PSK at SemEval-2026 Task 9: Multilingual Polarization Detection Using Ensemble Gemma Models with Synthetic Data Augmentation
Pith reviewed 2026-05-08 16:37 UTC · model grok-4.3
The pith
Per-language fine-tuned Gemma models augmented with GPT-4o-mini synthetic data and threshold tuning reach a mean macro-F1 of 0.811 across 22 languages.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
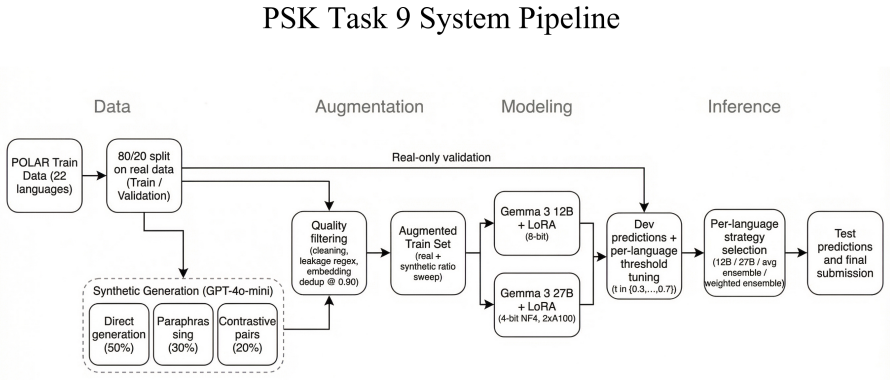
Fine-tuning Gemma-3 models separately for each of 22 languages on real data plus synthetic polarized text generated by GPT-4o-mini, then forming per-language weighted ensembles and applying development-set threshold tuning, yields a mean macro-F1 of 0.811 while alternative architectures suffer 30-50% F1 drops on the test set.
What carries the argument
Per-language LoRA fine-tuning of Gemma-3 12B and 27B models on filtered synthetic data from GPT-4o-mini, combined via weighted ensembles with language-specific threshold selection.
If this is right
- Synthetic data augmentation combined with per-language specialization improves robustness in multilingual classification.
- Threshold tuning on a development set delivers 2-4% F1 gains without retraining the models.
- Architectures that excel on development data can still lose 30-50% F1 on test data, showing that generalization must be verified explicitly.
- Ensemble selection of model size and synthetic strategy per language increases consistency across diverse languages.
Where Pith is reading between the lines
- The same synthetic-augmentation pipeline could be tested on other multilingual tasks where labeled polarized examples are scarce.
- Language-specific fine-tuning may capture polarization cues that a single shared model would miss.
- Future experiments could measure how much performance depends on the particular LLM used to create the synthetic examples.
- If the threshold-tuning gains hold only because the development set mirrors the test set, the reported ranking may not transfer to new domains.
Load-bearing premise
Synthetic data generated by GPT-4o-mini matches the distribution of real polarized text in every language and development-set threshold tuning will generalize to the unseen test set.
What would settle it
Evaluating the identical pipeline on a new test collection drawn from different sources and observing whether mean macro-F1 falls substantially below 0.811 or whether removing the synthetic data causes comparable degradation.
Figures
read the original abstract
We present our system for SemEval-2026 Task 9: Multilingual Polarization Detection, a binary classification task spanning 22 languages. Our approach fine-tunes separate Gemma~3 models (12B and 27B parameters) per language using Low-Rank Adaptation (LoRA), augmented with synthetic data generated by a large language model (LLM). We employ three synthetic data strategies (direct generation, paraphrasing, and contrastive pair creation) using GPT-4o-mini, with a multi-stage quality filtering pipeline including embedding-based deduplication. We find that per-language threshold tuning on the development set yields 2 to 4\% F1 improvements without retraining. We also use weighted ensembles of 12B and 27B model predictions with per-language strategy selection. Our final system achieves a mean macro-F1 of 0.811 across all 22 languages, ranking 2nd overall of the participating teams, with 1st place finishes in 3 languages and top-3 in 8 languages. We also find that alternative architectures (XLM-RoBERTa, Qwen3) that showed strong development set performance suffered 30 to 50\% F1 drops on the test set, highlighting the importance of generalization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents the PSK team's submission to SemEval-2026 Task 9 on multilingual polarization detection across 22 languages. It fine-tunes separate Gemma-3 (12B and 27B) models per language with LoRA, augments training data using three synthetic strategies (direct generation, paraphrasing, contrastive pairs) from GPT-4o-mini plus embedding-based deduplication, applies per-language threshold tuning on the development set, and uses weighted ensembles with per-language strategy selection. The system reports a mean macro-F1 of 0.811, 2nd place overall, 1st in 3 languages and top-3 in 8, while noting that XLM-RoBERTa and Qwen3 suffer 30-50% F1 drops on the test set.
Significance. If the synthetic data augmentation and per-language threshold tuning are shown to generalize, the work supplies a competitive baseline for multilingual polarization detection and useful evidence of generalization fragility across architectures. The concrete ranking and cross-architecture comparison are strengths. Without ablations isolating the contributions of the synthetic data and tuning, however, the result remains primarily a competition outcome rather than a source of transferable methodological insight.
major comments (2)
- [Abstract and Results] The reported 2-4% F1 gains from per-language threshold tuning on the development set (Abstract) are load-bearing for the final ranking, yet no ablation or analysis is provided to show that the chosen thresholds generalize to the unseen test distribution rather than capturing dev-set artifacts. This is especially salient given the 30-50% drops observed for other models.
- [Method and Experiments] No ablation is presented comparing Gemma-3 performance with versus without the GPT-4o-mini synthetic data (direct generation, paraphrasing, contrastive pairs plus deduplication). The central claim attributes success to this augmentation pipeline, but the assumption that the synthetic distribution matches real polarized text across all 22 languages remains untested.
minor comments (2)
- [Method] Exact ensemble weights, per-language strategy selection rules, and the precise criteria/thresholds used in the multi-stage quality filtering pipeline are not specified, hindering reproducibility.
- [Results] Performance numbers lack error bars, confidence intervals, or statistical significance tests comparing the final system to baselines or ablated variants.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the value of ablations for establishing transferable insights beyond the competition results. We address each major comment below and will revise the manuscript to incorporate additional discussion and analysis of limitations.
read point-by-point responses
-
Referee: [Abstract and Results] The reported 2-4% F1 gains from per-language threshold tuning on the development set (Abstract) are load-bearing for the final ranking, yet no ablation or analysis is provided to show that the chosen thresholds generalize to the unseen test distribution rather than capturing dev-set artifacts. This is especially salient given the 30-50% drops observed for other models.
Authors: We agree that an explicit ablation comparing tuned versus untuned thresholds on the test set would strengthen claims of generalization. Thresholds were selected exclusively on the development set under competition constraints where test labels were unavailable. Our final test performance (mean macro-F1 0.811, 2nd place) and the 30-50% drops for XLM-RoBERTa and Qwen3 provide indirect support for the approach. In the revised manuscript we will add a subsection analyzing the per-language threshold values, their variance, and a discussion of possible dev-set artifacts, while acknowledging the absence of a direct test-set ablation. revision: partial
-
Referee: [Method and Experiments] No ablation is presented comparing Gemma-3 performance with versus without the GPT-4o-mini synthetic data (direct generation, paraphrasing, contrastive pairs plus deduplication). The central claim attributes success to this augmentation pipeline, but the assumption that the synthetic distribution matches real polarized text across all 22 languages remains untested.
Authors: We acknowledge that a controlled ablation isolating the synthetic data pipeline on the test set is missing. Internal development runs indicated performance gains from the three strategies and embedding-based deduplication, motivating their use. However, a full test-set comparison was not performed within the shared-task timeline. We will revise the manuscript to include a limitations paragraph explicitly addressing the untested synthetic-to-real distribution match across languages, along with qualitative examples of generated data and the quality filtering steps to aid reader assessment of the method. revision: partial
- Full quantitative ablations isolating the test-set contributions of per-language threshold tuning and the GPT-4o-mini synthetic data augmentation, as these experiments were not conducted during the original competition timeline due to resource constraints.
Circularity Check
No circularity: empirical system results on external test set
full rationale
The paper is a shared-task systems description with no mathematical derivation chain, equations, or first-principles claims. All reported outcomes (mean macro-F1 of 0.811, per-language rankings, 2-4% F1 gains from threshold tuning) are direct empirical measurements on the organizer-provided test set after standard dev-set hyperparameter choices. Synthetic data generation, LoRA fine-tuning, embedding deduplication, and per-language threshold selection are procedural steps whose outputs are evaluated externally; none reduces to its own inputs by construction, self-definition, or self-citation. The absence of any fitted parameter presented as an independent prediction or any load-bearing self-citation chain confirms the derivation is self-contained.
Axiom & Free-Parameter Ledger
free parameters (1)
- per-language decision thresholds
axioms (2)
- domain assumption Synthetic data produced by GPT-4o-mini is of high quality and matches the distribution of real polarized text in each of the 22 languages.
- domain assumption Per-language fine-tuning with LoRA captures language-specific polarization signals better than a single multilingual model.
Reference graph
Works this paper leans on
-
[1]
Working Notes of CLEF 2024 -- Conference and Labs of the Evaluation Forum , year =
Mhalgi, Shrirang and Pulipaka, Srikar Kashyap and K\". Working Notes of CLEF 2024 -- Conference and Labs of the Evaluation Forum , year =
work page 2024
-
[2]
Cegin, Jan and Simko, Jakub and Brusilovsky, Peter , booktitle =. 2025 , url =
work page 2025
-
[3]
Yong, Zheng Xin and Menghini, Cristina and Bach, Stephen H. , journal =. 2024 , url =
work page 2024
-
[4]
Improving Neural Machine Translation Models with Monolingual Data , author =. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2016 , address =. doi:10.18653/v1/P16-1009 , url =
-
[5]
Understanding Back-Translation at Scale
Understanding Back-Translation at Scale , author =. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing , pages =. 2018 , address =. doi:10.18653/v1/D18-1045 , url =
-
[6]
Improving Counterfactual Generation for Fair Hate Speech Detection
Improving Counterfactual Generation for Fair Hate Speech Detection , author =. Proceedings of the 5th Workshop on Online Abuse and Harms (WOAH 2021) , pages =. 2021 , address =. doi:10.18653/v1/2021.woah-1.10 , url =
-
[7]
Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Wang, Lu and Chen, Weizhu , booktitle =. 2022 , url =
work page 2022
-
[8]
and Elkan, Charles and Narayanaswamy, Balakrishnan , journal =
Lipton, Zachary C. and Elkan, Charles and Narayanaswamy, Balakrishnan , journal =. Thresholding Classifiers to Maximize. 2014 , url =
work page 2014
-
[9]
Pattern Recognition , volume =
Threshold Optimisation for Multi-label Classifiers , author =. Pattern Recognition , volume =. 2013 , publisher =
work page 2013
-
[10]
Sentence- BERT : Sentence Embeddings using S iamese BERT -Networks
Reimers, Nils and Gurevych, Iryna , booktitle =. Sentence-. 2019 , address =. doi:10.18653/v1/D19-1410 , url =
-
[11]
Dettmers, Tim and Pagnoni, Artidoro and Holtzman, Ari and Zettlemoyer, Luke , booktitle =. 2023 , url =
work page 2023
-
[12]
Gemma: Open Models Based on Gemini Research and Technology , author=. 2024 , eprint=
work page 2024
-
[13]
POLAR: A Benchmark for Multilingual, Multicultural, and Multi-Event Online Polarization , author=. 2026 , eprint=
work page 2026
-
[14]
Proceedings of the 20th International Workshop on Semantic Evaluation (SemEval-2026) , year =
Naseem, Usman and Geislinger, Robert and Ren, Juan and Kohail, Sarah and Garrido Veliz, Rudy and Sam Sahil, P and Zhang, Yiran and Stranisci, Marco Antonio and Abdulmumin, Idris and Alacam,. Proceedings of the 20th International Workshop on Semantic Evaluation (SemEval-2026) , year =
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.