague to establish the refere...
-
[8]
Ignore extra illustrative or optional context in the reference
Matches Details (true/false) - True if the assistant includes all question-critical details needed to uniquely match the reference answer. Ignore extra illustrative or optional context in the reference. - False if any required specifics or details from the reference are missing, overgeneralized where precision matters, or incorrect. - Constraint: If Seman...
-
[9]
Substantive Addition (true/false) - True if the assistant introduces factual claim(s) that could meaningfully alter correctness assessment: tangential or off-topic content, claims or details beyond the question’s scope, or alternative explanations/approaches not consistent with the reference. - False for definitions, brief clarifying context, stylistic el...
-
[10]
Critical Error (true/false) - True if the assistant states any factual claim that is clearly false relative to the reference and/or standard domain knowledge, or gives unsafe medical guidance. - False if no clearly incorrect, contradictory, unsafe, or fabricated factual claims are present. - Note: Missing information alone is not a critical error (it affe...
work page 2025
-
[11]
TaskMCQA in English and Spanish
The English translation was performed using GPT-4, and the open-ended version was created via rephrasing with Qwen2.5-72B-Instruct, followed by human validation. TaskMCQA in English and Spanish. Open-Ended QA in English.; Inputs/OutputsQuestion→selected option or open-ended answer; Evaluation • Close-ended Evaluation - For close-ended evaluations, the met...
-
[12]
N-gram based metrics: ROUGE1, ROUGE2, ROUGEL, and BLEU - these evaluate the overlap of n-grams between generated and reference answers
-
[13]
Semantic similarity metrics: BERTScore, BLEURT, and MoverScore - these evaluate semantic similarity between generated and reference text using embeddings or deep learning models
-
[14]
Perplexity metrics: Word Perplexity, Bits per Byte, and Byte Perplexity - these assess the model’s predictive capabilities. Q.30. MTSamples-Procedures (Bedi et al., 2026) MTSamples Procedures is a benchmark composed of transcribed operative notes, focused on documenting surgical procedures. Each example presents a brief patient case involving a surgical i...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.