Recognition: no theorem link
Memory Inception: Latent-Space KV Cache Manipulation for Steering LLMs
Pith reviewed 2026-05-12 01:49 UTC · model grok-4.3
The pith
Inserting text-derived KV banks at selected layers steers LLMs by selective latent allocation rather than full prompt caching.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
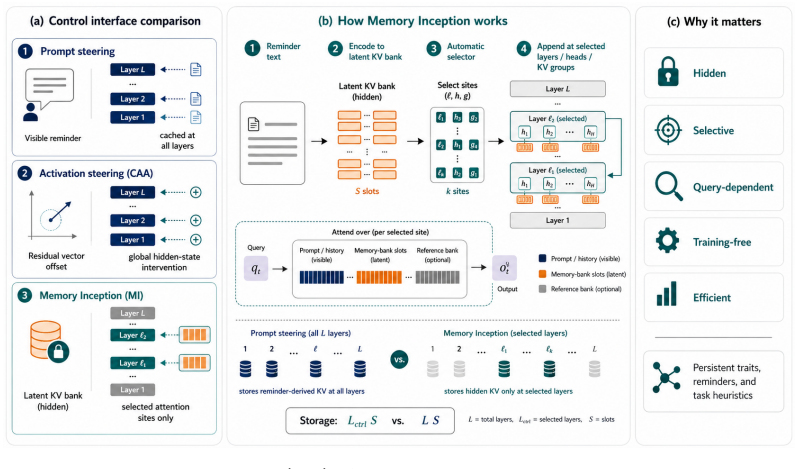
The central claim is that memory inception steers LLMs effectively by injecting text-derived key-value banks into the KV cache at chosen layers only, enabling persistent guidance and mid-conversation shifts without rewriting the visible transcript or materializing content at all layers. This latent-space manipulation remains competitive with prompting on personality-steering tasks while outperforming activation methods, and it exceeds visible prompting on HARDMath and PHYSICS reasoning in most subject-mode combinations. The same content-matched guidance requires up to 118 times less KV storage.
What carries the argument
Selective insertion of text-derived key-value banks into the KV cache at chosen layers, allowing the model to route to and utilize these latent slots for steering without full-layer caching.
If this is right
- MI delivers the strongest overall control-drift trade-off on matched personality-steering tasks while staying competitive with prompting and beating CAA.
- It supports mid-conversation behavior shifts without changing the visible transcript and achieves the highest post-shift alignment.
- On structured reasoning proxies like HARDMath and PHYSICS, MI beats visible prompting in 10 of 12 subject by mode combinations.
- Content-matched KV storage drops by up to 118 times compared with full prompt caching.
Where Pith is reading between the lines
- The layer-selective approach could extend to other persistent memory needs in long conversations where full transcript retention becomes costly.
- It implies that steering signals need not be distributed uniformly across layers, opening questions about automatic layer selection for different guidance types.
- Storage savings might compound in multi-turn settings by keeping guidance latent rather than expanding the active context window.
Load-bearing premise
That text-derived KV banks inserted at selected layers will be routed to and utilized by the model for steering without introducing uncontrolled side effects or requiring extensive per-model layer tuning.
What would settle it
A head-to-head evaluation on personality-steering tasks where memory inception shows a worse control-drift trade-off than prompting or CAA, or where it fails to outperform visible prompting on 10 of 12 HARDMath and PHYSICS cells while matching the claimed storage reduction.
Figures





read the original abstract
Steering large language models (LLMs) is usually done by either instruction prompting or activation steering. Prompting often gives strong control, but caches guidance tokens at every layer and can clutter long interactions; activation steering is compact but typically weaker and does not support large structured reminders. We introduce memory inception (MI), a training-free method that steers in latent attention space by inserting text-derived key-value (KV) banks only at selected layers. Rather than materializing reminder content throughout the prompt cache, MI treats steering as selective KV allocation, injecting latent slots only where the model routes to them. On matched personality-steering tasks, MI gives the best overall control--drift trade-off, remaining competitive with prompting while consistently outperforming CAA. On updateable guidance, MI supports mid-conversation behavior shifts without rewriting the visible transcript, achieving the highest post-shift alignment on Qwen3. On structured reasoning, MI outperforms visible prompting on HARDMath and PHYSICS (10/12 subject$\times$mode cells), serving as proxies for structured reasoning in verifiable domains, while cutting content-matched KV storage by up to 118$\times$. These results position MI as a powerful steering method when guidance is persistent, structured, or expensive to keep in the visible transcript.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Memory Inception (MI), a training-free method for steering LLMs by inserting text-derived KV banks selectively into the latent attention cache at chosen layers. It claims that MI achieves the best control-drift trade-off on personality-steering tasks (competitive with prompting, outperforming CAA), supports mid-conversation updates with highest post-shift alignment on Qwen3, outperforms visible prompting on 10/12 subject×mode cells of HARDMath and PHYSICS benchmarks, and reduces content-matched KV storage by up to 118×.
Significance. If the routing and utilization claims hold with proper controls, MI could represent a meaningful advance in efficient, persistent LLM steering by combining the compactness of activation methods with the structured capacity of prompting, while offering substantial cache savings for long or updateable guidance scenarios. The empirical focus on verifiable reasoning proxies and dynamic shifts is a strength.
major comments (3)
- [Results / Experimental Setup] Results section (and associated tables/figures reporting quantitative wins): the manuscript supplies no details on experimental controls, statistical tests, exact layer-selection procedure, or precise baseline implementations (e.g., how CAA and prompting were matched for token budget and content). This absence prevents evaluation of whether the reported superiority on personality tasks and 10/12 reasoning cells is robust.
- [Method / KV Insertion] Method description of KV bank insertion (likely §3): the central mechanism assumes that text-derived KV banks inserted at selected layers are routed to and utilized by the model's attention without uncontrolled side effects or per-model tuning. No supporting evidence is provided, such as attention-map visualizations, KV-ablation experiments, or routing analysis, making the control-drift and reasoning gains dependent on an unverified assumption.
- [Efficiency Analysis] Claims of 118× KV storage reduction: the comparison is described as 'content-matched' but lacks a precise accounting of how the baseline KV footprint is computed (full prompt cache vs. selective banks) and whether it accounts for any overhead from layer selection or bank management.
minor comments (2)
- [Method] Notation for layers and KV banks should be defined more explicitly (e.g., a table listing selected layers per model).
- [Related Work] Add references to recent work on KV cache compression and activation steering for context.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We address each major comment point by point below, providing clarifications and committing to specific revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Results / Experimental Setup] Results section (and associated tables/figures reporting quantitative wins): the manuscript supplies no details on experimental controls, statistical tests, exact layer-selection procedure, or precise baseline implementations (e.g., how CAA and prompting were matched for token budget and content). This absence prevents evaluation of whether the reported superiority on personality tasks and 10/12 reasoning cells is robust.
Authors: We agree that the original manuscript omitted key details on the experimental setup. In the revised version we will add a dedicated subsection under Experimental Setup that specifies: all controls (temperature, decoding parameters, random seeds, and prompt formatting); the statistical tests performed (paired t-tests with reported p-values for main comparisons); the exact layer-selection procedure (preliminary per-model ablations on a small validation set to identify layers with peak steering efficacy); and precise baseline matching (token budgets equalized by using identical guidance content lengths for CAA and prompting, with content-matched KV extraction for fair comparison). These additions will allow readers to assess the robustness of the reported wins on personality and reasoning tasks. revision: yes
-
Referee: [Method / KV Insertion] Method description of KV bank insertion (likely §3): the central mechanism assumes that text-derived KV banks inserted at selected layers are routed to and utilized by the model's attention without uncontrolled side effects or per-model tuning. No supporting evidence is provided, such as attention-map visualizations, KV-ablation experiments, or routing analysis, making the control-drift and reasoning gains dependent on an unverified assumption.
Authors: We accept that direct evidence for the insertion mechanism was insufficient. The revised manuscript will include: (i) attention-map visualizations from representative layers and examples showing elevated attention weights on the inserted KV bank positions; (ii) KV-ablation results demonstrating performance degradation when banks are removed or replaced with random vectors; and (iii) a short routing analysis quantifying attention allocation to bank tokens versus original context. These additions will substantiate that the banks are utilized by attention with limited side effects. Layer selection involves a one-time validation pass per model, which we will explicitly note as a lightweight preprocessing step rather than per-instance tuning. revision: yes
-
Referee: [Efficiency Analysis] Claims of 118× KV storage reduction: the comparison is described as 'content-matched' but lacks a precise accounting of how the baseline KV footprint is computed (full prompt cache vs. selective banks) and whether it accounts for any overhead from layer selection or bank management.
Authors: We will expand the efficiency section with an explicit accounting. The baseline is defined as the full KV cache for the guidance tokens stored across every layer (typically 32 layers), while MI stores banks only at the 2–4 selected layers. The reduction factor is computed as (total layers × guidance tokens) / (selected layers × guidance tokens), using identical source text for content matching. Overhead from layer selection (precomputed once) and bank management (static arrays with negligible indexing cost) will be quantified and shown to be <1% of the savings. We will add the corresponding formulas and a worked numerical example for the 118× figure. revision: yes
Circularity Check
No circularity: empirical method with direct comparisons and no derivations
full rationale
The paper introduces Memory Inception as a training-free empirical technique for latent-space KV cache manipulation, evaluated through direct performance comparisons on personality-steering tasks, updateable guidance, and structured reasoning benchmarks (HARDMath, PHYSICS). No equations, derivations, fitted parameters, or self-citation chains are present in the provided text that could reduce any claim to its own inputs by construction. All load-bearing assertions rest on reported experimental outcomes rather than logical self-reference, rendering the work self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Transformer attention layers maintain and can accept externally supplied key-value caches that influence generation when inserted at chosen depths.
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume =
Attention Is All You Need , author =. Advances in Neural Information Processing Systems , volume =. 2017 , publisher =
work page 2017
-
[2]
RoFormer: Enhanced Transformer with Rotary Position Embedding
Su, Jianlin and Lu, Yu and Pan, Shengfeng and Murtadha, Ahmed and Wen, Bo and Liu, Yunfeng , year =. doi:10.48550/arXiv.2104.09864 , url =. 2104.09864 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2104.09864
-
[3]
Language Models are Unsupervised Multitask Learners , author =. 2019 , url =
work page 2019
-
[4]
Grattafiori, Aaron and Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and Al-Dahle, Ahmad and Letman, Aiesha and Mathur, Akhil and Schelten, Alan and Vaughan, Alex and others , year =. The. doi:10.48550/arXiv.2407.21783 , url =. 2407.21783 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783
-
[5]
InProceedings of the 29th Symposium on Operating Systems Principles(Koblenz, Germany)(SOSP ’23)
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph E. and Zhang, Hao and Stoica, Ion , booktitle =. Efficient Memory Management for Large Language Model Serving with. 2023 , publisher =. doi:10.1145/3600006.3613165 , url =
- [6]
-
[7]
2025 , howpublished =
work page 2025
-
[8]
Yang, An and Li, Anfeng and Yang, Baosong and Zhang, Beichen and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Gao, Chang and Huang, Chengen and Lv, Chenxu and others , year =. doi:10.48550/arXiv.2505.09388 , url =. 2505.09388 , archivePrefix =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388
-
[9]
Journal of Research in Personality , volume =
The International Personality Item Pool and the Future of Public-Domain Personality Measures , author =. Journal of Research in Personality , volume =. 2006 , doi =
work page 2006
-
[10]
Advances in Neural Information Processing Systems , volume =
Language Models are Few-Shot Learners , author =. Advances in Neural Information Processing Systems , volume =. 2020 , publisher =
work page 2020
-
[11]
Prefix-Tuning: Optimizing Continuous Prompts for Generation , author =. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages =. 2021 , address =. doi:10.18653/v1/2021.acl-long.353 , url =
-
[12]
doi: 10.18653/v1/2021.emnlp-main.243
The Power of Scale for Parameter-Efficient Prompt Tuning , author =. Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing , pages =. 2021 , address =. doi:10.18653/v1/2021.emnlp-main.243 , url =
-
[13]
Advances in Neural Information Processing Systems , volume =
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author =. Advances in Neural Information Processing Systems , volume =. 2022 , publisher =
work page 2022
-
[14]
Large Language Models are Zero-Shot Reasoners
Large Language Models are Zero-Shot Reasoners , author =. Advances in Neural Information Processing Systems , volume =. 2022 , publisher =. 2205.11916 , archivePrefix =
work page internal anchor Pith review arXiv 2022
-
[15]
Retrieval-Augmented Generation for Knowledge-Intensive
Lewis, Patrick and Perez, Ethan and Piktus, Aleksandra and Petroni, Fabio and Karpukhin, Vladimir and Goyal, Naman and K. Retrieval-Augmented Generation for Knowledge-Intensive. Advances in Neural Information Processing Systems , volume =. 2020 , publisher =
work page 2020
-
[16]
arXiv preprint arXiv:1911.00172 , year=
Generalization through Memorization: Nearest Neighbor Language Models , author =. International Conference on Learning Representations , year =. 1911.00172 , archivePrefix =
-
[17]
Proceedings of the 39th International Conference on Machine Learning , series =
Improving Language Models by Retrieving from Trillions of Tokens , author =. Proceedings of the 39th International Conference on Machine Learning , series =. 2022 , publisher =
work page 2022
-
[18]
N., Hutchins, D., and Szegedy, C
Memorizing Transformers , author =. International Conference on Learning Representations , year =. 2203.08913 , archivePrefix =
-
[19]
Steering Language Models With Activation Engineering
Steering Language Models With Activation Engineering , author =. 2024 , eprint =. doi:10.48550/arXiv.2308.10248 , url =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.10248 2024
-
[20]
Steering Llama 2 via Contrastive Activation Addition
Rimsky, Nina and Gabrieli, Nick and Schulz, Julian and Tong, Meg and Hubinger, Evan and Turner, Alexander , booktitle =. Steering. 2024 , address =. doi:10.18653/v1/2024.acl-long.828 , url =
-
[21]
Function Vectors in Large Language Models , author =. The Twelfth International Conference on Learning Representations , year =. 2310.15213 , archivePrefix =
-
[22]
Representation Engineering: A Top-Down Approach to AI Transparency
Zou, Andy and Phan, Long and Chen, Sarah and Campbell, James and Guo, Phillip and Ren, Richard and Pan, Alexander and Yin, Xuwang and Mazeika, Mantas and Dombrowski, Ann-Kathrin and Goel, Shashwat and Li, Nathaniel and Byun, Michael J. and Wang, Zifan and Mallen, Alex and Basart, Steven and Koyejo, Sanmi and Song, Dawn and Fredrikson, Matt and Kolter, J. ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.01405
-
[23]
Programming Refusal with Conditional Activation Steering , author =. International Conference on Learning Representations , year =. doi:10.48550/arXiv.2409.05907 , url =. 2409.05907 , archivePrefix =
-
[24]
Findings of the Association for Computational Linguistics: EMNLP 2024 , pages =
Activation Scaling for Steering and Interpreting Language Models , author =. Findings of the Association for Computational Linguistics: EMNLP 2024 , pages =. 2024 , address =. doi:10.18653/v1/2024.findings-emnlp.479 , url =
-
[25]
Improved Representation Steering for Language Models , author =. 2025 , eprint =. doi:10.48550/arXiv.2505.20809 , url =
-
[26]
Model Tells Itself Where to Attend: Faithfulness Meets Automatic Attention Steering , author =. 2024 , eprint =. doi:10.48550/arXiv.2409.10790 , url =
-
[27]
The Fourteenth International Conference on Learning Representations , year =
Spectral Attention Steering for Prompt Highlighting , author =. The Fourteenth International Conference on Learning Representations , year =. doi:10.48550/arXiv.2603.01281 , url =. 2603.01281 , archivePrefix =
-
[28]
doi:10.48550/arXiv.2603.10705 , url =
Ge, Yuyao and Liu, Shenghua and Wang, Yiwei and Liu, Tianyu and Bi, Baolong and Mei, Lingrui and Yao, Jiayu and Guo, Jiafeng and Cheng, Xueqi , year =. doi:10.48550/arXiv.2603.10705 , url =. 2603.10705 , archivePrefix =
-
[29]
Spotlight Your Instructions: Instruction-following with Dynamic Attention Steering , author =. Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2026 , address =. doi:10.18653/v1/2026.eacl-long.174 , url =
-
[30]
and Dorkenwald, Michael and Mirza, M
Belitsky, Max and Kopiczko, Dawid J. and Dorkenwald, Michael and Mirza, M. Jehanzeb and Glass, James R. and Snoek, Cees G. M. and Asano, Yuki M. , year =. doi:10.48550/arXiv.2507.08799 , url =. 2507.08799 , archivePrefix =
-
[31]
Feng, Kaiyue and Zhao, Yilun and Liu, Yixin and Yang, Tianyu and Zhao, Chen and Sous, John and Cohan, Arman , booktitle =. 2025 , address =. doi:10.18653/v1/2025.findings-acl.610 , url =
-
[32]
Fan, Jingxuan and Martinson, Sarah and Wang, Erik Y. and Hausknecht, Kaylie and Brenner, Jonah and Liu, Danxian and Peng, Nianli and Wang, Corey and Brenner, Michael P. , booktitle =. 2025 , eprint =
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.