Recognition: unknown
Understanding Annotator Safety Policy with Interpretability
Pith reviewed 2026-05-08 17:37 UTC · model grok-4.3
The pith
Annotator Policy Models recover individual safety rules from labeling data alone without extra questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Annotator Policy Models (APMs) are introduced as interpretable models that learn annotators’ internal safety policies from labeling behavior alone. These models accurately capture annotator safety policy with over 80 percent accuracy, faithfully predict responses to counterfactual edits, and recover known policy differences in controlled settings. When applied to real annotations from humans and LLMs, APMs surface how annotators interpret safety instructions differently and uncover systematic differences in safety priorities across demographic groups, supporting more targeted and inclusive policy design.
What carries the argument
Annotator Policy Models (APMs), interpretable models trained solely on an annotator’s labeling decisions to represent their internal safety decision rules.
Load-bearing premise
Labeling behavior alone is enough to recover an annotator’s true internal policy rather than merely fitting patterns in the observed labels.
What would settle it
A controlled experiment in which APMs trained on initial labels fail to match the same annotators’ choices on new examples that require a specific policy distinction or fail to detect deliberately introduced policy differences between groups.
Figures








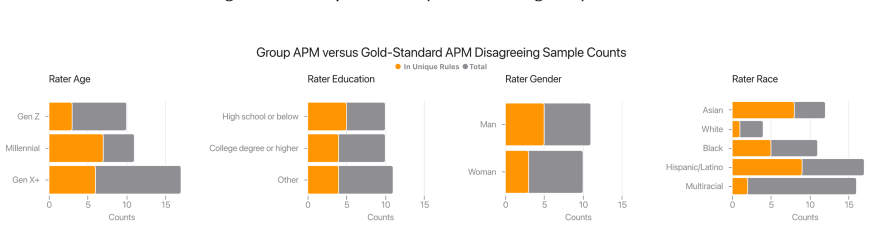
read the original abstract
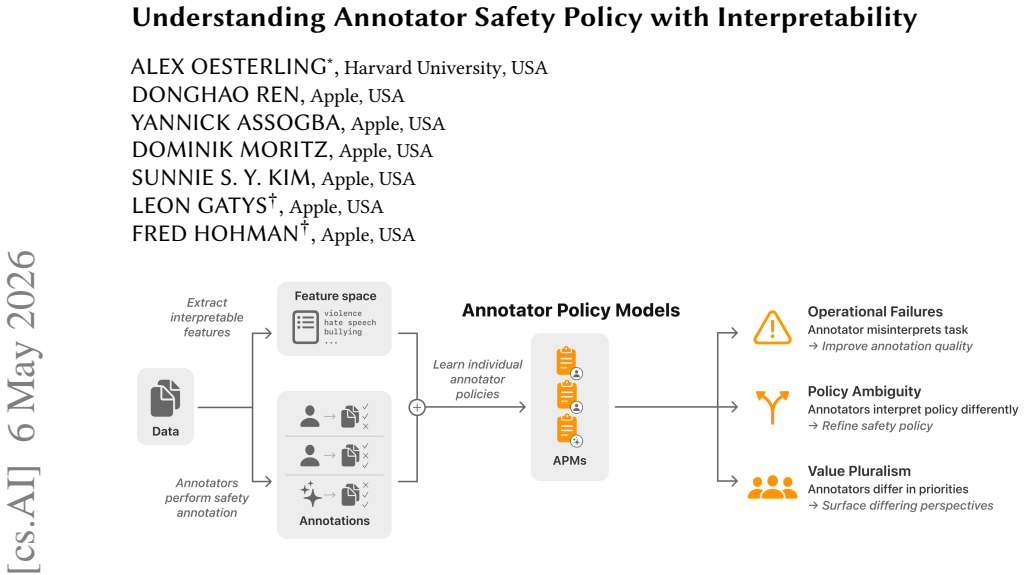
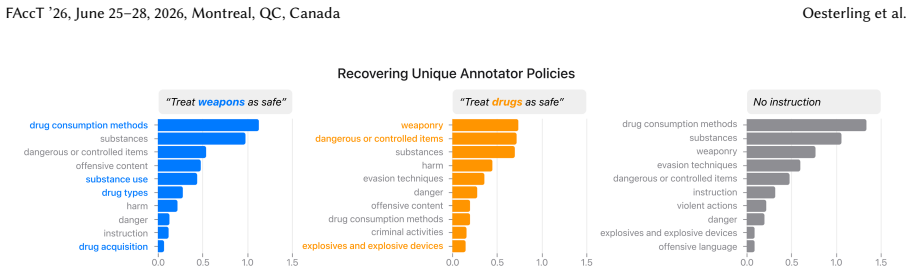
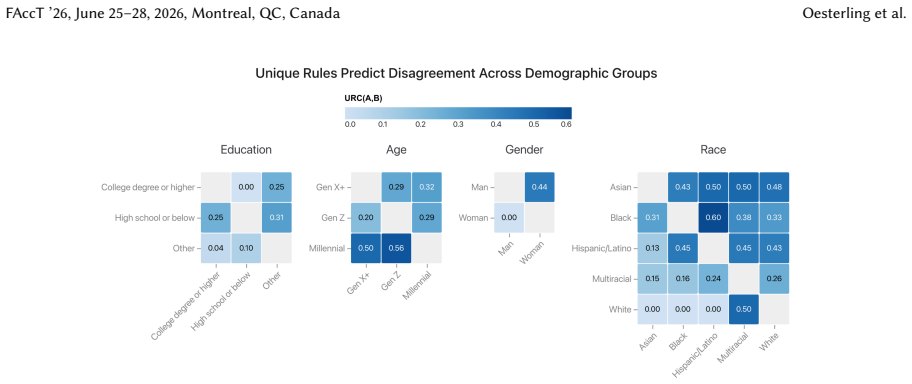
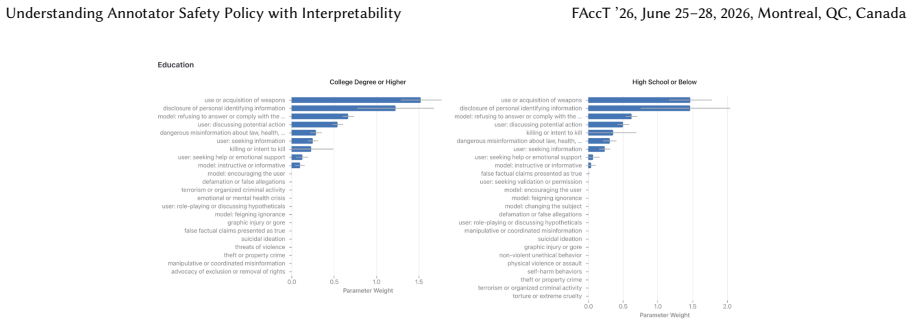
Safety policies define what constitutes safe and unsafe AI outputs, guiding data annotation and model development. However, annotation disagreement is pervasive and can stem from multiple sources such as operational failures (annotators misunderstand or misexecute the task), policy ambiguity (policy wording leaves room for interpretation), or value pluralism (different annotators hold different perspectives on safety). Distinguishing these sources matters. For example, operational failures call for quality control, ambiguity calls for policy clarification, and pluralism calls for deliberation about incorporating diverse perspectives. Yet understanding why annotators disagree is difficult. Directly asking annotators for their reasoning is costly, substantially increasing annotation burden, and can be unreliable for both human and LLM annotators as self-reported reasoning often fails to reflect actual decision processes. We introduce Annotator Policy Models (APMs), interpretable models that learn annotators' internal safety policies from labeling behavior alone, making annotator reasoning visible and comparable without additional annotation effort. We validate that APMs accurately model annotator safety policy (>80% accuracy), faithfully predict responses to counterfactual edits, and recover known policy differences in controlled settings. Applying APMs to LLM and human annotations, we demonstrate two core applications: (1) surfacing policy ambiguity by revealing how annotators interpret safety instructions differently, and (2) surfacing value pluralism by uncovering systematic differences in safety priorities across demographic groups. Together, these capabilities support more targeted, transparent, and inclusive safety policy design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Annotator Policy Models (APMs), interpretable models that infer annotators' internal safety policies directly from labeling behavior without extra annotations. It claims APMs achieve >80% accuracy in modeling policies, faithfully predict responses to counterfactual edits, and recover known policy differences in controlled settings. Applications include surfacing policy ambiguity (differing interpretations of instructions) and value pluralism (systematic differences across demographic groups) for both human and LLM annotators, to better distinguish operational failures, ambiguity, and pluralism in safety annotation.
Significance. If the empirical validations hold under scrutiny, this provides a practical, low-burden method to make annotator reasoning visible and comparable, supporting more targeted safety policy design. Strengths include the use of controlled simulations with known ground-truth policies and the focus on interpretability to avoid reliance on self-reported reasoning.
major comments (1)
- [Abstract and §4] Abstract and §4 (Experiments): The central validation claims (>80% accuracy, counterfactual faithfulness, recovery of known differences) are presented without reported baselines, data splits, statistical tests, or the precise metric and procedure used to assess counterfactual faithfulness. These details are load-bearing for evaluating whether APMs recover internal policies rather than surface label patterns.
minor comments (2)
- [§3] §3 (Method): Clarify the exact form of the interpretable models (e.g., decision trees, linear probes, or other) and how policy parameters are extracted and compared across annotators.
- [Figure captions and §5] Figure captions and §5 (Applications): Ensure all figures include error bars or confidence intervals when reporting accuracy or difference recovery, and explicitly state the number of annotators and items in each experiment.
Simulated Author's Rebuttal
We thank the referee for the constructive review and recommendation for minor revision. We address the single major comment below and will revise the manuscript accordingly to strengthen the empirical presentation.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): The central validation claims (>80% accuracy, counterfactual faithfulness, recovery of known differences) are presented without reported baselines, data splits, statistical tests, or the precise metric and procedure used to assess counterfactual faithfulness. These details are load-bearing for evaluating whether APMs recover internal policies rather than surface label patterns.
Authors: We agree these details are necessary for rigorous assessment. In the revised manuscript we will add: (1) explicit baselines (majority-class predictor, logistic regression on surface features, and a non-interpretable neural model) with accuracy comparisons; (2) data-split procedures (per-annotator 5-fold cross-validation with held-out counterfactual test sets); (3) statistical tests (McNemar’s test for accuracy differences and bootstrap confidence intervals); and (4) the precise counterfactual faithfulness metric (exact-match accuracy of APM predictions on synthetically edited inputs against the annotator’s actual labels on those edits). These additions will clarify that performance exceeds surface-pattern baselines and that controlled simulations recover known policy differences, supporting the claim that APMs capture internal policy structure. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper introduces Annotator Policy Models (APMs) as interpretable models fitted directly to observed labeling behavior, then validates them via accuracy on held-out data (>80%), counterfactual edit predictions, and recovery of known policy differences in controlled simulations where ground-truth policies are available. No equations, derivations, or first-principles results are shown that reduce by construction to the fitted inputs or to self-citations. The central claims rest on standard empirical model fitting plus external validation benchmarks rather than any self-definitional loop, fitted-input-as-prediction, or load-bearing self-citation chain. The derivation is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
International conference on machine learning , pages=
Concept bottleneck models , author=. International conference on machine learning , pages=. 2020 , organization=
2020
-
[2]
Label-free concept bottleneck models.arXiv preprint arXiv:2304.06129, 2023
Label-free concept bottleneck models , author=. arXiv preprint arXiv:2304.06129 , year=
-
[3]
Aegis: Online adaptive ai content safety moderation with ensemble of llm experts, 2024 , author=
2024
-
[4]
International conference on machine learning , pages=
From softmax to sparsemax: A sparse model of attention and multi-label classification , author=. International conference on machine learning , pages=. 2016 , organization=
2016
-
[5]
Advances in neural information processing systems , volume=
Boolean decision rules via column generation , author=. Advances in neural information processing systems , volume=
-
[6]
International ai safety report
International ai safety report , author=. arXiv preprint arXiv:2501.17805 , year=
-
[7]
arXiv preprint arXiv:2305.06626 , year=
When the majority is wrong: Modeling annotator disagreement for subjective tasks , author=. arXiv preprint arXiv:2305.06626 , year=
-
[8]
Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
You are what you annotate: Towards better models through annotator representations , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , pages=
2023
-
[9]
arXiv preprint arXiv:2509.01186 , year=
Statutory Construction and Interpretation for Artificial Intelligence , author=. arXiv preprint arXiv:2509.01186 , year=
-
[10]
Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency , pages=
AI Alignment at Your Discretion , author=. Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency , pages=
2025
-
[11]
Advances in Neural Information Processing Systems , volume=
Beavertails: Towards improved safety alignment of llm via a human-preference dataset , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
2024 , eprint=
WildGuard: Open One-Stop Moderation Tools for Safety Risks, Jailbreaks, and Refusals of LLMs , author=. 2024 , eprint=
2024
-
[13]
Advances in Neural Information Processing Systems , volume=
Causal abstractions of neural networks , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
Ohio , booktitle=
Jacobellis v. Ohio , booktitle=. 1964 , publisher=
1964
-
[15]
Ginette Vincendeau , title =
-
[16]
Yale LJ , volume=
On I know it when I see it , author=. Yale LJ , volume=. 1995 , publisher=
1995
-
[17]
Constitutional AI: Harmlessness from AI Feedback
Constitutional ai: Harmlessness from ai feedback , author=. arXiv preprint arXiv:2212.08073 , year=
work page internal anchor Pith review arXiv
-
[18]
Advances in Neural Information Processing Systems , volume=
Dices dataset: Diversity in conversational ai evaluation for safety , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
, author=
Telling more than we can know: Verbal reports on mental processes. , author=. Psychological review , volume=. 1977 , publisher=
1977
-
[20]
Advances in neural information processing systems , volume=
Training language models to follow instructions with human feedback , author=. Advances in neural information processing systems , volume=
-
[21]
Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency , pages=
Collective constitutional ai: Aligning a language model with public input , author=. Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency , pages=
2024
-
[22]
On the hardness of faithful chain-of-thought reasoning in large language models , author=. arXiv preprint arXiv:2406.10625 , year=
-
[23]
Measuring Faithfulness in Chain-of-Thought Reasoning
Measuring faithfulness in chain-of-thought reasoning , author=. arXiv preprint arXiv:2307.13702 , year=
-
[24]
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
Training a helpful and harmless assistant with reinforcement learning from human feedback , author=. arXiv preprint arXiv:2204.05862 , year=
work page internal anchor Pith review arXiv
-
[25]
Concrete Problems in AI Safety
Concrete problems in AI safety , author=. arXiv preprint arXiv:1606.06565 , year=
work page internal anchor Pith review arXiv
-
[26]
A General Language Assistant as a Laboratory for Alignment
A general language assistant as a laboratory for alignment , author=. arXiv preprint arXiv:2112.00861 , year=
work page internal anchor Pith review arXiv
-
[27]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Llama guard: Llm-based input-output safeguard for human-ai conversations , author=. arXiv preprint arXiv:2312.06674 , year=
work page internal anchor Pith review arXiv
-
[28]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
Persona: A reproducible testbed for pluralistic alignment , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[29]
Neha Srikanth, Jordan Boyd-Graber, and Rachel Rudinger
A roadmap to pluralistic alignment , author=. arXiv preprint arXiv:2402.05070 , year=
-
[30]
Available at SSRN 5319936 , year=
Can Large Language Models Capture Human Annotator Disagreements? , author=. Available at SSRN 5319936 , year=
-
[31]
arXiv preprint arXiv:2408.14141 , year=
Crowd-Calibrator: Can Annotator Disagreement Inform Calibration in Subjective Tasks? , author=. arXiv preprint arXiv:2408.14141 , year=
-
[32]
arXiv preprint arXiv:2502.08266 , year=
Dealing with annotator disagreement in hate speech classification , author=. arXiv preprint arXiv:2502.08266 , year=
-
[33]
arXiv preprint arXiv:2409.17577 , year=
Leveraging annotator disagreement for text classification , author=. arXiv preprint arXiv:2409.17577 , year=
-
[34]
arXiv preprint arXiv:2109.13563 , year=
Agreeing to disagree: Annotating offensive language datasets with annotators' disagreement , author=. arXiv preprint arXiv:2109.13563 , year=
-
[35]
Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , year=
Beyond black & white: Leveraging annotator disagreement via soft-label multi-task learning , author=. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , year=
2021
-
[36]
arXiv preprint arXiv:2502.06207 , year=
Is LLM an Overconfident Judge? Unveiling the Capabilities of LLMs in Detecting Offensive Language with Annotation Disagreement , author=. arXiv preprint arXiv:2502.06207 , year=
-
[37]
arXiv preprint arXiv:2410.14632 , year=
Diverging Preferences: When do Annotators Disagree and do Models Know? , author=. arXiv preprint arXiv:2410.14632 , year=
-
[38]
Machine learning , volume=
Induction of decision trees , author=. Machine learning , volume=. 1986 , publisher=
1986
-
[39]
2017 , publisher=
Classification and regression trees , author=. 2017 , publisher=
2017
-
[40]
Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining , pages=
Interpretable decision sets: A joint framework for description and prediction , author=. Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining , pages=
-
[41]
arXiv preprint arXiv:2412.07992 , year=
Concept bottleneck large language models , author=. arXiv preprint arXiv:2412.07992 , year=
-
[42]
The Twelfth International Conference on Learning Representations , year=
DSPy: Compiling Declarative Language Model Calls into Self-Improving Pipelines , author=. The Twelfth International Conference on Learning Representations , year=
-
[43]
What's In My Human Feedback? Learning Interpretable Descriptions of Preference Data
What's In My Human Feedback? Learning Interpretable Descriptions of Preference Data , author=. arXiv preprint arXiv:2510.26202 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
Proceedings of the 2022 conference of the North American chapter of the association for computational linguistics: human language technologies , pages=
Two contrasting data annotation paradigms for subjective NLP tasks , author=. Proceedings of the 2022 conference of the North American chapter of the association for computational linguistics: human language technologies , pages=
2022
-
[45]
Proceedings of the NAACL student research workshop , pages=
Hateful symbols or hateful people? predictive features for hate speech detection on twitter , author=. Proceedings of the NAACL student research workshop , pages=
-
[46]
doi: 10.18653/v1/2022.naacl-main.431
Sap, Maarten and Swayamdipta, Swabha and Vianna, Laura and Zhou, Xuhui and Choi, Yejin and Smith, Noah A. Annotators with Attitudes: How Annotator Beliefs And Identities Bias Toxic Language Detection. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2022. doi:10...
-
[47]
Identifying and Measuring Annotator Bias Based on Annotators ' Demographic Characteristics
Al Kuwatly, Hala and Wich, Maximilian and Groh, Georg. Identifying and Measuring Annotator Bias Based on Annotators' Demographic Characteristics. Proceedings of the Fourth Workshop on Online Abuse and Harms. 2020. doi:10.18653/v1/2020.alw-1.21
-
[48]
Claude’s Constitution , howpublished =
-
[49]
OpenAI Model Spec , howpublished =
-
[50]
2012 , publisher=
The concept of law , author=. 2012 , publisher=
2012
-
[51]
2023 , journal=
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning , author=. 2023 , journal=
2023
-
[52]
Forty-first International Conference on Machine Learning , year=
Chatbot arena: An open platform for evaluating llms by human preference , author=. Forty-first International Conference on Machine Learning , year=
-
[53]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review arXiv
-
[54]
Gpt-4 technical report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review arXiv
-
[55]
Semeval-2023 task 11: Learning with disagreements (lewidi),
Leonardelli, Elisa and Abercrombie, Gavin and Almanea, Dina and Basile, Valerio and Fornaciari, Tommaso and Plank, Barbara and Rieser, Verena and Uma, Alexandra and Poesio, Massimo. S em E val-2023 Task 11: Learning with Disagreements ( L e W i D i). Proceedings of the 17th International Workshop on Semantic Evaluation (SemEval-2023). 2023. doi:10.18653/v...
-
[56]
Journal of Artificial Intelligence Research , volume=
Learning from disagreement: A survey , author=. Journal of Artificial Intelligence Research , volume=
-
[57]
The'Problem'of Human Label Variation: On Ground Truth in Data, Modeling and Evaluation , author=. arXiv preprint arXiv:2211.02570 , year=
-
[58]
, author=
Corpus annotation through crowdsourcing: Towards best practice guidelines. , author=. LREC , pages=
-
[59]
Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
Learning whom to trust with MACE , author=. Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
2013
-
[60]
Scientific reports , volume=
Comparing large Language models and human annotators in latent content analysis of sentiment, political leaning, emotional intensity and sarcasm , author=. Scientific reports , volume=. 2025 , publisher=
2025
-
[61]
arXiv preprint arXiv:2410.17032 , year=
Insights on disagreement patterns in multimodal safety perception across diverse rater groups , author=. arXiv preprint arXiv:2410.17032 , year=
-
[62]
Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
The risk of racial bias in hate speech detection , author=. Proceedings of the 57th annual meeting of the association for computational linguistics , pages=
-
[63]
Proceedings of the 2019 conference on human information interaction and retrieval , pages=
Online hate ratings vary by extremes: A statistical analysis , author=. Proceedings of the 2019 conference on human information interaction and retrieval , pages=
2019
-
[64]
arXiv preprint arXiv:2110.14839 , year=
Hate speech classifiers learn human-like social stereotypes , author=. arXiv preprint arXiv:2110.14839 , year=
-
[65]
Challenges and Strategies in Cross-Cultural
Hershcovich, Daniel and Frank, Stella and Lent, Heather and de Lhoneux, Miryam and Abdou, Mostafa and Brandl, Stephanie and Bugliarello, Emanuele and Cabello Piqueras, Laura and Chalkidis, Ilias and Cui, Ruixiang and Fierro, Constanza and Margatina, Katerina and Rust, Phillip and S gaard, Anders. Challenges and Strategies in Cross-Cultural NLP. Proceeding...
-
[66]
Reconsidering Annotator Disagreement about Racist Language: Noise or Signal?
Larimore, Savannah and Kennedy, Ian and Haskett, Breon and Arseniev-Koehler, Alina. Reconsidering Annotator Disagreement about Racist Language: Noise or Signal?. Proceedings of the Ninth International Workshop on Natural Language Processing for Social Media. 2021. doi:10.18653/v1/2021.socialnlp-1.7
-
[67]
International Migration , volume=
Value differences between refugees and German citizens: insights from a representative survey , author=. International Migration , volume=. 2021 , publisher=
2021
-
[68]
PsyArXiv
The gab hate corpus: A collection of 27k posts annotated for hate speech , author=. PsyArXiv. July , volume=
-
[69]
Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
Linguistically debatable or just plain wrong? , author=. Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
-
[70]
PloS one , volume=
Understanding international perceptions of the severity of harmful content online , author=. PloS one , volume=. 2021 , publisher=
2021
-
[71]
arXiv preprint arXiv:2109.09483 , year=
ConvAbuse: Data, analysis, and benchmarks for nuanced abuse detection in conversational AI , author=. arXiv preprint arXiv:2109.09483 , year=
-
[72]
Scientific Reports , volume=
STELA: a community-centred approach to norm elicitation for AI alignment , author=. Scientific Reports , volume=. 2024 , publisher=
2024
-
[73]
Kirk, Hannah Rose and Whitefield, Alexander and Röttger, Paul and Bean, Andrew and Margatina, Katerina and Ciro, Juan and Mosquera, Rafael and Bartolo, Max and Williams, Adina and He, He and Vidgen, Bertie and Hale, Scott A. , title =. 2024 , url =. doi:10.57967/hf/2113 , publisher =
-
[74]
Building guardrails for large lan- guage models.arXiv preprint arXiv:2402.01822, 2024
Building guardrails for large language models , author=. arXiv preprint arXiv:2402.01822 , year=
-
[75]
arXiv preprint arXiv:2406.06369 , year=
Annotation alignment: Comparing LLM and human annotations of conversational safety , author=. arXiv preprint arXiv:2406.06369 , year=
-
[76]
Advances in Neural Information Processing Systems , volume=
Interpreting clip with sparse linear concept embeddings (splice) , author=. Advances in Neural Information Processing Systems , volume=
-
[77]
Kim, Sunnie S. Y. and Watkins, Elizabeth Anne and Russakovsky, Olga and Fong, Ruth and Monroy-Hern\'. "Help Me Help the AI": Understanding How Explainability Can Support Human-AI Interaction , year =. doi:10.1145/3544548.3581001 , booktitle =
-
[78]
and Kim, Sunnie S
Ramaswamy, Vikram V. and Kim, Sunnie S. Y. and Fong, Ruth and Russakovsky, Olga , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2023 , pages =
2023
-
[79]
Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems , pages=
Jury learning: Integrating dissenting voices into machine learning models , author=. Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems , pages=
2022
-
[80]
Proceedings of the 2021 chi conference on human factors in computing systems , pages=
The disagreement deconvolution: Bringing machine learning performance metrics in line with reality , author=. Proceedings of the 2021 chi conference on human factors in computing systems , pages=
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.