Recognition: 3 theorem links
· Lean TheoremGradient-Gated DPO: Stabilizing Preference Optimization in Language Models
Pith reviewed 2026-05-08 18:30 UTC · model grok-4.3
The pith
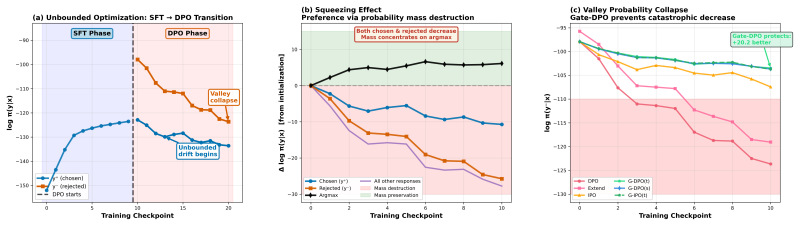
Gate-DPO attenuates gradients on low-probability rejected responses to stabilize DPO training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By introducing a gradient gate that scales down harmful updates to rejected responses when their probability is extremely low, Gate-DPO prevents the systematic probability collapse observed in vanilla DPO while preserving the original preference optimization objective. Mass-dynamics analysis shows improved preferred-response probabilities and reduced suppression across the distribution.
What carries the argument
The probability-geometry-based gradient gate, which detects when an update targets an extremely low-probability rejected response and attenuates the corresponding gradient.
If this is right
- Consistently reduces the squeezing effect across architectures and preference datasets.
- Improves the likelihood of chosen responses during optimization.
- Produces healthier mass dynamics with better preferred responses and less suppression of the overall distribution.
- Remains complementary to existing stabilization techniques such as extended SFT, IPO, and Cal-DPO.
- Smaller models using the gate can achieve stronger chosen-response improvements than larger models without it.
Where Pith is reading between the lines
- Controlling gradient flow by probability magnitude may generalize to other reinforcement-learning-style objectives in language model training.
- Reducing reliance on model scale for stability could lower the computational cost of alignment procedures.
- Future work could test whether the same gating logic applies when the rejected responses come from different data sources or when the model is fine-tuned on multiple tasks simultaneously.
- The gate's design suggests a broader principle: aligning models by protecting low-probability regions rather than only pushing high-probability ones.
Load-bearing premise
Attenuating gradients on extremely low-probability rejected responses will not create new instabilities or unintended biases in the preference optimization process.
What would settle it
Training a model with Gate-DPO on a held-out preference dataset and observing either increased squeezing metrics or lower chosen-response accuracy than the vanilla DPO baseline would falsify the central claim.
Figures






read the original abstract
Preference optimization has become a central paradigm for aligning large language models with human feedback. Direct Preference Optimization (DPO) simplifies reinforcement learning from human feedback by directly optimizing pairwise preferences, removing the need for reward modeling and policy optimization. However, recent work shows that DPO exhibits a squeezing effect, where negative gradients applied to rejected responses concentrate probability mass on high-confidence predictions while suppressing alternative responses. This phenomenon arises even in simple softmax models and can lead to systematic probability collapse during training. We introduce Gradient-Gated Preference Optimization (Gate-DPO), a method that stabilizes training by modulating rejected gradients according to the model's probability geometry. When updates target extremely low-probability responses, the gate attenuates harmful gradients while preserving standard optimization behavior. Gate-DPO addresses this optimization pathology without modifying the underlying preference objective and is complementary to existing methods such as extended SFT, IPO, and Cal-DPO. Experiments across multiple architectures and preference datasets show that Gate-DPO consistently reduces squeezing and improves chosen-response likelihood. Mass-dynamics analysis further reveals healthier optimization behavior, with improved preferred responses and reduced suppression of the overall distribution. Notably, smaller gated models can exhibit stronger chosen-response improvements than larger ungated models, suggesting that controlling gradient dynamics, rather than scale alone, is key to stable and efficient alignment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Gradient-Gated DPO (Gate-DPO), which stabilizes Direct Preference Optimization by attenuating gradients on rejected responses that fall below a probability threshold derived from the model's geometry. This is claimed to reduce the squeezing effect (probability collapse on high-confidence predictions) without changing the underlying preference objective, while improving chosen-response likelihood and yielding healthier mass dynamics. Experiments across architectures and datasets are reported to show consistent gains, with smaller gated models sometimes outperforming larger ungated ones; the method is asserted to be complementary to IPO, Cal-DPO, and extended SFT.
Significance. If the empirical claims hold under rigorous controls, Gate-DPO would provide a lightweight, objective-preserving stabilization technique for preference optimization. The mass-dynamics analysis and the scale-vs-control observation could shift emphasis from model size to gradient management in alignment research.
major comments (3)
- [Abstract] The abstract asserts complementarity to IPO and Cal-DPO and stability under mode collapse, yet no combined experiments, ablation on joint training, or analysis of gated dynamics when the base model already exhibits collapse are described; this leaves the complementarity claim untested and load-bearing for the practical contribution.
- [Experiments] The central empirical claims rest on experiments whose details (statistical tests, error bars, ablation specifics, controls for dataset size/architecture, and exact gating threshold derivation) are not provided; without these, the reported reductions in squeezing and improvements in chosen-response likelihood cannot be assessed for robustness.
- [Method] The gradient gate attenuates updates only on the rejected term when probability falls below a geometry-derived threshold; the manuscript must supply bounds or counter-examples showing this does not systematically under-penalize low-probability but semantically relevant rejected responses, as the implicit curriculum effect could weaken separation on edge cases.
minor comments (2)
- [Method] Define the precise functional form of the gate (including how the probability threshold is computed from geometry) in the main text rather than leaving it implicit.
- [Introduction] Add missing references to prior analyses of DPO squeezing/collapse and clarify notation for probability mass dynamics.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We appreciate the identification of areas where our claims can be strengthened with additional experiments and analysis. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract] The abstract asserts complementarity to IPO and Cal-DPO and stability under mode collapse, yet no combined experiments, ablation on joint training, or analysis of gated dynamics when the base model already exhibits collapse are described; this leaves the complementarity claim untested and load-bearing for the practical contribution.
Authors: We agree that the complementarity and stability claims would be more robust with direct empirical validation. In the revised manuscript, we will add new experiments combining Gate-DPO with IPO and Cal-DPO, including joint training ablations on shared datasets. We will also include an analysis section examining Gate-DPO's behavior when initialized from base models already exhibiting mode collapse, measuring changes in squeezing metrics and chosen-response likelihood. These additions will provide concrete support for the practical contribution. revision: yes
-
Referee: [Experiments] The central empirical claims rest on experiments whose details (statistical tests, error bars, ablation specifics, controls for dataset size/architecture, and exact gating threshold derivation) are not provided; without these, the reported reductions in squeezing and improvements in chosen-response likelihood cannot be assessed for robustness.
Authors: We acknowledge that additional experimental details are necessary for assessing robustness. The revised version will include: statistical tests such as paired t-tests with p-values across runs; error bars showing standard deviation over multiple random seeds (at least 3); expanded ablation tables varying gating thresholds and reporting effects on squeezing and likelihood metrics; controls for dataset size and architecture variations; and the exact derivation of the geometry-derived threshold (computed from the model's log-probability relative to its entropy with a fixed scaling hyperparameter). These changes will allow full evaluation of the claims. revision: yes
-
Referee: [Method] The gradient gate attenuates updates only on the rejected term when probability falls below a geometry-derived threshold; the manuscript must supply bounds or counter-examples showing this does not systematically under-penalize low-probability but semantically relevant rejected responses, as the implicit curriculum effect could weaken separation on edge cases.
Authors: This concern about potential under-penalization of semantically relevant responses is well-taken. We will revise the method section to include a theoretical analysis deriving bounds on the attenuation factor, showing that the gate activates only for probabilities far below typical semantic relevance thresholds. We will also add counter-examples and targeted empirical studies demonstrating that low-probability but relevant rejected responses maintain sufficient gradient magnitude because their probabilities stay above the gate during training. The design preserves the preference separation objective while mitigating collapse on implausible responses. revision: yes
Circularity Check
No significant circularity in derivation or claims
full rationale
The paper introduces a gradient-gating mechanism that attenuates updates on low-probability rejected responses based on instantaneous model geometry, without changing the DPO loss itself. This is presented as an algorithmic stabilization technique validated through experiments on multiple models and datasets showing reduced squeezing and healthier mass dynamics. No equations or central claims reduce by construction to fitted parameters, self-definitions, or self-citation chains; the method and its benefits are independently specified and empirically tested rather than tautologically derived from prior results or inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Softmax probability geometry reliably indicates when a rejected response gradient is harmful
Lean theorems connected to this paper
-
Foundation/BranchSelection.lean (the RCL combiner P(u,v)=2u+2v+c·u·v and reciprocal-symmetric J family)RCLCombiner_isCoupling_iff unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
g_θ(x) = σ(α(s_θ(x) − τ)) ... When s_θ(x) ≪ τ, the gate becomes small and attenuates the negative update; when s_θ(x) ≫ τ, the gate remains close to 1 and we recover standard DPO behavior.
-
Cost/FunctionalEquation.lean (J-cost ratio-symmetric uniqueness)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
L_DPO(θ) = E[−log σ(β(Δ_θ(x,y+) − Δ_θ(x,y−)))], with sequence log-prob factorization log π_θ(y|x) = Σ log π_θ(y_t|x,y_<t).
-
Foundation/AlphaCoordinateFixation.lean (parameter-free α-pinning via higher-derivative calibration)alpha_pin_under_high_calibration contradicts?
contradictsCONTRADICTS: the theorem conflicts with this paper passage, or marks a claim that would need revision before publication.
We use τ = 0.10 for sequence-level gating, τ = 0.005 for token-level gating, q = 0.10, and α = 50. ... performance is robust across α ∈ [10,100].
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2310.12036 , year=
Mohammad Gheshlaghi Azar, Mark Rowland, Bilal Piot, et al. A general theoretical paradigm to understand learning from human preferences.arXiv preprint arXiv:2310.12036,
-
[2]
Jinze Bai, Shuai Bai, et al. Qwen technical report.arXiv preprint arXiv:2309.16609,
-
[3]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Catherine McKinnon, Carol Chen, Catherine Olsson, Chris Olah, Danny Hernandez, Dawn Drain, Deep Ganguli, Dan Li, Evan Tran-Johnson, Ethan Perez, Jack Kerr, Jared Mueller, Jeffrey Ladish, Josh Landau, Kamal Ndousse, Kamil˙e Lu...
work page internal anchor Pith review arXiv
-
[4]
Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models
Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, and Quanquan Gu. Self-play fine-tuning converts weak language models to strong language models.arXiv preprint arXiv:2401.01335,
work page internal anchor Pith review arXiv
-
[5]
Ultrafeedback: Boosting language models with scaled ai feedback.arXiv preprint arXiv:2310.01377,
Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Wei Zhu, Yuan Ni, Guotong Xie, Zhiyuan Liu, and Maosong Sun. Ultrafeedback: Boosting language models with high-quality feedback.arXiv preprint arXiv:2310.01377,
-
[6]
KTO: Model Alignment as Prospect Theoretic Optimization
Kawin Ethayarajh, Winnie Xu, Niklas Muennighoff, Dan Jurafsky, and Douwe Kiela. Kto: Model alignment as prospect theoretic optimization.arXiv preprint arXiv:2402.01306,
work page internal anchor Pith review arXiv
-
[7]
Direct language model alignment from online ai feedback.arXiv preprint arXiv:2402.04792, 2024
Shangmin Guo, Biao Zhang, Tianlin Liu, Tianqi Liu, Misha Khalman, Felipe Llinares, Alexandre Rame, Thomas Mesnard, Yao Zhao, Bilal Piot, et al. Direct language model alignment from online ai feedback.arXiv preprint arXiv:2402.04792,
- [8]
-
[9]
In Findings of the Association for Computational Linguistics: ACL 2024, pages 4998–5017, 2024
Ryan Park, Rafael Rafailov, Stefano Ermon, and Chelsea Finn. Disentangling length from quality in direct preference optimization.arXiv preprint arXiv:2403.19159,
-
[10]
Direct Preference Optimization: Your Language Model is Secretly a Reward Model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, and Christopher D Manning. Di- rect preference optimization: Your language model is secretly a reward model.arXiv preprint arXiv:2305.18290,
work page internal anchor Pith review arXiv
-
[11]
Learning dynamics of llm finetuning.arXiv preprint arXiv:2407.10490,
arXiv:2407.10490v4. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
-
[12]
Preference fine-tuning of LLMs should leverage suboptimal, on-policy data,
Fahim Tajwar, Anikait Singh, Archit Sharma, Rafael Rafailov, Jeff Schneider, Tengyang Xie, Stefano Ermon, Chelsea Finn, and Aviral Kumar. Preference fine-tuning of llms should leverage suboptimal, on-policy data.arXiv preprint arXiv:2404.14367,
-
[13]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971,
work page internal anchor Pith review arXiv
-
[14]
Binghai Wang, Rui Dou, Shihan Dou, Songyang Gao, Wei Hua, Wei Shen, Yan Liu, Senjie Jin, Qin Liu, Yuhao Zhou, et al. Secrets of rlhf in large language models part ii: Reward modeling.arXiv preprint arXiv:2401.06080,
-
[15]
arXiv preprint arXiv:2405.00675 , year=
Yue Wu, Zhiqing Sun, Huizhuo Yuan, Kaixuan Ji, Yiming Yang, and Quanquan Gu. Self-play preference optimization for language model alignment.arXiv preprint arXiv:2405.00675,
- [16]
-
[17]
Haoran Xu, Amr Sharaf, Yunmo Chen, Weiting Tan, Lingfeng Shen, Benjamin Van Durme, Kenton Murray, and Young Jin Kim. Contrastive preference optimization: Pushing the boundaries of llm performance in machine translation.arXiv preprint arXiv:2401.08417,
-
[18]
Hui Yuan, Yifan Zeng, Yue Wu, Huazheng Wang, Mengdi Wang, and Liu Leqi. A common pitfall of margin-based language model alignment: Gradient entanglement.arXiv preprint arXiv:2410.13828, 2024a. Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Sainbayar Sukhbaatar, Jing Xu, and Jason Weston. Self-rewarding language models.arXiv preprint arXiv:2401.10020, 2...
-
[19]
Fine-Tuning Language Models from Human Preferences
Daniel M. Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B. Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. Fine-tuning language models from human preferences.arXiv preprint arXiv:1909.08593,
work page internal anchor Pith review arXiv 1909
-
[20]
Because Gate-DPO acts by scaling the rejected-response contribution before computing the loss, it applies naturally to Cal-DPO as well
12 A Modularity Beyond DPO Gate-Cal-DPO (Calibrated Direct Preference Optimization).Cal-DPO [Xiao et al., 2024] augments the standard contrastive preference objective with calibration terms that constrain the implicit rewards of chosen and rejected responses to remain on the scale of the ground-truth rewards. Because Gate-DPO acts by scaling the rejected-...
2024
-
[21]
Shaded bands mark success regions (τ∈[0.08,0.15] for seq_mean;[0.003,0.008]for q10)
15 Figure 4:Sensitivity to gating threshold τ.Sequence-level ( seq_mean) and token-level (q10) gating are evaluated across τ values on Pythia-410M (2k examples).Top:Chosen/rejected log-probability changes; positive ∆chosen indicates squeezing prevention.Middle:Gating rate and performance trade-off, showing optimal operating regions.Bottom:Gradient modulat...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.