Recognition: unknown
Anticipating Innovation Using Large Language Models
Pith reviewed 2026-05-08 17:09 UTC · model grok-4.3
The pith
Forthcoming technological combinations leave detectable traces in patent language decades before they occur.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Forthcoming combinations leave an early trace in the collective language of patents, with predictive signals detectable even decades in advance. The signal is not attributable to any single inventor but emerges as a collective shift in how technologies are described across thousands of patents. Context similarity between embeddings of International Patent Classification codes accurately predicts first technological combinations.
What carries the argument
TechToken, a transformer model that embeds International Patent Classification codes as tokens during fine-tuning on patent texts and uses context similarity between those embeddings to quantify linguistic convergence between technologies.
If this is right
- Long-horizon forecasts of technology combinations become feasible using only historical patent text data.
- Innovation signals arise collectively from the full patent corpus rather than from individual inventors or firms.
- The same model yields better performance on standard patent-related tasks such as classification and retrieval.
- Resource allocation for research and development could be guided by early linguistic signals of convergence.
Where Pith is reading between the lines
- The method could be adapted to scientific abstracts or grant proposals to forecast emerging research topic combinations.
- It invites tests for whether the detected shifts track real technical progress or merely evolving legal and drafting conventions in patent offices.
- Extending the embeddings to non-patent corpora might reveal whether the predictive power is specific to intellectual-property language or holds more generally.
Load-bearing premise
That similarity in the textual contexts of patent classification codes reflects genuine upcoming technological convergence rather than changes in patent writing styles or other unrelated factors.
What would settle it
A test on patents filed after the model's training cutoff showing that pairs with high predicted context similarity do not combine at rates significantly above those of randomly selected pairs.
Figures



read the original abstract
Forecasting innovation, intended as the emergence of new technological combinations, is a fundamental challenge for science and policy. We show that forthcoming combinations leave an early trace in the collective language of patents, with predictive signals detectable even decades in advance. We show that signal is not attributable to any single inventor, but emerges as a collective shift in how technologies are described across thousands of patents. To this end, we introduce TechToken, a transformer-based model that treats technologies, classified by International Patent Classification codes, as words in its vocabulary, learning the language of technologies by embedding these codes during fine-tuning. We define context similarity between code embeddings as a measure of linguistic convergence and show that it accurately predicts first technological combinations. TechToken also improves general representation quality, outperforming state-of-the-art models across different patent-related tasks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TechToken, a transformer-based model that embeds IPC codes as tokens in its vocabulary to learn the 'language of technologies.' It claims that context similarity between these embeddings captures collective linguistic convergence in patents, allowing accurate prediction of future technological combinations (first co-occurrences) even decades in advance. The predictive signal is asserted to be collective rather than inventor-specific, and TechToken is reported to outperform prior models on multiple patent-related tasks.
Significance. If the predictive validity holds after rigorous controls, the work offers a scalable, data-driven method for early detection of technological convergence using patent corpora and modern language models. This could inform innovation policy and R&D strategy by surfacing collective shifts in technical description that precede actual combinations. The framing of the signal as emergent from thousands of patents rather than individual inventors is a conceptual strength.
major comments (2)
- [Evaluation / Results] The central claim that context similarity between IPC embeddings predicts genuine technological convergence (rather than time-varying confounders) is load-bearing for the forecasting result. The evaluation must include explicit controls such as year-stratified baselines, ablation of drafting-style features, or comparison against IPC reclassification effects; without these, similarity could arise from correlated changes in patent language across the corpus.
- [Abstract and Results] The abstract and method description assert that the model 'accurately predicts' first combinations and outperforms SOTA, yet no quantitative details (effect sizes, baseline comparisons, validation time windows, or statistical tests) are supplied in the provided summary. Full results must report these metrics with clear train/test temporal splits to demonstrate that the signal is not an artifact of data leakage or volume trends.
minor comments (2)
- [Method] Clarify the exact definition and computation of 'context similarity' (e.g., cosine on which layer, aggregation over contexts) with an equation or pseudocode for reproducibility.
- [Results] The claim that the signal 'is not attributable to any single inventor' requires an explicit ablation or control experiment showing that inventor-level features do not drive the similarity scores.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We agree that strengthening the controls for confounders and providing explicit quantitative metrics will improve the manuscript. We address each major comment below and will incorporate revisions accordingly.
read point-by-point responses
-
Referee: [Evaluation / Results] The central claim that context similarity between IPC embeddings predicts genuine technological convergence (rather than time-varying confounders) is load-bearing for the forecasting result. The evaluation must include explicit controls such as year-stratified baselines, ablation of drafting-style features, or comparison against IPC reclassification effects; without these, similarity could arise from correlated changes in patent language across the corpus.
Authors: We agree that rigorous controls for time-varying confounders are necessary to support the central claim. The manuscript already employs temporal train/test splits to reduce leakage risks, but we acknowledge that additional explicit controls would strengthen the evaluation. In the revised version, we will add year-stratified baseline models, ablations removing drafting-style features (e.g., by normalizing patent text length and vocabulary), and a comparison against IPC reclassification effects. These will demonstrate that the predictive signal persists beyond corpus-wide language shifts or label changes. revision: yes
-
Referee: [Abstract and Results] The abstract and method description assert that the model 'accurately predicts' first combinations and outperforms SOTA, yet no quantitative details (effect sizes, baseline comparisons, validation time windows, or statistical tests) are supplied in the provided summary. Full results must report these metrics with clear train/test temporal splits to demonstrate that the signal is not an artifact of data leakage or volume trends.
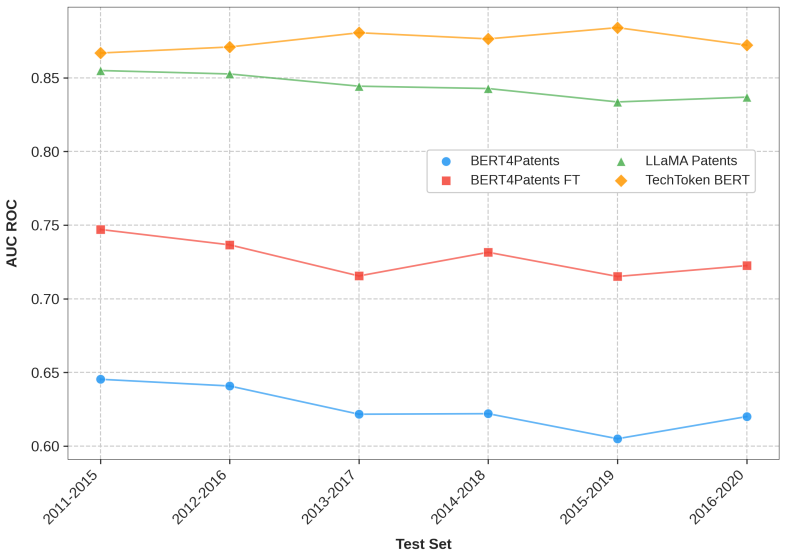
Authors: We will update the abstract to include key quantitative results, such as AUC-ROC values for first-combination prediction, effect sizes relative to baselines, and explicit validation time windows (e.g., training on patents through 2000 and testing on combinations from 2001 onward). The full results section reports these metrics along with statistical tests (e.g., paired t-tests against SOTA models) and temporal splits. To further address potential artifacts from data leakage or volume trends, we will add a robustness subsection showing performance stability across varying corpus sizes and confirming no leakage in the embedding fine-tuning process. revision: yes
Circularity Check
No significant circularity; derivation uses historical training to predict future events
full rationale
The paper trains TechToken on historical patent data to embed IPC codes as tokens in a transformer, then defines context similarity on those embeddings to forecast future first combinations of technologies. This is a standard out-of-sample prediction setup where representations are learned from past data and applied to unseen future combinations, without any self-definitional equivalence, fitted parameters renamed as predictions, or load-bearing self-citations. The abstract and description present the signal as emerging from collective linguistic shifts detectable decades ahead, with no equations or steps reducing the claimed predictions to the inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Transformer-based models can learn meaningful contextual relationships when IPC codes are treated as tokens
Reference graph
Works this paper leans on
-
[1]
Olivier Eulaerts, Marcelina Grabowska, and Michela Bergamini.Early-stage technolo- gies in the field of Clean Energy: Status Report on Technology Development, Trends, Value Chains and Markets. Tech. rep. JRC145225. Publications Office of the Euro- pean Union, 2026.doi:10.2760/8002916
-
[2]
World Intellectual Property Organization, 2025.doi:10
World Intellectual Property Organization.WIPO Technology Trends: Future of Trans- portation. World Intellectual Property Organization, 2025.doi:10 . 34667 / tind . 57963
2025
-
[3]
Paris: OECD Pub- lishing, 2023.doi:10.1787/0b55736e-en
OECD.OECD Science, Technology and Innovation Outlook 2023. Paris: OECD Pub- lishing, 2023.doi:10.1787/0b55736e-en
-
[4]
Joseph Alois Schumpeter.The theory of economic development: An inquiry into prof- its, capital, credit, interest, and the business cycle. Vol. 55. Transaction publishers, 1983
1983
-
[5]
routledge, 2013
Joseph A Schumpeter.Capitalism, socialism and democracy. routledge, 2013
2013
-
[6]
Invention as a combinatorial process: evidence from US patents
Hyejin Youn et al. “Invention as a combinatorial process: evidence from US patents”. In:Journal of the Royal Society interface12.106 (2015), p. 20150272
2015
-
[7]
Surprising combinations of research contents and con- texts are related to impact and emerge with scientific outsiders from distant disci- plines
Feng Shi and James Evans. “Surprising combinations of research contents and con- texts are related to impact and emerge with scientific outsiders from distant disci- plines”. In:Nature Communications14.1 (2023), p. 1641
2023
-
[8]
Technological change in the machine tool industry, 1840–1910
Nathan Rosenberg. “Technological change in the machine tool industry, 1840–1910”. In:The journal of economic history23.4 (1963), pp. 414–443
1910
-
[9]
Patent indicators for monitoring convergence– examples from NFF and ICT
Clive-Steven Curran and Jens Leker. “Patent indicators for monitoring convergence– examples from NFF and ICT”. In:Technological forecasting and social change78.2 (2011), pp. 256–273
2011
-
[10]
Exploring the research landscape of convergence from a TIM perspective: A review and research agenda
Nathalie Sick and Stefanie Br¨ oring. “Exploring the research landscape of convergence from a TIM perspective: A review and research agenda”. In:Technological Forecasting and Social Change175 (2022), p. 121321. 14
2022
-
[11]
Oxford University Press, 2000
Stuart A Kauffman.Investigations. Oxford University Press, 2000
2000
-
[12]
The dynamics of correlated novelties
Francesca Tria et al. “The dynamics of correlated novelties”. In:Scientific Reports4 (2014), p. 5890.doi:10.1038/srep05890
-
[13]
The building blocks of economic complex- ity
C´ esar A. Hidalgo and Ricardo Hausmann. “The building blocks of economic complex- ity”. In:Proceedings of the National Academy of Sciences106.26 (2009), pp. 10570– 10575
2009
-
[14]
PLOS ONE9(12), 113490 (2014) https://doi.org/10.1371/journal
Andrea Zaccaria et al. “How the taxonomy of products drives the economic develop- ment of countries”. In:PLOS ONE9.12 (2014), e0113770.doi:10.1371/journal. pone.0113770
-
[15]
Relatedness in the era of machine learning
Andrea Tacchella et al. “Relatedness in the era of machine learning”. In:Chaos, Solitons & Fractals176 (2023), p. 114167
2023
-
[16]
Projection-based link prediction in a bipartite network
Man Gao et al. “Projection-based link prediction in a bipartite network”. In:Infor- mation Sciences376 (2017), pp. 158–171
2017
-
[17]
Nonrandom behavior in the projection of random bipartite networks
Izat B Baybusinov et al. “Nonrandom behavior in the projection of random bipartite networks”. In:Physical Review E109.2 (2024), p. 024308
2024
-
[18]
Prediction of technology convergence on the basis of supernet- work
Junwan Liu et al. “Prediction of technology convergence on the basis of supernet- work”. In:IEEE Transactions on Engineering Management(2024)
2024
-
[19]
Effective indexes and classification algorithms for supervised link prediction approach to anticipating technology convergence: A comparative study
Suckwon Hong and Changyong Lee. “Effective indexes and classification algorithms for supervised link prediction approach to anticipating technology convergence: A comparative study”. In:IEEE Transactions on Engineering Management70.4 (2021), pp. 1430–1441
2021
-
[20]
A framework for technology opportunity discovery using GAT- based link prediction and network analysis
Zhi-Xing Chang et al. “A framework for technology opportunity discovery using GAT- based link prediction and network analysis”. In:Advanced Engineering Informatics 66 (2025), p. 103498
2025
-
[21]
Predicting future technological convergence patterns based on machine learning using link prediction
Joon Hyung Cho, Jungpyo Lee, and So Young Sohn. “Predicting future technological convergence patterns based on machine learning using link prediction”. In:Sciento- metrics126.7 (2021), pp. 5413–5429
2021
-
[22]
A supervised learning- based approach to anticipating potential technology convergence
Sungchul Choi, Mokhammad Afifuddin, and Wonchul Seo. “A supervised learning- based approach to anticipating potential technology convergence”. In:Ieee Access10 (2022), pp. 19284–19300
2022
-
[23]
DNformer: Temporal link prediction with transfer learning in dy- namic networks
Xin Jiang et al. “DNformer: Temporal link prediction with transfer learning in dy- namic networks”. In:ACM Transactions on Knowledge Discovery from Data17.3 (2023), pp. 1–21
2023
-
[24]
Forecasting technology convergence with the spatiotemporal link prediction model
Jianyu Zhao et al. “Forecasting technology convergence with the spatiotemporal link prediction model”. In:Technovation146 (2025), p. 103289
2025
-
[25]
Technology fusion: Identification and analysis of the drivers of technology convergence using patent data
Federico Caviggioli. “Technology fusion: Identification and analysis of the drivers of technology convergence using patent data”. In:Technovation55 (2016), pp. 22–32
2016
-
[26]
Predictive modeling for technology convergence: A patent data-driven approach through technology topic networks
Mokh Afifuddin and Wonchul Seo. “Predictive modeling for technology convergence: A patent data-driven approach through technology topic networks”. In:Computers & Industrial Engineering188 (2024), p. 109909
2024
-
[27]
Combining topic modeling and SAO semantic analysis to identify technological opportunities of emerging technologies
Tingting Ma et al. “Combining topic modeling and SAO semantic analysis to identify technological opportunities of emerging technologies”. In:Technological Forecasting and Social Change173 (2021), p. 121159
2021
-
[28]
Technology opportunity analysis using hierarchical semantic networks and dual link prediction
Zhenfeng Liu, Jian Feng, and Lorna Uden. “Technology opportunity analysis using hierarchical semantic networks and dual link prediction”. In:Technovation128 (2023), p. 102872
2023
-
[29]
Attention Is All You Need
Ashish Vaswani et al. “Attention Is All You Need”. In:Advances in Neural Informa- tion Processing Systems 30. 2017. 15
2017
-
[30]
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
Nils Reimers and Iryna Gurevych. “Sentence-bert: Sentence embeddings using siamese bert-networks”. In:arXiv preprint arXiv:1908.10084(2019)
work page internal anchor Pith review arXiv 1908
-
[31]
Developing a predictive model for anticipat- ing technology convergence: A transformer-based model and supervised learning ap- proach
Mokh Afifuddin and Wonchul Seo. “Developing a predictive model for anticipat- ing technology convergence: A transformer-based model and supervised learning ap- proach”. In:PloS one20.6 (2025), e0326417
2025
-
[32]
The proximity of ideas: An analysis of patent text using machine learn- ing
Sijie Feng. “The proximity of ideas: An analysis of patent text using machine learn- ing”. In:PloS one15.7 (2020), e0234880
2020
-
[33]
The language of innovation
Andrea Tacchella, Andrea Napoletano, and Luciano Pietronero. “The language of innovation”. In:PloS one15.4 (2020), e0230107
2020
-
[34]
Connected components in random graphs with given expected degree sequences
Fan Chung and Linyuan Lu. “Connected components in random graphs with given expected degree sequences”. In:Annals of combinatorics6.2 (2002), pp. 125–145
2002
-
[35]
Natural language processing in the patent domain: a survey
Lekang Jiang and Stephan M Goetz. “Natural language processing in the patent domain: a survey”. In:Artificial Intelligence Review58.7 (2025), p. 214
2025
-
[36]
Patentsberta: A deep nlp based hybrid model for patent distance and classification using augmented sbert
Hamid Bekamiri, Daniel S Hain, and Roman Jurowetzki. “Patentsberta: A deep nlp based hybrid model for patent distance and classification using augmented sbert”. In: Technological Forecasting and Social Change206 (2024), p. 123536
2024
-
[37]
arXiv preprint arXiv:2402.19411 , year=
Mainak Ghosh et al. “PaECTER: Patent-level representation learning using citation- informed transformers”. In:arXiv preprint arXiv:2402.19411(2024)
-
[38]
BERT: Pre-training of Deep Bidirectional Transformers for Lan- guage Understanding
Jacob Devlin et al. “BERT: Pre-training of Deep Bidirectional Transformers for Lan- guage Understanding”. In:Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Tech- nologies, Volume 1 (Long and Short Papers). Ed. by Jill Burstein, Christy Doran, and Thamar Solorio. Minneapolis...
2019
-
[39]
Rob Srebrovic and Jay Yonamine.Leveraging the BERT algorithm for Patents with TensorFlow and BigQuery. Tech. rep. Google, 2020
2020
-
[40]
Aaron Grattafiori et al. “The llama 3 herd of models”. In:arXiv preprint arXiv:2407.21783 (2024)
work page internal anchor Pith review arXiv 2024
-
[41]
Fangyu Liu et al. “Fast, effective, and self-supervised: Transforming masked language models into universal lexical and sentence encoders”. In:arXiv preprint arXiv:2104.08027 (2021)
-
[42]
Parishad BehnamGhader et al. “Llm2vec: Large language models are secretly powerful text encoders”. In:arXiv preprint arXiv:2404.05961(2024)
-
[43]
Inferring monopartite projections of bipartite networks: an entropy-based approach
Fabio Saracco et al. “Inferring monopartite projections of bipartite networks: an entropy-based approach”. In:New Journal of Physics19.5 (2017), p. 053022. 16
2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.