Recognition: 2 theorem links
· Lean TheoremTerminus-4B: Can a Smaller Model Replace Frontier LLMs at Agentic Execution Tasks?
Pith reviewed 2026-05-08 18:05 UTC · model grok-4.3
The pith
A 4B model can match frontier LLMs at agentic terminal execution tasks
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
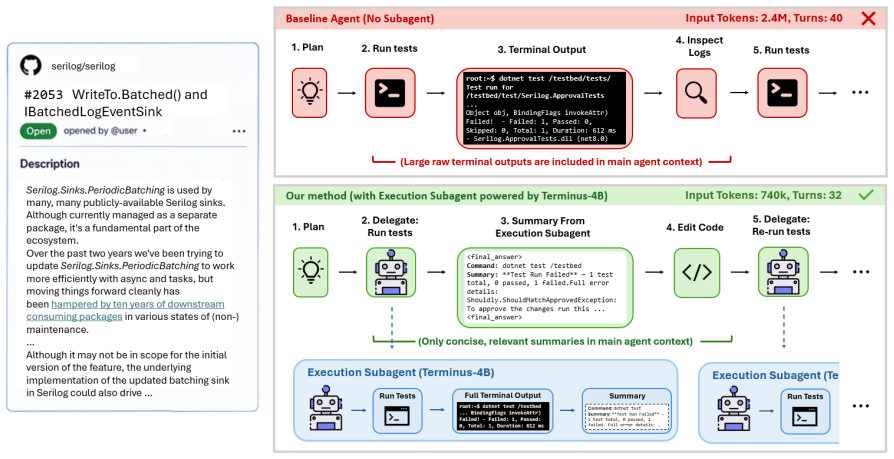
Terminus-4B is a post-trained Qwen3-4B model via SFT and RL using rubric-based LLM-as-judge reward for agentic terminal execution. It reduces the main agent's token usage by up to 30% compared to the No Subagent baseline with no impact to agent performance on benchmarks like SWE-Bench Pro and the internal SWE-Bench C# benchmark. The model also improves metrics that show the main agent relying more on subagent outputs and performing fewer terminal tasks itself, closing the gap to frontier models like Claude Sonnet, Opus, and GPT-5.3-Codex and often exceeding their performance.
What carries the argument
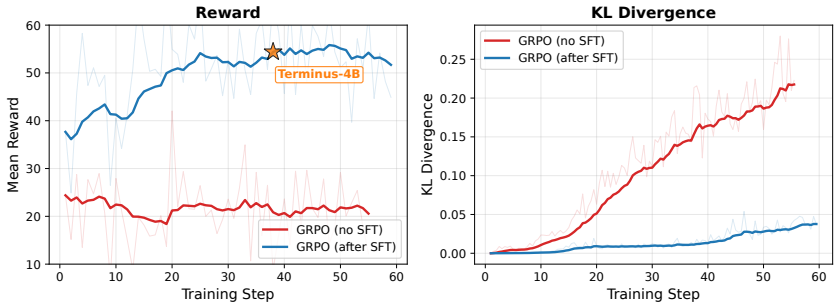
Terminus-4B, a 4B-parameter model post-trained on Qwen3-4B via supervised finetuning and reinforcement learning with rubric-based LLM-as-judge rewards to handle terminal execution subtasks.
If this is right
- Main agents delegate more terminal execution work to the subagent and execute fewer commands themselves.
- Overall token usage by the main agent falls by up to 30% while benchmark performance stays the same.
- Small specialized models can close or surpass the performance of frontier models on this narrow agentic task.
- Agent architectures can isolate verbose outputs such as build logs inside smaller, cheaper subagent loops.
Where Pith is reading between the lines
- The same post-training recipe could be repeated for other narrow subtasks such as code search or debugging to create additional efficient components.
- Widespread use of such models would lower the cost of running multi-step coding agents by reducing expensive frontier-model calls.
- Task-specific small models may become standard building blocks that let larger frontier models focus only on high-level planning.
Load-bearing premise
That the rubric-based LLM-as-judge reward produces training signals that generalize beyond the specific benchmarks and do not embed biases from the judge model itself.
What would settle it
A significant drop in success rate or token savings when Terminus-4B is evaluated on fresh terminal execution tasks outside the SWE-Bench family or when the reward judge model is replaced with a different one.
Figures





read the original abstract
Modern coding agents increasingly delegate specialized subtasks to subagents, which are smaller, focused agentic loops that handle narrow responsibilities like search, debugging or terminal execution. This architectural pattern keeps the main agent's context window clean by isolating verbose outputs (e.g. build logs, test results, etc.) within the subagent context. Typically when agents employ subagents for such tasks, they use frontier models as these subagents. In this paper, we investigate whether a finetuned small language model (SLM) can achieve comparable performance to frontier models in the task of agentic terminal execution. We present Terminus-4B, which is a post-trained Qwen3-4B model via Supervised Finetuning (SFT) and Reinforcement Learning (RL) using rubric-based LLM-as-judge reward, specifically for this task. In our extensive evaluation spanning various frontier models, training ablations and main agent configurations, we find that Terminus-4B is able to reduce the token usage of the main agent by up to ~30% compared to the No Subagent baseline with no impact to agent performance on benchmarks like SWE-Bench Pro and our internal SWE-Bench C# benchmark, which tends to be heavy in verbose execution tasks. Furthermore, Terminus-4B improves key metrics showing the main agent relying on the outputs of the subagent and doing fewer terminal execution tasks by itself. We see that our model not only closes the gap between the Vanilla Qwen model and frontier models like Claude Sonnet / Opus / GPT-5.3-Codex, but often even exceeds their performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Terminus-4B, a 4B-parameter model obtained by post-training Qwen3-4B via supervised fine-tuning followed by reinforcement learning that uses a rubric-based LLM-as-judge reward. The central claim is that this model, deployed as a subagent for terminal execution, reduces main-agent token consumption by up to ~30% relative to a no-subagent baseline while preserving or improving performance on SWE-Bench Pro and an internal SWE-Bench C# benchmark, increases main-agent reliance on subagent outputs, and matches or exceeds frontier models (Claude Sonnet/Opus, GPT-5.3-Codex) on the same tasks.
Significance. If the empirical results are robust, the work would demonstrate that small specialized models can replace frontier LLMs for narrow agentic subtasks, yielding measurable efficiency gains in multi-agent coding systems. The rubric-based RL approach, if shown to correlate with objective success, could also inform reward design for other execution-oriented agent loops.
major comments (3)
- [Abstract and Evaluation] Abstract and Evaluation sections: the headline claims of ~30% token reduction, unchanged benchmark performance, and superior subagent metrics are stated without accompanying numerical tables, confidence intervals, statistical tests, or ablation results that isolate the contribution of the rubric-based LLM-as-judge reward versus direct outcome signals (e.g., command success or test-pass rates).
- [Methods and Training] Methods and Training sections: no correlation analysis, cross-judge validation, or human evaluation on held-out terminal traces is reported to establish that the LLM-as-judge rubric produces signals that improve genuine execution quality rather than merely outputs favored by the judge model.
- [Experiments] Experiments section: the evaluation lacks controls for benchmark overfitting or judge-specific bias, such as ablations replacing the rubric reward with outcome-based rewards or testing generalization on tasks outside the training distribution.
minor comments (2)
- [Abstract and Evaluation] The internal SWE-Bench C# benchmark is mentioned repeatedly but never described in terms of size, task distribution, or construction details, hindering reproducibility.
- [Evaluation] Notation for the main-agent versus subagent token counts and reliance metrics could be clarified with an explicit equation or table definition early in the paper.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive suggestions. We address each of the major comments below, providing clarifications and indicating revisions to the manuscript. Our responses aim to strengthen the empirical rigor of the presented results while maintaining the core contributions of Terminus-4B.
read point-by-point responses
-
Referee: Abstract and Evaluation sections: the headline claims of ~30% token reduction, unchanged benchmark performance, and superior subagent metrics are stated without accompanying numerical tables, confidence intervals, statistical tests, or ablation results that isolate the contribution of the rubric-based LLM-as-judge reward versus direct outcome signals (e.g., command success or test-pass rates).
Authors: We appreciate this feedback on the presentation of results. The Evaluation section of the manuscript includes multiple tables reporting exact token reduction percentages (e.g., 28-32% across configurations), benchmark scores for SWE-Bench Pro and the C# benchmark, and subagent reliance metrics for Terminus-4B versus baselines and frontier models. However, we acknowledge the absence of confidence intervals and formal statistical tests in the current version. In the revised manuscript, we will add 95% confidence intervals to key metrics and perform paired statistical tests to confirm significance of the ~30% reduction and performance parity. Regarding ablations for the reward signal, the Training and Experiments sections describe comparisons between SFT, RL with rubric rewards, and variants; we will expand these to explicitly include direct outcome-based rewards (e.g., binary success signals) and report their impact on token usage and execution quality. revision: partial
-
Referee: Methods and Training sections: no correlation analysis, cross-judge validation, or human evaluation on held-out terminal traces is reported to establish that the LLM-as-judge rubric produces signals that improve genuine execution quality rather than merely outputs favored by the judge model.
Authors: We agree that validating the LLM-as-judge is crucial for the RL component. The Methods section details the rubric criteria, which are designed to align with objective execution outcomes such as command success and error resolution. To address the lack of correlation analysis, we will include in the revision a correlation study on 150 held-out terminal execution traces, computing Pearson correlations between rubric scores and ground-truth metrics like test passage rates. We will also perform cross-judge validation by re-scoring a subset with an alternative judge model. Human evaluation on traces was not performed in the original work due to resource constraints for expert review of complex terminal logs; we will note this as a limitation and suggest it as future work, while relying on the objective benchmarks for validation. revision: yes
-
Referee: Experiments section: the evaluation lacks controls for benchmark overfitting or judge-specific bias, such as ablations replacing the rubric reward with outcome-based rewards or testing generalization on tasks outside the training distribution.
Authors: Our evaluation does include controls via testing on two distinct benchmarks (SWE-Bench Pro and internal C#) and varying main-agent setups to demonstrate robustness. However, we recognize the need for more explicit ablations on reward types and out-of-distribution testing. In the revised Experiments section, we will add results from an ablation where the rubric reward is replaced with pure outcome-based rewards (e.g., success/failure from test execution), showing comparative performance. Additionally, we will report generalization results on a set of non-SWE terminal tasks (e.g., system administration commands) to address potential overfitting to the training distribution. These additions will help isolate judge-specific effects. revision: yes
Circularity Check
No significant circularity: purely empirical training and benchmark evaluation
full rationale
The paper presents Terminus-4B as the result of post-training Qwen3-4B via SFT followed by RL with a rubric-based LLM-as-judge reward, then reports direct empirical outcomes on external benchmarks (SWE-Bench Pro, internal SWE-Bench C#) and comparisons to frontier models. No derivations, first-principles predictions, equations, or fitted parameters are claimed or used; all headline metrics (token reduction, performance parity, subagent reliance) are measured outcomes rather than quantities defined by the training process itself. No self-citations form load-bearing premises, no uniqueness theorems are invoked, and no ansatz or renaming of known results occurs. The work is self-contained against external benchmarks with no reduction of results to inputs by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
Cost.FunctionalEquation / Foundation.AlphaCoordinateFixationwashburn_uniqueness_aczel; alpha_pin_under_high_calibration unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The final reward blends the scores for execution quality with final answer quality: r = (1−α)(s̄_pos − s̄_pit) + α·s̄_fa ... We use an α=0.5.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
VSCode Agent Mode,
Microsoft, “VSCode Agent Mode, ” https://code.visualstudio.com/blogs/ 2025/04/07/agentMode, 2025, accessed: 2025-09-28
2025
-
[2]
OpenHands: An Open Platform for AI Software Developers as Generalist Agents
X. Wang, B. Li, Y. Song, F. F. Xu, X. Tang, M. Zhuge, J. Pan, Y. Song, B. Li, J. Singh, H. H. Tran, F. Li, R. Ma, M. Zheng, B. Qian, Y. Shao, N. Muennighoff, Y. Zhang, B. Hui, J. Lin, R. Brennan, H. Peng, H. Ji, and G. Neubig, “Opendevin: An open platform for ai software developers as generalist agents, ” 2024. [Online]. Available: https://arxiv.org/abs/2...
work page internal anchor Pith review arXiv 2024
-
[3]
Claude for Coding,
Anthropic, “Claude for Coding, ” https://www.anthropic.com/claude-code, 2024, accessed: 2025-07-14
2024
-
[4]
SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering
J. Yang, C. E. Jimenez, A. Wettig, K. Lieret, S. Yao, K. Narasimhan, and O. Press, “Swe-agent: Agent-computer interfaces enable automated software engineering, ” 2024. [Online]. Available: https://arxiv.org/abs/ 2405.15793
work page internal anchor Pith review arXiv 2024
-
[5]
Debug2Fix: Can Interactive Debugging Help Coding Agents Fix More Bugs?
S. Garg and Y. Huang, “Debug2fix: Can interactive debugging help coding agents fix more bugs?” 2026. [Online]. Available: https: //arxiv.org/abs/2602.18571
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[6]
A. Yang, A. Li, B. Yang, B. Zhang, B. Hui, B. Zheng, B. Yu, C. Gao, C. Huang, C. Lv, C. Zheng, D. Liu, F. Zhou, F. Huang, F. Hu, H. Ge, H. Wei, H. Lin, J. Tang, J. Yang, J. Tu, J. Zhang, J. Yang, J. Yang, J. Zhou, J. Zhou, J. Lin, K. Dang, K. Bao, K. Yang, L. Yu, L. Deng, M. Li, M. Xue, 12 M. Li, P. Zhang, P. Wang, Q. Zhu, R. Men, R. Gao, S. Liu, S. Luo, ...
work page internal anchor Pith review arXiv 2025
-
[7]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Z. Shao, P. Wang, Q. Zhu, R. Xu, J. Song, X. Bi, H. Zhang, M. Zhang, Y. K. Li, Y. Wu, and D. Guo, “Deepseekmath: Pushing the limits of mathematical reasoning in open language models, ” 2024. [Online]. Available: https://arxiv.org/abs/2402.03300
work page internal anchor Pith review arXiv 2024
-
[8]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
L. Zheng, W.-L. Chiang, Y. Sheng, S. Zhuang, Z. Wu, Y. Zhuang, Z. Lin, Z. Li, D. Li, E. P. Xing, H. Zhang, J. E. Gonzalez, and I. Stoica, “Judging llm-as-a-judge with mt-bench and chatbot arena, ” 2023. [Online]. Available: https://arxiv.org/abs/2306.05685
work page internal anchor Pith review arXiv 2023
-
[9]
H. Hashemi, J. Eisner, C. Rosset, B. Van Durme, and C. Kedzie, “Llm-rubric: A multidimensional, calibrated approach to automated evaluation of natural language texts, ” inProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Association for Computational Linguistics, 2024, p. 13806–13834. [Online]...
-
[10]
Training language models to follow instructions with human feedback
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. L. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, A. Ray, J. Schulman, J. Hilton, F. Kelton, L. Miller, M. Simens, A. Askell, P. Welinder, P. Christiano, J. Leike, and R. Lowe, “Training language models to follow instructions with human feedback, ” 2022. [Online]. Available: https://arxiv.org/abs/2203.02155
work page internal anchor Pith review arXiv 2022
-
[11]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Q. Wu, G. Bansal, J. Zhang, Y. Wu, B. Li, E. Zhu, L. Jiang, X. Zhang, S. Zhang, J. Liu, A. H. Awadallah, R. W. White, D. Burger, and C. Wang, “Autogen: Enabling next-gen llm applications via multi-agent conversation, ” 2023. [Online]. Available: https://arxiv.org/abs/2308.08155
work page internal anchor Pith review arXiv 2023
-
[12]
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework
S. Hong, M. Zhuge, J. Chen, X. Zheng, Y. Cheng, C. Zhang, J. Wang, Z. Wang, S. K. S. Yau, Z. Lin, L. Zhou, C. Ran, L. Xiao, C. Wu, and J. Schmidhuber, “Metagpt: Meta programming for a multi-agent collaborative framework, ” 2024. [Online]. Available: https: //arxiv.org/abs/2308.00352
work page internal anchor Pith review arXiv 2024
-
[13]
ChatDev: Communicative Agents for Software Development
C. Qian, W. Liu, H. Liu, N. Chen, Y. Dang, J. Li, C. Yang, W. Chen, Y. Su, X. Cong, J. Xu, D. Li, Z. Liu, and M. Sun, “Chatdev: Communicative agents for software development, ” 2024. [Online]. Available: https://arxiv.org/abs/2307.07924
work page internal anchor Pith review arXiv 2024
-
[14]
J. He, C. Treude, and D. Lo, “Llm-based multi-agent systems for software engineering: Literature review, vision and the road ahead, ” 2025. [Online]. Available: https://arxiv.org/abs/2404.04834
-
[15]
(2025) How we built our multi-agent research system
Anthropic. (2025) How we built our multi-agent research system. Published June 13, 2025. [Online]. Available: https://www.anthropic.com/ engineering/built-multi-agent-research-system
2025
-
[16]
Small language models are the future of agentic ai,
P. Belcak, G. Heinrich, S. Diao, Y. Fu, X. Dong, S. Muralidharan, Y. C. Lin, and P. Molchanov, “Small language models are the future of agentic ai, ”
-
[17]
[Online]. Available: https://arxiv.org/abs/2506.02153
-
[18]
Deepseek-r1 incentivizes reasoning in llms through reinforcement learning,
D. Guo, D. Yang, H. Zhang, J. Song, P. Wang, Q. Zhu, R. Xu, R. Zhang, S. Ma, X. Bi, X. Zhang, X. Yu, Y. Wu, Z. F. Wu, Z. Gou, Z. Shao, Z. Li, Z. Gao, A. Liu, B. Xue, B. Wang, B. Wu, B. Feng, C. Lu, C. Zhao, C. Deng, C. Ruan, D. Dai, D. Chen, D. Ji, E. Li, F. Lin, F. Dai, F. Luo, G. Hao, G. Chen, G. Li, H. Zhang, H. Xu, H. Ding, H. Gao, H. Qu, H. Li, J. Gu...
-
[19]
Available: http://dx.doi.org/10.1038/s41586-025-09422-z
[Online]. Available: http://dx.doi.org/10.1038/s41586-025-09422-z
-
[20]
arXiv preprint arXiv:2503.16219
Q.-A. Dang and C. Ngo, “Reinforcement learning for reasoning in small llms: What works and what doesn’t, ” 2026. [Online]. Available: https://arxiv.org/abs/2503.16219
-
[21]
Qwen3-coder-next technical report,
R. Cao, M. Chen, J. Chen, Z. Cui, Y. Feng, B. Hui, Y. Jing, K. Li, M. Li, J. Lin, Z. Ma, K. Shum, X. Wang, J. Wei, J. Yang, J. Zhang, L. Zhang, Z. Zhang, W. Zhao, and F. Zhou, “Qwen3-coder-next technical report, ”
-
[22]
[Online]. Available: https://arxiv.org/abs/2603.00729
-
[23]
Skyrl-agent: Efficient rl training for multi-turn llm agent.arXiv preprint arXiv:2511.16108, 2025
S. Cao, D. Li, F. Zhao, S. Yuan, S. R. Hegde, C. Chen, C. Ruan, T. Griggs, S. Liu, E. Tang, R. Liaw, P. Moritz, M. Zaharia, J. E. Gonzalez, and I. Stoica, “Skyrl-agent: Efficient rl training for multi-turn llm agent, ” 2025. [Online]. Available: https://arxiv.org/abs/2511.16108
-
[24]
Goodman, and Dimitris Papailiopoulos
K. Gandhi, S. Garg, N. D. Goodman, and D. Papailiopoulos, “Endless terminals: Scaling rl environments for terminal agents, ” 2026. [Online]. Available: https://arxiv.org/abs/2601.16443
-
[25]
Active context compression: Autonomous memory management in LLM agents
N. Verma, “Active context compression: Autonomous memory management in llm agents, ” 2026. [Online]. Available: https: //arxiv.org/abs/2601.07190
-
[26]
Scaling long-horizon LLM agent via context-folding.CoRR, abs/2510.11967, 2025
W. Sun, M. Lu, Z. Ling, K. Liu, X. Yao, Y. Yang, and J. Chen, “Scaling long-horizon llm agent via context-folding, ” 2025. [Online]. Available: https://arxiv.org/abs/2510.11967
-
[27]
Memex(rl): Scaling long-horizon llm agents via indexed experience memory,
Z. Wang, H. Chen, J. Wang, and W. Wei, “Memex(rl): Scaling long-horizon llm agents via indexed experience memory, ” 2026. [Online]. Available: https://arxiv.org/abs/2603.04257
-
[28]
SWE Context Bench: A Benchmark for Context Learning in Coding
J. Zhu, M. Hu, and J. Wu, “Swe context bench: A benchmark for context learning in coding, ” 2026. [Online]. Available: https: //arxiv.org/abs/2602.08316
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Fireworks AI: Fast inference platform,
Fireworks AI, “Fireworks AI: Fast inference platform, ” https://fireworks.ai, 2025
2025
-
[30]
Slime: Distributed training framework,
THUDM, “Slime: Distributed training framework, ” https://github.com/ THUDM/slime, 2025
2025
-
[31]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Q. Yu, Z. Zhang, R. Zhu, Y. Yuan, X. Zuo, Y. Yue, W. Dai, T. Fan, G. Liu, L. Liu, X. Liu, H. Lin, Z. Lin, B. Ma, G. Sheng, Y. Tong, C. Zhang, M. Zhang, W. Zhang, H. Zhu, J. Zhu, J. Chen, J. Chen, C. Wang, H. Yu, Y. Song, X. Wei, H. Zhou, J. Liu, W.-Y. Ma, Y.-Q. Zhang, L. Yan, M. Qiao, Y. Wu, and M. Wang, “Dapo: An open-source llm reinforcement learning sy...
work page internal anchor Pith review arXiv 2025
-
[32]
SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?
X. Deng, J. Da, E. Pan, Y. Y. He, C. Ide, K. Garg, N. Lauffer, A. Park, N. Pasari, C. Rane, K. Sampath, M. Krishnan, S. Kundurthy, S. Hendryx, Z. Wang, V. Bharadwaj, J. Holm, R. Aluri, C. B. C. Zhang, N. Jacobson, B. Liu, and B. Kenstler, “Swe-bench pro: Can ai agents solve long-horizon software engineering tasks?” 2025. [Online]. Available: https://arxiv...
work page internal anchor Pith review arXiv 2025
-
[33]
Introducing swe-bench verified,
OpenAI, “Introducing swe-bench verified, ” https://openai.com/index/ introducing-swe-bench-verified/, 2024, published August 13, 2024; updated February 24, 2025. [Online]. Available: https://openai.com/index/ introducing-swe-bench-verified/ 13
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.