Recognition: no theorem link
Structured Diffusion Bridges: Inductive Bias for Denoising Diffusion Bridges
Pith reviewed 2026-05-13 07:03 UTC · model grok-4.3
The pith
Alignment constraints let diffusion bridges achieve near fully-paired modality translation quality even with unpaired data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce structured diffusion bridges that explicitly characterize the space of admissible cross-modal solutions and restrict it via alignment constraints, treating paired supervision as an optional heuristic. On synthetic and real benchmarks the method delivers consistent performance across supervision levels and reaches near fully-paired quality while remaining effective in the unpaired regime.
What carries the argument
Structured diffusion bridges that use alignment constraints to bias the denoising process toward consistent cross-modal mappings.
If this is right
- Performance stays stable from fully unpaired through semi-paired to fully paired regimes.
- Near fully-paired translation quality is reachable with substantially fewer paired examples.
- The same framework remains usable when no paired data at all is available.
- Diffusion bridges become a flexible base for modality translation that does not presuppose full pairing.
Where Pith is reading between the lines
- Collecting paired data for new modality pairs could become far less expensive if alignment constraints can be derived from weaker signals.
- Similar inductive biases might substitute for supervision in other under-constrained generative tasks.
- The approach suggests a general strategy: first enumerate admissible solutions, then apply cheap structural constraints to select among them.
Load-bearing premise
Alignment constraints are enough to narrow the space of admissible mappings down to those that produce high-quality translations without needing complete pairing.
What would settle it
Observe whether the method collapses to low-quality outputs on an unpaired dataset where many distinct mappings satisfy the marginals yet violate the alignment constraints.
Figures






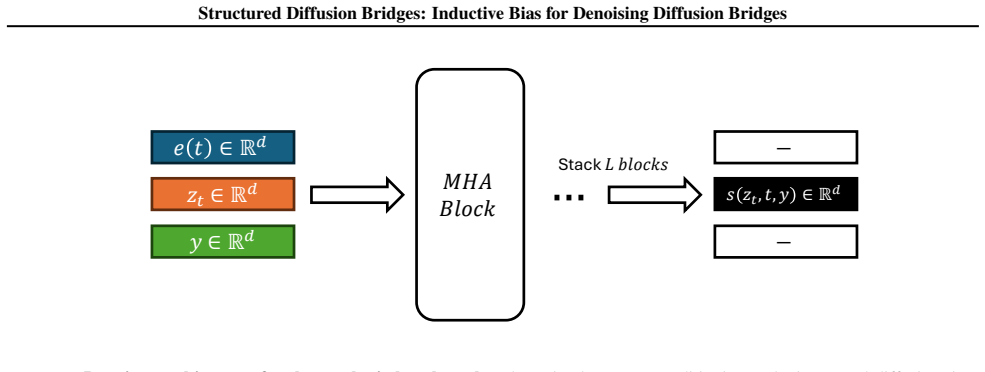

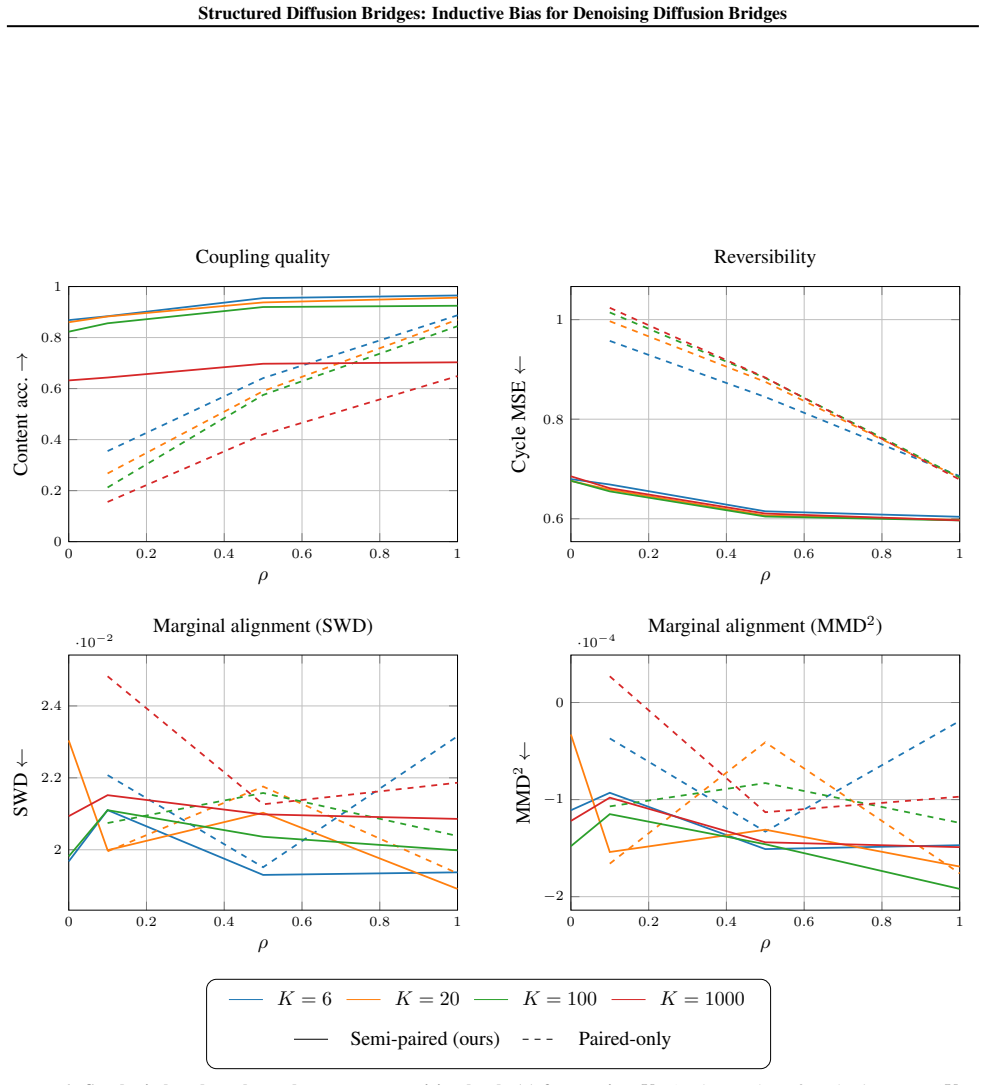








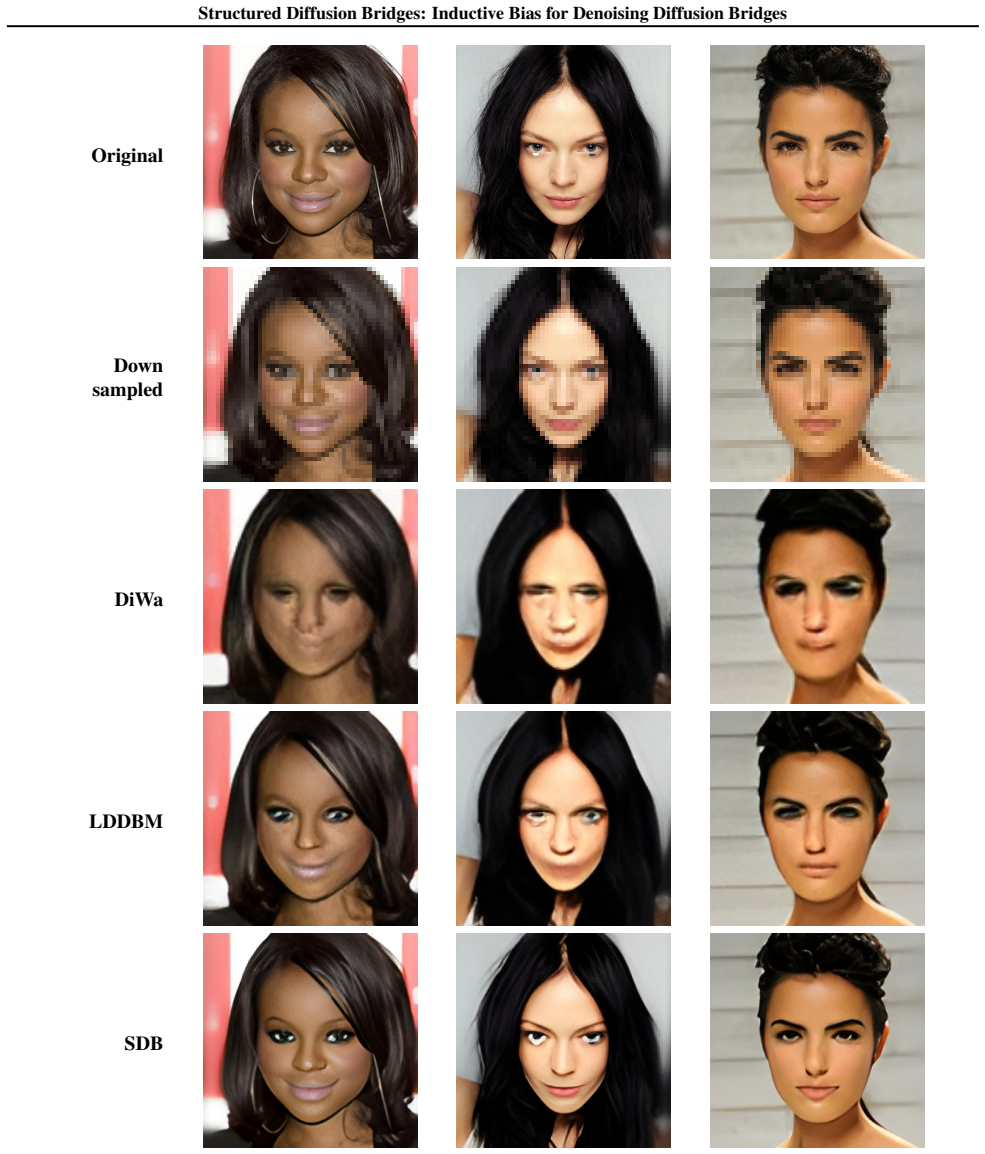









read the original abstract
Modality translation is inherently under-constrained, as multiple cross-modal mappings may yield the same marginals. Recent work has shown that diffusion bridges are effective for this task. However, most existing approaches rely on fully paired datasets, thereby imposing a single data-driven constraint. We propose a diffusion-bridge framework that characterizes the space of admissible solutions and restricts it via alignment constraints, treating paired supervision as an optional heuristic rather than a prerequisite. We validate our method on synthetic and real modality translation benchmarks across unpaired, semi-paired, and paired regimes, showing consistent performance across supervision levels. Notably, \textbf{it achieves near fully-paired quality with a substantial relaxation in pairing requirements, and remaining applicable in the unpaired regime}. These results highlight diffusion bridges as a flexible foundation for modality translation beyond fully paired data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Structured Diffusion Bridges, a framework for modality translation that characterizes the under-constrained space of cross-modal mappings (which share marginals) and restricts it via alignment constraints. Paired supervision is treated as an optional heuristic rather than a requirement. The method is evaluated on synthetic and real benchmarks across unpaired, semi-paired, and paired regimes, with the central claim that it achieves near fully-paired quality while remaining applicable in the unpaired regime.
Significance. If the central claim holds, the work would be significant for diffusion-based modality translation, as it relaxes the strong requirement for fully paired data that limits many existing bridge methods. This could enable broader use in settings where paired examples are scarce or expensive to obtain, while still leveraging the generative strengths of diffusion bridges.
major comments (3)
- [§3] §3 (Method): The manuscript states that alignment constraints restrict the space of admissible bridges, but does not provide the explicit loss formulation, score-matching term, or architectural mechanism by which these constraints are enforced on the diffusion process. Without this, it is unclear whether the constraints are sufficient to exclude semantically inconsistent mappings that still match the marginals, especially in the fully unpaired regime.
- [§4.2] §4.2 (Experiments, unpaired regime): The claim of 'near fully-paired quality' is load-bearing for the contribution, yet the reported metrics, baselines, and error bars are not detailed enough to verify that the alignment constraints (rather than other factors) are responsible for the observed performance. A direct ablation removing the alignment terms while keeping the bridge structure would be needed to isolate their effect.
- [§2] §2 (Related Work): The positioning against prior diffusion-bridge methods for translation does not include a quantitative comparison of pairing requirements or a clear statement of how the proposed inductive bias differs formally from existing conditional or paired bridge constructions.
minor comments (2)
- [Abstract] Abstract: The phrase 'remaining applicable in the unpaired regime' appears to be a grammatical error and should be revised for clarity.
- [§3] Notation: The definition of the alignment constraint function is introduced without an explicit equation number, making it difficult to reference in later sections.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (Method): The manuscript states that alignment constraints restrict the space of admissible bridges, but does not provide the explicit loss formulation, score-matching term, or architectural mechanism by which these constraints are enforced on the diffusion process. Without this, it is unclear whether the constraints are sufficient to exclude semantically inconsistent mappings that still match the marginals, especially in the fully unpaired regime.
Authors: We agree that the explicit formulation of the alignment constraints requires further detail. In the revised manuscript we will add the precise loss expression, the modified score-matching objective that incorporates the alignment term, and the architectural components (e.g., the projection layers and constraint enforcement modules) used to apply these constraints during the diffusion process. These additions will clarify how the constraints exclude semantically inconsistent mappings while preserving marginal consistency, including in the unpaired regime. revision: yes
-
Referee: [§4.2] §4.2 (Experiments, unpaired regime): The claim of 'near fully-paired quality' is load-bearing for the contribution, yet the reported metrics, baselines, and error bars are not detailed enough to verify that the alignment constraints (rather than other factors) are responsible for the observed performance. A direct ablation removing the alignment terms while keeping the bridge structure would be needed to isolate their effect.
Authors: We acknowledge that the current experimental section would benefit from greater transparency. In the revision we will report all metrics with standard error bars computed over multiple random seeds, explicitly list every baseline and its pairing regime, and include a direct ablation that removes the alignment loss terms while retaining the diffusion-bridge architecture. This ablation will isolate the contribution of the alignment constraints to the observed performance in the unpaired setting. revision: yes
-
Referee: [§2] §2 (Related Work): The positioning against prior diffusion-bridge methods for translation does not include a quantitative comparison of pairing requirements or a clear statement of how the proposed inductive bias differs formally from existing conditional or paired bridge constructions.
Authors: We thank the referee for this observation. We will expand §2 with a table that quantitatively compares the pairing requirements of prior diffusion-bridge translation methods. We will also add a concise formal statement that contrasts our alignment-constraint inductive bias with existing conditional and paired bridge formulations, highlighting the differences in the admissible function space each approach restricts. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes a diffusion-bridge framework that restricts admissible solutions via alignment constraints and validates it empirically across unpaired, semi-paired, and paired regimes. No load-bearing derivation steps, equations, or self-citations are exhibited that reduce the central claims to fitted inputs, self-definitions, or prior author results by construction. Performance claims (near fully-paired quality with relaxed pairing) are presented as experimental outcomes rather than mathematical necessities derived from the inputs themselves. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
work page 2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
work page 1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
work page 1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
work page 2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
work page 1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
work page 1959
-
[9]
Advances in Neural Information Processing Systems , volume=
Towards general modality translation with contrastive and predictive latent diffusion bridge , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
Classical potential theory and its probabilistic counterpart , author=. 1984 , publisher=
work page 1984
- [11]
-
[12]
U-net: Convolutional networks for biomedical image segmentation , author=. Medical image computing and computer-assisted intervention--MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18 , pages=. 2015 , organization=
work page 2015
-
[13]
Representation Learning with Contrastive Predictive Coding
Representation learning with contrastive predictive coding , author=. arXiv preprint arXiv:1807.03748 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
International conference on machine learning , pages=
A simple framework for contrastive learning of visual representations , author=. International conference on machine learning , pages=. 2020 , organization=
work page 2020
-
[15]
Allan Jabri and David J. Fleet and Ting Chen , title =. International Conference on Machine Learning,
-
[16]
Machine Translation with Large Language Models: Decoder Only vs. Encoder-Decoder , author=. 2024 , eprint=
work page 2024
-
[17]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale , author=. 2021 , eprint=
work page 2021
-
[18]
Muhammad Zayyanu Ph.D, Zaki , year =. Revolutionising Translation Technology: A Comparative Study of Variant Transformer Models - BERT, GPT, and T5 , volume =. Computer Science and Engineering An International Journal , doi =
-
[19]
Qorib, Muhammad and Moon, Geonsik and Ng, Hwee Tou. Are Decoder-Only Language Models Better than Encoder-Only Language Models in Understanding Word Meaning?. Findings of the Association for Computational Linguistics: ACL 2024. 2024. doi:10.18653/v1/2024.findings-acl.967
-
[20]
Boyu Liu , title=. Proceedings of the 1st International Conference on Data Science and Engineering - Volume 1: ICDSE , year=. doi:10.5220/0012829800004547 , isbn=
-
[21]
Deep residual learning for image recognition. 2016 IEEE Conf , author=. Comput. Vis. Pattern Recognit , pages=
work page 2016
- [22]
-
[23]
Advances in neural information processing systems , volume=
Generative adversarial nets , author=. Advances in neural information processing systems , volume=
-
[24]
International conference on machine learning , pages=
Deep unsupervised learning using nonequilibrium thermodynamics , author=. International conference on machine learning , pages=. 2015 , organization=
work page 2015
-
[25]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[26]
Yaron Lipman and Ricky T. Q. Chen and Heli Ben. Flow Matching for Generative Modeling , booktitle =
-
[27]
Score-Based Generative Modeling through Stochastic Differential Equations , booktitle =
Yang Song and Jascha Sohl. Score-Based Generative Modeling through Stochastic Differential Equations , booktitle =
-
[28]
9th International Conference on Learning Representations,
Jiaming Song and Chenlin Meng and Stefano Ermon , title =. 9th International Conference on Learning Representations,
-
[29]
9th International Conference on Learning Representations,
Zhifeng Kong and Wei Ping and Jiaji Huang and Kexin Zhao and Bryan Catanzaro , title =. 9th International Conference on Learning Representations,
-
[30]
Advances in Neural Information Processing Systems , volume=
Video diffusion models , author=. Advances in Neural Information Processing Systems , volume=
-
[31]
Advances in neural information processing systems , volume=
Diffusion models beat gans on image synthesis , author=. Advances in neural information processing systems , volume=
-
[32]
International conference on machine learning , pages=
Improved denoising diffusion probabilistic models , author=. International conference on machine learning , pages=. 2021 , organization=
work page 2021
-
[33]
Advances in neural information processing systems , volume=
Elucidating the design space of diffusion-based generative models , author=. Advances in neural information processing systems , volume=
-
[34]
Classifier-Free Diffusion Guidance
Classifier-free diffusion guidance , author=. arXiv preprint arXiv:2207.12598 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[35]
Advances in Neural Information Processing Systems , volume=
Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
Machine Intelligence Research , volume=
Dpm-solver++: Fast solver for guided sampling of diffusion probabilistic models , author=. Machine Intelligence Research , volume=. 2025 , publisher=
work page 2025
-
[37]
The Eleventh International Conference on Learning Representations,
Qinsheng Zhang and Yongxin Chen , title =. The Eleventh International Conference on Learning Representations,
-
[38]
International Conference on Machine Learning , pages=
simple diffusion: End-to-end diffusion for high resolution images , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[39]
arXiv preprint arXiv:2303.13336 , year=
A survey on audio diffusion models: Text to speech synthesis and enhancement in generative ai , author=. arXiv preprint arXiv:2303.13336 , year=
-
[40]
ACM Computing Surveys , volume=
Diffusion models: A comprehensive survey of methods and applications , author=. ACM Computing Surveys , volume=. 2023 , publisher=
work page 2023
-
[41]
DiGress: Discrete Denoising diffusion for graph generation , booktitle =
Cl. DiGress: Discrete Denoising diffusion for graph generation , booktitle =
-
[42]
International conference on machine learning , pages=
Autoregressive diffusion model for graph generation , author=. International conference on machine learning , pages=. 2023 , organization=
work page 2023
-
[43]
International Conference on Artificial Intelligence and Statistics , pages=
Permutation invariant graph generation via score-based generative modeling , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2020 , organization=
work page 2020
-
[44]
International conference on machine learning , pages=
Score-based generative modeling of graphs via the system of stochastic differential equations , author=. International conference on machine learning , pages=. 2022 , organization=
work page 2022
-
[45]
Qi Yan and Zhengyang Liang and Yang Song and Renjie Liao and Lele Wang , title =. Trans. Mach. Learn. Res. , volume =
-
[46]
Nimrod Berman and Eitan Kosman and Dotan Di Castro and Omri Azencot , title =. Trans. Mach. Learn. Res. , volume =
-
[47]
Advances in neural information processing systems , volume=
Sequence to sequence learning with neural networks , author=. Advances in neural information processing systems , volume=
-
[48]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Image captioning with semantic attention , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[49]
6th International Conference on Learning Representations,
Guillaume Lample and Alexis Conneau and Ludovic Denoyer and Marc'Aurelio Ranzato , title =. 6th International Conference on Learning Representations,
-
[50]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Image-to-image translation with conditional adversarial networks , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[51]
Proceedings of the IEEE international conference on computer vision , pages=
Unpaired image-to-image translation using cycle-consistent adversarial networks , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[52]
arXiv preprint arXiv:1707.01400 , year=
Aligngan: Learning to align cross-domain images with conditional generative adversarial networks , author=. arXiv preprint arXiv:1707.01400 , year=
-
[53]
2018 IEEE Spoken Language Technology Workshop (SLT) , pages=
Stargan-vc: Non-parallel many-to-many voice conversion using star generative adversarial networks , author=. 2018 IEEE Spoken Language Technology Workshop (SLT) , pages=. 2018 , organization=
work page 2018
-
[54]
International Conference on Machine Learning , pages=
Autovc: Zero-shot voice style transfer with only autoencoder loss , author=. International Conference on Machine Learning , pages=. 2019 , organization=
work page 2019
-
[55]
20th Annual Conference of the International Speech Communication Association, Interspeech , pages =
Steffen Schneider and Alexei Baevski and Ronan Collobert and Michael Auli , title =. 20th Annual Conference of the International Speech Communication Association, Interspeech , pages =
-
[56]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Deep supervised cross-modal retrieval , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[57]
Advances in neural information processing systems , volume=
wav2vec 2.0: A framework for self-supervised learning of speech representations , author=. Advances in neural information processing systems , volume=
-
[58]
Computerized medical imaging and graphics , volume=
MedGAN: Medical image translation using GANs , author=. Computerized medical imaging and graphics , volume=. 2020 , publisher=
work page 2020
-
[59]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Adabins: Depth estimation using adaptive bins , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[60]
Proceedings of the 38th International Conference on Machine Learning,
Aditya Ramesh and Mikhail Pavlov and Gabriel Goh and Scott Gray and Chelsea Voss and Alec Radford and Mark Chen and Ilya Sutskever , title =. Proceedings of the 38th International Conference on Machine Learning,
-
[61]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
work page 2021
-
[62]
De Bortoli, Valentin and Thornton, James and Heng, Jeremy and Doucet, Arnaud , journal=. Diffusion schr
-
[63]
Barron and Ben Mildenhall , title =
Ben Poole and Ajay Jain and Jonathan T. Barron and Ben Mildenhall , title =. The Eleventh International Conference on Learning Representations,
-
[64]
Guan. I\(. International Conference on Machine Learning,
-
[65]
Shi, Yuyang and De Bortoli, Valentin and Campbell, Andrew and Doucet, Arnaud , journal=. Diffusion schr
-
[66]
The Twelfth International Conference on Learning Representations,
Linqi Zhou and Aaron Lou and Samar Khanna and Stefano Ermon , title =. The Twelfth International Conference on Learning Representations,
-
[67]
International Conference on Learning Representations , volume=
Diffusion bridge implicit models , author=. International Conference on Learning Representations , volume=
-
[68]
Advances in Neural Information Processing Systems 38 , year =
Guande He and Kaiwen Zheng and Jianfei Chen and Fan Bao and Jun Zhu , title =. Advances in Neural Information Processing Systems 38 , year =
-
[69]
arXiv preprint arXiv:2412.19992 , year=
An Ordinary Differential Equation Sampler with Stochastic Start for Diffusion Bridge Models , author=. arXiv preprint arXiv:2412.19992 , year=
-
[70]
Albergo and Mark Goldstein and Nicholas Matthew Boffi and Rajesh Ranganath and Eric Vanden
Michael S. Albergo and Mark Goldstein and Nicholas Matthew Boffi and Rajesh Ranganath and Eric Vanden. Stochastic Interpolants with Data-Dependent Couplings , booktitle =
-
[71]
Flowing from Words to Pixels: A Framework for Cross-Modality Evolution , author=. arXiv preprint arXiv:2412.15213 , year=
-
[72]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Flowtok: Flowing seamlessly across text and image tokens , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[73]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Imagebind: One embedding space to bind them all , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[74]
The Twelfth International Conference on Learning Representations,
Bin Zhu and Bin Lin and Munan Ning and Yang Yan and Jiaxi Cui and Hongfa Wang and Yatian Pang and Wenhao Jiang and Junwu Zhang and Zongwei Li and Caiwan Zhang and Zhifeng Li and Wei Liu and Li Yuan , title =. The Twelfth International Conference on Learning Representations,
-
[75]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Scalable diffusion models with transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[76]
European Conference on Computer Vision , pages=
Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers , author=. European Conference on Computer Vision , pages=. 2024 , organization=
work page 2024
-
[77]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[78]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Multi-view 3d reconstruction with transformers , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[79]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
3d shape generation and completion through point-voxel diffusion , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[80]
Make-A-Video: Text-to-Video Generation without Text-Video Data
Make-a-video: Text-to-video generation without text-video data , author=. arXiv preprint arXiv:2209.14792 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.