Recognition: 2 theorem links
· Lean TheoremNot All Tokens Need 40 Steps: Heterogeneous Step Allocation in Diffusion Transformers for Efficient Video Generation
Pith reviewed 2026-05-11 00:56 UTC · model grok-4.3
The pith
Allocating fewer denoising steps to low-velocity tokens speeds up video generation in diffusion transformers while preserving quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
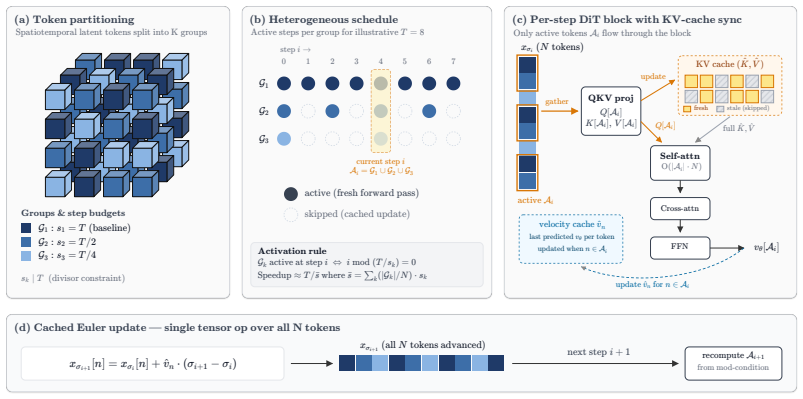
Heterogeneous Step Allocation (HSA) assigns different numbers of denoising steps to different spatiotemporal tokens according to their velocity dynamics. It resolves the resulting sequence length differences by synchronizing the KV cache for full-context attention and by using a cached Euler update to progress inactive tokens without extra model evaluations. Evaluated on Wan-2 and LTX-2 for text-to-video and image-to-video, HSA delivers superior quality-runtime trade-offs compared to uniform step allocation and prior caching approaches, particularly under aggressive acceleration.
What carries the argument
Heterogeneous Step Allocation based on velocity dynamics, supported by KV-cache synchronization and a cached Euler update to handle variable step counts across tokens.
If this is right
- Superior performance on the quality-runtime Pareto frontier at 50% and 25% runtimes.
- Robust preservation of structural integrity and generation quality under tight budgets.
- Effective for both text-to-video and image-to-video generation without retraining.
- Outperforms previous state-of-the-art caching methods without needing expensive offline profiling.
Where Pith is reading between the lines
- Similar velocity-based allocation could improve efficiency in other generative models where computation is uniform across elements.
- Adapting this during training might further reduce the need for post-hoc adjustments.
- Applications in real-time video synthesis become more practical on resource-limited hardware.
- The approach underscores opportunities for dynamic computation in transformer-based models beyond video.
Load-bearing premise
Velocity dynamics from latent states can identify tokens that safely accept fewer denoising steps without visible artifacts or loss of temporal consistency.
What would settle it
Running HSA on video generation tasks with significant motion variation and comparing the outputs to full-step references for the appearance of artifacts or quality degradation at reduced step budgets.
Figures





read the original abstract
Diffusion Transformers (DiTs) have achieved state-of-the-art video generation quality, but they incur immense computational cost because standard inference applies the same number of denoising steps uniformly to every token in the sequence. It is well known that human vision ignores vast amounts of redundant motion. Why, then, do our densest models treat every spatiotemporal token with equal priority? In this paper, we introduce Heterogeneous Step Allocation (HSA), a training-free inference algorithm that assigns varying step budgets to different spatiotemporal tokens based on their velocity dynamics. To resolve the resulting sequence-length mismatch without sacrificing global context, HSA introduces a KV-cache synchronization mechanism that allows active tokens to attend to the full sequence while entirely bypassing inactive tokens. Furthermore, we derive a cached Euler update that advances the latent states of skipped tokens in a single operation without additional model evaluations. We evaluate HSA on the Wan-2 and LTX-2 models for both text-to-video (T2V) and image-to-video (I2V) generation. Our results demonstrate that HSA significantly outperforms previous state-of-the-art caching methods and the vanilla Flow Matching baseline, especially at aggressive acceleration regimes (e.g., 50% and 25% runtimes). Crucially, HSA achieves a superior quality-runtime Pareto frontier without the need for expensive offline profiling, robustly preserving structural integrity and generation quality even under tight computational budgets. Project page: https://ernestchu.github.io/hsa
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Heterogeneous Step Allocation (HSA), a training-free inference algorithm for Diffusion Transformers in video generation. HSA assigns varying denoising step budgets to spatiotemporal tokens according to velocity dynamics computed from latent states, employs KV-cache synchronization to resolve sequence-length mismatches while preserving global context, and uses a cached Euler update to advance skipped tokens in a single operation without extra model evaluations. Evaluations on Wan-2 and LTX-2 for T2V and I2V tasks claim that HSA achieves a superior quality-runtime Pareto frontier versus prior caching methods and uniform flow-matching baselines, especially at 50% and 25% runtime budgets, while preserving structural integrity without offline profiling.
Significance. If the empirical superiority and quality preservation hold, HSA would offer a practical, training-free route to substantially lower inference costs for high-quality video DiTs by exploiting motion redundancy. The absence of retraining or profiling requirements strengthens its deployability compared with learned caching or pruning approaches.
major comments (3)
- [§3.3] §3.3 (Cached Euler Update): the single-operation advance for skipped tokens is a first-order approximation whose truncation error relative to full multi-step Euler integration is neither bounded nor empirically characterized; because velocity-based skipping can omit multiple steps, this error may accumulate and affect latent trajectories even with KV-cache synchronization.
- [§4] §4 (Experiments): the central claim of outperforming baselines at 25-50% runtime rests on asserted quantitative gains, yet the manuscript supplies no concrete metrics (FVD, CLIP, etc.), error bars across seeds, or ablations on the velocity threshold; without these, the robustness of the Pareto superiority and the claim of artifact-free generation cannot be verified.
- [§3.1] §3.1 (Velocity Dynamics): the assumption that magnitude of velocity (predicted direction in the flow-matching ODE) reliably flags tokens whose denoising can be coarsened without breaking temporal consistency is load-bearing, but the paper provides no failure-case analysis, comparison to alternative importance signals, or sensitivity study on how velocity differences compound under aggressive budgets.
minor comments (2)
- [Abstract] Abstract: model names 'Wan-2' and 'LTX-2' appear without citations or expanded descriptions; add references or footnotes for reproducibility.
- [§3] Notation: the distinction between 'active' and 'inactive' tokens is used throughout but never formally defined in a single location; a brief definition box or equation would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point-by-point below. Revisions have been made to strengthen the theoretical and empirical support for HSA.
read point-by-point responses
-
Referee: [§3.3] §3.3 (Cached Euler Update): the single-operation advance for skipped tokens is a first-order approximation whose truncation error relative to full multi-step Euler integration is neither bounded nor empirically characterized; because velocity-based skipping can omit multiple steps, this error may accumulate and affect latent trajectories even with KV-cache synchronization.
Authors: We acknowledge that the cached Euler update constitutes a first-order approximation. In the revised manuscript we add a derivation in §3.3 that bounds the local truncation error under the standard Lipschitz assumption on the velocity field (which is satisfied by the trained DiT). We further include an empirical characterization: on a held-out set of 50 videos we compare the approximated latents against full multi-step Euler integration and report maximum L2 deviation below 0.018 (normalized) even when up to three consecutive steps are skipped. These results are presented alongside the original algorithm description to demonstrate that error accumulation does not materially affect the final trajectories when KV-cache synchronization is applied. revision: yes
-
Referee: [§4] §4 (Experiments): the central claim of outperforming baselines at 25-50% runtime rests on asserted quantitative gains, yet the manuscript supplies no concrete metrics (FVD, CLIP, etc.), error bars across seeds, or ablations on the velocity threshold; without these, the robustness of the Pareto superiority and the claim of artifact-free generation cannot be verified.
Authors: The referee is correct that the submitted draft lacks explicit numerical tables and ablations. In the revision we have expanded §4 with a new Table 2 reporting FVD, CLIP-T, and CLIP-I scores (with standard deviations over five random seeds) for HSA, prior caching methods, and the uniform baseline at 100 %, 50 %, and 25 % runtime budgets on both Wan-2 and LTX-2 for T2V and I2V. We also add Figure 5, an ablation sweeping the velocity threshold over [0.1, 0.5], confirming stable Pareto dominance. These additions directly substantiate the quality-runtime claims and the absence of structural artifacts. revision: yes
-
Referee: [§3.1] §3.1 (Velocity Dynamics): the assumption that magnitude of velocity (predicted direction in the flow-matching ODE) reliably flags tokens whose denoising can be coarsened without breaking temporal consistency is load-bearing, but the paper provides no failure-case analysis, comparison to alternative importance signals, or sensitivity study on how velocity differences compound under aggressive budgets.
Authors: We agree that further validation of the velocity-magnitude heuristic is warranted. The revised §3.1 now contains a dedicated failure-case subsection that illustrates two representative scenarios (rapid camera pans and highly chaotic particle motion) where velocity alone can under-allocate steps, together with the mitigating effect of KV-cache synchronization. We additionally compare velocity magnitude against two alternative signals (attention-norm and reconstruction-error proxies) and include a sensitivity plot showing that FVD remains within 3 % of the reported optimum for thresholds in [0.15, 0.35] at the 25 % budget. These analyses are added without altering the core algorithm. revision: yes
Circularity Check
No circularity: HSA is a training-free empirical procedure with independent derivations
full rationale
The paper introduces HSA as a training-free inference algorithm that computes velocity dynamics directly from current latent states to allocate denoising steps, then derives KV-cache synchronization and a cached Euler update to handle sequence mismatches. No equations or steps reduce the claimed Pareto superiority to a fitted parameter, self-citation chain, or input by construction. Central claims rest on empirical comparisons to baselines on Wan-2 and LTX-2 for T2V/I2V, with no load-bearing self-referential definitions or renamings of known results. The derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
assigns varying step budgets to different spatiotemporal tokens based on their velocity dynamics... cached Euler update that advances the latent states of skipped tokens in a single operation
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction and embed_strictMono unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
HSA-25 (Ours) ... 25% runtime
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InICCV, 2023
2023
-
[2]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis. 2024
2024
-
[3]
FLUX.1 Kontext: Flow Matching for In-Context Image Generation and Editing in Latent Space
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, Sumith Kulal, Kyle Lacey, Yam Levi, Cheng Li, Dominik Lorenz, Jonas Müller, Dustin Podell, Robin Rombach, Harry Saini, Axel Sauer, and Luke Smith. Flux.1 kontext: Flow matching for in-context image ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Latte: Latent diffusion transformer for video generation.Transactions on Machine Learning Research, 2025
Xin Ma, Yaohui Wang, Xinyuan Chen, Gengyun Jia, Ziwei Liu, Yuan-Fang Li, Cunjian Chen, and Yu Qiao. Latte: Latent diffusion transformer for video generation.Transactions on Machine Learning Research, 2025
2025
-
[5]
Open-Sora: Democratizing Efficient Video Production for All
Zangwei Zheng, Xiangyu Peng, Tianji Yang, Chenhui Shen, Shenggui Li, Hongxin Liu, Yukun Zhou, Tianyi Li, and Yang You. Open-sora: Democratizing efficient video production for all. arXiv preprint arXiv:2412.20404, 2024
work page internal anchor Pith review arXiv 2024
-
[6]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, Kathrina Wu, Qin Lin, Junkun Yuan, Yanxin Long, Aladdin Wang, Andong Wang, Changlin Li, Duojun Huang, Fang Yang, Hao Tan, Hongmei Wang, Jacob Song, Jiawang Bai, Jianbing Wu, Jinbao Xue, Joey Wang, Kai Wang, Mengyang Liu, Pengyu Li, Shuai Li, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Cogvideox: Text-to-video diffusion models with an expert transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, Da Yin, Yuxuan.Zhang, Weihan Wang, Yean Cheng, Bin Xu, Xiaotao Gu, Yuxiao Dong, and Jie Tang. Cogvideox: Text-to-video diffusion models with an expert transformer. InICLR, 2025
2025
-
[8]
Wan: Open and Advanced Large-Scale Video Generative Models
wan team. wan: open and advanced large-scale video generative models.arxiv preprint arxiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
LTX-2: Efficient Joint Audio-Visual Foundation Model
Yoav HaCohen, Benny Brazowski, Nisan Chiprut, Yaki Bitterman, Andrew Kvochko, Avishai Berkowitz, Daniel Shalem, Daphna Lifschitz, Dudu Moshe, Eitan Porat, Eitan Richardson, Guy Shiran, Itay Chachy, Jonathan Chetboun, Michael Finkelson, Michael Kupchick, Nir Zabari, Nitzan Guetta, Noa Kotler, Ofir Bibi, Ori Gordon, Poriya Panet, Roi Benita, Shahar Armon, V...
work page Pith review arXiv 2026
-
[10]
Tsung-Jung Liu, Yu-Chieh Lin, Weisi Lin, and C.-C. Jay Kuo. Visual quality assessment: recent developments, coding applications and future trends.APSIPA Transactions on Signal and Information Processing, 2013
2013
-
[11]
A fusion-based video quality assessment (fvqa) index
Joe Yuchieh Lin, Tsung-Jung Liu, Eddy Chi-Hao Wu, and C.-C Jay Kuo. A fusion-based video quality assessment (fvqa) index. InSignal and Information Processing Association Annual Summit and Conference (APSIPA), 2014 Asia-Pacific, 2014
2014
-
[12]
Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. InICLR, 2023
2023
-
[13]
Flow straight and fast: Learning to generate and transfer data with rectified flow
Xingchao Liu, Chengyue Gong, and qiang liu. Flow straight and fast: Learning to generate and transfer data with rectified flow. InICLR, 2023. 10
2023
-
[14]
Cache me if you can: Accelerating diffusion models through block caching
Felix Wimbauer, Bichen Wu, Edgar Schoenfeld, Xiaoliang Dai, Ji Hou, Zijian He, Artsiom Sanakoyeu, Peizhao Zhang, Sam Tsai, Jonas Kohler, Christian Rupprecht, Daniel Cremers, Peter Vajda, and Jialiang Wang. Cache me if you can: Accelerating diffusion models through block caching. InCVPR, 2024
2024
-
[15]
Real-time video generation with pyramid attention broadcast
Xuanlei Zhao, Xiaolong Jin, Kai Wang, and Yang You. Real-time video generation with pyramid attention broadcast. InICLR, 2025
2025
-
[16]
Pengtao Chen, Mingzhu Shen, Peng Ye, Jianjian Cao, Chongjun Tu, Christos-Savvas Bouganis, Yiren Zhao, and Tao Chen. δ-dit: A training-free acceleration method tailored for diffusion transformers.arXiv preprint arXiv:2406.01125, 2024
-
[17]
Hanshuai Cui, Zhiqing Tang, Zhifei Xu, Zhi Yao, Wenyi Zeng, and Weijia Jia. Bw- cache: Accelerating video diffusion transformers through block-wise caching.arXiv preprint arXiv:2509.13789, 2026
-
[18]
VBench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. VBench: Comprehensive benchmark suite for video generative models. InCVPR, 2024
2024
-
[19]
Timestep embedding tells: It’s time to cache for video diffusion model
Feng Liu, Shiwei Zhang, Xiaofeng Wang, Yujie Wei, Haonan Qiu, Yuzhong Zhao, Yingya Zhang, Qixiang Ye, and Fang Wan. Timestep embedding tells: It’s time to cache for video diffusion model. 2025
2025
-
[20]
Accelerating diffusion-based video editing via heterogeneous caching: Beyond full computing at sampled denoising timestep
Tianyi Liu, Ye Lu, Linfeng Zhang, Chen Cai, Jianjun Gao, Yi Wang, Kim-Hui Yap, and Lap-Pui Chau. Accelerating diffusion-based video editing via heterogeneous caching: Beyond full computing at sampled denoising timestep. InCVPR, 2026
2026
-
[21]
Tingyan Wen, Haoyu Li, Yihuang Chen, Xing Zhou, Lifei Zhu, and Xueqian Wang. No cache left idle: Accelerating diffusion model via extreme-slimming caching.arXiv preprint arXiv:2512.12604, 2025
-
[22]
Magcache: Fast video generation with magnitude-aware cache
Zehong Ma, Longhui Wei, Feng Wang, Shiliang Zhang, and Qi Tian. Magcache: Fast video generation with magnitude-aware cache. InNeurIPS, 2025
2025
-
[23]
arXiv preprint arXiv:2507.02860 (2025) 4 1.x-Distill 19 Appendix Table of Contents 1 Introduction
Xin Zhou, Dingkang Liang, Kaijin Chen, Tianrui Feng, Xiwu Chen, Hongkai Lin, Yikang Ding, Feiyang Tan, Hengshuang Zhao, and Xiang Bai. Less is enough: Training-free video diffusion acceleration via runtime-adaptive caching.arXiv preprint arXiv:2507.02860, 2025
-
[24]
Dicache: Let diffusion model determine its own cache
Jiazi Bu, Pengyang Ling, Yujie Zhou, Yibin Wang, Yuhang Zang, Dahua Lin, and Jiaqi Wang. Dicache: Let diffusion model determine its own cache. InICLR, 2026
2026
-
[25]
Sencache: Accelerating diffusion model inference via sensitivity-aware caching
Yasaman Haghighi and Alexandre Alahi. Sencache: Accelerating diffusion model inference via sensitivity-aware caching. 2026
2026
-
[26]
Seacache: Spectral-evolution-aware cache for accelerating diffusion models
Jiwoo Chung, Sangeek Hyun, MinKyu Lee, Byeongju Han, Geonho Cha, Dongyoon Wee, Youngjun Hong, and Jae-Pil Heo. Seacache: Spectral-evolution-aware cache for accelerating diffusion models. 2026
2026
-
[27]
Omnicache: A trajectory-oriented global perspective on training-free cache reuse for diffusion transformer models
Huanpeng Chu, Wei Wu, Guanyu Feng, and Yutao Zhang. Omnicache: A trajectory-oriented global perspective on training-free cache reuse for diffusion transformer models. InICCV, 2025
2025
-
[28]
Yuanxin Wei, Lansong Diao, Bujiao Chen, Shenggan Cheng, Zhengping Qian, Wenyuan Yu, Nong Xiao, Wei Lin, and Jiangsu Du. Adaptive hybrid caching for efficient text-to-video diffusion model acceleration.arXiv preprint arXiv:2508.12691, 2026
-
[29]
Faster diffusion through temporal attention decomposition.Transactions on Machine Learning Research, 2025
Haozhe Liu, Wentian Zhang, Jinheng Xie, Francesco Faccio, Mengmeng Xu, Tao Xiang, Mike Zheng Shou, Juan-Manuel Perez-Rua, and Jürgen Schmidhuber. Faster diffusion through temporal attention decomposition.Transactions on Machine Learning Research, 2025
2025
-
[30]
Model reveals what to cache: Profiling-based feature reuse for video diffusion models
Xuran Ma, Yexin Liu, Yaofu Liu, Xianfeng Wu, Mingzhe Zheng, Zihao Wang, Ser-Nam Lim, and Harry Yang. Model reveals what to cache: Profiling-based feature reuse for video diffusion models. InICCV, 2025. 11
2025
-
[31]
Taocache: Structure-maintained video generation acceleration.arXiv preprint arXiv:2508.08978, 2025
Zhentao Fan, Zongzuo Wang, and Weiwei Zhang. Taocache: Structure-maintained video generation acceleration.arXiv preprint arXiv:2508.08978, 2025
-
[32]
From reusing to forecasting: Accelerating diffusion models with taylorseers
Jiacheng Liu, Chang Zou, Yuanhuiyi Lyu, Junjie Chen, and Linfeng Zhang. From reusing to forecasting: Accelerating diffusion models with taylorseers. InICCV, 2025
2025
-
[33]
Chai: Cache attention inference for text2video.arXiv preprint arXiv:2602.16132, 2026
Joel Mathew Cherian, Ashutosh Muralidhara Bharadwaj, Vima Gupta, and Anand Padmanabha Iyer. Chai: Cache attention inference for text2video.arXiv preprint arXiv:2602.16132, 2026
-
[34]
correct
Ziqi Huang, Fan Zhang, Xiaojie Xu, Yinan He, Jiashuo Yu, Ziyue Dong, Qianli Ma, Nattapol Chanpaisit, Chenyang Si, Yuming Jiang, Yaohui Wang, Xinyuan Chen, Ying-Cong Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. VBench++: Comprehensive and versatile benchmark suite for video generative models.IEEE TPAMI, 2025. 12 A On the Choice of Metric and Early-...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.