Recognition: unknown
Retrieve, Integrate, and Synthesize: Spatial-Semantic Grounded Latent Visual Reasoning
Pith reviewed 2026-05-11 01:09 UTC · model grok-4.3
The pith
Multimodal language models can reason in continuous hidden states without drifting from their pretrained circuits when latent tokens are anchored to spatial locations and region-specific semantics.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
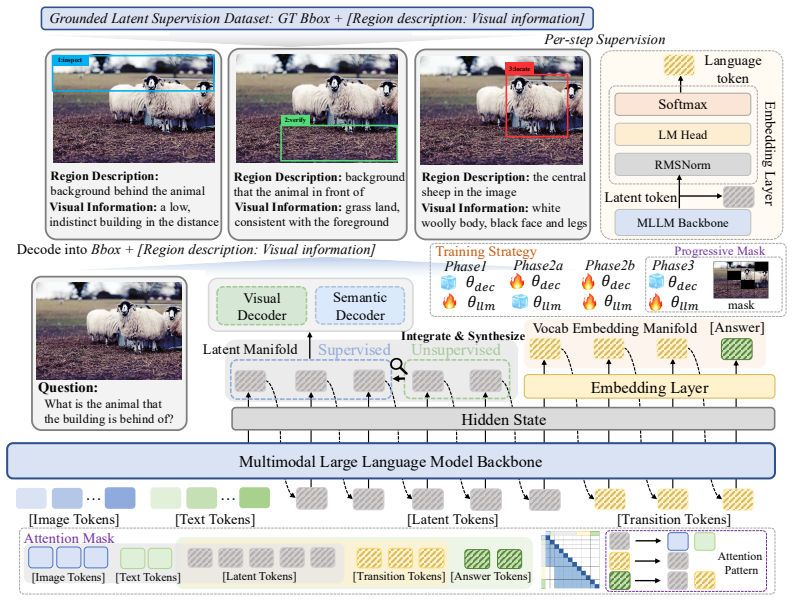
RIS develops latent reasoning as a compatible extension of pretrained MLLM computation. It anchors latent tokens to both spatial and semantic evidence from a constructed step-wise grounded reasoning dataset, enforces their causal role through a progressive attention bottleneck, and introduces short language transition tokens to bridge synthesized latent states back to vocabulary-aligned decoding, yielding consistent gains over baselines on V*, HRBench4K, HRBench8K, MMVP, and BLINK.
What carries the argument
The RIS process of anchoring latent tokens to spatial-semantic evidence, enforced by a progressive attention bottleneck and bridged by language transition tokens.
If this is right
- Latent trajectories become more diverse and progressively integrated across reasoning steps.
- Models show measurable accuracy lifts on benchmarks that test fine-grained visual perception and reasoning.
- Internal visual reasoning becomes more faithful because the latent states remain causally linked to specific image regions.
- The method serves as a practical extension that does not require changing the base MLLM architecture.
Where Pith is reading between the lines
- Similar anchoring techniques could be applied to other continuous-state reasoning domains such as audio or video sequences.
- The use of short transition tokens might generalize to other places where hidden-state outputs need to re-enter discrete language decoding.
- If the dataset construction scales, it could reduce dependence on purely textual chain-of-thought prompting for vision tasks.
Load-bearing premise
A step-wise grounded reasoning dataset with bounding boxes and region descriptions can be built and used to train latent trajectories that stay compatible with pretrained circuits and are not bypassed at answer time.
What would settle it
Training the model with the RIS dataset and mechanisms yet still observing latent trajectories that collapse to instance-agnostic patterns or get bypassed during final decoding on the reported benchmarks.
Figures







read the original abstract
Multimodal Large Language Models (MLLMs) have made remarkable progress on vision-language reasoning, yet most methods still compress visual evidence into discrete textual thoughts, creating an information bottleneck for fine-grained perception. Recent latent visual reasoning methods attempt to reason in continuous hidden states, but we find that they suffer from insufficient manifold compatibility: latent trajectories drift away from pretrained reasoning circuits, collapse into instance-agnostic patterns, and are often bypassed during answer generation. To address these issues, we propose RIS (Retrieve, Integrate, and Synthesize), a spatial-semantic grounded framework that develops latent reasoning as a compatible extension of pretrained MLLM computation. We first construct a step-wise grounded reasoning dataset with bounding boxes and region-specific semantic descriptions. Built on this supervision, RIS anchors latent tokens to both spatial and semantic evidence, enforces their causal role through a progressive attention bottleneck, and introduces short language transition tokens to bridge synthesized latent states back to vocabulary-aligned decoding. Experiments on V*, HRBench4K, HRBench8K, MMVP, and BLINK show consistent improvements over closed/open-source and latent reasoning baselines. Further analyses demonstrate that RIS learns diverse, interpretable, and progressively integrated latent trajectories, offering a practical path toward faithful internal visual reasoning in MLLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RIS (Retrieve, Integrate, and Synthesize), a spatial-semantic grounded framework for latent visual reasoning in MLLMs. It constructs a step-wise grounded reasoning dataset using bounding boxes and region-specific semantic descriptions, then anchors latent tokens to spatial and semantic evidence, enforces their causal role via a progressive attention bottleneck, and introduces short language transition tokens to bridge synthesized latent states to vocabulary-aligned decoding. The approach aims to mitigate manifold incompatibility, trajectory collapse, and bypassing issues in prior latent reasoning methods. Experiments report consistent improvements over closed- and open-source MLLM baselines as well as other latent reasoning approaches on V*, HRBench4K, HRBench8K, MMVP, and BLINK, with further analyses indicating diverse, interpretable, and progressively integrated latent trajectories.
Significance. If the empirical gains and mechanistic claims are substantiated, the work would offer a practical route to faithful internal visual reasoning in MLLMs by extending pretrained circuits rather than replacing them with text-based bottlenecks. The combination of grounded supervision, attention-based causal enforcement, and transition tokens addresses a recognized limitation in current latent reasoning approaches and could improve fine-grained perception tasks. The emphasis on interpretability of latent trajectories is a positive contribution if verified through the promised analyses.
major comments (3)
- [Abstract] Abstract: The abstract reports benchmark gains on V*, HRBench4K, HRBench8K, MMVP, and BLINK but supplies no quantitative details on baseline performances, effect sizes, statistical tests, ablation controls, or error analysis. This omission is load-bearing for the central claim that the RIS mechanisms (rather than the new dataset alone) produce the improvements.
- [Method description (RIS framework)] Method description (RIS framework): The claim that the progressive attention bottleneck enforces the causal role of latent tokens and prevents bypass during answer generation lacks supporting quantitative evidence such as attention mass on latent tokens, hidden-state similarity metrics to pretrained paths, or intervention/ablation results. Without these checks, it is unclear whether the synthesized states remain manifold-compatible or are simply ignored once transition tokens appear.
- [Dataset construction section] Dataset construction section: The step-wise grounded reasoning dataset with bounding boxes and region-specific semantic descriptions is described only at a high level. Specifics on construction procedure, scale, quality controls, and how the supervision is injected during training are required to verify that the resulting latent trajectories avoid collapse and remain compatible with pretrained MLLM circuits.
minor comments (1)
- The abstract and method sections would benefit from explicit references or brief characterizations of the benchmark datasets (V*, HRBench4K, etc.) for readers outside the immediate subfield.
Simulated Author's Rebuttal
Thank you for the detailed and constructive feedback on our manuscript. We appreciate the referee's recognition of the potential significance of our work on spatial-semantic grounded latent visual reasoning. Below, we provide point-by-point responses to the major comments and describe the revisions we plan to make in the updated version of the paper.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract reports benchmark gains on V*, HRBench4K, HRBench8K, MMVP, and BLINK but supplies no quantitative details on baseline performances, effect sizes, statistical tests, ablation controls, or error analysis. This omission is load-bearing for the central claim that the RIS mechanisms (rather than the new dataset alone) produce the improvements.
Authors: We agree that the abstract would benefit from more quantitative details to support our claims. Due to abstract length limits, we will revise it to highlight key effect sizes and gains (e.g., specific percentage improvements over baselines on each benchmark) and reference the ablation studies that show the RIS mechanisms contribute beyond the dataset. Full details on baselines, effect sizes, statistical tests, ablations, and error analysis will be expanded in the main text and supplementary material. This revision will clarify that the improvements are due to the proposed framework. revision: partial
-
Referee: [Method description (RIS framework)] Method description (RIS framework): The claim that the progressive attention bottleneck enforces the causal role of latent tokens and prevents bypass during answer generation lacks supporting quantitative evidence such as attention mass on latent tokens, hidden-state similarity metrics to pretrained paths, or intervention/ablation results. Without these checks, it is unclear whether the synthesized states remain manifold-compatible or are simply ignored once transition tokens appear.
Authors: We appreciate this comment and will strengthen the evidence for the attention bottleneck's role. In the revised manuscript, we will add quantitative results including attention mass on latent tokens (e.g., average attention weights per layer), hidden-state similarity metrics to pretrained MLLM paths, and ablation/intervention experiments showing performance drops when the bottleneck is removed. These will be included in the method and analysis sections to confirm that the synthesized latent states are manifold-compatible and causally influence the output rather than being bypassed. revision: yes
-
Referee: [Dataset construction section] Dataset construction section: The step-wise grounded reasoning dataset with bounding boxes and region-specific semantic descriptions is described only at a high level. Specifics on construction procedure, scale, quality controls, and how the supervision is injected during training are required to verify that the resulting latent trajectories avoid collapse and remain compatible with pretrained MLLM circuits.
Authors: We agree that more details are necessary. We will revise the dataset construction section to provide a comprehensive description, including the exact procedure for generating bounding boxes and semantic descriptions (using automated tools with human oversight), the dataset scale (number of examples and reasoning steps), quality control processes (filtering criteria and verification on samples), and the training injection method (specific loss terms and how they anchor the latent tokens). This will enable better verification of the trajectory properties. revision: yes
Circularity Check
No circularity; empirical method with independent experimental validation
full rationale
The paper proposes the RIS framework as a training procedure that constructs a step-wise grounded dataset and applies components including spatial-semantic anchoring, progressive attention bottleneck, and language transition tokens. All central claims are presented as empirical outcomes measured on external benchmarks (V*, HRBench4K, HRBench8K, MMVP, BLINK) against baselines, with no equations, parameter-fitting steps, or derivations shown that reduce to self-definition or self-citation. The abstract and description frame improvements as results of the new procedure rather than predictions forced by inputs. No load-bearing self-citations, ansatzes smuggled via prior work, or renaming of known results appear. The derivation chain is therefore self-contained as an engineering contribution validated externally.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
work page 2022
-
[2]
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners.Advances in neural information processing systems, 35:22199–22213, 2022
work page 2022
-
[3]
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language- image pre-training for unified vision-language understanding and generation. InInternational conference on machine learning, pages 12888–12900. PMLR, 2022. 10
work page 2022
-
[4]
Thinking with Images for Multimodal Reasoning: Foundations, Methods, and Future Frontiers
Zhaochen Su, Peng Xia, Hangyu Guo, Zhenhua Liu, Yan Ma, Xiaoye Qu, Jiaqi Liu, Yanshu Li, Kaide Zeng, Zhengyuan Yang, et al. Thinking with images for multimodal reasoning: Foundations, methods, and future frontiers.arXiv preprint arXiv:2506.23918, 2025
work page internal anchor Pith review arXiv 2025
-
[5]
MM-REACT: Prompting ChatGPT for Multimodal Reasoning and Action
Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Ehsan Azarnasab, Faisal Ahmed, Zicheng Liu, Ce Liu, Michael Zeng, and Lijuan Wang. Mm-react: Prompting chatgpt for multimodal reasoning and action.arXiv preprint arXiv:2303.11381, 2023
work page internal anchor Pith review arXiv 2023
-
[6]
Llava-plus: Learning to use tools for creating multimodal agents
Shilong Liu, Hao Cheng, Haotian Liu, Hao Zhang, Feng Li, Tianhe Ren, Xueyan Zou, Jianwei Yang, Hang Su, Jun Zhu, et al. Llava-plus: Learning to use tools for creating multimodal agents. InEuropean conference on computer vision, pages 126–142. Springer, 2024
work page 2024
-
[7]
Zifu Wang, Junyi Zhu, Bo Tang, Zhiyu Li, Feiyu Xiong, Jiaqian Yu, and Matthew B Blaschko. Jigsaw-r1: A study of rule-based visual reinforcement learning with jigsaw puzzles.arXiv preprint arXiv:2505.23590, 2025
-
[8]
Visual programming: Compositional visual reasoning without training
Tanmay Gupta and Aniruddha Kembhavi. Visual programming: Compositional visual reasoning without training. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14953–14962, 2023
work page 2023
-
[9]
Vipergpt: Visual inference via python execution for reasoning
Dídac Surís, Sachit Menon, and Carl V ondrick. Vipergpt: Visual inference via python execution for reasoning. InProceedings of the IEEE/CVF international conference on computer vision, pages 11888–11898, 2023
work page 2023
-
[10]
Yushi Hu, Otilia Stretcu, Chun-Ta Lu, Krishnamurthy Viswanathan, Kenji Hata, Enming Luo, Ranjay Krishna, and Ariel Fuxman. Visual program distillation: Distilling tools and program- matic reasoning into vision-language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9590–9601, 2024
work page 2024
-
[11]
Xinlei Yu, Zhangquan Chen, Yongbo He, Tianyu Fu, Cheng Yang, Chengming Xu, Yue Ma, Xiaobin Hu, Zhe Cao, Jie Xu, et al. The latent space: Foundation, evolution, mechanism, ability, and outlook.arXiv preprint arXiv:2604.02029, 2026
-
[12]
Latent visual reasoning.arXiv preprint arXiv:2509.24251, 2025a
Bangzheng Li, Ximeng Sun, Jiang Liu, Ze Wang, Jialian Wu, Xiaodong Yu, Hao Chen, Emad Barsoum, Muhao Chen, and Zicheng Liu. Latent visual reasoning.arXiv preprint arXiv:2509.24251, 2025
-
[13]
Qixun Wang, Yang Shi, Yifei Wang, Yuanxing Zhang, Pengfei Wan, Kun Gai, Xianghua Ying, and Yisen Wang. Monet: Reasoning in latent visual space beyond images and language.arXiv preprint arXiv:2511.21395, 2025
-
[14]
You Li, Chi Chen, Yanghao Li, Fanhu Zeng, Kaiyu Huang, Jinan Xu, and Maosong Sun. Imagination helps visual reasoning, but not yet in latent space.arXiv preprint arXiv:2602.22766, 2026
-
[15]
Multimodal Chain-of-Thought Reasoning in Language Models
Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, and Alex Smola. Mul- timodal chain-of-thought reasoning in language models.arXiv preprint arXiv:2302.00923, 2023
work page internal anchor Pith review arXiv 2023
-
[16]
Mul- timodal chain-of-thought reasoning: A comprehensive survey,
Yaoting Wang, Shengqiong Wu, Yuecheng Zhang, Shuicheng Yan, Ziwei Liu, Jiebo Luo, and Hao Fei. Multimodal chain-of-thought reasoning: A comprehensive survey.arXiv preprint arXiv:2503.12605, 2025
-
[17]
Training Large Language Models to Reason in a Continuous Latent Space
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space.arXiv preprint arXiv:2412.06769, 2024
work page internal anchor Pith review arXiv 2024
-
[18]
Codi: Com- pressing chain-of-thought into continuous space via self-distillation
Zhenyi Shen, Hanqi Yan, Linhai Zhang, Zhanghao Hu, Yali Du, and Yulan He. Codi: Com- pressing chain-of-thought into continuous space via self-distillation. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 677–693, 2025
work page 2025
-
[19]
LLM latent reasoning as chain of superposition
Jingcheng Deng, Liang Pang, Zihao Wei, Shicheng Xu, Zenghao Duan, Kun Xu, Yang Song, Huawei Shen, and Xueqi Cheng. Llm latent reasoning as chain of superposition, 2026. URL https://arxiv.org/abs/2510.15522. 11
-
[20]
Zeyuan Yang, Xueyang Yu, Delin Chen, Maohao Shen, and Chuang Gan. Machine men- tal imagery: Empower multimodal reasoning with latent visual tokens.arXiv preprint arXiv:2506.17218, 2025
-
[21]
Drew A. Hudson and Christopher D. Manning. Gqa: A new dataset for real-world vi- sual reasoning and compositional question answering.2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 6693–6702, 2019. URL https: //api.semanticscholar.org/CorpusID:152282269
work page 2019
-
[22]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, et al. Grounding dino: Marrying dino with grounded pre-training for open-set object detection.arXiv preprint arXiv:2303.05499, 2023
work page Pith review arXiv 2023
-
[23]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report,
-
[24]
URLhttps://arxiv.org/abs/2502.13923
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
Penghao Wu and Saining Xie. V*: Guided visual search as a core mechanism in multimodal llms. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13084–13094, 2024. doi: 10.1109/CVPR52733.2024.01243
-
[26]
Wenbin Wang, Liang Ding, Minyan Zeng, Xiabin Zhou, Li Shen, Yong Luo, Wei Yu, and Dacheng Tao. Divide, conquer and combine: A training-free framework for high-resolution image perception in multimodal large language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 7907–7915, 2025
work page 2025
-
[27]
Eyes wide shut? exploring the visual shortcomings of multimodal llms
Shengbang Tong, Zhuang Liu, Yuexiang Zhai, Yi Ma, Yann LeCun, and Saining Xie. Eyes wide shut? exploring the visual shortcomings of multimodal llms. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9568–9578, 2024
work page 2024
-
[28]
Blink: Multimodal large language models can see but not perceive
Xingyu Fu, Yushi Hu, Bangzheng Li, Yu Feng, Haoyu Wang, Xudong Lin, Dan Roth, Noah A Smith, Wei-Chiu Ma, and Ranjay Krishna. Blink: Multimodal large language models can see but not perceive. InEuropean Conference on Computer Vision, pages 148–166. Springer, 2024
work page 2024
-
[29]
Yiming Qin, Bomin Wei, Jiaxin Ge, Konstantinos Kallidromitis, Stephanie Fu, Trevor Darrell, and XuDong Wang. Chain-of-visual-thought: Teaching vlms to see and think better with continuous visual tokens.arXiv preprint arXiv:2511.19418, 2025. 12 A Limitations AlthoughRISprovides an effective framework for grounded latent visual reasoning, it still has sever...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.