Recognition: 3 theorem links
· Lean TheoremStochastic Sparse Attention for Memory-Bound Inference
Pith reviewed 2026-05-08 19:16 UTC · model grok-4.3
The pith
SANTA sparsifies attention by sampling few value indices from the post-softmax distribution, yielding an unbiased estimator that replaces multiplies with adds and delivers 1.5x kernel speedup.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
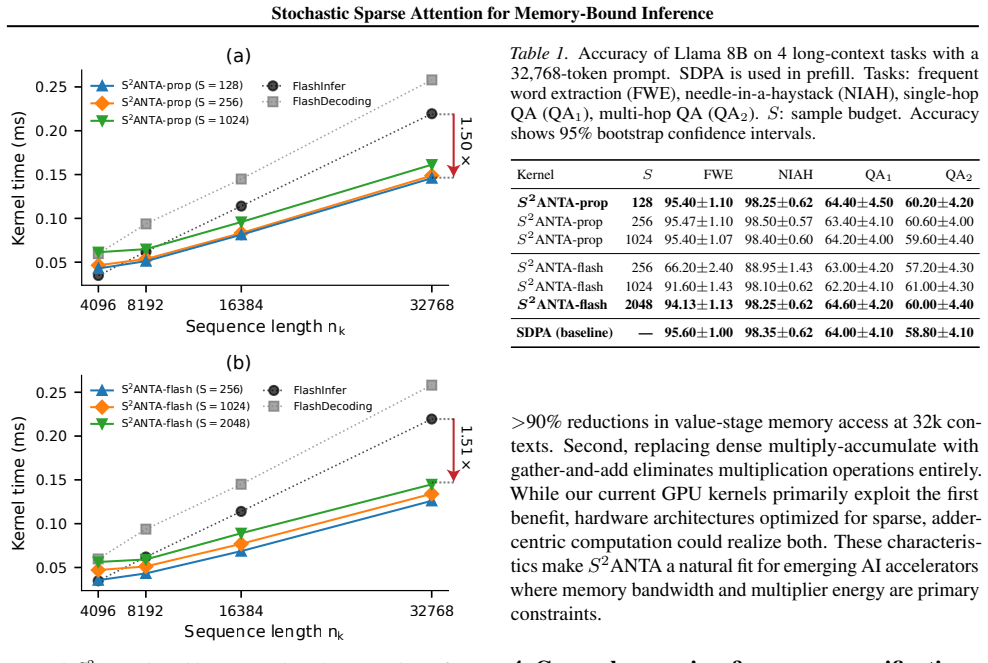
The central claim is that sampling S much smaller than the full number of keys from the post-softmax attention distribution produces an unbiased estimator for the value aggregation. Stratified sampling reduces variance to a level that preserves model accuracy, allowing the value stage to be implemented with gather-and-add rather than full multiply-accumulate. On an NVIDIA RTX 6000 Ada this yields a 1.5 times speedup in the decode-step attention kernel relative to FlashInfer and FlashDecoding while matching baseline accuracy at 32k contexts. A complementary Bernoulli qK^T sampling step can further reduce key-feature access in the score stage.
What carries the argument
Stochastic sampling of S indices from the post-softmax attention distribution, followed by gather-and-add aggregation of the corresponding value rows, with stratified sampling to control variance.
If this is right
- Value aggregation becomes an unbiased Monte Carlo estimate rather than an exact weighted sum.
- Value-stage arithmetic changes from multiply-accumulates to gather followed by simple additions.
- Stratified sampling keeps variance low enough to match dense accuracy at 32k contexts.
- The 1.5x kernel speedup is measured against FlashInfer and FlashDecoding on consumer GPUs.
- Bernoulli sampling of query-key scores can be combined to sparsify the earlier computation stage.
Where Pith is reading between the lines
- The reduction in memory traffic could translate to lower energy consumption for long-context inference on battery-powered devices.
- Further variance-reduction methods such as control variates might permit even smaller S without accuracy loss.
- The same sampling logic could be tested on encoder-only or non-autoregressive models to check whether the unbiased property generalizes.
Load-bearing premise
The variance introduced by sampling only S value vectors must remain low enough across layers and heads that downstream accuracy is unaffected at the chosen S.
What would settle it
Measure end-to-end accuracy or token-level perplexity on a 32k-context benchmark using the sampled attention kernel and compare directly to the dense baseline; any statistically significant drop would falsify the accuracy-preservation claim.
Figures








read the original abstract
Autoregressive decoding becomes bandwidth-limited at long contexts, as generating each token requires reading all $n_k$ key and value vectors from KV cache. We present Stochastic Additive No-mulT Attention (SANTA), a method that sparsifies value-cache access by sampling $S \ll n_k$ indices from the post-softmax distribution and aggregates only those value rows. This yields an unbiased estimator of the post-softmax value aggregation while replacing value-stage multiply-accumulates with gather-and-add. We introduce stratified sampling to design variance-reduced, GPU-friendly variants, demonstrating $1.5\times$ decode-step attention kernel speedup over FlashInfer and FlashDecoding on an NVIDIA RTX 6000 Ada while matching baseline accuracy at 32k-token contexts. Finally, we propose Bernoulli $qK^\mathsf{T}$ sampling as a complementary technique to sparsify the score stage, reducing key-feature access through stochastic ternary queries. Both methods are orthogonal to upstream techniques such as ternary quantization, low-rank projections, and KV-cache compression. Together, they point toward sparse, multiplier-free, and energy-efficient inference. We open-source our kernels at: https://github.com/OPUSLab/SANTA.git
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Stochastic Additive No-mulT Attention (SANTA) for memory-bound autoregressive decoding. It sparsifies value-cache reads by sampling S ≪ n_k indices from the post-softmax distribution, yielding an unbiased Monte-Carlo estimator of the value aggregation that replaces MACs with gather-and-add. Stratified sampling variants are proposed for variance reduction and GPU efficiency. The work reports 1.5× decode-step attention kernel speedup over FlashInfer and FlashDecoding on an NVIDIA RTX 6000 Ada at 32k-token contexts while preserving baseline accuracy, plus a complementary Bernoulli qK^T sampling method for the score stage. Kernels are open-sourced.
Significance. If the empirical accuracy parity generalizes, the approach provides a practical, multiplier-light path to reducing KV-cache bandwidth in long-context inference that is orthogonal to quantization and compression. The hardware-measured kernel speedups and open-sourced implementation are concrete strengths that support reproducibility.
major comments (2)
- [Experimental Evaluation] The central claim of accuracy parity rests on the variance of the Monte-Carlo estimator remaining tolerable. The variance expression (1/S) ∑_i p_i ||v_i − μ||² is stated in the method but no per-head or per-layer empirical variance statistics, no S-ablation curves, and no analysis of high-entropy heads are supplied in the experimental section. This leaves open whether the chosen S that delivers the 1.5× speedup keeps downstream error within model tolerance across layers and longer contexts.
- [Method] The description of stratified sampling claims GPU-friendly variance reduction, yet the manuscript provides no breakdown of sampling overhead versus the reported gather-and-add savings. Without this accounting it is unclear whether the net 1.5× kernel speedup holds once the full sampling pipeline (including index generation and any prefix-sum or alias-table construction) is included.
minor comments (2)
- [Abstract] The abstract states 'matching baseline accuracy' without naming the models, tasks, or exact metrics (e.g., perplexity on which datasets). Adding these details would strengthen the claim.
- Exact per-layer or per-head S values and the precise hardware kernel launch configurations used for the 1.5× measurement should be tabulated for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work and the recommendation for minor revision. The comments raise valid points about strengthening the empirical support for accuracy claims and clarifying the performance accounting. We address each major comment below and will incorporate the suggested additions in the revised manuscript.
read point-by-point responses
-
Referee: [Experimental Evaluation] The central claim of accuracy parity rests on the variance of the Monte-Carlo estimator remaining tolerable. The variance expression (1/S) ∑_i p_i ||v_i − μ||² is stated in the method but no per-head or per-layer empirical variance statistics, no S-ablation curves, and no analysis of high-entropy heads are supplied in the experimental section. This leaves open whether the chosen S that delivers the 1.5× speedup keeps downstream error within model tolerance across layers and longer contexts.
Authors: We agree that additional empirical variance analysis would strengthen the presentation. In the revised manuscript we will add per-head and per-layer variance statistics, S-ablation curves relating accuracy to the number of samples, and targeted analysis of high-entropy heads. These results will be reported for the 32 k context lengths already evaluated and, where compute permits, for longer contexts to confirm that the chosen S keeps downstream error within model tolerance. revision: yes
-
Referee: [Method] The description of stratified sampling claims GPU-friendly variance reduction, yet the manuscript provides no breakdown of sampling overhead versus the reported gather-and-add savings. Without this accounting it is unclear whether the net 1.5× kernel speedup holds once the full sampling pipeline (including index generation and any prefix-sum or alias-table construction) is included.
Authors: The reported 1.5× kernel speedups are measured on the complete, end-to-end attention kernel that already includes index generation, any prefix-sum or alias-table construction, and the subsequent gather-and-add operations. To make this explicit, the revision will contain a timing breakdown table that isolates the sampling overhead from the value-aggregation savings, confirming that the net speedup remains after accounting for the full pipeline. revision: yes
Circularity Check
No significant circularity; core claims rest on standard Monte Carlo math and hardware benchmarks.
full rationale
The paper's central derivation states that sampling indices from the post-softmax distribution produces an unbiased estimator of the value aggregation. This follows directly from the definition of expectation and is a standard Monte Carlo fact, not a self-referential construction or fitted parameter renamed as prediction. Speedup claims are obtained from direct kernel measurements on RTX 6000 Ada hardware rather than any equation that reduces to a tuned hyperparameter. Accuracy parity is reported empirically at 32k contexts with no indication that S or sampling parameters were chosen to force the reported metric. No self-citation chains, uniqueness theorems, or ansatzes imported from prior author work appear load-bearing in the provided text. The derivation chain is therefore self-contained against external mathematical and empirical benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- S (sample count)
axioms (1)
- standard math Sampling indices from the normalized post-softmax attention distribution produces an unbiased estimator of the weighted value sum.
Reference graph
Works this paper leans on
-
[1]
Gqa: Training generalized multi-query transformer models from multi-head checkpoints
Ainslie, J., Lee-Thorp, J., de Jong, M., Zemlyanskiy, Y., Lebron, F., and Sanghai, S. Gqa: Training generalized multi-query transformer models from multi-head checkpoints. In The 2023 Conference on Empirical Methods in Natural Language Processing, 2023
2023
-
[2]
Longformer: The Long-Document Transformer
Beltagy, I., Peters, M. E., and Cohan, A. Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150, 2020
work page internal anchor Pith review arXiv 2004
-
[3]
Concentration Inequalities: A Nonasymptotic Theory of Independence
Boucheron, S., Lugosi, G., and Massart, P. Concentration Inequalities: A Nonasymptotic Theory of Independence. Oxford University Press, Oxford, 2013
2013
-
[4]
MMLU : Massive multitask language understanding dataset
Center for AI Safety . MMLU : Massive multitask language understanding dataset. https://huggingface.co/datasets/cais/mmlu, 2024. MIT license. Commit c30699e (uploaded 2024-03-08). Accessed 2025-05-14
2024
-
[5]
Magic PIG : LSH sampling for efficient LLM generation
Chen, Z., Sadhukhan, R., Ye, Z., Zhou, Y., Zhang, J., Nolte, N., Tian, Y., Douze, M., Bottou, L., Jia, Z., and Chen, B. Magic PIG : LSH sampling for efficient LLM generation. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=ALzTQUgW8a
2025
-
[6]
Generating Long Sequences with Sparse Transformers
Child, R., Gray, S., Radford, A., and Sutskever, I. Generating long sequences with sparse transformers. arXiv preprint arXiv:1904.10509, 2019
work page internal anchor Pith review arXiv 1904
-
[7]
Clark, K., Khandelwal, U., Levy, O., and Manning, C. D. What does BERT look at? an analysis of BERT `s attention. In Linzen, T., Chrupa a, G., Belinkov, Y., and Hupkes, D. (eds.), Proceedings of the 2019 ACL Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, pp.\ 276--286, Florence, Italy, August 2019. Association for Computational ...
-
[8]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021
work page Pith review arXiv 2021
-
[9]
Cochran, W. G. Sampling Techniques. Wiley, New York, 3rd edition, 1977
1977
-
[10]
Flash-Decoding for long-context inference
Dao, T., Haziza, D., Massa, F., and Sizov, G. Flash-Decoding for long-context inference. https://crfm.stanford.edu/2023/10/12/flashdecoding.html, October 2023. Stanford Center for Research on Foundation Models (CRFM) blog post, accessed 2026-01-20
2023
-
[11]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025. URL https://arxiv.org/abs/2501.12948
work page internal anchor Pith review arXiv 2025
-
[12]
Qlora: Efficient finetuning of quantized llms
Dettmers, T., Pagnoni, A., Holtzman, A., and Zettlemoyer, L. Qlora: Efficient finetuning of quantized llms. Advances in neural information processing systems, 36: 0 10088--10115, 2023
2023
-
[13]
OPTQ : Accurate quantization for generative pre-trained transformers
Frantar, E., Ashkboos, S., Hoefler, T., and Alistarh, D. OPTQ : Accurate quantization for generative pre-trained transformers. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=tcbBPnfwxS
2023
-
[14]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team , Anil, R., Borgeaud, S., Alayrac, J.-B., Yu, J., Soricut, R., Schalkwyk, J., Dai, A. M., Hauth, A., Millican, K., et al. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023
work page Pith review arXiv 2023
-
[15]
doi: 10.18653/v1/2021.sustainlp-1.5
Gupta, A., Dar, G., Goodman, S., Ciprut, D., and Berant, J. Memory-efficient transformers via top-k attention. In Moosavi, N. S., Gurevych, I., Fan, A., Wolf, T., Hou, Y., Marasovi \'c , A., and Ravi, S. (eds.), Proceedings of the Second Workshop on Simple and Efficient Natural Language Processing, pp.\ 39--52, Virtual, November 2021. Association for Comp...
-
[16]
Measuring massive multitask language understanding
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J. Measuring massive multitask language understanding. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=d7KBjmI3GmQ
2021
-
[17]
W., Shao, Y
Hooper, C., Kim, S., Mohammadzadeh, H., Mahoney, M. W., Shao, Y. S., Keutzer, K., and Gholami, A. Kvquant: Towards 10 million context length llm inference with kv cache quantization. Advances in Neural Information Processing Systems, 37: 0 1270--1303, 2024
2024
-
[18]
1.1 computing's energy problem (and what we can do about it)
Horowitz, M. 1.1 computing's energy problem (and what we can do about it). In 2014 IEEE International Solid-State Circuits Conference Digest of Technical Papers (ISSCC), pp.\ 10--14, 2014. doi:10.1109/ISSCC.2014.6757323
-
[19]
Ruler: What’s the real context size of your long-context language models? In First Conference on Language Modeling, 2024
Hsieh, C.-P., Sun, S., Kriman, S., Acharya, S., Rekesh, D., Jia, F., and Ginsburg, B. Ruler: What’s the real context size of your long-context language models? In First Conference on Language Modeling, 2024
2024
-
[20]
and Ko, J
Kim, H. and Ko, J. Fast monte-carlo approximation of the attention mechanism. In Proceedings of the AAAI conference on artificial intelligence, volume 36, pp.\ 7185--7193, 2022
2022
-
[21]
Reformer: The efficient transformer
Kitaev, N., Kaiser, L., and Levskaya, A. Reformer: The efficient transformer. In International Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=rkgNKkHtvB
2020
-
[22]
Let's verify step by step
Lightman, H., Kosaraju, V., Burda, Y., Edwards, H., Baker, B., Lee, T., Leike, J., Schulman, J., Sutskever, I., and Cobbe, K. Let's verify step by step. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=v8L0pN6EOi
2024
-
[23]
Kivi: A tuning-free asymmetric 2bit quantization for kv cache
Liu, Z., Yuan, J., Jin, H., Zhong, S., Xu, Z., Braverman, V., Chen, B., and Hu, X. Kivi: A tuning-free asymmetric 2bit quantization for kv cache. In International Conference on Machine Learning, pp.\ 32332--32344. PMLR, 2024
2024
-
[24]
Lohr, S. L. Sampling: Design and Analysis. Brooks/Cole, Boston, 2nd edition, 2010
2010
-
[25]
Bitnet b1.58 2b4t technical report,
Ma, S., Wang, H., Huang, S., Zhang, X., Hu, Y., Song, T., Xia, Y., and Wei, F. Bitnet b1.58 2b4t technical report, 2025. URL https://arxiv.org/abs/2504.12285
-
[26]
Meta Llama 3.1 8B Instruct : Version 1
Meta AI . Meta Llama 3.1 8B Instruct : Version 1. https://huggingface.co/meta-llama/Llama-3.1-8B-Instruct, 2024. Llama 3.1 Community License. Model release 2024-07-23. Accessed 2025-05-14
2024
-
[27]
OpenAI. Gpt-4 technical report, 2023. URL https://arxiv.org/abs/2303.08774
work page internal anchor Pith review arXiv 2023
-
[28]
GSM8K : Grade school math word problems (v1.0)
OpenAI . GSM8K : Grade school math word problems (v1.0). https://huggingface.co/datasets/openai/gsm8k, 2023. MIT License, commit e53f048. Accessed 2025-05-14
2023
-
[29]
Owen, A. B. Monte Carlo Theory, Methods and Examples. 2013. Monograph
2013
-
[30]
Optimum bounds for the distributions of martingales in banach spaces
Pinelis, I. Optimum bounds for the distributions of martingales in banach spaces. The Annals of Probability, 22 0 (4): 0 1679--1706, 1994
1994
-
[31]
Know What You Don 't Know : Unanswerable Questions for SQuAD
Rajpurkar, P., Jia, R., and Liang, P. Know what you don ' t know: Unanswerable questions for SQ u AD . In Gurevych, I. and Miyao, Y. (eds.), Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), pp.\ 784--789, Melbourne, Australia, July 2018. Association for Computational Linguistics. doi:10.1865...
-
[32]
Sparq attention: Bandwidth-efficient llm inference
Ribar, L., Chelombiev, I., Hudlass-Galley, L., Blake, C., Luschi, C., and Orr, D. Sparq attention: Bandwidth-efficient llm inference. In International Conference on Machine Learning, pp.\ 42558--42583. PMLR, 2024
2024
-
[33]
Hire: High recall approximate top- k estimation for efficient llm inference, 2024
Samaga B L, Y., Yerram, V., You, C., Bhojanapalli, S., Kumar, S., Jain, P., and Netrapalli, P. Hire: High recall approximate top- k estimation for efficient llm inference, 2024. URL https://arxiv.org/abs/2402.09360
-
[34]
Triforce: Lossless acceleration of long sequence generation with hierarchical speculative decoding
Sun, H., Chen, Z., Yang, X., Tian, Y., and Chen, B. Triforce: Lossless acceleration of long sequence generation with hierarchical speculative decoding. In First Conference on Language Modeling, 2024
2024
-
[35]
Quest: query-aware sparsity for efficient long-context llm inference
Tang, J., Zhao, Y., Zhu, K., Xiao, G., Kasikci, B., and Han, S. Quest: query-aware sparsity for efficient long-context llm inference. In Proceedings of the 41st International Conference on Machine Learning, pp.\ 47901--47911, 2024
2024
-
[36]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., Rodriguez, A., Joulin, A., Grave, E., and Lample, G. Llama: Open and efficient foundation language models, 2023. URL https://arxiv.org/abs/2302.13971
work page internal anchor Pith review arXiv 2023
-
[37]
N., Kaiser, ., and Polosukhin, I
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, ., and Polosukhin, I. Attention is all you need. Advances in neural information processing systems, 30, 2017
2017
-
[38]
Linformer: Self-Attention with Linear Complexity
Wang, S., Li, B. Z., Khabsa, M., Fang, H., and Ma, H. Linformer: Self-attention with linear complexity. arXiv preprint arXiv:2006.04768, 2020
work page internal anchor Pith review arXiv 2006
-
[39]
Williams, R. J. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine Learning, 8 0 (3-4): 0 229--256, 1992
1992
-
[40]
RT op-k: Ultra-fast row-wise top-k selection for neural network acceleration on GPU s
Xie, X., Luo, Y., Peng, H., and Ding, C. RT op-k: Ultra-fast row-wise top-k selection for neural network acceleration on GPU s. In The Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=PHg4rAXFVH
2025
-
[41]
Yang, Z., Qi, P., Zhang, S., Bengio, Y., Cohen, W., Salakhutdinov, R., and Manning, C. D. H otpot QA : A dataset for diverse, explainable multi-hop question answering. In Riloff, E., Chiang, D., Hockenmaier, J., and Tsujii, J. (eds.), Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, pp.\ 2369--2380, Brussels, Belgium...
-
[42]
Flashinfer: Efficient and customizable attention engine for LLM inference serving
Ye, Z., Chen, L., Lai, R., Lin, W., Zhang, Y., Wang, S., Chen, T., Kasikci, B., Grover, V., Krishnamurthy, A., and Ceze, L. Flashinfer: Efficient and customizable attention engine for LLM inference serving. In Eighth Conference on Machine Learning and Systems, 2025. URL https://openreview.net/forum?id=RXPofAsL8F
2025
-
[43]
A., Ainslie, J., Alberti, C., Ontanon, S., Pham, P., Ravula, A., Wang, Q., Yang, L., et al
Zaheer, M., Guruganesh, G., Dubey, K. A., Ainslie, J., Alberti, C., Ontanon, S., Pham, P., Ravula, A., Wang, Q., Yang, L., et al. Big bird: Transformers for longer sequences. Advances in neural information processing systems, 33: 0 17283--17297, 2020
2020
-
[44]
H2o: Heavy-hitter oracle for efficient generative inference of large language models
Zhang, Z., Sheng, Y., Zhou, T., Chen, T., Zheng, L., Cai, R., Song, Z., Tian, Y., R \'e , C., Barrett, C., et al. H2o: Heavy-hitter oracle for efficient generative inference of large language models. Advances in Neural Information Processing Systems, 36: 0 34661--34710, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.