Recognition: unknown
DexSim2Real: Foundation Model-Guided Sim-to-Real Transfer for Generalizable Dexterous Manipulation
Pith reviewed 2026-05-09 17:05 UTC · model grok-4.3
The pith
DexSim2Real uses vision-language models to optimize simulation parameters so dexterous manipulation policies transfer to real robots with an 8 percent performance gap.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
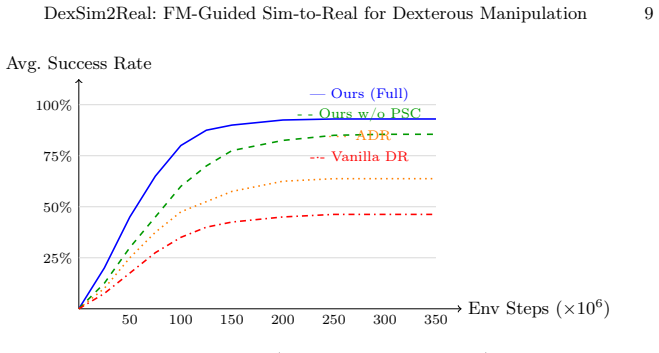
DexSim2Real integrates foundation model-guided domain randomization, where a vision-language model acts as a visual realism critic to optimize simulation parameters through CMA-ES, together with a tactile-visual cross-attention policy and a progressive skill curriculum based on LLM task decomposition. On six challenging manipulation tasks the system reaches 78.2 percent average real-world success while shrinking the sim-to-real performance gap to 8.3 percent and outperforming prior methods that rely on text-only feedback or hand-designed randomization.
What carries the argument
Foundation Model-Guided Domain Randomization (FM-DR), in which a vision-language model evaluates simulated images for visual realism and supplies feedback that CMA-ES uses to adjust simulation parameters.
If this is right
- Dexterous policies trained in simulation can reach high real-world success rates without task-specific manual tuning of randomization ranges.
- Cross-attention fusion of visual and tactile inputs improves policy robustness during contact-rich phases of manipulation.
- Progressive curricula built from LLM task decomposition enable stable learning of long-horizon dexterous sequences.
- The sim-to-real gap shrinks to single-digit percentages when visual feedback from foundation models complements text-based domain randomization.
Where Pith is reading between the lines
- The same visual-critic loop could be tested on locomotion or navigation tasks where image realism also drives parameter search.
- If later vision-language models become more reliable at judging physical plausibility, the remaining 8 percent gap could be narrowed further without changing the overall structure.
- The method still assumes access to a simulator whose adjustable parameters cover the main visual mismatches; tasks with unmodeled dynamics would require additional mechanisms.
Load-bearing premise
The vision-language model must supply unbiased, task-relevant judgments about visual realism that produce simulation parameters whose resulting policies transfer directly to real hardware without extra real-world adaptation.
What would settle it
A new dexterous task in which the real-world success rate after using the optimized simulation parameters drops far below the simulated rate or requires substantial additional real-world training would show the transfer does not generalize as claimed.
Figures

read the original abstract
Sim-to-real transfer remains a critical bottleneck for deploying dexterous manipulation policies learned in simulation to real-world robots. Existing approaches rely on manually designed domain randomization or task-specific adaptation, limiting their generalizability across diverse manipulation scenarios. We present DexSim2Real, an integrated framework that leverages vision-language foundation models to bridge the sim-to-real gap for dexterous manipulation. Our system combines three components: (1) Foundation Model-Guided Domain Randomization (FM-DR), which uses a vision-language model as a visual realism critic to optimize simulation parameters via closed-loop CMA-ES, complementing text-based approaches like DrEureka with direct visual feedback; (2) a Tactile-Visual Cross-Attention Policy (TVCAP) that adapts cross-attention visuo-tactile fusion to zero-shot sim-to-real RL; and (3) a Progressive Skill Curriculum (PSC) that builds on LLM-based task decomposition with a difficulty scheduler tailored to contact-rich dexterous tasks. Extensive experiments on six challenging manipulation tasks with blinded evaluation demonstrate that DexSim2Real achieves a 78.2% average real-world success rate, outperforming DrEureka and DeXtreme while reducing the sim-to-real performance gap to only 8.3%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents DexSim2Real, an integrated framework for sim-to-real transfer in dexterous manipulation. It combines Foundation Model-Guided Domain Randomization (FM-DR) that uses a vision-language model as a visual realism critic to optimize simulation parameters via closed-loop CMA-ES, a Tactile-Visual Cross-Attention Policy (TVCAP) for visuo-tactile fusion in zero-shot RL, and a Progressive Skill Curriculum (PSC) based on LLM task decomposition with a difficulty scheduler. Experiments across six challenging manipulation tasks with blinded evaluation report a 78.2% average real-world success rate, outperforming DrEureka and DeXtreme while reducing the sim-to-real gap to 8.3%.
Significance. If the performance claims hold under rigorous scrutiny, the work offers a promising direction for automating domain randomization in contact-rich dexterous tasks by leveraging foundation models for visual feedback. This could reduce manual engineering effort compared to prior text-based methods and support broader deployment of learned policies. The combination of VLM guidance with tactile-visual policies and curricula addresses a recognized bottleneck in the field.
major comments (2)
- The headline claims of 78.2% real-world success and an 8.3% sim-to-real gap reduction rest on FM-DR producing superior simulation parameters via VLM visual feedback. However, the manuscript provides no validation that the VLM realism scores are unbiased, task-relevant, or correlated with improved policy transfer (e.g., no human rating correlation, no ablation removing the VLM critic, and no analysis of VLM behavior on dynamic contact scenes). This is load-bearing for attributing gains specifically to the foundation-model component rather than TVCAP or PSC.
- The experimental section reports average success rates on six tasks but supplies no error bars, number of evaluation trials per task, or statistical tests for the comparisons against DrEureka and DeXtreme. Without these, the reliability of the outperformance claim and the gap reduction cannot be assessed.
minor comments (2)
- The abstract and early sections introduce several acronyms (FM-DR, TVCAP, PSC) that would benefit from a brief summary table or expanded first-use definitions for readers unfamiliar with the subfield.
- Figure captions and method diagrams could more explicitly label the closed-loop CMA-ES optimization path and the role of the VLM critic to improve readability.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment below with honest clarifications from the manuscript and commit to targeted revisions that strengthen the evidence without overstating current results.
read point-by-point responses
-
Referee: The headline claims of 78.2% real-world success and an 8.3% sim-to-real gap reduction rest on FM-DR producing superior simulation parameters via VLM visual feedback. However, the manuscript provides no validation that the VLM realism scores are unbiased, task-relevant, or correlated with improved policy transfer (e.g., no human rating correlation, no ablation removing the VLM critic, and no analysis of VLM behavior on dynamic contact scenes). This is load-bearing for attributing gains specifically to the foundation-model component rather than TVCAP or PSC.
Authors: We agree that direct validation of the VLM critic's properties is needed to firmly attribute gains to FM-DR rather than the other components. The manuscript reports end-to-end outperformance over DrEureka (text-based) and DeXtreme but does not contain an ablation isolating the VLM critic, human correlation data, or targeted analysis of VLM scoring on dynamic contacts. In revision we will add: (i) an ablation replacing the VLM critic with random or text-only parameter selection, (ii) quantitative analysis of VLM score distributions and failure modes on contact-rich scenes, and (iii) a small-scale human rating correlation study on a subset of rendered images. These additions will be presented in a new subsection and updated tables. revision: yes
-
Referee: The experimental section reports average success rates on six tasks but supplies no error bars, number of evaluation trials per task, or statistical tests for the comparisons against DrEureka and DeXtreme. Without these, the reliability of the outperformance claim and the gap reduction cannot be assessed.
Authors: We acknowledge that the absence of variability measures and statistical tests limits assessment of result reliability. The reported 78.2% average and 8.3% gap are based on multiple real-world rollouts per task, yet trial counts, standard deviations, and significance tests were omitted. In the revised manuscript we will: (i) state the exact number of evaluation trials per task (minimum 10), (ii) add error bars to all success-rate figures and tables, and (iii) include paired t-tests or Wilcoxon tests with p-values for all baseline comparisons. These changes will appear in the experimental results section and supplementary material. revision: yes
Circularity Check
No circularity: empirical system evaluated via direct experiments
full rationale
The paper introduces an integrated framework (FM-DR using VLM critic + CMA-ES, TVCAP policy, PSC curriculum) and reports measured real-world success rates (78.2% average, 8.3% gap) from blinded experiments on six tasks. No equations, derivations, or parameter-fitting steps are described that reduce by construction to the inputs or prior self-citations. The central claims rest on external experimental outcomes rather than self-referential definitions or renamed fits. Any self-citations (if present in full text) are not load-bearing for the reported metrics, which are falsifiable via replication on hardware.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Black, K., Brown, N., Driess, D., Esmail, A., Equi, M., Finn, C., Fusai, N., Groom, L., Hausman, K., Ichter, B., et al.:π0: A vision-language-action flow model for general robot control. arXiv preprint arXiv:2410.24164 (2024)
work page internal anchor Pith review arXiv 2024
-
[2]
In: Conference on Robot Learning (CoRL)
Brohan, A., Brown, N., Carbajal, J., Chebotar, Y., Chen, X., Choromanski, K., et al.: RT-2: Vision-language-action models transfer web knowledge to robotic con- trol. In: Conference on Robot Learning (CoRL). pp. 2165–2183 (2023)
2023
-
[3]
In: Conference on Robot Learning (CoRL)
Chen, Y., Van der Merwe, M., Sipos, A., Fazeli, N.: Visuo-tactile transformers for manipulation. In: Conference on Robot Learning (CoRL). pp. 2026–2040 (2023)
2026
-
[4]
In: Robotics: Science and Systems (RSS) (2023)
Chi, C., Xu, Z., Feng, S., Cousineau, E., Du, Y., Burchfiel, B., Tedrake, R., Song, S.: Diffusion policy: Visuomotor policy learning via action diffusion. In: Robotics: Science and Systems (RSS) (2023)
2023
-
[5]
In: International Conference on Learning Representations (ICLR) (2024) 12 Z
Dalal, M., Chiruvolu, T., Chaplot, D.S., Salakhutdinov, R.: Plan-seq-learn: Lan- guage model guided RL for solving long horizon robotics tasks. In: International Conference on Learning Representations (ICLR) (2024) 12 Z. Zeng et al
2024
-
[6]
In: Advances in Neural Information Pro- cessing Systems (NeurIPS)
Dalal, M., Pathak, D., Salakhutdinov, R.: Accelerating robotic reinforcement learn- ing via parameterized action primitives. In: Advances in Neural Information Pro- cessing Systems (NeurIPS). vol. 34, pp. 21789–21803 (2021)
2021
-
[7]
In: Conference on Robot Learn- ing (CoRL)
Gervet, T., Xian, Z., Gkanatsios, N., Fragkiadaki, K.: Act3D: 3D feature field transformers for multi-task robotic manipulation. In: Conference on Robot Learn- ing (CoRL). pp. 3949–3965 (2023)
2023
-
[8]
Goyal, A., Xu, J., Guo, Y., Blukis, V., Chao, Y.W., Fox, D.: RVT: Robotic view transformerfor3dobjectmanipulation.In:ConferenceonRobotLearning(CoRL). pp. 694–710 (2023)
2023
-
[9]
In: IEEE Inter- national Conference on Robotics and Automation (ICRA)
Handa, A., Allshire, A., Makoviychuk, V., Petrenko, A., Singh, R., Liu, J., Makovi- ichuk, D., Van Wyk, K., Zhurkevich, A., Sundaralingam, B., et al.: DeXtreme: Transfer of agile in-hand manipulation from simulation to reality. In: IEEE Inter- national Conference on Robotics and Automation (ICRA). pp. 5977–5984 (2023)
2023
-
[10]
In: Conference on Robot Learning (CoRL) (2024)
Huang, B., Wang, Y., Yang, X., Luo, Y., Li, Y.: 3D-ViTac: Learning fine-grained manipulation with visuo-tactile sensing. In: Conference on Robot Learning (CoRL) (2024)
2024
-
[11]
In: Conference on Robot Learning (CoRL) Workshop on Dexterous Manipulation (2025)
Liang,H.,Geng,H.,Zhang,K.,Abbeel,P.,Malik,J.:ViTacFormer:Learningcross- modal representation for visuo-tactile dexterous manipulation. In: Conference on Robot Learning (CoRL) Workshop on Dexterous Manipulation (2025)
2025
-
[12]
Lin, T., Zhang, Y., Li, Q., Qi, H., Yi, B., Levine, S., Malik, J.: Learning visuotactile skills with two multifingered hands (2024)
2024
-
[13]
Ma, Y.J., Liang, W., Wang, G., Huang, D.A., Bastani, O., Jayaraman, D., Zhu, Y., Fan, L., Anandkumar, A.: Eureka: Human-level reward design via coding large languagemodels.In:InternationalConferenceonLearningRepresentations(ICLR) (2024)
2024
-
[14]
In: Robotics: Science and Systems (RSS) (2024)
Ma, Y.J., Liang, W., Wang, H.J., Wang, S., Zhu, Y., Fan, L., Bastani, O., Ja- yaraman, D.: DrEureka: Language model guided sim-to-real transfer. In: Robotics: Science and Systems (RSS) (2024)
2024
-
[15]
A Survey on Vision-Language-Action Models for Embodied AI
Ma, Y., Song, Z., Zhuang, Y., Hao, J., King, I.: A survey on vision-language-action models for embodied AI. arXiv preprint arXiv:2405.14093 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
In: Advances in Neural Information Processing Systems (NeurIPS) (2021)
Makoviychuk, V., Wawrzyniak, L., Guo, Y., Lu, M., Storey, K., Macklin, M., Hoeller, D., Rudin, N., Allshire, A., Handa, A., State, G.: Isaac gym: High perfor- mance GPU-based physics simulation for robot learning. In: Advances in Neural Information Processing Systems (NeurIPS) (2021)
2021
-
[17]
In: Conference on Robot Learning (CoRL)
Mehta,B.,Diaz,M.,Golemo,F.,Pal,C.J.,Paull,L.:Activedomainrandomization. In: Conference on Robot Learning (CoRL). pp. 1162–1176 (2020)
2020
-
[18]
The International Journal of Robotics Research39(1), 3–20 (2020)
OpenAI, Andrychowicz, M., Baker, B., Chociej, M., Jozefowicz, R., McGrew, B., Pachocki, J., Petron, A., Plappert, M., Powell, G., Ray, A., Schneider, J., Sidor, S., Tobin, J., Welinder, P., Weng, L., Zaremba, W.: Learning dexterous in-hand manipulation. The International Journal of Robotics Research39(1), 3–20 (2020)
2020
-
[19]
In: IEEE International Conference on Robotics and Automation (ICRA)
Peng, X.B., Andrychowicz, M., Zaremba, W., Abbeel, P.: Sim-to-real transfer of robotic control with dynamics randomization. In: IEEE International Conference on Robotics and Automation (ICRA). pp. 3803–3810 (2018)
2018
-
[20]
Qin, Y., Huang, B., Yin, Z.H., Su, H., Wang, X.: DexPoint: Generalizable point cloudreinforcementlearningforsim-to-realdexterousmanipulation.In:Conference on Robot Learning (CoRL) (2023)
2023
-
[21]
In: International Conference on Machine Learning (ICML)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International Conference on Machine Learning (ICML). pp. 8748–8763 (2021) DexSim2Real: FM-Guided Sim-to-Real for Dexterous Manipulation 13
2021
-
[22]
In: IEEE International Conference on Robotics and Automation (ICRA) (2025)
Ryu, K., Liao, Q., Li, Z., Delgosha, P., Sreenath, K., Mehr, N.: CurricuLLM: Au- tomatic task curricula design for learning complex robot skills using large language models. In: IEEE International Conference on Robotics and Automation (ICRA) (2025)
2025
-
[23]
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., Klimov, O.: Proximal policy optimization algorithms (2017)
2017
-
[24]
In: Conference on Robot Learning (CoRL)
Shridhar, M., Manuelli, L., Fox, D.: Perceiver-actor: A multi-task transformer for robotic manipulation. In: Conference on Robot Learning (CoRL). pp. 785–799 (2023)
2023
-
[25]
In: IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Tobin, J., Fong, R., Ray, A., Schneider, J., Zaremba, W., Abbeel, P.: Domain randomization for transferring deep neural networks from simulation to the real world. In: IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 23–30 (2017)
2017
-
[26]
In: Advances in Neural Information Processing Systems (NeurIPS)
Vaswani,A.,Shazeer,N.,Parmar,N.,Uszkoreit,J.,Jones,L.,Gomez,A.N.,Kaiser, Ł., Polosukhin, I.: Attention is all you need. In: Advances in Neural Information Processing Systems (NeurIPS). vol. 30 (2017)
2017
-
[27]
In: Robotics: Science and Systems (RSS) (2024)
Wang, C., Shi, H., Wang, W., Zhang, R., Fei-Fei, L., Liu, C.K.: DexCap: Scal- able and portable mocap data collection system for dexterous manipulation. In: Robotics: Science and Systems (RSS) (2024)
2024
-
[28]
In: International Conference on Learning Representations (ICLR) (2024)
Wang, L., Ling, Y., Yuan, Z., Shridhar, M., Bao, C., Qin, Y., Wang, B., Xu, H., Wang, X.: GenSim: Generating robotic simulation tasks via large language models. In: International Conference on Learning Representations (ICLR) (2024)
2024
-
[29]
In: Conference on Robot Learning (CoRL)
Wu, P., Escontrela, A., Hafner, D., Abbeel, P., Goldberg, K.: DayDreamer: World models for physical robot learning. In: Conference on Robot Learning (CoRL). pp. 2226–2240 (2023)
2023
-
[30]
In: Robotics: Science and Systems (RSS) (2024)
Ze, Y., Zhang, G., Zhang, K., Hu, C., Wang, M., Xu, H.: 3D diffusion policy: Gen- eralizable visuomotor policy learning via simple 3D representations. In: Robotics: Science and Systems (RSS) (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.