Recognition: unknown
4DThinker: Thinking with 4D Imagery for Dynamic Spatial Understanding
Pith reviewed 2026-05-08 14:14 UTC · model grok-4.3
The pith
4DThinker lets vision-language models simulate evolving scenes inside their latent space for dynamic spatial reasoning from monocular video.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
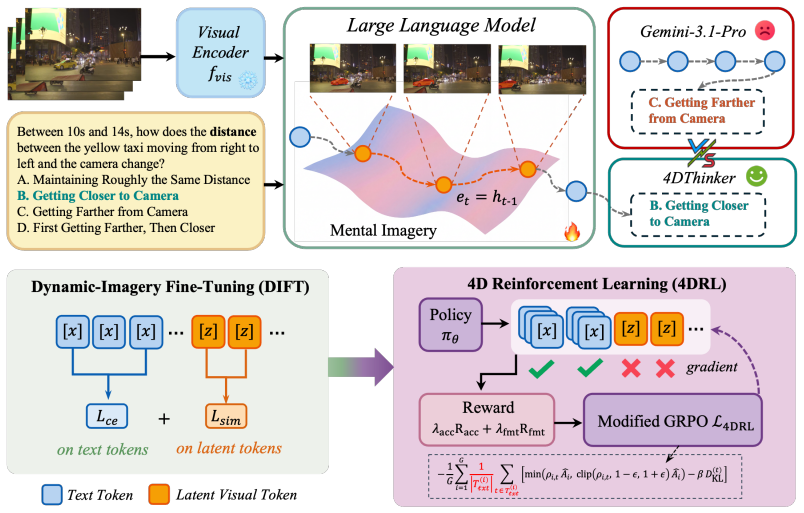
We present 4DThinker, the first framework that enables VLMs to think with 4D through dynamic latent mental imagery, i.e., internally simulating how scenes evolve within the continuous hidden space. We first introduce a scalable, annotation-free data generation pipeline that synthesizes 4D reasoning data from raw videos. We then propose Dynamic-Imagery Fine-Tuning (DIFT), which jointly supervises textual tokens and 4D latents to ground the model in dynamic visual semantics. Building on this, 4D Reinforcement Learning (4DRL) further tackles complex reasoning tasks via outcome-based rewards, restricting policy gradients to text tokens to ensure stable optimization.
What carries the argument
Dynamic latent mental imagery realized through Dynamic-Imagery Fine-Tuning (DIFT) that jointly supervises text tokens and 4D latents plus 4D Reinforcement Learning (4DRL) that applies outcome rewards while restricting policy gradients to text tokens only.
If this is right
- VLMs gain intrinsic dynamic spatial understanding without needing to verbalize every step or invoke external geometric modules at inference.
- Annotation-free synthesis of 4D data from ordinary videos becomes a scalable source of supervision for temporal reasoning.
- Restricting policy gradients to text tokens during reinforcement learning stabilizes training while still improving 4D-aware behavior.
- The approach offers a new route to 4D reasoning inside VLMs that scales beyond current text-heavy methods.
Where Pith is reading between the lines
- Similar latent-imagery training could be tested on non-spatial temporal tasks such as action prediction or physics forecasting.
- If the internal 4D simulation proves accurate, downstream systems might reduce reliance on explicit 3D reconstruction pipelines for video understanding.
- The method suggests a general pattern: pair text optimization with latent-space dynamics to improve any VLM task that involves continuous change.
Load-bearing premise
The annotation-free pipeline for synthesizing 4D reasoning data from raw videos produces sufficiently rich and accurate signals, and the joint DIFT plus restricted 4DRL training produces stable gains in intrinsic dynamic reasoning without external geometry.
What would settle it
Experiments in which 4DThinker fails to outperform strong text-only or geometry-augmented baselines on multiple dynamic spatial reasoning benchmarks from monocular video would falsify the central performance claim.
Figures














read the original abstract
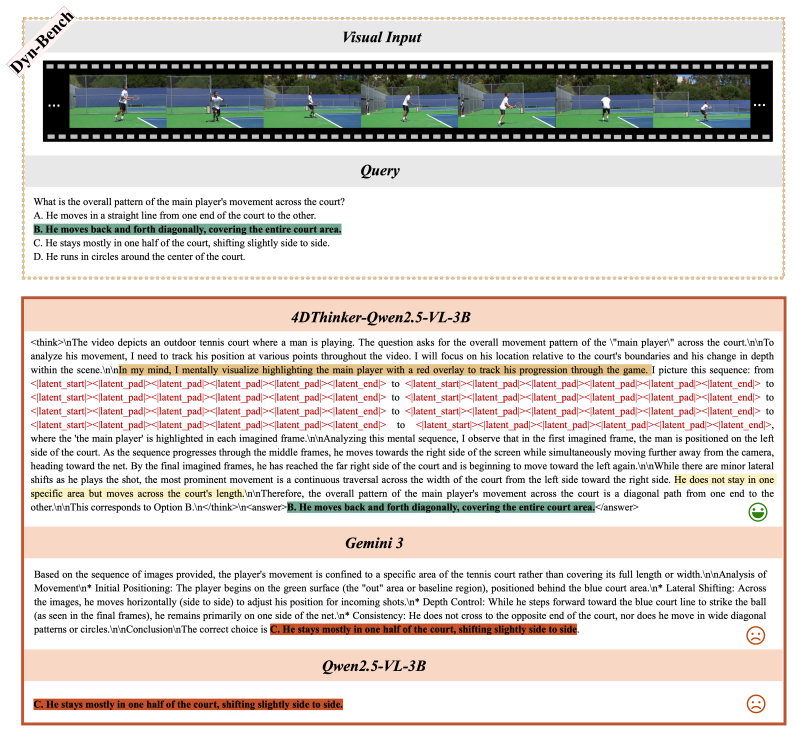
Dynamic spatial reasoning from monocular video is essential for bridging visual intelligence and the physical world, yet remains challenging for vision-language models (VLMs). Prior approaches either verbalize spatial-temporal reasoning entirely as text, which is inherently verbose and imprecise for complex dynamics, or rely on external geometric modules that increase inference complexity without fostering intrinsic model capability. In this paper, we present 4DThinker, the first framework that enables VLMs to "think with 4D" through dynamic latent mental imagery, i.e., internally simulating how scenes evolve within the continuous hidden space. Specifically, we first introduce a scalable, annotation-free data generation pipeline that synthesizes 4D reasoning data from raw videos. We then propose Dynamic-Imagery Fine-Tuning (DIFT), which jointly supervises textual tokens and 4D latents to ground the model in dynamic visual semantics. Building on this, 4D Reinforcement Learning (4DRL) further tackles complex reasoning tasks via outcome-based rewards, restricting policy gradients to text tokens to ensure stable optimization. Extensive experiments across multiple dynamic spatial reasoning benchmarks demonstrate that 4DThinker consistently outperforms strong baselines and offers a new perspective toward 4D reasoning in VLMs. Our code is available at https://github.com/zhangquanchen/4DThinker.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces 4DThinker, a framework that enables VLMs to perform dynamic spatial reasoning from monocular video by internally simulating scene evolution via dynamic latent mental imagery in continuous hidden space. It consists of an annotation-free pipeline to synthesize 4D reasoning data from raw videos, Dynamic-Imagery Fine-Tuning (DIFT) that jointly supervises textual tokens and 4D latents, and 4D Reinforcement Learning (4DRL) that applies outcome-based rewards while restricting policy gradients to text tokens for stable optimization. The paper claims this approach avoids verbose text-only reasoning or external geometric modules and demonstrates consistent outperformance over strong baselines across multiple dynamic spatial reasoning benchmarks, with code released publicly.
Significance. If the synthesized 4D data fidelity and empirical gains hold, the work could meaningfully advance intrinsic 4D reasoning in VLMs by reducing reliance on external modules and fostering more efficient dynamic spatial understanding. The open-sourced code is a positive factor for reproducibility.
major comments (3)
- [§3.1] §3.1 (4D Data Synthesis Pipeline): The central claim that the annotation-free pipeline produces sufficiently rich and accurate 4D latent supervision from monocular videos is load-bearing for both DIFT grounding and 4DRL stability, yet the manuscript supplies no quantitative validation metrics (e.g., depth consistency, motion trajectory error, or comparison to geometric ground truth) to confirm fidelity or bound synthesis inaccuracies.
- [§4] §4 (Experiments): The assertion of consistent outperformance lacks reported ablation studies isolating the contributions of DIFT versus 4DRL, baseline implementation details, or error analysis; without these, the link between the proposed components and benchmark gains cannot be evaluated.
- [§3.3] §3.3 (4DRL): Restricting policy gradients to text tokens is presented as ensuring stable optimization, but no ablation comparing this choice to full-token updates or analysis of gradient variance is provided, leaving the stability benefit unsubstantiated.
minor comments (2)
- [Abstract] Abstract: While the high-level claims are clear, inclusion of at least one key quantitative result (e.g., average accuracy gain) would strengthen the summary for readers.
- [§3] Notation: The distinction between '4D latents' and standard visual features should be clarified with a brief formal definition or diagram in the method section to avoid ambiguity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below and will revise the manuscript to strengthen the presentation of our contributions.
read point-by-point responses
-
Referee: [§3.1] §3.1 (4D Data Synthesis Pipeline): The central claim that the annotation-free pipeline produces sufficiently rich and accurate 4D latent supervision from monocular videos is load-bearing for both DIFT grounding and 4DRL stability, yet the manuscript supplies no quantitative validation metrics (e.g., depth consistency, motion trajectory error, or comparison to geometric ground truth) to confirm fidelity or bound synthesis inaccuracies.
Authors: We agree that quantitative validation metrics would strengthen the claims regarding the 4D data synthesis pipeline. The pipeline builds on established off-the-shelf models for depth and motion estimation whose individual accuracies are documented in prior literature, and we provide qualitative examples of synthesized 4D latents in the manuscript. To directly address this concern, the revised version will include quantitative metrics such as frame-to-frame depth consistency, motion trajectory error where proxy ground truth can be derived, and comparisons against geometric reconstructions on subsets of the data. revision: yes
-
Referee: [§4] §4 (Experiments): The assertion of consistent outperformance lacks reported ablation studies isolating the contributions of DIFT versus 4DRL, baseline implementation details, or error analysis; without these, the link between the proposed components and benchmark gains cannot be evaluated.
Authors: We acknowledge that additional ablations and analysis would improve interpretability. The current results focus on end-to-end benchmark comparisons against strong baselines. In the revision we will add ablation studies that isolate the contributions of DIFT and 4DRL, expand baseline implementation details (including hyperparameters and training protocols), and include error analysis such as per-benchmark breakdowns and qualitative failure cases. revision: yes
-
Referee: [§3.3] §3.3 (4DRL): Restricting policy gradients to text tokens is presented as ensuring stable optimization, but no ablation comparing this choice to full-token updates or analysis of gradient variance is provided, leaving the stability benefit unsubstantiated.
Authors: We will add an ablation study in the revised manuscript that directly compares the restricted policy-gradient approach to full-token updates, together with measurements of gradient variance across training runs. This will provide empirical support for the stability rationale described in §3.3. revision: yes
Circularity Check
No circularity: empirical framework with no derivation chain
full rationale
The paper introduces an empirical training pipeline (annotation-free 4D synthesis, DIFT joint supervision, and 4DRL with outcome rewards) rather than any mathematical derivation, equations, or first-principles claims that could reduce to inputs by construction. No self-definitional steps, fitted parameters renamed as predictions, or load-bearing self-citations appear in the provided text. The central claims rest on experimental outperformance on benchmarks, which is falsifiable and independent of the method description itself. This is the standard case of a non-circular empirical ML contribution.
Axiom & Free-Parameter Ledger
invented entities (1)
-
dynamic latent mental imagery
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923,
work page internal anchor Pith review arXiv
-
[2]
Spatialbot: Precise spatial understanding with vision language models
Wenxiao Cai, Iaroslav Ponomarenko, Jianhao Yuan, Xiaoqi Li, Wankou Yang, Hao Dong, and Bo Zhao. Spatialbot: Precise spatial understanding with vision language models.arXiv preprint arXiv:2406.13642,
-
[3]
SAM 3: Segment Anything with Concepts
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719,
work page internal anchor Pith review arXiv
-
[4]
Jiewen Chan, Zhenjun Zhao, and Yu-Lun Liu. Adagar: Adaptive gabor representation for dynamic scene reconstruction.arXiv preprint arXiv:2601.00796,
-
[5]
Zhangquan Chen, Manyuan Zhang, Xinlei Yu, Xufang Luo, Mingze Sun, Zihao Pan, Yan Feng, Peng Pei, Xunliang Cai, and Ruqi Huang. Think with 3d: Geometric imagination grounded spatial reasoning from limited views.arXiv preprint arXiv:2510.18632, 2025a. Zhangquan Chen, Ruihui Zhao, Chuwei Luo, Mingze Sun, Xinlei Yu, Yangyang Kang, and Ruqi Huang. Sifthinker: ...
-
[6]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review arXiv
-
[7]
From explicit cot to implicit cot: Learning to internalize cot step by step
Yuntian Deng, Yejin Choi, and Stuart Shieber. From explicit cot to implicit cot: Learning to internalize cot step by step.arXiv preprint arXiv:2405.14838,
-
[8]
VLM-3R: Vision-Language Models Augmented with Instruction-Aligned 3D Reconstruction
Zhiwen Fan, Jian Zhang, Renjie Li, Junge Zhang, Runjin Chen, Hezhen Hu, Kevin Wang, Huaizhi Qu, Dilin Wang, Zhicheng Yan, et al. Vlm-3r: Vision-language models augmented with instruction-aligned 3d reconstruction.arXiv preprint arXiv:2505.20279,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Sachin Goyal, Ziwei Ji, Ankit Singh Rawat, Aditya Krishna Menon, Sanjiv Kumar, and Vaishnavh Nagarajan. Think before you speak: Training language models with pause tokens.arXiv preprint arXiv:2310.02226,
-
[10]
Training Large Language Models to Reason in a Continuous Latent Space
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space.arXiv preprint arXiv:2412.06769,
work page internal anchor Pith review arXiv
-
[11]
Yuzhi Huang, Kairun Wen, Rongxin Gao, Dongxuan Liu, Yibin Lou, Jie Wu, Jing Xu, Jian Zhang, Zheng Yang, Yunlong Lin, et al. Thinking in dynamics: How multimodal large language models perceive, track, and reason dynamics in physical 4d world.arXiv preprint arXiv:2603.12746,
-
[12]
Latent visual reasoning.arXiv preprint arXiv:2509.24251, 2025a
Bangzheng Li, Ximeng Sun, Jiang Liu, Ze Wang, Jialian Wu, Xiaodong Yu, Hao Chen, Emad Barsoum, Muhao Chen, and Zicheng Liu. Latent visual reasoning.arXiv preprint arXiv:2509.24251, 2025a. Haoang Li, Ji Zhao, Jean-Charles Bazin, Pyojin Kim, Kyungdon Joo, Zhenjun Zhao, and Yun-Hui Liu. Hong kong world: Leveraging structural regularity for line-based slam.IE...
-
[13]
Hongxing Li, Dingming Li, Zixuan Wang, Yuchen Yan, Hang Wu, Wenqi Zhang, Yongliang Shen, Weiming Lu, Jun Xiao, and Yueting Zhuang. Spatialladder: Progressive training for spatial reasoning in vision-language models.arXiv preprint arXiv:2510.08531, 2025b. Mingrui Li, Dong Li, Sijia Hu, Kangxu Wang, Zhenjun Zhao, and Hongyu Wang. Slam-x: Generalizable dynam...
-
[14]
Yuecheng Liu, Dafeng Chi, Shiguang Wu, Zhanguang Zhang, Yaochen Hu, Lingfeng Zhang, Yingxue Zhang, Shuang Wu, Tongtong Cao, Guowei Huang, et al. Spatialcot: Advancing spatial reasoning through coordinate alignment and chain-of-thought for embodied task planning.arXiv preprint arXiv:2501.10074, 2025a. Yuhong Liu, Beichen Zhang, Yuhang Zang, Yuhang Cao, Lon...
-
[15]
SpaceR: Reinforcing MLLMs in Video Spatial Reasoning
Kun Ouyang, Yuanxin Liu, Haoning Wu, Yi Liu, Hao Zhou, Jie Zhou, Fandong Meng, and Xu Sun. Spacer: Reinforcing mllms in video spatial reasoning.arXiv preprint arXiv:2504.01805,
work page internal anchor Pith review arXiv
-
[16]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review arXiv
-
[17]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Jiahao Wang, Yufeng Yuan, Rujie Zheng, Youtian Lin, Jian Gao, Lin-Zhuo Chen, Yajie Bao, Yi Zhang, Chang Zeng, Yanxi Zhou, et al. Spatialvid: A large-scale video dataset with spatial annotations.arXiv preprint arXiv:2509.09676, 2025a. Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Sha...
-
[19]
Learning how to use tools, not just when: Pattern-aware tool-integrated reasoning.MATH-AI @ NeurIPS 2025,
Ningning Xu, Yuxuan Jiang, Shubhashis Roy Dipta, and Zhang Hengyuan. Learning how to use tools, not just when: Pattern-aware tool-integrated reasoning.MATH-AI @ NeurIPS 2025,
2025
-
[20]
Visual spatial tuning.arXiv preprint arXiv:2511.05491, 2025
Jihan Yang, Shusheng Yang, Anjali W Gupta, Rilyn Han, Li Fei-Fei, and Saining Xie. Thinking in space: How multimodal large language models see, remember, and recall spaces. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10632–10643, 2025a. Rui Yang, Ziyu Zhu, Yanwei Li, Jingjia Huang, Shen Yan, Siyuan Zhou, Zhe Liu, Xiangta...
-
[21]
Xinlei Yu, Zhangquan Chen, Yongbo He, Tianyu Fu, Cheng Yang, Chengming Xu, Yue Ma, Xiaobin Hu, Zhe Cao, Jie Xu, et al. The latent space: Foundation, evolution, mechanism, ability, and outlook.arXiv preprint arXiv:2604.02029,
-
[22]
Dsi- bench: A benchmark for dynamic spatial intelligence.arXiv preprint arXiv:2510.18873, 2025
Ziang Zhang, Zehan Wang, Guanghao Zhang, Weilong Dai, Yan Xia, Ziang Yan, Minjie Hong, and Zhou Zhao. Dsi-bench: A benchmark for dynamic spatial intelligence.arXiv preprint arXiv:2510.18873,
-
[23]
Duo Zheng, Shijia Huang, Yanyang Li, and Liwei Wang. Learning from videos for 3d world: Enhancing mllms with 3d vision geometry priors.arXiv preprint arXiv:2505.24625,
-
[24]
Shengchao Zhou, Yuxin Chen, Yuying Ge, Wei Huang, Jiehong Lin, Ying Shan, and Xiaojuan Qi. Learning to reason in 4d: Dynamic spatial understanding for vision language models.arXiv preprint arXiv:2512.20557, 2025a. Shengchao Zhou, Yuxin Chen, Yuying Ge, Wei Huang, Jiehong Lin, Ying Shan, and Xiaojuan Qi. Learning to reason in 4d: Dynamic spatial understand...
-
[25]
the red car on the left lane
12 A Object Selection Rules As described in Sec. 3.1, we define a set of predefined rules R to guide Mhigh in selecting a representative static object os and a dynamic object od from each video. Specifically, we instruct Mhigh with the following criteria: Static object selection. • The object must bestationarythroughout the entire video (e.g., the traffic...
2025
-
[26]
mental imagery,
is appended before every question during DIFT training, 4DRL, and inference, specifying the output format that the model must follow. During 4DRL, the format reward Rfmt checks adherence to this think-answer structure. Table 6: Candidate question types, target objects, and descriptions in our data generation pipeline. Category Type Target Object Descripti...
2026
-
[27]
Absolute
DSR-Bench subtasks.DSR-Bench Zhou et al. (2025a) organizes its 13 subtasks along two axes: viewpoint mobility(Absolute vs. Relative) andspatial attribute type. “Absolute” (A.) denotes that the viewpoint is fixed at a specific timestamp, while “Relative” (R.) denotes that the viewpoint moves with the observing agent over time. The attribute types are: •Dis...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.