Recognition: 2 theorem links
· Lean TheoremStableI2I: Spotting Unintended Changes in Image-to-Image Transition
Pith reviewed 2026-05-08 18:17 UTC · model grok-4.3
The pith
StableI2I measures content fidelity and consistency in image-to-image tasks by querying multimodal models without reference images.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
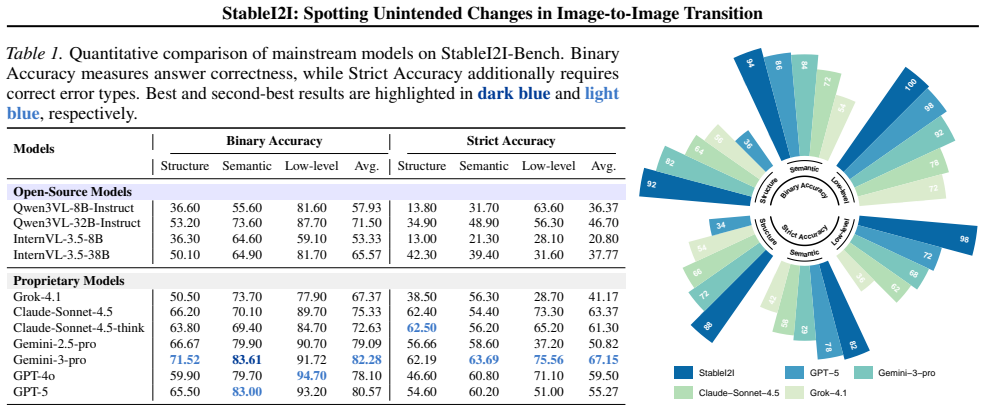
StableI2I is a unified dynamic framework that uses multimodal large language models to evaluate content fidelity and pre-post consistency in a wide range of image-to-image scenarios without requiring reference images. It constructs StableI2I-Bench to measure the accuracy of these model-based judgments. Experiments show that the resulting evaluations are accurate, fine-grained, interpretable, and strongly correlated with human subjective judgments, making the framework a practical tool for diagnosing consistency problems in real-world I2I systems.
What carries the argument
The StableI2I framework, which dynamically prompts multimodal large language models to assess semantic correspondence and spatial structure between an input image and its edited or restored output.
If this is right
- Developers can diagnose specific consistency failures in image editing and restoration models without collecting paired reference data.
- Benchmarking suites for I2I systems can incorporate automated fidelity checks that track changes across diverse tasks.
- Model selection for real-world applications can prioritize outputs that maintain input structure according to the framework's scores.
- Iterative improvement of generative pipelines becomes possible by using the framework's interpretable feedback on unintended alterations.
Where Pith is reading between the lines
- The same prompting approach could be adapted to video or 3D generation tasks if multimodal models handle temporal or volumetric consistency well.
- Training loops for I2I models might incorporate StableI2I-style scores as an auxiliary loss to penalize unintended changes directly.
- Widespread adoption could shift evaluation standards away from reference-based metrics toward reference-free semantic checks in production pipelines.
Load-bearing premise
Multimodal large language models can reliably detect semantic and structural changes in image-to-image outputs without any reference image.
What would settle it
A collection of image editing and restoration examples where human raters assign high fidelity scores but StableI2I assigns low scores, or vice versa, on a scale large enough to break the reported correlation.
Figures














read the original abstract
In most real-world image-to-image (I2I) scenarios, existing evaluations primarily focus on instruction following and the perceptual quality or aesthetics of the generated images. However, they largely fail to assess whether the output image preserves the semantic correspondence and spatial structure of the input image. To address this limitation, we propose StableI2I, a unified and dynamic evaluation framework that explicitly measures content fidelity and pre--post consistency across a wide range of I2I tasks without requiring reference images, including image editing and image restoration. In addition, we construct StableI2I-Bench, a benchmark designed to systematically evaluate the accuracy of MLLMs on such fidelity and consistency assessment tasks. Extensive experimental results demonstrate that StableI2I provides accurate, fine-grained, and interpretable evaluations of content fidelity and consistency, with strong correlations to human subjective judgments. Our framework serves as a practical and reliable evaluation tool for diagnosing content consistency and benchmarking model performance in real-world I2I systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes StableI2I, a unified dynamic evaluation framework that uses MLLMs to measure content fidelity and pre-post consistency in image-to-image tasks (editing, restoration, etc.) without reference images. It introduces StableI2I-Bench to quantify MLLM accuracy on these fidelity/consistency tasks and reports that extensive experiments show accurate, fine-grained, interpretable evaluations with strong correlations to human judgments.
Significance. If the central experimental claims hold, the framework would address a clear gap in I2I evaluation by enabling reference-free diagnosis of semantic correspondence and spatial structure preservation, which existing metrics largely ignore. This could become a practical benchmarking tool for real-world I2I systems.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: the claim of 'strong correlations to human subjective judgments' and 'accurate, fine-grained' evaluation is presented without any quantitative results, correlation coefficients, per-task breakdowns, or tables showing performance on spatial-heavy cases; this is load-bearing for the central claim yet unverifiable from the provided evidence.
- [StableI2I-Bench] StableI2I-Bench construction (likely §3): the benchmark description does not include explicit controls, held-out spatial-reasoning subsets, or difficulty distributions designed to stress-test documented MLLM failure modes such as object positioning inconsistencies or fine-grained attribute tracking, leaving the reliability assumption untested.
minor comments (1)
- [Abstract] Abstract: 'pre--post consistency' contains a typographical double hyphen.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify how to strengthen the presentation of our experimental claims and benchmark details. We respond point-by-point below and will incorporate revisions to address the concerns.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: the claim of 'strong correlations to human subjective judgments' and 'accurate, fine-grained' evaluation is presented without any quantitative results, correlation coefficients, per-task breakdowns, or tables showing performance on spatial-heavy cases; this is load-bearing for the central claim yet unverifiable from the provided evidence.
Authors: We agree that the abstract summarizes the findings without including the specific quantitative details. The Experiments section provides the supporting results on content fidelity and consistency evaluations, including correlations with human judgments, per-task breakdowns, and analysis of spatial structure cases. To improve verifiability and prominence, we will revise the abstract to reference key quantitative highlights and add an overview table summarizing the main correlation metrics and per-task results at the start of the Experiments section. revision: yes
-
Referee: [StableI2I-Bench] StableI2I-Bench construction (likely §3): the benchmark description does not include explicit controls, held-out spatial-reasoning subsets, or difficulty distributions designed to stress-test documented MLLM failure modes such as object positioning inconsistencies or fine-grained attribute tracking, leaving the reliability assumption untested.
Authors: We appreciate this observation on the benchmark description. Section 3 currently outlines the overall task construction and evaluation protocol. In the revised manuscript, we will expand this section with a new subsection that details the explicit controls, introduces held-out spatial-reasoning subsets, describes the difficulty distributions, and explains how the design targets MLLM failure modes such as object positioning inconsistencies and fine-grained attribute tracking. revision: yes
Circularity Check
No significant circularity in framework or validation chain
full rationale
The paper defines StableI2I as an MLLM-based framework for measuring content fidelity and consistency in I2I tasks without references, then introduces StableI2I-Bench to test MLLM accuracy on those tasks. Central claims rest on reported correlations between MLLM outputs and independent human subjective judgments. No equations, fitted parameters, or self-citations are shown to reduce any prediction or result to the inputs by construction. The evaluation chain treats human judgments as an external reference rather than a self-referential loop, making the derivation self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multimodal LLMs can accurately detect unintended semantic and spatial changes in I2I outputs
Lean theorems connected to this paper
-
Cost.FunctionalEquation (J(x)=½(x+x⁻¹)−1)washburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
RBinary = max(0, |P̂∩P|/|P| − α|P̂\P|/|P|), where α penalizes false positive predictions.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Accessed: 2025-08-20. Wang, J., Chan, K. C., and Loy, C. C. Exploring CLIP for Assessing the Look and Feel of Images. InAAAI, 2023. Wang, W., Gao, Z., Gu, L., Pu, H., Cui, L., Wei, X., Liu, Z., Jing, L., Ye, S., Shao, J., et al. Internvl3.5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, ...
work page internal anchor Pith review arXiv 2025
-
[2]
Any change that is a necessary and physically plausible consequence of the intended edit (e.g., lighting, shading, subtle color adaptation) should NOT be counted as an error
Only judge regions that are NOT explicitly targeted by the task prompt. Any change that is a necessary and physically plausible consequence of the intended edit (e.g., lighting, shading, subtle color adaptation) should NOT be counted as an error
-
[3]
Ignore purely semantic category changes unless they manifest as clear repainting or structural deformation
Focus on structure and texture consistency only. Ignore purely semantic category changes unless they manifest as clear repainting or structural deformation
-
[4]
Any deviation should be marked as inconsistent
If the task prompt is NULL (no specified edit/restoration intent), then the expected behavior is identity mapping: the two images should be completely identical in structure and texture. Any deviation should be marked as inconsistent
-
[5]
If both misalignment and repainting are observed, list both
-
[6]
answer":
When uncertain, choose ‘‘No’’ (i.e., favor sensitivity over specificity). Return your decision in a single line of valid JSON with the format: {"answer": "Yes", "problem": "NULL"}if the images are consistent, otherwise{"answer": "No", "problem": ["misalignment", "repainting"]}, where the "problem" field should reflect the dominant issue(s) observed. Model...
-
[7]
Ignore purely low-level appearance differences (e.g., mild noise, compression artifacts) unless they cause an actual semantic change (e.g., text becomes unreadable)
Focus on semantic content only. Ignore purely low-level appearance differences (e.g., mild noise, compression artifacts) unless they cause an actual semantic change (e.g., text becomes unreadable)
-
[8]
Legitimate global side effects that are a physically plausible consequence of the intended edit (e.g., shadows, reflections, minor lighting changes) should NOT be counted as semantic errors
-
[9]
Any semantic difference should be marked as inconsistent
If the task prompt is NULL (no specified edit/restoration intent), then the expected behavior is identity mapping: the two images should 16 StableI2I: Spotting Unintended Changes in Image-to-Image Transition be completely identical in semantic content. Any semantic difference should be marked as inconsistent
-
[10]
answer":
Use ‘‘No’’ whenever you detect any potential semantic inconsistency in regions that should have been preserved. Return your decision in a single line of valid JSON with the format: {"answer": "Yes", "problem": "NULL"}if the images are semantically consistent, otherwise{"answer": "No", "problem": ["add", "replace", "remove"]}. Model Output (GT): {"answer":...
2053
-
[11]
- Explicitly state which changes can be ignored because they fall inside the intended edit scope
Preservation analysis (think): - Identify the intended edit target region(s) according to the task prompt. - Explicitly state which changes can be ignored because they fall inside the intended edit scope. - Identify the regions/elements that must be preserved (non-edit regions), and list them as a concrete checklist with brief justification
-
[12]
think":
Problem reporting (problem): - Report ONLY issues that violate the preservation analysis above. - If something was stated as ignorable or allowed-to-change in the think stage, it MUST NOT appear here. - Focus on preserved regions and explain the semantic drift clearly. - Use only the drift type keys that were provided above (Drift type(s): XXX). Output Fo...
-
[13]
- State which changes are allowed ONLY if they occur strictly inside the intended target region(s)
Preservation & scope analysis (think): - Identify the intended target region(s) implied by the task prompt. - State which changes are allowed ONLY if they occur strictly inside the intended target region(s). - Clarify that low-level degradations (noise/blur/color cast/exposure issues/artifacts) are NOT intended unless the task prompt explicitly requests l...
-
[14]
Problem reporting (problem): - Report ONLY low-level degradations that violate the scope above (i.e., occur in preserved regions or exceed intended scope). - If no violation is found, output an empty object: problem = . - Use ONLY the keys provided in YYY. Do not invent new keys. - For each key you include, describe: where it appears, how it differs from ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.