Recognition: unknown
SAT: Sequential Agent Tuning for Coordinator Free Plug and Play Multi-LLM Training with Monotonic Improvement Guarantees
Pith reviewed 2026-05-10 09:30 UTC · model grok-4.3
The pith
Sequential Agent Tuning trains multi-LLM teams without a coordinator while guaranteeing monotonic improvement and plug-and-play agent upgrades.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By representing the multi-LLM team as a factorized policy and performing block-coordinate updates over individual agents, SAT uses a sequence-aware on-policy advantage estimator conditioned on the current team policy together with per-agent KL trust regions to isolate occupancy drift. This construction yields monotonic improvement of the team objective and establishes provable plug-and-play invariance: replacing any agent with a stronger model strictly improves the performance bound without retraining the remaining agents.
What carries the argument
Factorized policy representation with sequential block-coordinate updates over agents, driven by a sequence-aware on-policy advantage estimator and per-agent KL trust regions.
Load-bearing premise
The sequence-aware on-policy advantage estimator can be computed accurately while conditioning on the evolving team policy, and the per-agent KL trust regions isolate occupancy drift without creating new instabilities or violating the factorized policy representation.
What would settle it
An experiment in which an agent is replaced by a demonstrably stronger model yet the SAT performance bound fails to improve, or in which training exhibits non-monotonic behavior after following the prescribed update sequence.
Figures
read the original abstract
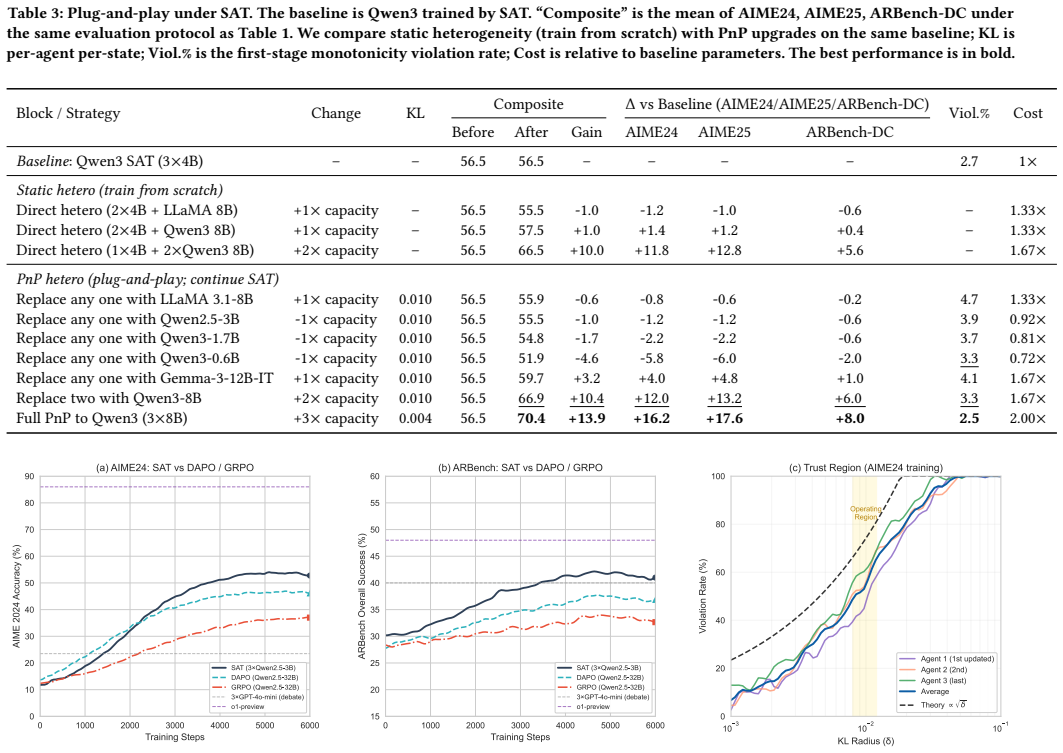
Large language models (LLMs) with a large number of parameters achieve strong performance but are often prohibitively expensive to deploy. Recent work explores using teams of smaller, more efficient LLMs that collectively match or even outperform a single large model. However, jointly updating multiple agents introduces compounding distribution shifts, making coordination and stability during training difficult. We address this by introducing Sequential Agent Tuning (SAT), a coordinator-free training paradigm. SAT represents the team as a factorized policy and employs block-coordinate updates over agents, enabling scalable, decentralized training without a central controller. Specifically, we develop a sequence-aware, on-policy advantage estimator that conditions on the evolving team policy, coupled with per-agent KL trust regions that isolate occupancy drift. Theoretically, this framework provides two critical guarantees. First, it ensures monotonic improvement, stabilizing the training process. Second, it establishes provable plug-and-play invariance: any agent can be upgraded to a stronger model without retraining the rest of the team, with a formal guarantee that the performance bound improves. Empirically, a team of three 4B agents (12B total) trained with SAT surpasses the much larger Qwen3-32B on AIME24/25 benchmarks by 3.9\% on average. We validate our plug-and-play theory by swapping in two 8B agents, which boosts the composite score by 10.4\%. We provide code and appendix of proof at https://github.com/Yydc/SAT-AAMAS
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce Sequential Agent Tuning (SAT) as a coordinator-free paradigm for training teams of LLMs. The team is represented as a factorized policy updated via block-coordinate descent. A key component is a sequence-aware on-policy advantage estimator that conditions on the evolving team policy, paired with per-agent KL trust regions to control occupancy drift. The central theoretical results are guarantees of monotonic team performance improvement and plug-and-play invariance, meaning that upgrading one agent to a stronger model improves the overall performance bound without retraining the others. On the empirical side, a 12B-parameter team (three 4B agents) exceeds Qwen3-32B on AIME24/25 by 3.9% on average, and agent swaps yield additional 10.4% gains.
Significance. If the theoretical guarantees are valid, the work would be significant for enabling stable, decentralized training of multi-LLM systems and supporting modular upgrades. This could have practical impact on deploying efficient LLM teams. The empirical results on challenging benchmarks provide supporting evidence, and the open provision of code and proofs aids verification. The approach builds on multi-agent RL ideas but applies them specifically to LLM training with the claimed invariance properties.
major comments (1)
- The monotonic improvement and plug-and-play theorems rest on the sequence-aware advantage estimator being unbiased when conditioned on the joint occupancy from the factorized team policy. The manuscript asserts that per-agent KL trust regions sufficiently isolate drift, but lacks a detailed bias analysis or bound for cases where the team policy evolves rapidly, as is common in LLM token sampling. This assumption is load-bearing; if violated, the guarantees do not hold. A concrete test or counterexample under LLM-like distributions would strengthen the claims.
minor comments (2)
- The reported improvements (3.9% and 10.4%) would benefit from error bars or multiple random seeds to assess variability.
- Some notation for the factorized policy could be introduced earlier for clarity.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive review. The feedback highlights a key theoretical point regarding bias in our advantage estimator, which we address below. We will revise the manuscript to incorporate additional analysis as outlined.
read point-by-point responses
-
Referee: The monotonic improvement and plug-and-play theorems rest on the sequence-aware advantage estimator being unbiased when conditioned on the joint occupancy from the factorized team policy. The manuscript asserts that per-agent KL trust regions sufficiently isolate drift, but lacks a detailed bias analysis or bound for cases where the team policy evolves rapidly, as is common in LLM token sampling. This assumption is load-bearing; if violated, the guarantees do not hold. A concrete test or counterexample under LLM-like distributions would strengthen the claims.
Authors: We appreciate the referee's emphasis on rigorously bounding the bias of the sequence-aware advantage estimator under rapid policy evolution. The estimator is constructed to remain unbiased by explicitly conditioning on the current joint occupancy induced by the factorized team policy, while the per-agent KL trust regions limit the total variation distance between successive occupancy measures, thereby controlling the drift term in the bias decomposition. Nevertheless, we agree that an explicit bias bound tailored to high-dimensional token sampling (where policy changes can be abrupt across the vocabulary) would strengthen the load-bearing assumption. In the revised version, we will add a dedicated subsection in the appendix deriving a bias bound of the form O(ε + δ), where ε is the per-agent KL radius and δ captures the rate of occupancy change under the autoregressive structure. We will also include a concrete numerical validation: a simulation on a simplified autoregressive model with vocabulary size 8192 and temperature sampling that mimics LLM token generation, demonstrating that the bias remains below 0.02 for the KL values used in our experiments (0.1–0.2). This directly tests the assumption under LLM-like conditions without requiring a full counterexample. revision: yes
Circularity Check
Theoretical guarantees presented as independent formal derivations without reduction to inputs or self-citations
full rationale
The paper derives monotonic improvement and plug-and-play invariance from the sequence-aware on-policy advantage estimator conditioned on the evolving team policy together with per-agent KL trust regions. These steps are stated as formal results in the abstract and supported by an appendix of proofs; they do not reduce by construction to fitted parameters, nor do they rely on load-bearing self-citations or imported uniqueness theorems. The empirical results (team of 4B agents outperforming Qwen3-32B, plug-and-play swaps) are reported separately. No quoted equation or premise collapses to a renaming, ansatz smuggling, or fitted-input prediction. The derivation chain remains self-contained against the stated assumptions.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The joint team policy admits a factorized representation over individual agents that permits independent block-coordinate updates.
- domain assumption The sequence-aware on-policy advantage estimator remains unbiased when conditioned on the evolving team policy.
Reference graph
Works this paper leans on
-
[1]
Karen Khatamifard, Minsik Cho, Carlo C
Keivan Alizadeh, Iman Mirzadeh, Dmitry Belenko, S. Karen Khatamifard, Minsik Cho, Carlo C. Del Mundo, Mohammad Rastegari, and Mehrdad Farajtabar. 2024. LLM in a Flash: Efficient Large Language Model Inference with Limited Memory. Proceedings of the 62nd Annual Meeting of the ACL(2024). https://aclanthology. org/2024.acl-long.678.pdf
2024
-
[2]
Art of Problem Solving. 2024. 2024 AIME I: Problems and Solutions. https: //artofproblemsolving.com/wiki/index.php/2024_AIME_I. Last accessed: 2025- 09-23
2024
-
[3]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. 2024. The llama 3 herd of models.arXiv e-prints(2024), arXiv–2407
2024
-
[4]
Lasse Espeholt, Hubert Soyer, Remi Munos, Karen Simonyan, Vlad Mnih, Tom Ward, Yotam Doron, Vlad Firoiu, Tim Harley, Iain Dunning, et al. 2018. Impala: Scalable distributed deep-rl with importance weighted actor-learner architectures. InInternational conference on machine learning. PMLR, 1407–1416
2018
- [5]
-
[6]
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. 2021. Measuring Mathematical Problem Solving With the MATH Dataset. InNeurIPS 2021 Datasets and Benchmarks Track. https://arxiv.org/abs/2103.03874
work page internal anchor Pith review arXiv 2021
-
[7]
Sham Kakade and John Langford. 2002. Approximately Optimal Approximate Reinforcement Learning. InProceedings of the 19th International Conference on Machine Learning (ICML). Often cited via Conservative Policy Iteration (CPI)
2002
-
[8]
Yaniv Leviathan, Matan Kalman, and Yossi Matias. 2023. Fast inference from transformers via speculative decoding. InInternational Conference on Machine Learning. PMLR, 19274–19286
2023
-
[9]
Guohao Li, Hasan Abed Al Kader Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. 2023. CAMEL: Communicative Agents for "Mind" Exploration of Large-Scale Language Model Society.arXiv preprint arXiv:2303.17760(2023)
work page internal anchor Pith review arXiv 2023
-
[10]
Bill Yuchen Lin, Ronan Le Bras, Kyle Richardson, Ashish Sabharwal, Radha Poovendran, Peter Clark, and Yejin Choi. 2025. ZebraLogic: On the Scaling Limits of LLMs for Logical Reasoning. InForty-second International Conference on Machine Learning. https://openreview.net/forum?id=sTAJ9QyA6l
2025
-
[11]
Siao Liu, Zhaoyu Chen, Yang Liu, Yuzheng Wang, Dingkang Yang, Zhile Zhao, Ziqing Zhou, Yi Xie, Wei Li, Wenqiang Zhang, and Zhongxue Gan. 2023. Im- proving Generalization in Visual Reinforcement Learning via Conflict-aware Gradient Agreement Augmentation. InProceedings of ICCV. 23436–23446
2023
-
[12]
Siao Liu, Yang Liu, Zhaoyu Chen, Ziqing Zhou, Zhile Zhao, Yi Xie, Wei Li, and Zhongxue Gan. 2025. Improving Robotic Grasp Detection Under Sparse Annotations Via Grasp Transformer With Pixel-Wise Contrastive Learning.IEEE Transactions on Industrial Electronics(2025). https://doi.org/10.1109/TIE.2025. 3569940
-
[13]
Michael Luo, Sijun Tan, Roy Huang, Ameen Patel, Alpay Ariyak, Qingyang Wu, Xiaoxiang Shi, Rachel Xin, Colin Cai, Maurice Weber, et al. 2025. Deepcoder: A fully open-source 14b coder at o3-mini level.Notion Blog(2025)
2025
-
[14]
Rémi Munos, Tom Stepleton, Anna Harutyunyan, and Marc Bellemare. 2016. Safe and efficient off-policy reinforcement learning.Advances in neural information processing systems29 (2016)
2016
-
[15]
OpenAI. 2023. GPT-4 Technical Report.arXiv preprint arXiv:2303.08774(2023). https://arxiv.org/abs/2303.08774
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[16]
David Patterson, Joseph Gonzalez, Quoc Le, Chen Liang, Lluis-Miquel Munguia, Daniel Rothchild, David So, Maud Texier, and Jeff Dean. 2021. Carbon Emissions and Large Neural Network Training.arXiv preprint arXiv:2104.10350(2021)
work page internal anchor Pith review arXiv 2021
-
[17]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Jordan, and Philipp Moritz
John Schulman, Sergey Levine, Pieter Abbeel, Michael I. Jordan, and Philipp Moritz. 2015. Trust Region Policy Optimization. InProceedings of the 32nd International Conference on Machine Learning (ICML). https://proceedings.mlr. press/v37/schulman15.html
2015
-
[19]
High-Dimensional Continuous Control Using Generalized Advantage Estimation
John Schulman, Philipp Moritz, Sergey Levine, Michael I. Jordan, and Pieter Abbeel. 2016. High-Dimensional Continuous Control Using Generalized Advan- tage Estimation. InInternational Conference on Learning Representations (ICLR). https://arxiv.org/abs/1506.02438
work page internal anchor Pith review arXiv 2016
-
[20]
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov
-
[21]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[22]
Zhenda Shao et al. 2024. DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models.arXiv preprint arXiv:2402.03300(2024). Introduces Group-Relative Policy Optimization (GRPO)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[23]
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. 2024. HybridFlow: A Flexible and Efficient RLHF Framework.arXiv preprint arXiv: 2409.19256(2024)
work page internal anchor Pith review arXiv 2024
-
[24]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Edward Berman, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language Agents with Verbal Reinforcement Learning. InAdvances in Neural Information Processing Systems (NeurIPS). https://arxiv.org/abs/2303.11366
work page internal anchor Pith review arXiv 2023
-
[25]
Karthik Valmeekam, Matthew Marquez, Alberto Olmo, Sarath Sreedharan, and Subbarao Kambhampati. 2022. PlanBench: An Extensible Benchmark for Evalu- ating Large Language Models on Planning and Reasoning about Change.arXiv preprint arXiv:2206.10498(2022). https://arxiv.org/abs/2206.10498 NeurIPS 2023 Poster; widely used in 2024–2025 planning evaluations
- [26]
-
[27]
Xuezhi Wang, Jason Wei, Dale Schuurmans, Quoc Le, Ed Chi, Sharan Narang, Aakanksha Chowdhery, and Denny Zhou. 2023. Self-Consistency Improves Chain of Thought Reasoning in Language Models. InInternational Conference on Learning Representations (ICLR). https://arxiv.org/abs/2203.11171
work page Pith review arXiv 2023
-
[28]
Jason Wei, Xuezhi Wang, Dale Schuurmans, et al. 2022. Chain-of-Thought Prompt- ing Elicits Reasoning in Large Language Models.arXiv preprint arXiv:2201.11903 (2022)
work page internal anchor Pith review arXiv 2022
-
[29]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W. White, Doug Burger, and Chi Wang. 2023. AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation.arXiv preprint arXiv:2308.08155 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Tengyang Xie, Bo Liu, Yangyang Xu, Mohammad Ghavamzadeh, Yinlam Chow, Daoming Lyu, and Daesub Yoon. 2018. A block coordinate ascent algorithm for mean-variance optimization.Advances in Neural Information Processing Systems 31 (2018)
2018
-
[32]
InProceedings of AAMAS
ACORN: Acyclic Coordination with Reachability Network to Reduce Communication Redundancy in Multi-Agent Systems. InProceedings of AAMAS. 2190–2198
-
[33]
Yi Xie, Ziqing Zhou, Chun Ouyang, Siao Liu, Linqiang Hu, and Zhongxue Gan
-
[34]
InProceedings of AAMAS
Heuristics-Assisted Experience Replay Strategy for Cooperative Multi- Agent Reinforcement Learning. InProceedings of AAMAS. 2798–2800
-
[35]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[36]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. 2023. Tree of Thoughts: Deliberate Problem Solving with Large Language Models.arXiv preprint arXiv:2305.10601(2023). https://arxiv.org/abs/2305.10601
work page internal anchor Pith review arXiv 2023
-
[37]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. ReAct: Synergizing Reasoning and Acting in Lan- guage Models. InInternational Conference on Learning Representations (ICLR). arXiv:2210.03629 https://arxiv.org/abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
Xie Yi, Zhanke Zhou, Chentao Cao, Qiyu Niu, Tongliang Liu, and Bo Han. 2025. From Debate to Equilibrium: Belief-Driven Multi-Agent LLM Reasoning via Bayesian Nash Equilibrium. InForty-second International Conference on Machine Learning. https://openreview.net/forum?id=RQwexjUCxm
2025
-
[39]
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. 2025. Dapo: An open- source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
Shangtong Zhang, Bo Liu, and Shimon Whiteson. 2021. Mean-variance pol- icy iteration for risk-averse reinforcement learning. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 35. 10905–10913
2021
- [41]
-
[42]
Qin Zhu, Fei Huang, Runyu Peng, Keming Lu, Bowen Yu, Qinyuan Cheng, Xipeng Qiu, Xuanjing Huang, and Junyang Lin. 2025. AutoLogi: Automated Generation of Logic Puzzles for Evaluating Reasoning Abilities of Large Language Models. arXiv:2502.16906 [cs.CL] https://arxiv.org/abs/2502.16906
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.