Recognition: 3 theorem links
· Lean TheoremA Meta Reinforcement Learning Approach to Goals-Based Wealth Management
Pith reviewed 2026-05-08 18:37 UTC · model grok-4.3
The pith
Pre-trained meta reinforcement learning produces near-optimal goals-based wealth management strategies in milliseconds.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The MetaRL approach, by pre-training on thousands of GBWM problems, enables inference-mode solutions for new GBWM problems in a few hundredths of a second that deliver expected utilities averaging 97.8% of the optimal expected utilities from Dynamic Programming, and these results hold robustly across capital market regime changes.
What carries the argument
Meta reinforcement learning model pre-trained for zero-shot application to goals-based wealth management problems involving annual portfolio choices and goal fulfillments to maximize expected utility.
If this is right
- New investor problems can be solved without separate training or optimization steps.
- Problems with state spaces larger than what dynamic programming can handle become solvable.
- The model works even if training used only one market regime but testing uses different regimes.
- Expected utilities close to optimal are obtained in real time for dynamic portfolio and goal decisions.
Where Pith is reading between the lines
- The method could extend to other sequential decision problems in finance where pre-training on variants allows fast adaptation to new constraints.
- Integration with real-time market data feeds might allow continuous updating of strategies without full re-optimization.
- Similar meta-learning could reduce computation in other goal-oriented optimization domains like retirement planning with multiple objectives.
Load-bearing premise
That pre-training on thousands of GBWM problems produces a model that generalizes to new investor problems with different parameters, goals, and market conditions without significant performance loss.
What would settle it
Running the MetaRL model on a held-out set of GBWM problems with parameters outside the training distribution and finding that average utility falls substantially below 97.8% of the dynamic programming benchmark would falsify the generalization claim.
Figures






read the original abstract
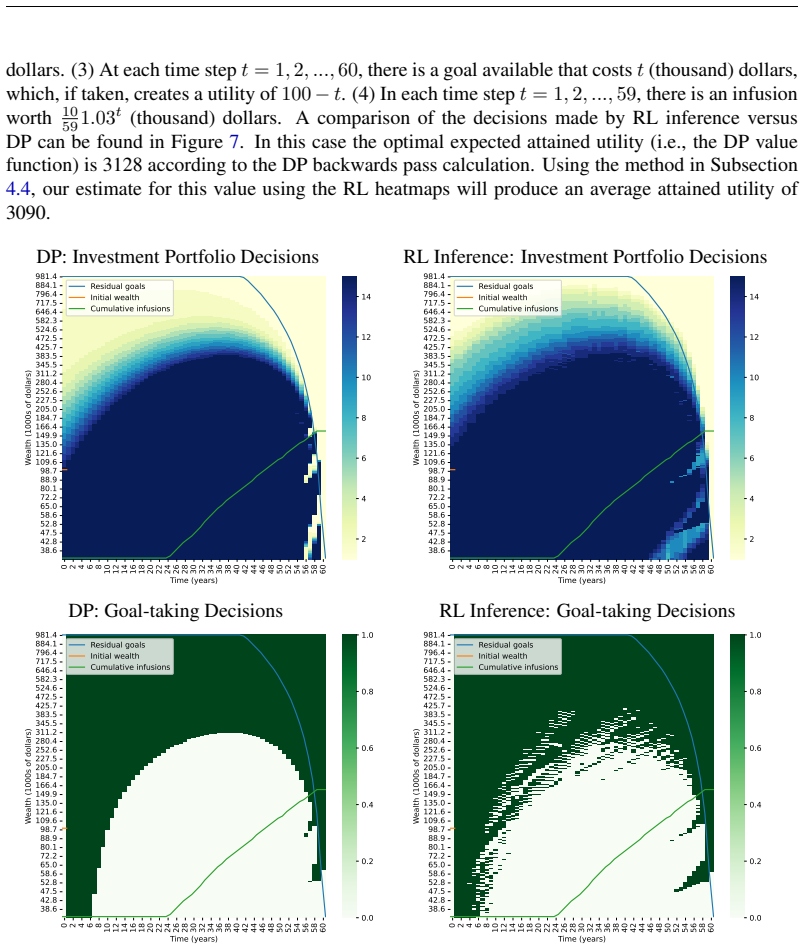
Applying concepts related to zero-shot meta-learning and pre-training of foundation models, we develop a meta reinforcement learning approach (denoted MetaRL) that is pre-trained on thousands of goals-based wealth management (GBWM) problems. Each GBWM problem involves a multiple year scenario over which the investor looks to optimally choose an investment portfolio each year and choose to fulfill all, some, or none of the different financial goals that arise each year. These choices seek to maximize the expected total investor utility obtained from the fulfilled financial goals. By eliminating separate training and optimization for each new investor problem, the MetaRL model in inference mode produces near-optimal dynamic investment portfolio and goal-fulfilling strategies for a new GBWM problem within a few hundredths of a second. This delivers expected utilities that are, on average, 97.8% of the optimal expected utilities (determined via Dynamic Programming). These results are remarkably robust to capital market regime changes, even when training uses only one capital market regime. Further, the MetaRL approach can enable solving problems with larger state spaces where Dynamic Programming becomes computationally infeasible.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a meta-reinforcement learning (MetaRL) framework pre-trained on thousands of goals-based wealth management (GBWM) problems. In inference, the model generates dynamic investment portfolio and goal-fulfillment strategies for unseen GBWM instances in milliseconds, achieving average expected utilities of 97.8% relative to dynamic programming (DP) optima. It claims robustness to capital market regime changes and applicability to large state spaces where DP is intractable.
Significance. If the empirical results hold under rigorous validation, this work could enable practical, real-time optimization for complex personalized financial planning problems, extending meta-RL techniques to a high-stakes sequential decision domain. The reported inference speed and cross-regime robustness would represent a meaningful advance over per-instance DP or standard RL training, with potential to inspire similar meta-learning applications in other uncertain planning settings.
major comments (2)
- [Abstract] Abstract: The central performance claim that MetaRL delivers expected utilities averaging 97.8% of DP optima is presented without any description of the experimental protocol, including the number and parameterization of test GBWM problems, the state-space dimensions used for the DP comparisons, the number of evaluation runs, or measures of variability. This detail is load-bearing because the near-optimality assertion rests entirely on this figure.
- [Abstract] Abstract: The claim that MetaRL solves larger state-space GBWM problems (where DP is computationally infeasible) with near-optimal strategies lacks any supporting optimality anchor, upper bound, or proxy metric for those instances. The 97.8% figure applies only to small-state cases amenable to DP; the extension to the regime where the method is positioned as most useful therefore relies on untested extrapolation.
minor comments (1)
- [Abstract] Abstract: The phrase 'zero-shot meta-learning' is invoked but not operationally distinguished from standard meta-RL pre-training and fine-tuning in the GBWM setting; a brief clarification would improve precision.
Simulated Author's Rebuttal
We appreciate the referee's thorough review and insightful comments on our manuscript. We address each major comment below and indicate where revisions will be made to strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central performance claim that MetaRL delivers expected utilities averaging 97.8% of DP optima is presented without any description of the experimental protocol, including the number and parameterization of test GBWM problems, the state-space dimensions used for the DP comparisons, the number of evaluation runs, or measures of variability. This detail is load-bearing because the near-optimality assertion rests entirely on this figure.
Authors: We agree that the abstract would benefit from a concise description of the experimental protocol to support the 97.8% claim. While the full protocol (including test problem parameterization, state-space dimensions for DP comparisons, number of runs, and variability) is detailed in the Experiments section, we will revise the abstract to briefly summarize these elements so the performance figure is self-contained. revision: yes
-
Referee: [Abstract] Abstract: The claim that MetaRL solves larger state-space GBWM problems (where DP is computationally infeasible) with near-optimal strategies lacks any supporting optimality anchor, upper bound, or proxy metric for those instances. The 97.8% figure applies only to small-state cases amenable to DP; the extension to the regime where the method is positioned as most useful therefore relies on untested extrapolation.
Authors: We thank the referee for this observation. The abstract does not claim near-optimality for larger state-space problems; it states only that the approach 'can enable solving problems with larger state spaces where Dynamic Programming becomes computationally infeasible.' The 97.8% figure is tied exclusively to DP-comparable instances. We will revise the abstract to explicitly distinguish these regimes and clarify that no direct optimality benchmark is provided for large instances. We will also add discussion of feasibility demonstrations and proxy checks in the main text to avoid any implication of untested extrapolation. revision: partial
Circularity Check
No circularity; performance measured against independent DP benchmark on tractable instances
full rationale
The paper's central result is an empirical claim: a meta-RL model pre-trained on thousands of GBWM instances produces policies whose expected utility reaches 97.8% of the value obtained by exact Dynamic Programming on new test problems. DP is an external, non-learned algorithm whose optimality is defined by the Bellman equation and does not depend on the MetaRL parameters or outputs. No equation in the abstract or described method reduces the reported utility ratio to a fitted quantity, a self-citation, or a redefinition of optimality. The extension to larger state spaces is presented only as computational feasibility, not as a measured optimality percentage. This is a standard train-then-evaluate protocol with no load-bearing self-referential step.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J = ½(x+x⁻¹)−1) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We implement a two-agent variant of Proximal Policy Optimization (PPO) ... 26 state variables ... normalized ... helping with generalizability.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leann/a — paper uses GBM, not φ-ladder iteration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
wealth transitions ... governed by geometric Brownian motion ... W(t+1) = [W(t)+I(t)−g(t)C(t)]·exp((μ−½σ²)h+σ√h Z)
-
n/ano RS theorem applies — empirical ML benchmark in finance unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MetaRL ... delivers expected utilities that are, on average, 97.8% of the optimal expected utilities (determined via Dynamic Programming).
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
The Review of Financial Studies , author =
Machine. The Review of Financial Studies , author =. 2024 , pages =. doi:10.1093/rfs/hhae043 , abstract =
-
[2]
INFORMS Journal on Data Science , author =
Credit. INFORMS Journal on Data Science , author =. 2023 , note =. doi:10.1287/ijds.2022.00018 , abstract =
-
[3]
Annals of Operations Research , author =
Prediction of bank credit worthiness through credit risk analysis: an explainable machine learning study , issn =. Annals of Operations Research , author =. 2024 , keywords =. doi:10.1007/s10479-024-06134-x , abstract =
-
[4]
Annals of Operations Research , author =
Extending application of explainable artificial intelligence for managers in financial organizations , issn =. Annals of Operations Research , author =. 2024 , keywords =. doi:10.1007/s10479-024-05825-9 , abstract =
-
[5]
Annals of Operations Research , author =. 2023 , keywords =. doi:10.1007/s10479-023-05631-9 , abstract =
-
[6]
Journal of Banking & Finance , author =
Dynamic optimization for multi-goals wealth management , volume =. Journal of Banking & Finance , author =. 2022 , keywords =. doi:10.1016/j.jbankfin.2021.106192 , abstract =
-
[7]
Journal of Wealth Management , author =
Optimal. Journal of Wealth Management , author =
-
[8]
Annals of Operations Research , author =
Goal-based investing with goal postponement: multistage stochastic mixed-integer programming approach , issn =. Annals of Operations Research , author =. 2024 , keywords =. doi:10.1007/s10479-024-06146-7 , abstract =
-
[9]
The Review of Financial Studies , author =
A. The Review of Financial Studies , author =. 2005 , pages =. doi:10.1093/rfs/hhi019 , abstract =
-
[10]
The Journal of Finance , author =
Dynamic. The Journal of Finance , author =. 2006 , note =. doi:10.1111/j.1540-6261.2006.01055.x , abstract =
-
[11]
Financial Analysts Journal , author =
Asset. Financial Analysts Journal , author =. 1991 , note =
1991
-
[12]
Journal of Political Economy , author =
The. Journal of Political Economy , author =. 1973 , note =
1973
-
[13]
The Journal of Portfolio Management , author =
Liabilities—. The Journal of Portfolio Management , author =. 1990 , note =. doi:10.3905/jpm.1990.409248 , language =
-
[14]
Upbin, Brian and Stefanelli, Nikki and Gendron, Nicholas , month = may, year =
-
[15]
Liability-
Stockton, Kimberly and Donaldson, Scott and Shtekhman, Anatoly , year =. Liability-
-
[16]
The Journal of Portfolio Management , author =
Liability-. The Journal of Portfolio Management , author =. 2013 , note =. doi:10.3905/jpm.2013.40.1.071 , abstract =
-
[17]
Computers & Operations Research , author =
Funding and investment decisions in a stochastic defined benefit pension plan with several levels of labor-income earnings , volume =. Computers & Operations Research , author =. 2008 , keywords =. doi:10.1016/j.cor.2006.02.021 , abstract =
-
[18]
International Review of Financial Analysis , author =
Pension de-risking choice and firm risk:. International Review of Financial Analysis , author =. 2022 , keywords =. doi:10.1016/j.irfa.2022.102064 , abstract =
-
[19]
Journal of Insurance Issues , author =
Optimal. Journal of Insurance Issues , author =. 2021 , note =
2021
-
[20]
Insurance: Mathematics and Economics , author =
Mean-variance optimization problems for an accumulation phase in a defined benefit plan , volume =. Insurance: Mathematics and Economics , author =. 2008 , note =
2008
-
[21]
Insurance: Mathematics and Economics , author =
Optimal pension management in a stochastic framework , volume =. Insurance: Mathematics and Economics , author =. 2004 , keywords =. doi:10.1016/j.insmatheco.2003.11.001 , abstract =
-
[22]
optimal pension management in a stochastic framework
On “optimal pension management in a stochastic framework” with exponential utility , volume =. Insurance: Mathematics and Economics , author =. 2011 , keywords =. doi:10.1016/j.insmatheco.2011.02.003 , abstract =
-
[23]
Duarte, Victor and Fonseca, Julia and Goodman, Aaron S. and Parker, Jonathan A. , month = dec, year =. Simple. doi:10.3386/w29559 , note =
-
[24]
Insurance: Mathematics and Economics , author =
Stochastic optimal control of annuity contracts , volume =. Insurance: Mathematics and Economics , author =. 2003 , note =
2003
-
[25]
Insurance: Mathematics and Economics , author =
Portfolio optimization in a defined benefit pension plan where the risky assets are processes with constant elasticity of variance , volume =. Insurance: Mathematics and Economics , author =. 2018 , note =
2018
-
[26]
Journal of Risk and Financial Management , author =
Combining. Journal of Risk and Financial Management , author =. 2021 , note =. doi:10.3390/jrfm14070285 , abstract =
-
[27]
The Journal of Wealth Management , author =
Portfolios for. The Journal of Wealth Management , author =. 2011 , pages =. doi:10.3905/jwm.2011.14.2.025 , language =
-
[28]
Journal of Financial and Quantitative Analysis , author =
Portfolio. Journal of Financial and Quantitative Analysis , author =. 2010 , pages =
2010
-
[29]
Journal of Economic Dynamics and Control , author =
Options and structured products in behavioral portfolios , volume =. Journal of Economic Dynamics and Control , author =. 2013 , keywords =
2013
-
[30]
Proceedings of the National Academy of Sciences , author =
On the. Proceedings of the National Academy of Sciences , author =. 1952 , pmid =. doi:10.1073/pnas.38.8.716 , language =
-
[31]
Das, Sanjiv Ranjan and Ross, Greg , month = sep, year =. The. doi:10.2139/ssrn.3691699 , keywords =
-
[32]
Journal of Investment Management , author =
Multi-. Journal of Investment Management , author =. 2020 , pages =
2020
-
[33]
What determines the asset allocation of defined benefit pension funds? , volume =. Applied Economics , author =. 2021 , note =. doi:10.1080/00036846.2021.1897512 , abstract =
-
[34]
The Journal of Finance , author =
The. The Journal of Finance , author =. 1978 , note =. doi:10.1111/j.1540-6261.1978.tb03397.x , language =
-
[35]
Halperin, Igor , month = apr, year =. Distributional. doi:10.48550/arXiv.2104.01040 , abstract =
-
[36]
arXiv preprint arXiv:2302.05206 , year =
Zhang, Tianjun and Liu, Fangchen and Wong, Justin and Abbeel, Pieter and Gonzalez, Joseph E. , month = feb, year =. The. doi:10.48550/arXiv.2302.05206 , abstract =
-
[37]
Ouyang, Long and Wu, Jeff and Jiang, Xu and Almeida, Diogo and Wainwright, Carroll L. and Mishkin, Pamela and Zhang, Chong and Agarwal, Sandhini and Slama, Katarina and Ray, Alex and Schulman, John and Hilton, Jacob and Kelton, Fraser and Miller, Luke and Simens, Maddie and Askell, Amanda and Welinder, Peter and Christiano, Paul and Leike, Jan and Lowe, R...
work page internal anchor Pith review doi:10.48550/arxiv.2203.02155
-
[38]
Ziegler, Ryan Lowe, Chelsea V oss, Alec Radford, Dario Amodei, and Paul Christiano
Stiennon, Nisan and Ouyang, Long and Wu, Jeff and Ziegler, Daniel M. and Lowe, Ryan and Voss, Chelsea and Radford, Alec and Amodei, Dario and Christiano, Paul , month = feb, year =. Learning to summarize from human feedback , url =. doi:10.48550/arXiv.2009.01325 , abstract =
-
[39]
Fine-Tuning Language Models from Human Preferences
Ziegler, Daniel M. and Stiennon, Nisan and Wu, Jeffrey and Brown, Tom B. and Radford, Alec and Amodei, Dario and Christiano, Paul and Irving, Geoffrey , month = jan, year =. Fine-. doi:10.48550/arXiv.1909.08593 , abstract =
work page internal anchor Pith review doi:10.48550/arxiv.1909.08593 1909
-
[40]
Asynchronous methods for deep reinforcement learning.arXiv preprint arXiv:1602.01783,
Mnih, Volodymyr and Badia, Adrià Puigdomènech and Mirza, Mehdi and Graves, Alex and Lillicrap, Timothy P. and Harley, Tim and Silver, David and Kavukcuoglu, Koray , month = jun, year =. Asynchronous. doi:10.48550/arXiv.1602.01783 , abstract =
-
[41]
Quanta Magazine , author =
Machines. Quanta Magazine , author =. 2023 , file =
2023
-
[42]
NAIC , file =. Pension
-
[43]
PonderNet: Learning to ponder.arXiv preprint arXiv:2106.01345,
Decision. arXiv:2106.01345 [cs] , author =. 2021 , note =
-
[44]
and Xu, Renyuan and Yang, Huining , month = nov, year =
Hambly, Ben M. and Xu, Renyuan and Yang, Huining , month = nov, year =. Recent. doi:10.2139/ssrn.3971071 , keywords =
-
[45]
Journal of Applied Mathematics and Decision Sciences , author =
Three. Journal of Applied Mathematics and Decision Sciences , author =. 2004 , note =. doi:10.1207/s15327612jamd0801_1 , abstract =
-
[46]
Mathematical Finance , author =
Recent advances in reinforcement learning in finance , volume =. Mathematical Finance , author =. doi:10.1111/mafi.12382 , abstract =
-
[47]
Understanding
Raschka, Sebastian , month = apr, year =. Understanding
-
[48]
Kodres, Laura , month = may, year =. Too. doi:10.2139/ssrn.4445632 , abstract =
-
[49]
Journal of Financial Economics , author =
A note on the geometry of. Journal of Financial Economics , author =. 1985 , pages =. doi:10.1016/0304-405X(85)90003-0 , abstract =
-
[50]
Journal of Financial Economics , author =
Potential performance and tests of portfolio efficiency , volume =. Journal of Financial Economics , author =. 1982 , note =
1982
-
[51]
Optimal. The Review of Financial Studies , author =. 2009 , pages =. doi:10.1093/rfs/hhm075 , abstract =
-
[52]
Financial Analysts Journal , author =
The. Financial Analysts Journal , author =. 1989 , note =
1989
-
[53]
Journal of the American Statistical Association , author =
Estimation for. Journal of the American Statistical Association , author =. 1980 , note =. doi:10.2307/2287643 , abstract =
-
[54]
On the. Physical Review , author =. 1930 , note =. doi:10.1103/PhysRev.36.823 , abstract =
-
[55]
An equilibrium characterization of the term structure , volume =. Journal of Financial Economics , author =. 1977 , pages =. doi:10.1016/0304-405X(77)90016-2 , abstract =
-
[56]
Sgouros, Tom , year =. Funding
-
[57]
Sgouros, Tom , year =. The
-
[58]
doi:10.2139/ssrn.4566372 , abstract =
Halperin, Igor , month = sep, year =. doi:10.2139/ssrn.4566372 , abstract =
-
[59]
Journal of Risk and Insurance , author =
Managing. Journal of Risk and Insurance , author =. 2013 , note =. doi:10.1111/j.1539-6975.2012.01508.x , abstract =
-
[60]
Journal of Risk and Insurance , author =
The. Journal of Risk and Insurance , author =. 2013 , note =. doi:10.1111/j.1539-6975.2011.01456.x , abstract =
-
[61]
Journal of Risk and Insurance , author =
A. Journal of Risk and Insurance , author =. 2018 , note =. doi:10.1111/jori.12150 , abstract =
-
[62]
Journal of Risk and Insurance , author =
Pension. Journal of Risk and Insurance , author =. 2013 , note =. doi:10.1111/j.1539-6975.2012.01465.x , abstract =
-
[63]
Journal of Risk and Insurance , author =
Pension. Journal of Risk and Insurance , author =. 2002 , note =. doi:10.1111/1539-6975.00013 , abstract =
-
[64]
Journal of Risk and Insurance , author =
The. Journal of Risk and Insurance , author =. 2002 , note =. doi:10.1111/1539-6975.00012 , abstract =
-
[65]
Journal of Risk and Insurance , author =
Informed. Journal of Risk and Insurance , author =. 2013 , note =. doi:10.1111/j.1539-6975.2013.01524.x , abstract =
-
[66]
Journal of Risk and Insurance , author =
Optimal. Journal of Risk and Insurance , author =. 2010 , note =. doi:10.1111/j.1539-6975.2009.01350.x , abstract =
-
[67]
In deep reinforcement learning, a pruned network is a good network , url =
Obando-Ceron, Johan and Courville, Aaron and Castro, Pablo Samuel , month = feb, year =. In deep reinforcement learning, a pruned network is a good network , url =. doi:10.48550/arXiv.2402.12479 , abstract =
-
[68]
and Barto, Andrew G
Sutton, Richard S. and Barto, Andrew G. , month = nov, year =. Reinforcement
-
[69]
, year = 1980, month = dec, journal =
On estimating the expected return on the market:. Journal of Financial Economics , author =. 1980 , pages =. doi:10.1016/0304-405X(80)90007-0 , abstract =
-
[70]
Annals of Actuarial Science , author =
Causes of defined benefit pension scheme funding ratio volatility and average contribution rates , volume =. Annals of Actuarial Science , author =. 2012 , keywords =. doi:10.1017/S1748499511000303 , abstract =
-
[71]
Mathematical Methods of Operations Research , author =
Optimal investment for a pension fund under inflation risk , volume =. Mathematical Methods of Operations Research , author =. 2010 , keywords =. doi:10.1007/s00186-009-0294-5 , abstract =
-
[72]
Journal of Pension Economics & Finance , author =
Dynamic allocation decisions in the presence of funding ratio constraints , volume =. Journal of Pension Economics & Finance , author =. 2012 , pages =. doi:10.1017/S1474747212000194 , abstract =
-
[73]
and Brandt, Michael W
van Binsbergen, Jules H. and Brandt, Michael W. , year =. Optimal. Handbook of
-
[74]
Learning to predict by the methods of temporal differences , volume =. Machine Learning , author =. 1988 , keywords =. doi:10.1007/BF00115009 , abstract =
-
[75]
Watkins, C. J. C. H. , year =. Learning from
-
[76]
Playing Atari with Deep Reinforcement Learning
Playing. NIPS Deep Learning Workshop , author =. 2013 , note =. doi:10.48550/ARXIV.1312.5602 , abstract =
work page internal anchor Pith review doi:10.48550/arxiv.1312.5602 2013
-
[77]
Human-level control through deep reinforcement learning , volume =. Nature , author =. 2015 , note =. doi:10.1038/nature14236 , abstract =
-
[78]
Mastering the game of. Nature , author =. 2016 , note =. doi:10.1038/nature16961 , abstract =
-
[79]
Haarnoja, Tuomas and Zhou, Aurick and Abbeel, Pieter and Levine, Sergey , month = aug, year =. Soft. doi:10.48550/arXiv.1801.01290 , abstract =
work page internal anchor Pith review doi:10.48550/arxiv.1801.01290
-
[80]
Zheng, Cong and He, Jiafa and Yang, Can , month = jun, year =. Optimal. doi:10.48550/arXiv.2306.17178 , abstract =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.