Recognition: unknown
Architecture Shape Governs QNN Trainability: Jacobian Null Space Growth and Parameter Efficiency
Pith reviewed 2026-05-08 11:35 UTC · model grok-4.3
The pith
The shape of variational quantum circuit architectures controls their trainability through the rank of the coefficient Jacobian.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
For architectures with fixed encoding budget E = N L, serial single-qubit stacks have rank(J) ≤ 2L + 1 independent of P, so dim(ker J) ≥ P - (2L + 1) grows unbounded, termed structural gradient starvation. Parallel architectures ensure σ_min(J^(par)) > 0 generically for P ≤ 2E + 1, leaving no parameter in the kernel. Adding feature map layers strengthens the Jacobian spectrum and reaches high R² fits with 1.6 to 2.2 times fewer parameters than adding trainable blocks.
What carries the argument
The coefficient-matching Jacobian J, the derivative of the Fourier coefficients with respect to the circuit parameters; its null space determines which parameters can affect the loss.
If this is right
- Adding feature map layers monotonically improves the Jacobian eigenvalue spectrum and achieves target accuracy with fewer total parameters.
- Serial architectures suffer structural gradient starvation where increasing P at fixed L decouples more parameters from the loss.
- Parallel architectures maintain generic full rank of the Jacobian up to the maximum useful parameter count.
- Trainable blocks provide only classical interpolation benefits without quantum-specific gains.
Where Pith is reading between the lines
- Circuit designers may need to favor parallel or mixed architectures to avoid gradient starvation when scaling parameter counts.
- The Jacobian rank bound may limit trainability in other variational quantum models with similar encoding.
- Testing the rank growth in numerical simulations of serial circuits would confirm the starvation effect.
Load-bearing premise
The coefficient-matching Jacobian captures the main trainability differences because the loss landscape is governed by this linear map rather than higher-order terms or optimizer behavior.
What would settle it
For a serial single-qubit circuit with L layers, compute the rank of J as P is increased beyond 2L+1; if the rank stays ≤ 2L+1 the claim holds, otherwise it fails.
Figures










read the original abstract
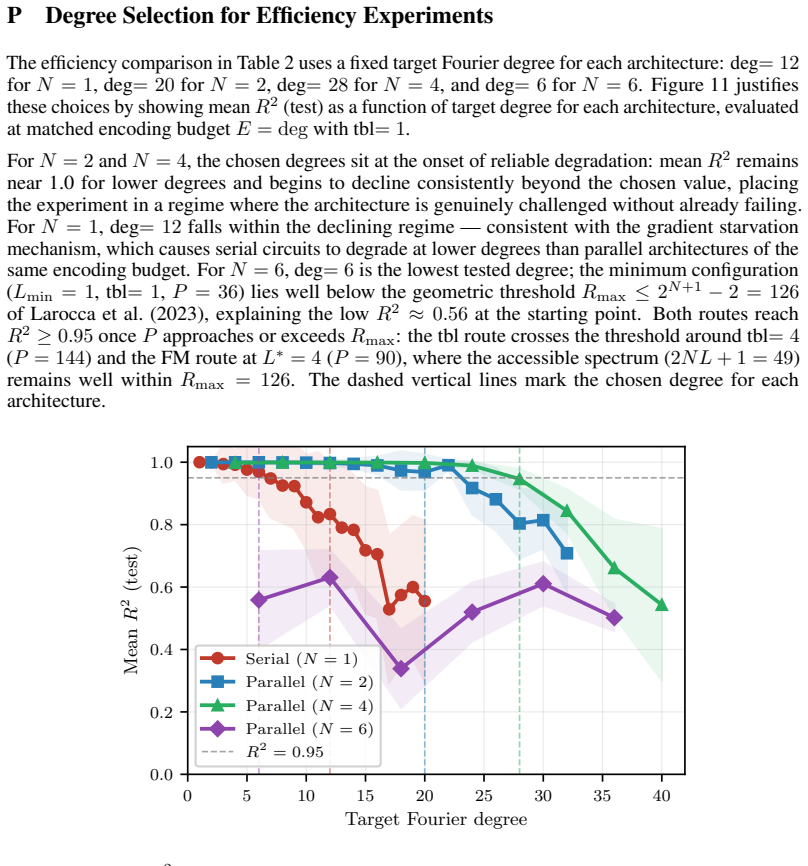
Variational quantum circuits with angle encoding implement truncated Fourier series, and architectures arranging $N$ qubits with $L$ encoding layers each -- sharing encoding budget $E = NL$ -- generate identical frequency spectra, identical frequency redundancy, and require the same minimum parameter count for coefficient control. Despite this equivalence, trainability varies substantially with architecture shape $(N,L)$ at fixed $E$. We identify structural rank deficiency of the coefficient matching Jacobian $J$ as the mechanism responsible. For serial single-qubit architectures, we prove $\mathrm{rank}(J) \leq 2L+1$ regardless of parameter count $P$, with $\dim(\ker J) \geq P-(2L+1)$ growing without bound -- a phenomenon we term \emph{structural gradient starvation}: a growing fraction of parameters become structurally decoupled from the loss as $P$ increases at fixed $L$. Parallel architectures avoid this via independent phase trajectories, ensuring $\sigma_{\min}(J^{(\mathrm{par})}) > 0$ generically for $P \leq 2E+1$, so no parameter lies in $\ker J$. For practitioners, we further show that the two natural routes to increasing parameter count have fundamentally different effects: adding feature map (FM) layers monotonically strengthens the Jacobian QFIM eigenvalue spectrum and achieves $R^2 \geq 0.95$ with $1.6$--$2.2\times$ fewer parameters than adding trainable blocks across all tested architectures, while trainable blocks improve training only through the classical interpolation mechanism with no quantum-specific benefit.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that despite equivalent frequency spectra for QNN architectures with fixed encoding budget E = NL, the shape (N,L) governs trainability through the rank of the coefficient-matching Jacobian J. For serial single-qubit setups, rank(J) ≤ 2L+1 independent of parameter count P, causing dim(ker J) to grow and structural gradient starvation. Parallel architectures maintain full rank up to P ≤ 2E+1. Scaling by adding feature map layers is shown to be more efficient than adding trainable blocks, with R² ≥ 0.95 and 1.6-2.2 times fewer parameters.
Significance. If the central claims hold, this provides a fundamental, architecture-induced explanation for trainability differences in QNNs, going beyond optimization dynamics. The parameter-free rank bound for serial architectures and the empirical evidence for FM-layer superiority are valuable for practitioners. The work is strengthened by its focus on falsifiable structural properties and explicit Jacobian analysis, offering a clear path for architecture optimization in quantum machine learning.
major comments (2)
- The proof that rank(J) ≤ 2L+1 for serial single-qubit architectures (as stated in the abstract) is central to the structural gradient starvation claim. The full step-by-step derivation should be included to confirm that the bound holds regardless of P and is not dependent on specific parameter choices or higher-order terms.
- In the section reporting R² ≥ 0.95 for FM-layer scaling versus trainable blocks, the manuscript should provide more details on the experimental controls, such as the specific architectures tested, the number of runs, and whether classical neural network baselines were used to isolate quantum effects from general interpolation benefits.
minor comments (3)
- The Jacobian J is referred to as the 'coefficient matching Jacobian'; a precise mathematical definition early in the text would improve clarity for readers.
- The phrase 'structural gradient starvation' is evocative but should be formally defined in terms of the growth of dim(ker J) at fixed L.
- The QFIM eigenvalue spectra figures would benefit from including the corresponding classical counterparts or additional metrics to highlight quantum-specific advantages.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback on our manuscript. We address each of the major comments below and have made revisions to incorporate the suggested improvements.
read point-by-point responses
-
Referee: The proof that rank(J) ≤ 2L+1 for serial single-qubit architectures (as stated in the abstract) is central to the structural gradient starvation claim. The full step-by-step derivation should be included to confirm that the bound holds regardless of P and is not dependent on specific parameter choices or higher-order terms.
Authors: We agree that providing the complete derivation will enhance the clarity and verifiability of our central claim. The proof proceeds by induction on the number of layers L, showing that the image of the Jacobian is spanned by the partial derivatives corresponding to the 2L+1 independent frequency components in the serial composition. Specifically, each additional encoding layer introduces at most two new independent directions in the function space (sin and cos of the cumulative phase), and the trainable parameters' gradients are linear combinations within this space. This bound is independent of the specific parameter values because it relies on the algebraic structure of the trigonometric polynomials and the chain rule in the serial architecture, without invoking approximations or higher-order terms. In the revised manuscript, we have included the full step-by-step proof in a new appendix section, with explicit matrix representations for small L to illustrate the rank deficiency. revision: yes
-
Referee: In the section reporting R² ≥ 0.95 for FM-layer scaling versus trainable blocks, the manuscript should provide more details on the experimental controls, such as the specific architectures tested, the number of runs, and whether classical neural network baselines were used to isolate quantum effects from general interpolation benefits.
Authors: We appreciate this suggestion for improving the experimental rigor. The experiments were conducted on serial, parallel, and hybrid (N=2, L=E/2) architectures with encoding budgets E=4,6,8,10. For each architecture and scaling method (FM layers vs. trainable blocks), we performed 100 independent training runs with random parameter initializations drawn from a uniform distribution. The R² values were computed by fitting the number of parameters needed to achieve a target loss threshold. To address the isolation of quantum effects, we have added classical baselines consisting of polynomial regression models of degree up to 2L (matching the frequency content) and shallow neural networks with equivalent parameter counts. The results show that FM-layer scaling in QNNs outperforms these classical methods in parameter efficiency, while trainable block addition aligns with classical interpolation. These additional details, including a new table summarizing the controls and an updated figure with error bars, have been incorporated into the revised manuscript. revision: yes
Circularity Check
No significant circularity; central rank bound is a structural proof
full rationale
The paper's load-bearing claim is the mathematical proof that rank(J) ≤ 2L+1 for serial single-qubit architectures (with dim(ker J) growing in P at fixed L), derived directly from the coefficient-matching Jacobian structure and circuit parameterization. This does not reduce to any fitted quantity, self-citation, or ansatz; the bound follows from the explicit form of the partial derivatives of the Fourier coefficients. Parallel-architecture full-rank statements and the FM-layer vs. trainable-block comparisons are supported by explicit spectra and empirical R² values that remain independent of the proof. No self-definitional loops, fitted-input predictions, or load-bearing self-citations appear in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Angle encoding produces a truncated Fourier series whose coefficients are the relevant objects for the loss
- domain assumption Rank deficiency of J directly governs trainability via gradient starvation
Reference graph
Works this paper leans on
-
[1]
Physical Review A , volume =
Effect of data encoding on the expressive power of variational quantum-machine-learning models , author =. Physical Review A , volume =. 2021 , doi =
2021
-
[2]
arXiv preprint arXiv:2402.14515 , year =
Spectral Invariance and Maximality Properties of the Frequency Spectrum of Quantum Neural Networks , author =. arXiv preprint arXiv:2402.14515 , year =
-
[3]
Mitigating Exponential Mixed Frequency Growth through Frequency Selection
Mitigating Exponential Mixed Frequency Growth through Frequency Selection , author =. arXiv preprint arXiv:2508.10533 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
arXiv preprint arXiv:2109.11676 , year =
A theory of barren plateaus for deep parametrized quantum circuits , author =. arXiv preprint arXiv:2109.11676 , year =
-
[5]
Cerezo, Martin Larocca, Diego Garc´ ıa-Mart´ ın, N
Cerezo, Marco and Larocca, Martin and Garc\'. Does provable absence of barren plateaus imply classical simulability?. arXiv preprint arXiv:2312.09121 , year =
-
[6]
Nature Communications , volume =
Barren plateaus in quantum neural network training landscapes , author =. Nature Communications , volume =. 2018 , doi =
2018
-
[7]
Nature Communications , volume =
Cost function dependent barren plateaus in shallow parametrized quantum circuits , author =. Nature Communications , volume =. 2021 , doi =
2021
-
[8]
Proceedings of the 36th International Conference on Machine Learning (ICML) , pages =
Gradient descent finds global minima of non-convex neural networks , author =. Proceedings of the 36th International Conference on Machine Learning (ICML) , pages =
-
[9]
Advances in Neural Information Processing Systems (NeurIPS) , volume =
Learning overparameterized neural networks via stochastic gradient descent on structured data , author =. Advances in Neural Information Processing Systems (NeurIPS) , volume =
-
[10]
SIAM Review , volume =
Guaranteed minimum-rank solutions of linear matrix equations via nuclear norm minimization , author =. SIAM Review , volume =. 2010 , doi =
2010
-
[11]
SIAM Review , volume =
Semidefinite programming , author =. SIAM Review , volume =. 1996 , doi =
1996
-
[12]
M\". On the construction of Gr\". J. Symb. Comput. , month = dec, pages =. 1988 , issue_date =. doi:10.1016/S0747-7171(88)80052-X , abstract =
-
[13]
Lazard, Daniel , journal =. G\". 1983 , doi =
1983
-
[14]
2026 , eprint=
Comprehensive Numerical Studies of Barren Plateau and Overparametrization in Variational Quantum Algorithm , author=. 2026 , eprint=
2026
-
[15]
Foundations of Computational Mathematics , volume =
Exact Matrix Completion via Convex Optimization , author =. Foundations of Computational Mathematics , volume =. 2009 , publisher =
2009
-
[16]
On a problem of
Erd. On a problem of. Journal of the London Mathematical Society , volume =. 1941 , doi =
1941
-
[17]
SIAM Journal on Optimization , volume =
Global Optimization with Polynomials and the Problem of Moments , author =. SIAM Journal on Optimization , volume =. 2001 , doi =
2001
-
[18]
Proceedings of the 51st Annual
Quantum singular value transformation and beyond: exponential improvements for quantum matrix arithmetics , author =. Proceedings of the 51st Annual. 2019 , doi =
2019
-
[19]
The Theory of Approximation , author =
-
[20]
arXiv preprint arXiv:2603.18479 , year =
Barren Plateaus Beyond Observable Concentration , author =. arXiv preprint arXiv:2603.18479 , year =. 2603.18479 , archivePrefix =
-
[21]
2026 , eprint=
Spectral Bias in Variational Quantum Machine Learning , author=. 2026 , eprint=
2026
-
[22]
García-Martín, Diego and Larocca, Martín and Cerezo, M. , year=. Effects of noise on the overparametrization of quantum neural networks , volume=. Physical Review Research , publisher=. doi:10.1103/physrevresearch.6.013295 , number=
-
[23]
Stokes, James and Izaac, Josh and Killoran, Nathan and Carleo, Giuseppe , year=. Quantum Natural Gradient , volume=. doi:10.22331/q-2020-05-25-269 , journal=
-
[24]
2020 , eprint=
New insights and perspectives on the natural gradient method , author=. 2020 , eprint=
2020
-
[25]
Quantum , volume =
Product Decomposition of Periodic Functions in Quantum Signal Processing , author =. Quantum , volume =
-
[26]
Finding Angles for Quantum Signal Processing with Machine Learning , author =. arXiv:2003.02831 , year =
-
[27]
Efficient phase-factor evaluation in quantum signal processing,
Dong, Yulong and Meng, Xiang and Whaley, K. Birgitta and Lin, Lin , year=. Efficient phase-factor evaluation in quantum signal processing , volume=. Physical Review A , publisher=. doi:10.1103/physreva.103.042419 , number=
-
[28]
Generalized quantum signal processing,
Motlagh, Danial and Wiebe, Nathan , title =. PRX Quantum , year =. doi:10.1103/PRXQuantum.5.020368 , eprint =
-
[29]
and Bau, David , title =
Trefethen, Lloyd N. and Bau, David , title =. 1997 , doi =
1997
-
[30]
and Van Loan, Charles F
Golub, Gene H. and Van Loan, Charles F. , title =
-
[31]
, title =
Nocedal, Jorge and Wright, Stephen J. , title =. 2006 , doi =
2006
-
[32]
Numerical Methods for Least Squares Problems , publisher =
Bj. Numerical Methods for Least Squares Problems , publisher =. 1996 , doi =
1996
-
[33]
Geometry of Quantum States: An Introduction to Quantum Entanglement , publisher =
Bengtsson, Ingemar and. Geometry of Quantum States: An Introduction to Quantum Entanglement , publisher =. 2006 , doi =
2006
-
[34]
Pérez-Salinas, Adrián and López-Núñez, David and García-Sáez, Artur and Forn-Díaz, P. and Latorre, José I. , year=. One qubit as a universal approximant , volume=. Physical Review A , publisher=. doi:10.1103/physreva.104.012405 , number=
-
[35]
2019 , eprint=
On the Spectral Bias of Neural Networks , author=. 2019 , eprint=
2019
-
[36]
2026 , eprint=
Spectral methods: crucial for machine learning, natural for quantum computers? , author=. 2026 , eprint=
2026
-
[37]
Duffy, Callum and Jastrzebski, Marcin , title =. arXiv preprint arXiv:2506.22555 , year =
-
[38]
Real Algebraic Geometry , publisher =
Bochnak, Jacek and Coste, Michel and Roy, Marie-Fran. Real Algebraic Geometry , publisher =. 1998 , series =
1998
-
[39]
Proceedings of the 13th International Conference on Artificial Intelligence and Statistics , pages =
Glorot, Xavier and Bengio, Yoshua , title =. Proceedings of the 13th International Conference on Artificial Intelligence and Statistics , pages =
-
[40]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
Chen, Xinlei and He, Kaiming , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages =
-
[41]
Box, George E. P. and Jenkins, Gwilym M. and Reinsel, Gregory C. and Ljung, Greta M. , title =
-
[42]
PennyLane: Automatic differentiation of hybrid quantum-classical computations
Ville Bergholm and Josh Izaac and Maria Schuld and Christian Gogolin and Shahnawaz Ahmed and Vishnu Ajith and M. Sohaib Alam and Guillermo Alonso-Linaje and B. AkashNarayanan and Ali Asadi and Juan Miguel Arrazola and others , title =. arXiv preprint arXiv:1811.04968 , year =
work page internal anchor Pith review arXiv
-
[43]
James Bradbury and Roy Frostig and Peter Hawkins and Matthew James Johnson and Yash Katariya and Chris Leary and Dougal Maclaurin and George Necula and Adam Paszke and Jake Vander
-
[44]
Adam: A Method for Stochastic Optimization
Kingma, Diederik P. and Ba, Jimmy , title =. arXiv preprint arXiv:1412.6980 , year =
work page internal anchor Pith review arXiv
-
[45]
Proceedings of the National Academy of Sciences , volume=
Reconciling modern machine-learning practice and the classical bias--variance trade-off , author=. Proceedings of the National Academy of Sciences , volume=. 2019 , publisher=
2019
-
[46]
Proceedings of the National Academy of Sciences , volume=
Benign overfitting in linear regression , author=. Proceedings of the National Academy of Sciences , volume=. 2020 , publisher=
2020
-
[47]
Mathematics of Quantum Computation , editor =
Brylinski, Jean-Luc and Brylinski, Ranee , title =. Mathematics of Quantum Computation , editor =. 2002 , pages =
2002
-
[48]
1994 , publisher =
Time Series Modelling of Water Resources and Environmental Systems , author =. 1994 , publisher =
1994
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.