Recognition: unknown
When Should a Language Model Trust Itself? Same-Model Self-Verification as a Conditional Confidence Signal
Pith reviewed 2026-05-10 17:29 UTC · model grok-4.3
The pith
Same-model self-verification serves as a conditional confidence signal for language models rather than a general uncertainty estimator.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
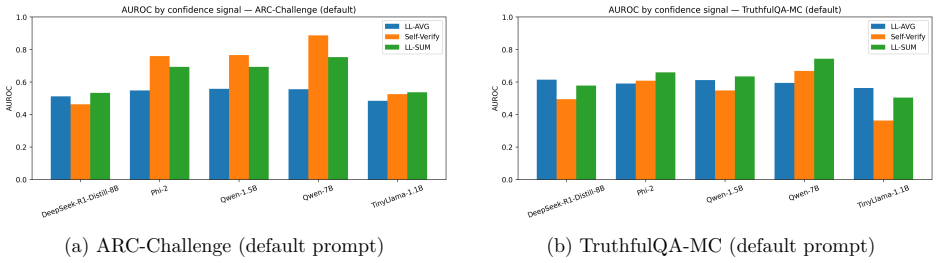
Same-model self-verification is evaluated against LL-AVG and LL-SUM likelihood baselines on ARC-Challenge and TruthfulQA-MC across model families, scales, and prompts. On ARC-Challenge self-verification substantially improves over LL-AVG for some models with largest gains in certain cases. On TruthfulQA-MC the signal is less reliable with prompt sensitivity in smaller models and degradation in others, while LL-SUM often remains stronger. The conclusion is that self-verification is a conditional confidence signal whose value depends on task type, model family, prompt formulation, and the baseline it must beat.
What carries the argument
Same-model self-verification prompting the model to audit its own predicted answer, assessed through correctness ranking and abstention quality using AURC and operating-point analyses.
If this is right
- Self-verification improves over the average likelihood baseline on factual reasoning tasks for multiple model families.
- Self-verification shows reduced reliability on truthfulness assessment tasks, where the sum likelihood baseline often performs better.
- Smaller models exhibit greater sensitivity to prompt formulation in self-verification setups.
- Self-verification should not be adopted as a default uncertainty estimator without task-specific validation.
Where Pith is reading between the lines
- In practice, teams deploying language models for selective answering may need to run targeted tests on their own tasks to determine if self-verification adds value over simple likelihood methods.
- Future work could investigate the reasons for task differences, such as how question format influences the effectiveness of self-auditing.
- Hybrid approaches that combine self-verification with likelihood scores might address cases where one signal alone is insufficient.
Load-bearing premise
The load-bearing premise is that the two likelihood baselines represent the strongest relevant comparisons and that differences seen on the two tested tasks will apply to other selective prediction settings.
What would settle it
Demonstrating consistent outperformance of self-verification over the strongest likelihood baseline on a broad set of additional tasks and models would challenge the view that it is only conditionally effective.
Figures












read the original abstract
Same-model self-verification, prompting a model to audit its own predicted answer, is a plausible confidence signal for selective prediction, but its practical value remains unclear once strong likelihood-based baselines are taken seriously. We evaluate self-verification against two such baselines, LL-AVG and LL-SUM, on ARC-Challenge and TruthfulQA-MC across multiple model families, scales, and prompt variants. We measure not only correctness ranking, but also abstention quality through AURC and operating-point analyses. The results are sharply task- and model-dependent. On ARC-Challenge, self-verification substantially improves over LL-AVG for Phi-2 and the Qwen models, with the largest gains appearing in Qwen-7B. On TruthfulQA-MC, however, the signal is less reliable: smaller models can become prompt-sensitive, DeepSeek-R1-Distill-8B degrades relative to LL-AVG, and LL-SUM often remains the stronger practical baseline. We therefore do not treat self-verification as a general-purpose uncertainty estimator. In this setting, it is better understood as a conditional confidence signal whose value depends on task type, model family, prompt formulation, and, crucially, the baseline it must beat.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper evaluates same-model self-verification as a confidence signal for selective prediction in LLMs. It compares this approach against two likelihood-based baselines (LL-AVG and LL-SUM) on ARC-Challenge and TruthfulQA-MC across multiple model families and scales. Using metrics including ranking quality and AURC for abstention performance, the results show that self-verification yields substantial gains over LL-AVG on ARC-Challenge for models like Qwen-7B and Phi-2, but is weaker or reversed on TruthfulQA-MC, where LL-SUM is often competitive and smaller models show prompt sensitivity. The central claim is that self-verification should be viewed as a conditional, task- and model-dependent signal rather than a general-purpose uncertainty estimator.
Significance. If the empirical patterns hold, the work provides a useful corrective to over-optimism about self-verification in uncertainty estimation for LLMs. By demonstrating clear task- and baseline-dependence and by including AURC and operating-point analyses, it supplies concrete guidance on when self-verification is worth deploying versus when stronger likelihood baselines suffice. The multi-model, multi-task design is a strength that helps bound the scope of the conclusion.
major comments (2)
- [Experimental Setup] Experimental Setup (likely §3 or §4): The manuscript does not provide the exact prompt templates or implementation details for self-verification, LL-AVG, and LL-SUM. Because the paper itself emphasizes prompt sensitivity as a key factor (especially for smaller models on TruthfulQA-MC), the absence of these templates prevents readers from reproducing the reported differences or assessing whether the observed variability is robust to minor prompt variations.
- [Results] Results and Analysis sections: No statistical significance tests (e.g., paired t-tests or bootstrap confidence intervals) are reported for the performance deltas, such as the gains for Qwen-7B on ARC-Challenge or the degradation for DeepSeek-R1-Distill-8B on TruthfulQA-MC. Given that the central claim rests on these task-dependent differences, the lack of significance testing leaves open whether the patterns exceed what could arise from sampling variability.
minor comments (2)
- [Experiments] The paper should clarify the exact data splits or evaluation subsets used for ARC-Challenge and TruthfulQA-MC to ensure the results are not sensitive to particular test-set choices.
- [Figures/Tables] Figure captions and table legends could more explicitly state the number of prompt variants tested per model to make the prompt-sensitivity claims easier to interpret at a glance.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback, which helps clarify key aspects of reproducibility and statistical rigor in our evaluation of self-verification. We respond to each major comment below.
read point-by-point responses
-
Referee: [Experimental Setup] Experimental Setup (likely §3 or §4): The manuscript does not provide the exact prompt templates or implementation details for self-verification, LL-AVG, and LL-SUM. Because the paper itself emphasizes prompt sensitivity as a key factor (especially for smaller models on TruthfulQA-MC), the absence of these templates prevents readers from reproducing the reported differences or assessing whether the observed variability is robust to minor prompt variations.
Authors: We agree that exact prompt templates are necessary for full reproducibility and for readers to evaluate robustness, particularly given our discussion of prompt sensitivity. In the revised manuscript we will add a dedicated appendix containing the complete prompt templates and implementation details for self-verification, LL-AVG, and LL-SUM across all models and tasks. This will enable direct replication and assessment of the variability we report. revision: yes
-
Referee: [Results] Results and Analysis sections: No statistical significance tests (e.g., paired t-tests or bootstrap confidence intervals) are reported for the performance deltas, such as the gains for Qwen-7B on ARC-Challenge or the degradation for DeepSeek-R1-Distill-8B on TruthfulQA-MC. Given that the central claim rests on these task-dependent differences, the lack of significance testing leaves open whether the patterns exceed what could arise from sampling variability.
Authors: We acknowledge that formal significance testing would strengthen the evidence for the observed task- and model-dependent patterns. Although the multi-model, multi-task design already provides convergent evidence, we did not report statistical tests in the original submission. In the revision we will add bootstrap confidence intervals for the key performance deltas and AURC differences to quantify whether the reported gains and degradations are statistically distinguishable from sampling variability. revision: yes
Circularity Check
No significant circularity in empirical evaluation
full rationale
This is a pure empirical comparison study evaluating same-model self-verification against LL-AVG and LL-SUM baselines on ARC-Challenge and TruthfulQA-MC across models and prompts. No mathematical derivations, equations, fitted parameters presented as predictions, or self-citation chains appear in the provided text or abstract. The central claim—that self-verification acts as a conditional (task-, model-, and baseline-dependent) signal rather than a general-purpose estimator—follows directly from observed performance patterns without reducing to any input by construction. The analysis is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption ARC-Challenge and TruthfulQA-MC are representative proxies for selective prediction needs in language model applications.
Reference graph
Works this paper leans on
-
[1]
Language Models (Mostly) Know What They Know
Language Models (Mostly) Know What They Know , author =. arXiv preprint arXiv:2207.05221 , year =. doi:10.48550/arXiv.2207.05221 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2207.05221
-
[2]
Transactions on Machine Learning Research , year =
Teaching Models to Express Their Uncertainty in Words , author =. Transactions on Machine Learning Research , year =
-
[3]
Constitutional AI: Harmlessness from AI Feedback
Constitutional AI: Harmlessness from AI Feedback , author =. arXiv preprint arXiv:2212.08073 , year =. doi:10.48550/arXiv.2212.08073 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2212.08073
-
[4]
Why Language Models Hallucinate
Why Language Models Hallucinate , author =. arXiv preprint arXiv:2509.04664 , year =. doi:10.48550/arXiv.2509.04664 , url =
work page internal anchor Pith review doi:10.48550/arxiv.2509.04664
-
[5]
Think You Have Solved Question Answering? Try
Clark, Peter and Cowhey, Isaac and Etzioni, Oren and Khot, Tushar and Sabharwal, Ashish and Schoenick, Carissa and Tafjord, Oyvind , journal =. Think You Have Solved Question Answering? Try. 2018 , doi =
2018
-
[6]
2022 , publisher =
Lin, Stephanie and Hilton, Jacob and Evans, Owain , booktitle =. 2022 , publisher =
2022
-
[7]
Uncertainty in natural language processing: Sources, quantification, and applications,
Uncertainty in Natural Language Processing: Sources, Quantification, and Applications , author =. arXiv preprint arXiv:2306.04459 , year =. doi:10.48550/arXiv.2306.04459 , url =
-
[8]
Nature , volume =
Detecting Hallucinations in Large Language Models Using Semantic Entropy , author =. Nature , volume =. 2024 , doi =
2024
-
[9]
Xiong, Miao and Hu, Zhiyuan and Lu, Xinyang and Li, Yifei and Fu, Jie and He, Junxian and Hooi, Bryan , journal =. Can. 2023 , doi =
2023
-
[10]
On Verbalized Confidence Scores for
Yang, Daniel and Tsai, Yao-Hung Hubert and Yamada, Makoto , journal =. On Verbalized Confidence Scores for. 2024 , doi =
2024
-
[11]
Nature , volume =
Large Language Models Encode Clinical Knowledge , author =. Nature , volume =. 2023 , doi =
2023
-
[12]
Proceedings of Machine Learning Research (NeurIPS 2023 Workshop) , volume =
Self-Evaluation Improves Selective Generation in Large Language Models , author =. Proceedings of Machine Learning Research (NeurIPS 2023 Workshop) , volume =. 2023 , url =
2023
-
[13]
Semantic Entropy Probes: Robust and Cheap Hallucination Detection in
Kossen, Jannik and Han, Jiatong and Razzak, Muhammed and Schut, Lisa and Malik, Shreshth and Gal, Yarin , journal =. Semantic Entropy Probes: Robust and Cheap Hallucination Detection in. 2024 , doi =
2024
-
[14]
2025 , eprint =
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author =. 2025 , eprint =
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.