Recognition: unknown
Finite-Size Gradient Transport in Large Language Model Pretraining: From Cascade Size to Intensive Transport Efficiency
Pith reviewed 2026-05-10 14:44 UTC · model grok-4.3
The pith
Finite-size gradient transport in LLM pretraining shares a near-unity cascade-size backbone but splits into distinct duration and efficiency regimes across model families.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
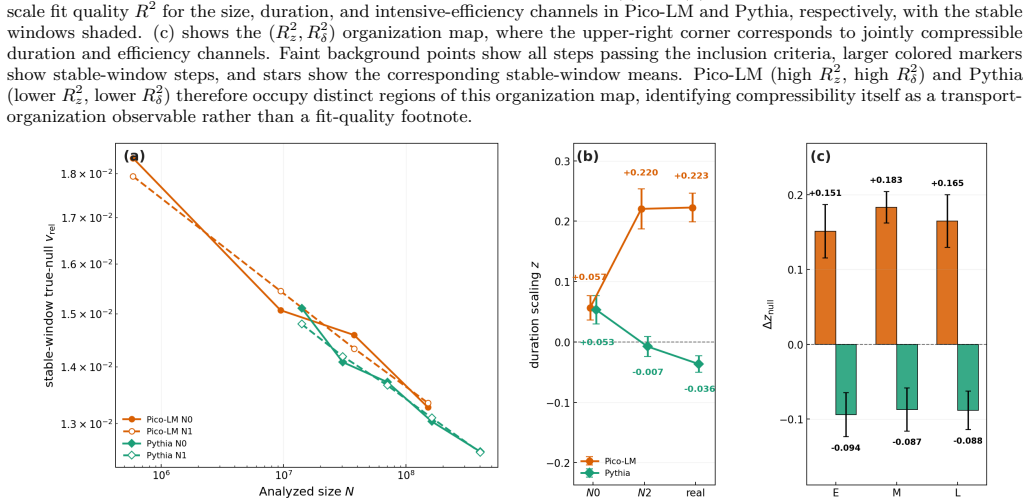
We introduce a finite-size gradient-transport framework for real language-model training, based on five observables (D, z, β, δ, v_rel) that separate cascade size, duration, absolute transport, and intensive transport efficiency. We analyze direct raw-gradient measurements from Pico-LM across four scales and 125 aligned steps, together with a five-scale Pythia companion dataset built from 153 aligned checkpoint-difference update fields. The same algebraic closure holds in both families, and both share a near-unity cascade-size backbone, but they occupy distinct transport regimes: Pico-LM shows positive duration scaling and negative intensive-efficiency scaling, whereas Pythia remains near D=
What carries the argument
The five observables D (cascade size), z, β, δ, and v_rel (intensive transport efficiency) that decompose finite-size gradient flow into separate channels for size, duration, absolute transport, and efficiency during pretraining.
If this is right
- Both Pico-LM and Pythia exhibit the same algebraic closure among the five observables.
- D(t) functions as a shared size backbone that lacks significant exponent-level association with downstream performance.
- Performance associations are carried mainly by v_rel and normalized cascade duration at the channel level.
- Pico-LM preserves clean power-law compressibility in duration and efficiency channels, while Pythia shows weaker one-slope compressibility outside the size backbone.
- The framework supports reusable transport measurements across models without requiring a universal fixed point.
Where Pith is reading between the lines
- If the regime split persists, training schedules might need family-specific tuning to exploit positive duration scaling in smaller models versus near-baseline behavior in larger ones.
- Applying the same five-observable decomposition to transformer variants beyond these two families could test whether the near-unity cascade backbone is architecture-independent.
- Longer training runs with finer step alignment might reveal whether the weak efficiency scaling in Pythia strengthens or saturates at even larger scales.
Load-bearing premise
The five observables and the aligned checkpoint steps capture the essential finite-size transport behavior without missing dominant mechanisms or requiring model-specific redefinitions.
What would settle it
Direct replication on a third model family or additional scales that shows either breakdown of the shared algebraic closure or disappearance of the regime contrast after identical randomized controls would falsify the claim of distinct transport regimes built on a common null skeleton.
Figures





read the original abstract
We introduce a finite-size gradient-transport framework for real language-model training, based on five observables $(D,z,\beta,\delta,v_{\mathrm{rel}})$ that separate cascade size, duration, absolute transport, and intensive transport efficiency. We analyze direct raw-gradient measurements from Pico-LM across four scales and 125 aligned steps, together with a five-scale Pythia companion dataset built from 153 aligned checkpoint-difference update fields. The same algebraic closure holds in both families, and both share a near-unity cascade-size backbone, but they occupy distinct transport regimes: Pico-LM shows positive duration scaling and negative intensive-efficiency scaling, whereas Pythia remains near the $D=1$ baseline with only weak positive efficiency scale dependence. Randomized-field controls give nearly matched null floors in the intensive and duration channels, indicating that the contrast reflects different real departures from a shared null skeleton rather than different null calibrations. The families also differ in stepwise power-law compressibility: Pico-LM retains clean duration and efficiency power laws, whereas Pythia preserves the size backbone but shows weaker one-slope compressibility in those channels. External performance associations are correspondingly channel-level, carried mainly by $v_{\mathrm{rel}}$ and normalized cascade duration, while $D(t)$ acts as a shared size backbone without a significant exponent-level performance association. These results support a reusable transport measurement framework without claiming a universal fixed point or a first-principles derivation of neural scaling laws.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a finite-size gradient-transport framework for LLM pretraining based on five observables (D, z, β, δ, v_rel) that separate cascade size, duration, absolute transport, and intensive efficiency. Using direct raw-gradient measurements from Pico-LM (four scales, 125 aligned steps) and a Pythia companion set (five scales, 153 aligned checkpoint differences), it reports that both families share an algebraic closure and near-unity D backbone, yet occupy distinct regimes: Pico-LM exhibits positive duration scaling and negative intensive-efficiency scaling, while Pythia remains near the D=1 baseline with only weak positive efficiency dependence. Randomized-field controls, stepwise power-law compressibility differences, and channel-level performance associations (mainly via v_rel and normalized duration) are also presented, without claiming universality or first-principles scaling-law derivations.
Significance. If the observables and alignment procedure prove robust, the work offers a reusable empirical measurement framework for comparing finite-size gradient transport across model families, highlighting shared structural features alongside regime-specific scaling behaviors that correlate with performance at the channel level. The provision of real-training data, randomized controls, and explicit contrasts between Pico-LM and Pythia is a constructive contribution that could inform future studies of why different pretraining setups depart differently from a common null skeleton.
major comments (2)
- [§3] §3 (Observables and Alignment Procedure): The central claim that the five observables plus the chosen step alignment fully capture essential finite-size transport behavior (and that the reported regime contrast is not an artifact) requires explicit robustness checks. No tests are shown for invariance under plausible alternatives such as token-based rather than step-based alignment, different gradient-magnitude normalizations, or inclusion of higher-order moments; without these, the Pico-LM vs. Pythia differences in duration and intensive-efficiency scaling remain vulnerable to measurement-basis artifacts.
- [§4.2] §4.2 (Algebraic Closure and D Backbone): The assertion that the same algebraic closure holds in both families and that D remains near unity as a shared size backbone is load-bearing for the 'distinct regimes' conclusion. The manuscript must clarify whether this closure is independently verified or reduces to a fitted relation by construction of the observables; the current presentation leaves open the possibility that the shared backbone is tautological rather than an empirical finding.
minor comments (2)
- [Abstract and §5] The abstract and §5 would benefit from a concise table summarizing the scaling exponents for each observable and family, including confidence intervals and the randomized-control baselines, to make the regime contrast immediately quantifiable.
- [§2] Notation for v_rel and the intensive-efficiency channel should be defined with an explicit equation on first use rather than relying on the parenthetical list in the abstract.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed report. We address each major comment below, indicating the changes we will make in revision.
read point-by-point responses
-
Referee: §3 (Observables and Alignment Procedure): The central claim that the five observables plus the chosen step alignment fully capture essential finite-size transport behavior requires explicit robustness checks. No tests are shown for invariance under plausible alternatives such as token-based rather than step-based alignment, different gradient-magnitude normalizations, or inclusion of higher-order moments.
Authors: We agree that additional robustness checks would strengthen the manuscript. In the revised version we will add tests for alternative gradient-magnitude normalizations (L1 versus L2) and inclusion of selected higher-order moments on a representative subset of the data. Token-based alignment cannot be performed because the released checkpoints are provided only at fixed training steps; we will state this limitation explicitly and note that step-based alignment was required for consistency with the available logs. The existing randomized-field controls already address some measurement artifacts, but the new normalization checks will be included. revision: partial
-
Referee: §4.2 (Algebraic Closure and D Backbone): The assertion that the same algebraic closure holds in both families and that D remains near unity must clarify whether this closure is independently verified or reduces to a fitted relation by construction of the observables.
Authors: The algebraic closure follows directly from the definitions of the five observables and is not imposed by any fitting procedure. In the revision we will insert a dedicated paragraph in §4.2 that (i) derives the closure from the observable definitions, (ii) reports the empirical residuals computed on the raw Pico-LM and Pythia measurements, and (iii) confirms that the near-unity D backbone is an observed feature of the data rather than a fitted constraint. This will eliminate any ambiguity about tautology. revision: yes
- Full token-based alignment robustness checks, because the released checkpoint data are available only at fixed step intervals.
Circularity Check
No significant circularity; empirical measurement framework
full rationale
The paper introduces five observables (D, z, β, δ, v_rel) to separate aspects of finite-size gradient transport and reports empirical findings that algebraic closure holds across two model families on aligned checkpoint data. No equations, derivations, or self-citations appear in the provided text that would reduce the reported closure, scaling relations, or regime distinctions to the definitions or inputs by construction. The work is explicitly framed as an empirical analysis of raw measurements rather than a first-principles derivation or closed prediction, with randomized controls used to validate departures from null behavior. No load-bearing step reduces to a fitted parameter renamed as prediction or to an ansatz smuggled via citation.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Raw gradients from checkpoint differences provide a faithful proxy for transport dynamics during pretraining.
- domain assumption The algebraic closure relation among the five observables is model-family independent at the level of the size backbone.
invented entities (1)
-
Finite-size gradient-transport observables (D, z, β, δ, v_rel)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Pico-LM (primary raw-gradient family) Pico-LM [17] is the primary raw-gradient fam- ily analyzed in this study. We use the four re- leasedpico-decodermodels (tiny, small, medium, and large), a LLaMA-style decoder-only family trained un- der matched settings onpretokenized-dolma, derived from Dolma [22]. These runs have nominal model sizes of 11M, 65M, 181...
-
[2]
These are GPT-NeoX-based autoregressive language models [24] trained on the Pile [25]
Pythia/PolyPythias (checkpoint-difference companion family) The checkpoint-difference companion family is drawn from the Pythia project [18] and the PolyPythias seed extensions [19]. These are GPT-NeoX-based autoregressive language models [24] trained on the Pile [25]. In the present analysis we use the five seed-3 released runspythia-14m-seed3,pythia-31m...
-
[3]
learning-rate-partial
External performance metrics and learning-rate partial correlations For Pico-LM, the external performance metric is a perplexity scaling exponentβ PPL(t), defined as the log- log slope∂log PPL/∂logNfitted across the four train- ing scales at each step using the per-checkpoint Paloma perplexity [17, 23] evaluated on thepico-paloma-tinsy subset. For Pythia,...
-
[4]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Radford, J. Wu, and D. Amodei, arXiv preprint arXiv:2001.08361 10.48550/arXiv.2001.08361 (2020)
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2001.08361 2001
-
[5]
Training Compute-Optimal Large Language Models
J. Hoffmann, S. Borgeaud, A. Mensch, E. Buchatskaya, T. Cai, E. Rutherford, D. de las Casas, L. A. Hen- dricks, J. Welbl, A. Clark, T. Hennigan, E. Noland, K. Millican, G. van den Driessche, B. Damoc, A. Guy, S. Osindero, K. Simonyan, E. Elsen, O. Vinyals, J. W. Rae, and L. Sifre, inAdvances in Neural Information Processing Systems, Vol. 35 (2022) pp. 300...
work page internal anchor Pith review arXiv 2022
-
[6]
A. M. Saxe, J. L. McClelland, and S. Ganguli, inInter- national Conference on Learning Representations(2014) arXiv:1312.6120
work page Pith review arXiv 2014
-
[7]
Poole, S
B. Poole, S. Lahiri, M. Raghu, J. Sohl-Dickstein, and S. Ganguli, inAdvances in Neural Information Processing Systems 29(2016) pp. 3360–3368
2016
-
[8]
S. S. Schoenholz, J. Gilmer, S. Ganguli, and J. Sohl- Dickstein, inInternational Conference on Learning Rep- resentations(2017)
2017
-
[9]
Grokking: Generalization Beyond Overfitting on Small Algorithmic Datasets
A. Power, Y. Burda, H. Edwards, I. Babuschkin, and V. Misra, arXiv preprint arXiv:2201.02177 10.48550/arXiv.2201.02177 (2022)
work page internal anchor Pith review doi:10.48550/arxiv.2201.02177 2022
-
[10]
Nanda, L
N. Nanda, L. Chan, T. Lieberum, J. Smith, and J. Stein- hardt, inInternational Conference on Learning Repre- sentations(2023)
2023
-
[11]
Cohen, S
J. Cohen, S. Kaur, Y. Li, J. Z. Kolter, and A. Talwalkar, inInternational Conference on Learning Representations (2021)
2021
-
[12]
A. Lewkowycz, Y. Bahri, E. Dyer, J. Sohl-Dickstein, and G. Gur-Ari, arXiv preprint arXiv:2003.02218 10.48550/arXiv.2003.02218 (2020)
-
[13]
In-context Learning and Induction Heads
C. Olsson, N. Elhage, N. Nanda, N. Joseph, N. Das- Sarma, T. Henighan, B. Mann, A. Askell, Y. Bai, A. Chen, T. Conerly, D. Drain, D. Ganguli, Z. Hatfield- Dodds, D. Hernandez, S. Johnston, A. Jones, J. Kernion, L. Lovitt, K. Ndousse, D. Amodei, T. Brown, J. Clark, J. Kaplan, S. McCandlish, and C. Olah, Transformer Circuits Thread 10.48550/arXiv.2209.11895...
work page internal anchor Pith review doi:10.48550/arxiv.2209.11895 2022
-
[14]
P. Bak, C. Tang, and K. Wiesenfeld, Phys. Rev. Lett.59, 381 (1987)
1987
-
[15]
Olami, H
Z. Olami, H. J. S. Feder, and K. Christensen, Phys. Rev. Lett.68, 1244 (1992)
1992
-
[16]
J. P. Sethna, K. A. Dahmen, and C. R. Myers, Nature 410, 242 (2001)
2001
-
[17]
M. E. Fisher and M. N. Barber, Phys. Rev. Lett.28, 1516 (1972)
1972
-
[18]
Grokking as Dimensional Phase Transition in Neural Networks
P. Wang, Grokking as dimensional phase transition in neural networks (2026), arXiv preprint, submitted 6 Apr 2026, arXiv:2604.04655 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[19]
Dimensional Criticality at Grokking Across MLPs and Transformers
P. Wang, Dimensional criticality at grokking across MLPs and Transformers (2026), arXiv preprint, submit- ted 6 Apr 2026, arXiv:2604.16431 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
Diehl Martinez, D
R. Diehl Martinez, D. D. Africa, Y. Weiss, S. Sal- han, R. Daniels, and P. Buttery, inProceedings of the 2025 Conference on Empirical Methods in Natural Lan- guage Processing: System Demonstrations(Association for Computational Linguistics, Suzhou, China, 2025) pp. 295–306
2025
-
[21]
S. Biderman, H. Schoelkopf, Q. G. Anthony, H. Bradley, K. O’Brien, E. Hallahan, M. A. Khan, S. Purohit, U. S. Prashanth, E. Raff, A. Skowron, L. Sutawika, and O. Van Der Wal, inProceedings of the 40th International Con- ference on Machine Learning, Proceedings of Machine Learning Research, Vol. 202 (PMLR, 2023) pp. 2397– 2430, arXiv:2304.01373
-
[22]
O. van der Wal, P. Lesci, M. M¨ uller-Eberstein, N. Saphra, H. Schoelkopf, W. H. Zuidema, and S. R. Biderman, inInternational Conference on Learning Representations (2025) openReview: bmrYu2Ekdz, arXiv:2503.09543, arXiv:2503.09543
-
[23]
Barab´ asi and R
A.-L. Barab´ asi and R. Albert, Science286, 509 (1999)
1999
-
[24]
D. P. Kingma and J. Ba, in3rd International Conference on Learning Representations, ICLR 2015(San Diego, CA, USA, 2015) arXiv:1412.6980
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[25]
22 Kaiqiang Song, Xiaoyang Wang, Sangwoo Cho, Xiaoman Pan, and Dong Yu
L. Soldaini, R. Kinney, A. Bhagia, D. Schwenk, D. Atkinson, R. Authur, B. Bogin, K. Chandu, J. Du- mas, Y. Elazar, V. Hofmann, A. Jha, S. Kumar, L. Lucy, X. Lyu, N. Lambert, I. Magnusson, J. Mor- rison, N. Muennighoff, A. Naik, C. Nam, M. Peters, A. Ravichander, K. Richardson, Z. Shen, E. Strubell, N. Subramani, O. Tafjord, E. Walsh, L. Zettlemoyer, N. Sm...
-
[26]
and Richardson, Kyle and Dodge, Jesse , year =
I. Magnusson, A. Bhagia, V. Hofmann, L. Soldaini, A. H. Jha, O. Tafjord, D. Schwenk, E. P. Walsh, Y. Elazar, K. Lo, D. Groeneveld, I. Beltagy, H. Hajishirzi, N. A. Smith, K. Richardson, and J. Dodge, arXiv preprint arXiv:2312.10523 (2023)
-
[27]
Andonian, Q
A. Andonian, Q. Anthony, S. Biderman, S. Black, P. Gali, L. Gao, E. Hallahan, J. Levy-Kramer, C. Leahy, L. Nestler, K. Parker, M. Pieler, J. Phang, S. Puro- hit, H. Schoelkopf, D. Stander, T. Songz, C. Tigges, B. Th´ erien, P. Wang, and S. Weinbach, GPT-NeoX: Large Scale Autoregressive Language Modeling in Py- Torch (2023)
2023
-
[28]
L. Gao, S. Biderman, S. Black, L. Golding, T. Hoppe, C. Foster, J. Phang, H. He, A. Thite, N. Nabeshima, S. Presser, and C. Leahy, arXiv preprint arXiv:2101.00027 10.48550/arXiv.2101.00027 (2020)
work page internal anchor Pith review doi:10.48550/arxiv.2101.00027 2020
-
[29]
Measuring Massive Multitask Language Understanding
D. Hendrycks, C. Burns, S. Basart, A. Zou, M. Mazeika, D. Song, and J. Steinhardt, inInternational Conference on Learning Representations(2021) arXiv:2009.03300
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[30]
Sutawika, H
L. Sutawika, H. Schoelkopf, L. Gao, B. Abbasi, S. Biderman, J. Tow, B. Fattori, C. Lovering, Farzanehnakhaee70, J. Phang, A. Thite, Fazz, T. Wang, Niklas, Aflah, Sdtblck, Nopperl, Gakada, Tttyuntian, Researcher2, J. Etxaniz, Chris, J. A. Michaelov, H. A. Lee, Janna, L. Sinev, Khalid, K. Stokes, Z. Kasner, and KonradSzafer, EleutherAI/lm-evaluation-harness...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.