Recognition: unknown
Deep Wave Network for Modeling Multi-Scale Physical Dynamics
Pith reviewed 2026-05-08 17:29 UTC · model grok-4.3
The pith
Stacking multiple U-Net waves improves accuracy-cost trade-offs for modeling multi-scale physical flows
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Replacing the single encoder-decoder wave of a U-Net with a sequence of such waves linked by additional skip connections yields Deep Wave Networks whose accuracy-cost scaling dominates that of conventional single-wave U-Nets on physical flow prediction tasks.
What carries the argument
The stacked-wave architecture with intra-wave and inter-wave skip connections, which increases effective depth while preserving multi-resolution feature flow.
If this is right
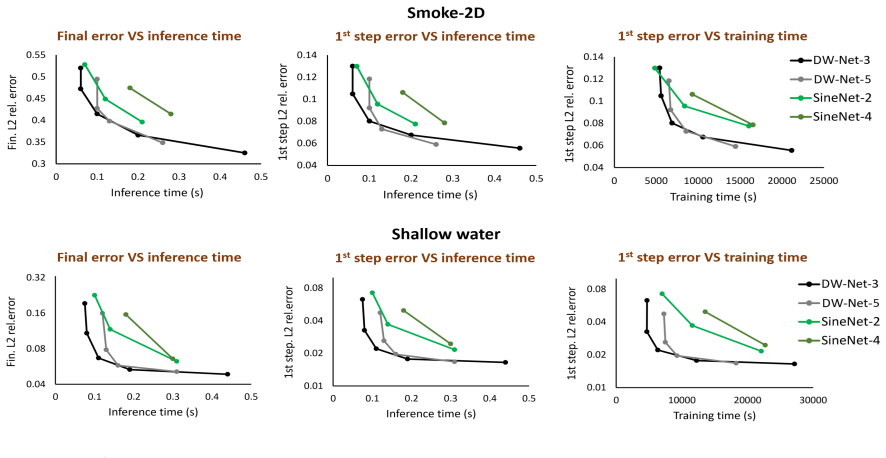
- DW-Net models reach low-error regimes with up to 3x less training time under identical training settings.
- For matched computational cost, DW-Nets deliver higher accuracy than single-wave U-Nets on the tested flow problems.
- For matched accuracy, DW-Nets require less GPU time than single-wave U-Nets.
- The advantage holds across several 2D and 3D benchmarks for gas, fluid, and plasma dynamics.
- Varying width together with the number of stacked waves explores the accuracy-cost space more effectively than varying width alone.
Where Pith is reading between the lines
- The stacking approach could be tested on other encoder-decoder tasks such as weather forecasting or medical image segmentation where multi-scale features matter.
- If cross-wave skips remain effective at larger depths, they might allow deeper networks without the usual optimization difficulties of very deep single-path models.
- The optimal number of waves may increase with the range of spatial scales in the target physical system, which could be checked by varying Reynolds number or domain size.
Load-bearing premise
That keeping training data, optimization, and schedules identical across architectures isolates the effect of the stacked-wave structure without hidden differences in convergence behavior or effective capacity.
What would settle it
A single-wave U-Net, when allowed its own optimized schedule or deeper single-path configuration, that matches or exceeds the DW-Net accuracy versus GPU-time Pareto front on the same benchmarks would falsify the reported consistent improvement.
Figures

















read the original abstract
Performance of deep learning models is strongly governed by architectural capacity, with width and depth as primary controls. However, in physical-science applications, models are often compared at a single fixed size or by separating accuracy and computational cost, which can be misleading since architectures exhibit different accuracy-cost scaling as width and depth vary. This issue is particularly relevant for U-Net-type encoder-decoder models, widely used for multi-scale gas, fluid, and plasma dynamics due to their ability to represent features across spatial scales. A U-Net constructs a multi-resolution representation via an encoder that progressively reduces spatial resolution, followed by a decoder that restores it for prediction. Skip connections link corresponding encoder and decoder features, preserving fine-scale information and improving optimization. In practice, U-Net width is routinely tuned, while depth is typically kept fixed (a set number of down/up-sampling stages with few convolutions per stage), limiting systematic exploration of depth for improving the accuracy-cost trade-off. We address this limitation by increasing effective depth through stacking multiple encoder-decoder "waves" in series, with skip connections both within and across waves to enable progressive cross-scale refinement. We call this architecture a Deep Wave Network (DW-Net). Training data, optimization, and schedules are kept identical across models. Instead of evaluating single configurations, we train multiple width variants of each architecture and compare accuracy vs. GPU time Pareto fronts. Across several 2D and 3D flow benchmarks, DW-Net models consistently improve the Pareto frontier over single-wave U-Nets, achieving higher accuracy at matched cost or similar accuracy at reduced cost, and reaching low-error regimes with up to 3x less training time under identical training settings.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Deep Wave Networks (DW-Net) as an extension of U-Net architectures for multi-scale physical dynamics modeling. By stacking multiple encoder-decoder waves in series and adding intra- and inter-wave skip connections, the design increases effective depth while preserving multi-resolution features. The central empirical claim is that, when multiple width variants of DW-Net and baseline single-wave U-Nets are trained under identical data, optimizer, and schedules, the DW-Net models improve the accuracy-versus-GPU-time Pareto frontier on 2D and 3D flow benchmarks, yielding higher accuracy at matched cost or equivalent accuracy with up to 3x less training time.
Significance. If the results hold after addressing experimental controls, the work provides a systematic method for exploring depth in U-Net-style models without relying solely on width scaling, which is relevant for efficiency in scientific machine learning tasks such as fluid and plasma simulations. The Pareto-front evaluation across width variants is a methodological strength that avoids single-point cherry-picking and directly addresses accuracy-cost trade-offs.
major comments (3)
- [Experiments] Experiments section: The Pareto-front results rely on fixed training schedules applied identically to single-wave U-Nets and multi-wave DW-Nets. Because wave stacking increases effective depth and modifies skip-connection topology, gradient magnitudes and convergence behavior can differ; without loss curves, epoch-to-target-error metrics, or schedule-sensitivity ablations, it is impossible to separate claimed multi-scale refinement benefits from incidental optimization advantages under the shared schedule.
- [Method] Method section (DW-Net definition): The inter-wave skip connections are presented as enabling progressive cross-scale refinement, yet no explicit accounting is given for how these connections affect total parameter count or per-forward-pass FLOPs relative to a single-wave U-Net of comparable nominal width. This detail is load-bearing for interpreting the cost axis of the reported Pareto fronts.
- [Results] Results (Pareto-front figures): The manuscript should report whether width variants were selected to match parameter budgets or FLOPs across architectures, and whether error metrics include run-to-run uncertainty; post-hoc selection of the best width per architecture could inflate the apparent frontier improvement.
minor comments (2)
- [Abstract] Abstract: The phrase 'up to 3x less training time' should specify the precise error threshold at which this factor is measured.
- Notation: Ensure consistent use of symbols for wave count, skip-connection types, and width scaling factors throughout the text and figures.
Simulated Author's Rebuttal
Thank you for the referee's constructive comments on our manuscript. We address each major point below with point-by-point responses and indicate where revisions will be made to improve clarity and rigor.
read point-by-point responses
-
Referee: [Experiments] Experiments section: The Pareto-front results rely on fixed training schedules applied identically to single-wave U-Nets and multi-wave DW-Nets. Because wave stacking increases effective depth and modifies skip-connection topology, gradient magnitudes and convergence behavior can differ; without loss curves, epoch-to-target-error metrics, or schedule-sensitivity ablations, it is impossible to separate claimed multi-scale refinement benefits from incidental optimization advantages under the shared schedule.
Authors: We agree that convergence diagnostics would strengthen the claims. The reported Pareto fronts reflect final accuracies under the fixed, identical training protocol, which matches practical use cases in scientific ML. To address the concern, we will add training loss curves for representative DW-Net and U-Net variants in the revised experiments section, along with a short discussion of observed convergence behavior. This will help demonstrate that the gains arise from the architecture rather than incidental optimization effects. revision: yes
-
Referee: [Method] Method section (DW-Net definition): The inter-wave skip connections are presented as enabling progressive cross-scale refinement, yet no explicit accounting is given for how these connections affect total parameter count or per-forward-pass FLOPs relative to a single-wave U-Net of comparable nominal width. This detail is load-bearing for interpreting the cost axis of the reported Pareto fronts.
Authors: The referee correctly notes this omission. Inter-wave skip connections add projection convolutions that modestly increase parameter count beyond the extra wave computations. We will revise the method section to include explicit parameter counts, FLOPs estimates, and a comparison table for DW-Net versus single-wave U-Net at matched nominal widths. Our primary cost metric remains measured GPU training time, which already incorporates these overheads for the Pareto analysis. revision: yes
-
Referee: [Results] Results (Pareto-front figures): The manuscript should report whether width variants were selected to match parameter budgets or FLOPs across architectures, and whether error metrics include run-to-run uncertainty; post-hoc selection of the best width per architecture could inflate the apparent frontier improvement.
Authors: Width variants were selected independently for each architecture by scaling the base channel count to span comparable capacity ranges; exact parameter or FLOP matching was not performed due to structural differences. All trained points are shown in the figures, with the frontier as the lower envelope, avoiding post-hoc selection of only the best widths. We will update the results section to state the selection process explicitly and add run-to-run uncertainty (standard deviations from repeated seeds) for representative points where such data is available. revision: partial
Circularity Check
No circularity: empirical Pareto comparison under fixed training protocol
full rationale
The paper's central claim is an empirical result: DW-Net (stacked-wave U-Net) improves the accuracy-vs-GPU-time Pareto frontier over single-wave U-Nets across 2D/3D flow benchmarks when width variants are trained with identical data, optimizer, and schedules. No equations, predictions, or first-principles derivations are offered; the architecture is defined explicitly by adding inter-wave skip connections, and performance is measured on external benchmarks. The comparison does not reduce any claimed improvement to a quantity defined by the architecture itself or to a self-citation chain. The skeptic concern about schedule optimality is a question of experimental isolation, not circularity.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Identical training data, optimizer, and schedule isolate architectural effects
Reference graph
Works this paper leans on
-
[1]
D. C. Wilcoxet al.,Turbulence modeling for CFD, vol. 2. DCW industries La Canada, CA, 1998
1998
-
[2]
Hasegawa,Plasma instabilities and nonlinear effects, vol
A. Hasegawa,Plasma instabilities and nonlinear effects, vol. 8. Springer Science & Business Media, 2012
2012
-
[3]
Learning skillful medium-range global weather forecasting,
R. Lam, A. Sanchez-Gonzalez, M. Willson, P. Wirnsberger, M. Fortunato, F. Alet, S. Ravuri, T. Ewalds, Z. Eaton-Rosen, W. Hu,et al., “Learning skillful medium-range global weather forecasting,”Science, vol. 382, no. 6677, pp. 1416–1421, 2023
2023
-
[4]
A refinement of previous hypotheses concerning the local structure of tur- bulence in a viscous incompressible fluid at high reynolds number,
A. N. Kolmogorov, “A refinement of previous hypotheses concerning the local structure of tur- bulence in a viscous incompressible fluid at high reynolds number,”Journal of Fluid Mechanics, vol. 13, no. 1, pp. 82–85, 1962
1962
-
[5]
arXiv preprint arXiv:2408.12171 , year=
H. Wang, Y. Cao, Z. Huang, Y. Liu, P. Hu, X. Luo, Z. Song, W. Zhao, J. Liu, J. Sun,et al., “Recent advances on machine learning for computational fluid dynamics: A survey,”arXiv preprint arXiv:2408.12171, 2024
-
[6]
Current and emerging deep-learning methods for the simulation of fluid dynamics,
M. Lino, S. Fotiadis, A. A. Bharath, and C. D. Cantwell, “Current and emerging deep-learning methods for the simulation of fluid dynamics,”Proceedings of the Royal Society A, vol. 479, no. 2275, p. 20230058, 2023
2023
-
[7]
Solver-in-the-loop: Learning from differentiable physics to interact with iterative pde-solvers,
K. Um, R. Brand, Y. R. Fei, P. Holl, and N. Thuerey, “Solver-in-the-loop: Learning from differentiable physics to interact with iterative pde-solvers,”Advances in neural information processing systems, vol. 33, pp. 6111–6122, 2020
2020
-
[8]
Machine learn- ing–accelerated computational fluid dynamics,
D. Kochkov, J. A. Smith, A. Alieva, Q. Wang, M. P. Brenner, and S. Hoyer, “Machine learn- ing–accelerated computational fluid dynamics,”Proceedings of the National Academy of Sciences, vol. 118, no. 21, p. e2101784118, 2021
2021
-
[9]
Physics-preserving ai-accelerated simulations of plasma turbulence,
R. Greif, F. Jenko, and N. Thuerey, “Physics-preserving ai-accelerated simulations of plasma turbulence,”arXiv preprint arXiv:2309.16400, 2023
-
[10]
Combining differentiable pde solvers and graph neural networks for fluid flow prediction,
F. D. A. Belbute-Peres, T. Economon, and Z. Kolter, “Combining differentiable pde solvers and graph neural networks for fluid flow prediction,” ininternational conference on machine learning, pp. 2402–2411, PMLR, 2020
2020
-
[11]
Deep neural networks for data-driven les closure models,
A. Beck, D. Flad, and C.-D. Munz, “Deep neural networks for data-driven les closure models,” Journal of Computational Physics, vol. 398, p. 108910, 2019
2019
-
[12]
Training convolutional neural networks to estimate turbulent sub-grid scale reaction rates,
C. J. Lapeyre, A. Misdariis, N. Cazard, D. Veynante, and T. Poinsot, “Training convolutional neural networks to estimate turbulent sub-grid scale reaction rates,”Combustion and Flame, vol. 203, pp. 255–264, 2019
2019
-
[13]
Data-driven subgrid-scale modeling of forced burgers turbulence using deep learning with generalization to higher reynolds numbers via transfer learning,
A. Subel, A. Chattopadhyay, Y. Guan, and P. Hassanzadeh, “Data-driven subgrid-scale modeling of forced burgers turbulence using deep learning with generalization to higher reynolds numbers via transfer learning,”Physics of Fluids, vol. 33, no. 3, 2021
2021
-
[14]
Cfdnet: a deep learning- based accelerator for fluid simulations,
O. Obiols-Sales, A. Vishnu, N. Malaya, and A. Chandramowliswharan, “Cfdnet: a deep learning- based accelerator for fluid simulations,” inProceedings of the 34th ACM International Conference on Supercomputing, ICS ’20, (New York, NY, USA), Association for Computing Machinery, 2020
2020
-
[15]
Accelerating kinetic plasma simulations with machine-learning-generated initial conditions,
A. T. Powis, D. C. Rivera, A. Khrabry, and I. D. Kaganovich, “Accelerating kinetic plasma simulations with machine-learning-generated initial conditions,”Physics of Plasmas, vol. 33, p. 013902, 2026
2026
-
[16]
Prediction of aerodynamic flow fields using convolutional neural networks,
S. Bhatnagar, Y. Afshar, S. Pan, K. Duraisamy, and S. Kaushik, “Prediction of aerodynamic flow fields using convolutional neural networks,”Computational Mechanics, vol. 64, pp. 525–545, 2019. 26
2019
-
[17]
Clifford neural layers for PDE modeling,
J. Brandstetter, R. van den Berg, M. Welling, and J. K. Gupta, “Clifford neural layers for PDE modeling,” inThe Eleventh International Conference on Learning Representations, 2023
2023
-
[18]
Universal physics transformers: A framework for efficiently scaling neural operators,
B. Alkin, A. F¨ urst, S. Schmid, L. Gruber, M. Holzleitner, and J. Brandstetter, “Universal physics transformers: A framework for efficiently scaling neural operators,”Advances in Neural Infor- mation Processing Systems, vol. 37, pp. 25152–25194, 2024
2024
-
[19]
Fourier Neural Operator for Parametric Partial Differential Equations
Z. Li, N. Kovachki, K. Azizzadenesheli, B. Liu, K. Bhattacharya, A. Stuart, and A. Anand- kumar, “Fourier neural operator for parametric partial differential equations,”arXiv preprint arXiv:2010.08895, 2020
work page internal anchor Pith review arXiv 2010
-
[20]
Learning nonlinear operators via deep- onet based on the universal approximation theorem of operators,
L. Lu, P. Jin, G. Pang, Z. Zhang, and G. E. Karniadakis, “Learning nonlinear operators via deep- onet based on the universal approximation theorem of operators,”Nature machine intelligence, vol. 3, no. 3, pp. 218–229, 2021
2021
-
[21]
Learning the solution operator of parametric partial differ- ential equations with physics-informed deeponets,
S. Wang, H. Wang, and P. Perdikaris, “Learning the solution operator of parametric partial differ- ential equations with physics-informed deeponets,”Science advances, vol. 7, no. 40, p. eabi8605, 2021
2021
-
[22]
Hierarchical-embedding autoencoder with a predictor as efficient architecture for learning time-evolution in multi-scale turbulent flows,
A. I. Khrabry, E. A. Startsev, A. T. Powis, and I. D. Kaganovich, “Hierarchical-embedding autoencoder with a predictor as efficient architecture for learning time-evolution in multi-scale turbulent flows,”Physics of Fluids, vol. 38, no. 4, 2026
2026
-
[23]
Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differ- ential equations,
M. Raissi, P. Perdikaris, and G. E. Karniadakis, “Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differ- ential equations,”Journal of Computational physics, vol. 378, pp. 686–707, 2019
2019
-
[24]
Physics- informed machine learning,
G. E. Karniadakis, I. G. Kevrekidis, L. Lu, P. Perdikaris, S. Wang, and L. Yang, “Physics- informed machine learning,”Nature Reviews Physics, vol. 3, no. 6, pp. 422–440, 2021
2021
-
[25]
Physics-informed neural networks as surrogate models of hydrodynamic simulators,
J. Donnelly, A. Daneshkhah, and S. Abolfathi, “Physics-informed neural networks as surrogate models of hydrodynamic simulators,”Science of the Total Environment, vol. 912, p. 168814, 2024
2024
-
[26]
Neuralpde: Automating physics-informed neural networks (pinns) with error approximations,
K. Zubov, Z. McCarthy, Y. Ma, F. Calisto, V. Pagliarino, S. Azeglio, L. Bottero, E. Luj´ an, V. Sulzer, A. Bharambe,et al., “Neuralpde: Automating physics-informed neural networks (pinns) with error approximations,”arXiv preprint arXiv:2107.09443, 2021
-
[27]
Z. Zhao, X. Ding, and B. A. Prakash, “Pinnsformer: A transformer-based framework for physics- informed neural networks,”arXiv preprint arXiv:2307.11833, 2023
-
[28]
Nsfnets (navier-stokes flow nets): Physics- informed neural networks for the incompressible navier-stokes equations,
X. Jin, S. Cai, H. Li, and G. E. Karniadakis, “Nsfnets (navier-stokes flow nets): Physics- informed neural networks for the incompressible navier-stokes equations,”Journal of Compu- tational Physics, vol. 426, p. 109951, 2021
2021
-
[29]
Physics-informed neural networks for solving reynolds-averaged navier–stokes equations,
H. Eivazi, M. Tahani, P. Schlatter, and R. Vinuesa, “Physics-informed neural networks for solving reynolds-averaged navier–stokes equations,”Physics of Fluids, vol. 34, no. 7, 2022
2022
-
[30]
Physics-informed neural operator for learning partial differential equations,
Z. Li, H. Zheng, N. Kovachki, D. Jin, H. Chen, B. Liu, K. Azizzadenesheli, and A. Anandkumar, “Physics-informed neural operator for learning partial differential equations,”ACM/IMS Journal of Data Science, vol. 1, no. 3, pp. 1–27, 2024
2024
-
[31]
Generative-machine-learning surrogate model of plasma turbulence,
B. Clavier, D. Zarzoso, D. del Castillo-Negrete, and E. Fr´ enod, “Generative-machine-learning surrogate model of plasma turbulence,”Physical Review E, vol. 111, no. 1, p. L013202, 2025
2025
-
[32]
Learned coarse models for efficient turbulence simula- tion,
K. Stachenfeld, D. B. Fielding, D. Kochkov, M. Cranmer, T. Pfaff, J. Godwin, C. Cui, S. Ho, P. Battaglia, and A. Sanchez-Gonzalez, “Learned coarse models for efficient turbulence simula- tion,” inInternational Conference on Learning Representations, 2022
2022
-
[33]
Towards physics-informed deep learning for turbulent flow prediction,
R. Wang, K. Kashinath, M. Mustafa, A. Albert, and R. Yu, “Towards physics-informed deep learning for turbulent flow prediction,” inProceedings of the 26th ACM SIGKDD Interna- tional Conference on Knowledge Discovery & Data Mining, KDD ’20, (New York, NY, USA), p. 1457–1466, Association for Computing Machinery, 2020. 27
2020
-
[34]
Scientific machine learning based reduced-order models for plasma turbulence simulations,
C. Gahr, I.-G. Farca¸ s, and F. Jenko, “Scientific machine learning based reduced-order models for plasma turbulence simulations,”Physics of Plasmas, vol. 31, no. 11, 2024
2024
-
[35]
PDE-refiner: Achiev- ing accurate long rollouts with neural PDE solvers,
P. Lippe, B. S. Veeling, P. Perdikaris, R. E. Turner, and J. Brandstetter, “PDE-refiner: Achiev- ing accurate long rollouts with neural PDE solvers,” inThirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[36]
Sinenet: Learning tem- poral dynamics in time-dependent partial differential equations,
X. Zhang, J. Helwig, Y. Lin, Y. Xie, C. Fu, S. Wojtowytsch, and S. Ji, “Sinenet: Learning tem- poral dynamics in time-dependent partial differential equations,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[37]
Deep fluids: A generative network for parameterized fluid simulations,
B. Kim, V. C. Azevedo, N. Thuerey, T. Kim, M. Gross, and B. Solenthaler, “Deep fluids: A generative network for parameterized fluid simulations,” inComputer graphics forum, vol. 38, pp. 59–70, Wiley Online Library, 2019
2019
-
[38]
Towards multi-spatiotemporal-scale generalized pde modeling.arXiv preprint arXiv:2209.15616, 2022
J. K. Gupta and J. Brandstetter, “Towards multi-spatiotemporal-scale generalized pde model- ing,”arXiv preprint arXiv:2209.15616, 2022
-
[39]
The well: a large-scale collection of diverse physics simulations for machine learning,
R. Ohana, M. McCabe, L. Meyer, R. Morel, F. Agocs, M. Beneitez, M. Berger, B. Burkhart, S. Dalziel, D. Fielding,et al., “The well: a large-scale collection of diverse physics simulations for machine learning,”Advances in Neural Information Processing Systems, vol. 37, pp. 44989– 45037, 2024
2024
-
[40]
Transform once: Efficient operator learning in frequency domain,
M. Poli, S. Massaroli, F. Berto, J. Park, T. Dao, C. R´ e, and S. Ermon, “Transform once: Efficient operator learning in frequency domain,”Advances in Neural Information Processing Systems, vol. 35, pp. 7947–7959, 2022
2022
-
[41]
Factorized fourier neural operators,
A. Tran, A. Mathews, L. Xie, and C. S. Ong, “Factorized fourier neural operators,” inThe Eleventh International Conference on Learning Representations, 2023
2023
-
[42]
J. Helwig, X. Zhang, C. Fu, J. Kurtin, S. Wojtowytsch, and S. Ji, “Group equivariant fourier neural operators for partial differential equations,”arXiv preprint arXiv:2306.05697, 2023
-
[43]
U-no: U-shaped neural operators.arXiv preprint arXiv:2204.11127, 2022
M. A. Rahman, Z. E. Ross, and K. Azizzadenesheli, “U-no: U-shaped neural operators,”arXiv preprint arXiv:2204.11127, 2022
-
[44]
Plasma surrogate modelling using fourier neural operators,
Z. Li, V. Gopakumar, S. Pamela, L. Zanisi, and A. Anandkumar, “Plasma surrogate modelling using fourier neural operators,” inAPS Division of Plasma Physics Meeting Abstracts, vol. 2024, pp. CM11–007, 2024
2024
-
[45]
Neural operator surrogate models of plasma edge simulations: feasibility and data efficiency,
N. Carey, L. Zanisi, S. Pamela, V. Gopakumar, J. Omotani, J. Buchanan, J. Brandstetter, F. Paischer, G. Galletti, and P. Setinek, “Neural operator surrogate models of plasma edge simulations: feasibility and data efficiency,”Nuclear Fusion, vol. 65, no. 10, p. 106010, 2025
2025
-
[46]
Fourier neural operator for large eddy simulation of compressible rayleigh–taylor turbulence,
T. Luo, Z. Li, Z. Yuan, W. Peng, T. Liu, L. L. Wang, and J. Wang, “Fourier neural operator for large eddy simulation of compressible rayleigh–taylor turbulence,”Physics of Fluids, vol. 36, no. 7, 2024
2024
-
[47]
Spatiotemporal wall pressure forecast of a rectangular cylinder with physics-aware deepu-fourier neural network,
J. Liu, C. Liu, Y. Ke, W. Chen, K. Shum, T. K. Tse, and G. Hu, “Spatiotemporal wall pressure forecast of a rectangular cylinder with physics-aware deepu-fourier neural network,”Physics of Fluids, vol. 37, no. 12, 2025
2025
-
[48]
Enhancing fourier neural operators with local spatial features.arXiv preprint arXiv:2503.17797, 2025
C. Liu, D. Murari, C. Budd, L. Liu, and C.-B. Sch¨ onlieb, “Enhancing fourier neural operators with local spatial features,”arXiv preprint arXiv:2503.17797, 2025
-
[49]
R. J. George, J. Zhao, J. Kossaifi, Z. Li, and A. Anandkumar, “Incremental spatial and spectral learning of neural operators for solving large-scale pdes,”arXiv preprint arXiv:2211.15188, 2022
-
[50]
Learning how landscapes evolve with neural operators,
G. G. Roberts, “Learning how landscapes evolve with neural operators,”Earth Surface Dynam- ics, vol. 13, no. 4, pp. 563–570, 2025
2025
-
[51]
Fourier neural operator network for fast photoacoustic wave simulations,
S. Guan, K.-T. Hsu, and P. V. Chitnis, “Fourier neural operator network for fast photoacoustic wave simulations,”Algorithms, vol. 16, no. 2, p. 124, 2023. 28
2023
-
[52]
Modeling multivariable high-resolution 3d urban microclimate using localized fourier neural operator,
S. Qin, D. Zhan, D. Geng, W. Peng, G. Tian, Y. Shi, N. Gao, X. Liu, and L. L. Wang, “Modeling multivariable high-resolution 3d urban microclimate using localized fourier neural operator,” Building and Environment, vol. 273, p. 112668, 2025
2025
-
[53]
Attention is all you need,
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polo- sukhin, “Attention is all you need,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[54]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly,et al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review arXiv 2010
-
[55]
Multiple physics pretraining for spatiotemporal surrogate models,
M. McCabe, B. R´ egaldo-Saint Blancard, L. Parker, R. Ohana, M. Cranmer, A. Bietti, M. Eicken- berg, S. Golkar, G. Krawezik, F. Lanusse,et al., “Multiple physics pretraining for spatiotemporal surrogate models,”Advances in Neural Information Processing Systems, vol. 37, pp. 119301– 119335, 2024
2024
-
[56]
Climformer-a spherical transformer model for long-term climate projections,
S. R. Cachay, P. Mitra, H. Hirasawa, S. Kim, S. Hazarika, D. Hingmire, P. Rasch, H. Singh, and K. Ramea, “Climformer-a spherical transformer model for long-term climate projections,” inProceedings of the Machine Learning and the Phys-ical Sciences Workshop, NeurIPS 2022, 2022
2022
-
[57]
Deep spatial transformers for autoregressive data-driven forecasting of geophysical turbulence,
A. Chattopadhyay, M. Mustafa, P. Hassanzadeh, and K. Kashinath, “Deep spatial transformers for autoregressive data-driven forecasting of geophysical turbulence,” inProceedings of the 10th international conference on climate informatics, pp. 106–112, 2020
2020
-
[58]
Earthformer: Ex- ploring space-time transformers for earth system forecasting,
Z. Gao, X. Shi, H. Wang, Y. Zhu, Y. B. Wang, M. Li, and D.-Y. Yeung, “Earthformer: Ex- ploring space-time transformers for earth system forecasting,”Advances in Neural Information Processing Systems, vol. 35, pp. 25390–25403, 2022
2022
-
[59]
In: Proceedings of the 40th International Conference on Machine Learning
T. Nguyen, J. Brandstetter, A. Kapoor, J. K. Gupta, and A. Grover, “Climax: A foundation model for weather and climate,”arXiv preprint arXiv:2301.10343, 2023
-
[60]
Scalable transformer for pde surrogate modeling,
Z. Li, D. Shu, and A. Barati Farimani, “Scalable transformer for pde surrogate modeling,” Advances in Neural Information Processing Systems, vol. 36, pp. 28010–28039, 2023
2023
-
[61]
Choose a transformer: Fourier or galerkin,
S. Cao, “Choose a transformer: Fourier or galerkin,”Advances in neural information processing systems, vol. 34, pp. 24924–24940, 2021
2021
-
[62]
Gnot: A general neural operator transformer for operator learning,
Z. Hao, Z. Wang, H. Su, C. Ying, Y. Dong, S. Liu, Z. Cheng, J. Song, and J. Zhu, “Gnot: A general neural operator transformer for operator learning,” inInternational Conference on Machine Learning, pp. 12556–12569, PMLR, 2023
2023
-
[63]
Transformer for partial differential equations’ operator learning,
Z. Li, K. Meidani, and A. B. Farimani, “Transformer for partial differential equations’ operator learning,”Transactions on Machine Learning Research, 2023
2023
-
[64]
Large-scale distributed training of transformers for chemical fingerprinting,
H. Abdel-Aty and I. R. Gould, “Large-scale distributed training of transformers for chemical fingerprinting,”Journal of Chemical Information and Modeling, vol. 62, no. 20, pp. 4852–4862, 2022
2022
-
[65]
Self-attention with relative position repre- sentations
P. Shaw, J. Uszkoreit, and A. Vaswani, “Self-attention with relative position representations,” arXiv preprint arXiv:1803.02155, 2018
-
[66]
Rethinking and improving relative position encoding for vision transformer,
K. Wu, H. Peng, M. Chen, J. Fu, and H. Chao, “Rethinking and improving relative position encoding for vision transformer,” inProceedings of the IEEE/CVF international conference on computer vision, pp. 10033–10041, 2021
2021
-
[67]
Roformer: Enhanced transformer with rotary position embedding,
J. Su, M. Ahmed, Y. Lu, S. Pan, W. Bo, and Y. Liu, “Roformer: Enhanced transformer with rotary position embedding,”Neurocomputing, vol. 568, p. 127063, 2024
2024
-
[68]
Relational inductive biases, deep learning, and graph networks
P. W. Battaglia, J. B. Hamrick, V. Bapst, A. Sanchez-Gonzalez, V. Zambaldi, M. Malinowski, A. Tacchetti, D. Raposo, A. Santoro, R. Faulkner,et al., “Relational inductive biases, deep learning, and graph networks,”arXiv preprint arXiv:1806.01261, 2018. 29
work page internal anchor Pith review arXiv 2018
-
[69]
Graph networks as learnable physics engines for inference and control,
A. Sanchez-Gonzalez, N. Heess, J. T. Springenberg, J. Merel, M. Riedmiller, R. Hadsell, and P. Battaglia, “Graph networks as learnable physics engines for inference and control,” inInter- national conference on machine learning, pp. 4470–4479, PMLR, 2018
2018
-
[70]
Learning to simulate complex physics with graph networks,
A. Sanchez-Gonzalez, J. Godwin, T. Pfaff, R. Ying, J. Leskovec, and P. Battaglia, “Learning to simulate complex physics with graph networks,” inInternational conference on machine learning, pp. 8459–8468, PMLR, 2020
2020
-
[71]
Deep learning method based on physics informed neural network with resnet block for solving fluid flow problems,
C. Cheng and G.-T. Zhang, “Deep learning method based on physics informed neural network with resnet block for solving fluid flow problems,”Water, vol. 13, no. 4, p. 423, 2021
2021
-
[72]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inPro- ceedings of the IEEE conference on computer vision and pattern recognition, pp. 770–778, 2016
2016
-
[73]
Resunet-a: A deep learning framework for semantic segmentation of remotely sensed data,
F. I. Diakogiannis, F. Waldner, P. Caccetta, and C. Wu, “Resunet-a: A deep learning framework for semantic segmentation of remotely sensed data,”ISPRS Journal of Photogrammetry and Remote Sensing, vol. 162, pp. 94–114, 2020
2020
-
[74]
arXiv preprint arXiv:1711.08506 , year=
X. Xia and B. Kulis, “W-net: A deep model for fully unsupervised image segmentation,”arXiv preprint arXiv:1711.08506, 2017
-
[75]
Stacked u-nets: a no-frills approach to natural image segmentation,
S. Shah, P. Ghosh, L. S. Davis, and T. Goldstein, “Stacked u-nets: a no-frills approach to natural image segmentation,”arXiv preprint arXiv:1804.10343, 2018
-
[76]
U-net: Convolutional networks for biomedical image segmentation,
O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” inMedical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18, pp. 234–241, Springer, 2015
2015
-
[77]
Pdebench: An extensive benchmark for scientific machine learning,
M. Takamoto, T. Praditia, R. Leiteritz, D. MacKinlay, F. Alesiani, D. Pfl¨ uger, and M. Niepert, “Pdebench: An extensive benchmark for scientific machine learning,”Advances in Neural Infor- mation Processing Systems, vol. 35, pp. 1596–1611, 2022
2022
-
[78]
Group normalization,
Y. Wu and K. He, “Group normalization,” inProceedings of the European conference on computer vision (ECCV), pp. 3–19, 2018
2018
-
[79]
S. Zagoruyko and N. Komodakis, “Wide residual networks,”arXiv preprint arXiv:1605.07146, 2016
work page internal anchor Pith review arXiv 2016
-
[80]
Denoising diffusion probabilistic models,
J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,”Advances in neural information processing systems, vol. 33, pp. 6840–6851, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.