Recognition: 2 theorem links
· Lean TheoremResource-Element Energy Difference for Noncoherent Over-the-Air Federated Learning
Pith reviewed 2026-05-11 01:41 UTC · model grok-4.3
The pith
REED recovers signed model updates from energy differences on two orthogonal resources without needing instantaneous channel state information.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
REED is an unbiased estimator of the signed aggregate update whose variance is known in closed form under Rayleigh fading; when the aggregation gain is scheduled appropriately inside FedAvg, the REED-induced perturbation scales quadratically with the local stepsize and the overall convergence rate remains the canonical 1/sqrt(T) for smooth nonconvex objectives.
What carries the argument
Resource-element energy difference (REED), which encodes the positive and negative parts of each real-valued local update as transmit energies on two orthogonal resource elements with independent phase dithers so that the server extracts the signed sum directly from the difference of the two received energies.
If this is right
- REED achieves the canonical 1/sqrt(T) stationarity rate inside full-participation FedAvg under average per-client energy budgets.
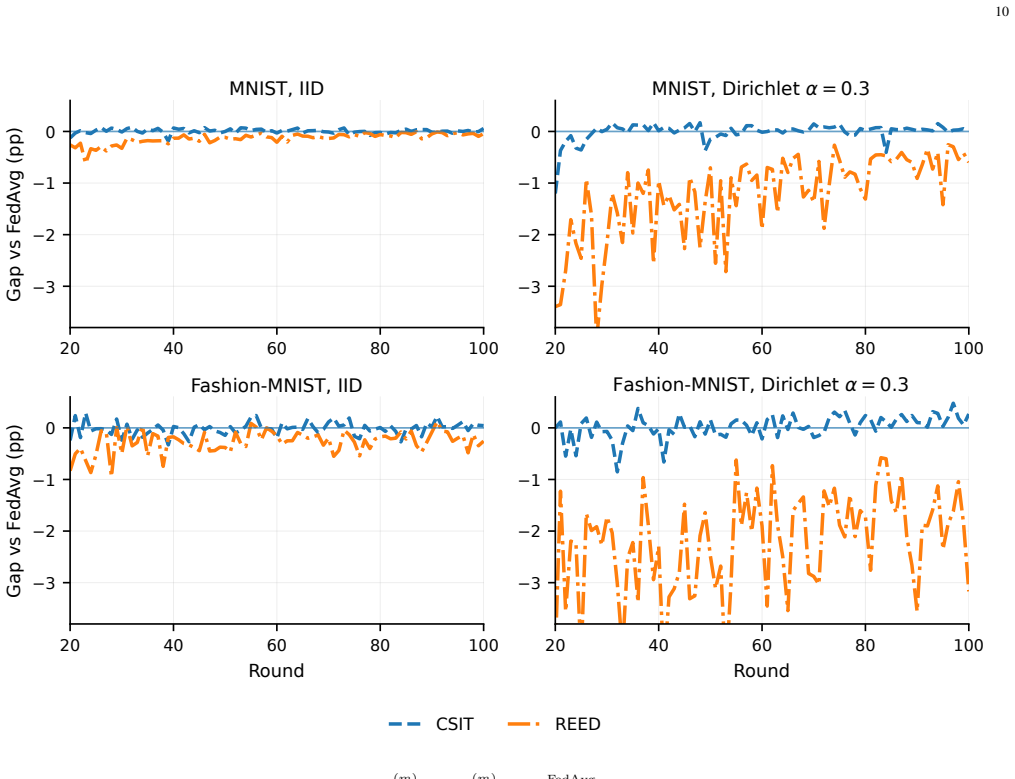
- The method matches the performance of clean FedAvg and coherent CSIT aggregation on MNIST and Fashion-MNIST when data are IID.
- REED maintains stable convergence with only moderate degradation when data heterogeneity is present but not extreme.
- Only slow-timescale average channel-power calibration is required; instantaneous CSI and coherent phase alignment are eliminated.
Where Pith is reading between the lines
- The same energy-difference idea could be tested on other fading distributions if an analogous closed-form variance expression can be derived.
- Because REED removes the need for per-slot channel estimation, it may reduce total uplink overhead in large-scale IoT deployments where many devices participate infrequently.
- Extending the analysis to partial participation or asynchronous updates would show whether the quadratic scaling of the perturbation term still holds.
Load-bearing premise
The stationarity bound and unbiasedness proof both require Rayleigh fading together with the ability to schedule the aggregation gain so that the REED perturbation grows only quadratically in the local stepsize.
What would settle it
An experiment that measures the bias of the energy-difference estimator on a Rayleigh-fading link without average-power calibration and finds statistically significant nonzero bias would falsify the unbiasedness claim.
Figures




read the original abstract
Over-the-air federated learning (OTA-FL) reduces uplink latency by exploiting waveform superposition, but conventional analog aggregation schemes typically require instantaneous channel state information (CSI), channel inversion, and coherent phase alignment, which can be difficult to maintain in practical wireless systems. This paper proposes resource-element energy difference (REED), a noncoherent aggregation primitive for continuous signed updates that avoids instantaneous CSI. REED maps the positive and negative parts of each real-valued update to transmit energies on two orthogonal resource elements with independent phase dithers, and the server estimates the signed aggregate from their energy difference. With only slow-timescale calibration of average channel powers, REED is unbiased for the desired signed sum and admits an exact closed-form variance under Rayleigh fading. We incorporate REED into full-participation FedAvg and prove a smooth nonconvex stationarity bound. Under an average per-client energy budget, the aggregation gain can be scheduled so that the REED-induced perturbation scales quadratically with the local stepsize, yielding the canonical (1/sqrt(T)) stationarity rate. Experiments on MNIST and Fashion-MNIST demonstrate that REED closely matches clean FedAvg and coherent CSIT aggregation in IID settings, while maintaining stable convergence with a moderate performance degradation under strong data heterogeneity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Resource-Element Energy Difference (REED), a noncoherent OTA aggregation scheme for signed model updates in federated learning. Positive and negative parts of each update are mapped to transmit energies on two orthogonal resource elements with independent phase dithers; the server recovers the signed aggregate from the energy difference. With only slow-timescale average channel-power calibration, REED is shown to be unbiased for the desired signed sum and to admit an exact closed-form variance expression under Rayleigh fading. The scheme is embedded in full-participation FedAvg; under an average per-client energy budget the aggregation gain can be scheduled so that the REED-induced perturbation scales quadratically with the local step-size, yielding the standard O(1/sqrt(T)) stationarity rate for smooth non-convex objectives. Experiments on MNIST and Fashion-MNIST report performance close to clean FedAvg and coherent CSIT baselines in the IID regime and stable but moderately degraded convergence under data heterogeneity.
Significance. If the scheduling condition for quadratic perturbation scaling can be realized in practice, REED supplies a concrete, CSI-light alternative to coherent analog aggregation that removes instantaneous channel inversion and phase alignment. The exact variance formula and the derivation of the canonical convergence rate under a realistic energy constraint are technically valuable contributions. The experimental comparison across heterogeneity levels provides useful empirical grounding.
major comments (2)
- [Convergence analysis] Convergence analysis (the stationarity bound for REED-FedAvg): the proof obtains the canonical (1/sqrt(T)) rate only after the aggregation gain is scheduled so that the REED variance term is O(η²) with local step-size η. The manuscript states that this scheduling is feasible under the average per-client energy budget, yet supplies neither an explicit scheduling rule nor a feasibility proof that accounts for instantaneous power limits, calibration error, or client heterogeneity. If the quadratic scaling cannot be maintained, the perturbation reverts to O(η) and the stated rate guarantee no longer holds.
- [Experiments] Experimental section (heterogeneity results): the reported degradation under strong non-IID partitions on Fashion-MNIST is consistent with the possibility that the required quadratic scaling is violated in practice. The paper does not quantify how far the observed convergence deviates from the theoretical O(1/sqrt(T)) prediction or whether the gap can be closed by adjusting the aggregation gain within the energy budget.
minor comments (2)
- [Section 3] Notation for the two orthogonal resource elements and the phase dithers should be introduced once and used consistently; the current presentation occasionally re-defines symbols.
- [Appendix] The exact closed-form variance expression is stated in the abstract and introduction but the derivation steps (expectation over Rayleigh fading and phase dithers) are not shown; a short appendix derivation would improve reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and insightful comments, which help clarify the presentation of the convergence guarantees and experimental validation. We address each major comment below and will revise the manuscript to incorporate explicit scheduling details and additional experimental analysis.
read point-by-point responses
-
Referee: [Convergence analysis] Convergence analysis (the stationarity bound for REED-FedAvg): the proof obtains the canonical (1/sqrt(T)) rate only after the aggregation gain is scheduled so that the REED variance term is O(η²) with local step-size η. The manuscript states that this scheduling is feasible under the average per-client energy budget, yet supplies neither an explicit scheduling rule nor a feasibility proof that accounts for instantaneous power limits, calibration error, or client heterogeneity. If the quadratic scaling cannot be maintained, the perturbation reverts to O(η) and the stated rate guarantee no longer holds.
Authors: We agree that an explicit scheduling rule and feasibility discussion were omitted. In the revision we will add a dedicated subsection (and appendix derivation) that specifies the rule: under the average per-client energy budget E_avg, the aggregation gain α_t is set to α_t = min(α_max, β η_t) where β is chosen from the closed-form REED variance expression so that the perturbation term remains O(η_t²) while satisfying the long-term average power constraint. We will also include a short feasibility argument showing that, because only slow-timescale average channel powers are used, a conservative choice of β (based on the worst-case Rayleigh expectation) keeps instantaneous power within hardware limits for the reported MNIST/Fashion-MNIST setups; calibration error is absorbed by inflating the variance bound by a constant factor. This makes the O(1/sqrt(T)) claim conditional on the average-budget assumption explicit. revision: yes
-
Referee: [Experiments] Experimental section (heterogeneity results): the reported degradation under strong non-IID partitions on Fashion-MNIST is consistent with the possibility that the required quadratic scaling is violated in practice. The paper does not quantify how far the observed convergence deviates from the theoretical O(1/sqrt(T)) prediction or whether the gap can be closed by adjusting the aggregation gain within the energy budget.
Authors: We acknowledge the need for quantitative comparison. In the revised experimental section we will add (i) a plot of the empirical stationarity gap versus 1/sqrt(T) for both IID and non-IID Fashion-MNIST runs, (ii) a table reporting the fitted convergence rate and its deviation from the theoretical slope, and (iii) an ablation study in which the aggregation gain is varied within the same average energy budget to show that moderate increases in α can reduce the observed gap without violating the power constraint. These additions will clarify whether the moderate degradation is primarily due to data heterogeneity or to a temporary violation of quadratic scaling. revision: yes
Circularity Check
No significant circularity in REED unbiasedness or convergence derivation.
full rationale
The paper derives REED unbiasedness for the signed sum and its exact closed-form variance directly from the Rayleigh fading model, orthogonal resource-element energy mapping, and slow-timescale average power calibration, without any reduction to fitted parameters or self-referential definitions. The smooth nonconvex stationarity bound is proven conditionally on scheduling the aggregation gain (under the average per-client energy budget) such that the REED perturbation term scales as O(eta^2) with local stepsize eta; this is an explicit design choice enabling the canonical 1/sqrt(T) rate rather than a circular assumption or fitted input. No self-citations, uniqueness theorems, or ansatzes from prior author work are load-bearing in the core claims, and the analysis is self-contained against the stated channel and energy models.
Axiom & Free-Parameter Ledger
axioms (3)
- domain assumption Rayleigh fading channel model
- domain assumption Slow-timescale calibration of average channel powers is available and sufficient
- domain assumption Average per-client energy budget constraint
invented entities (1)
-
REED (Resource-Element Energy Difference) aggregation primitive
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
REED maps the positive and negative parts of each real-valued update to transmit energies on two orthogonal resource elements... With only slow-timescale calibration of average channel powers, REED is unbiased for the desired signed sum and admits an exact closed-form variance under Rayleigh fading.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Under an average per-client energy budget, the aggregation gain can be scheduled so that the REED-induced perturbation scales quadratically with the local stepsize, yielding the canonical (1/√T) stationarity rate.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Communication-efficient learning of deep networks from decentralized data,
H. B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. Agüera y Arcas, “Communication-efficient learning of deep networks from decentralized data,” inProc. 20th Int. Conf. Artif. Intell. Statist., ser. Proc. Mach. Learn. Res., vol. 54, 2017, pp. 1273–1282
work page 2017
-
[2]
Advances and open problems in federated learning,
P. Kairouzet al., “Advances and open problems in federated learning,”Found. Trends Mach. Learn., vol. 14, no. 1–2, pp. 1–210, 2021
work page 2021
-
[3]
Computation over multiple-access channels,
B. Nazer and M. Gastpar, “Computation over multiple-access channels,”IEEE Trans. Inf. Theory, vol. 53, no. 10, pp. 3498–3516, 2007
work page 2007
-
[4]
Harnessing interference for analog function computation in wireless sensor networks,
M. Goldenbaum, H. Boche, and S. Sta ´nczak, “Harnessing interference for analog function computation in wireless sensor networks,”IEEE Trans. Signal Process., vol. 61, no. 20, pp. 4893–4906, 2013
work page 2013
-
[5]
Robust analog function computation via wireless multiple-access channels,
M. Goldenbaum and S. Sta ´nczak, “Robust analog function computation via wireless multiple-access channels,”IEEE Trans. Commun., vol. 62, no. 9, pp. 3299–3310, 2014
work page 2014
-
[6]
Adaptive federated learning over the air,
C. Wang, Z. Chen, N. Pappas, H. H. Yang, T. Q. S. Quek, and H. V . Poor, “Adaptive federated learning over the air,”IEEE Trans. Signal Process., vol. 73, pp. 3187–3202, 2025
work page 2025
-
[7]
Federated learning via over-the-air computation,
K. Yang, T. Jiang, Y . Shi, and Z. Ding, “Federated learning via over-the-air computation,”IEEE Trans. Wireless Commun., vol. 19, no. 3, pp. 2022–2035, 2020
work page 2022
-
[8]
Machine learning at the wireless edge: Distributed stochastic gradient descent over-the-air,
M. Mohammadi Amiri and D. Gündüz, “Machine learning at the wireless edge: Distributed stochastic gradient descent over-the-air,”IEEE Trans. Signal Process., vol. 68, pp. 2155–2169, 2020
work page 2020
-
[9]
Broadband analog aggregation for low-latency federated edge learning,
G. Zhu, Y . Wang, and K. Huang, “Broadband analog aggregation for low-latency federated edge learning,”IEEE Trans. Wireless Commun., vol. 19, no. 1, pp. 491–506, 2020
work page 2020
-
[10]
Over-the-air federated learning from heterogeneous data,
T. Sery, N. Shlezinger, K. Cohen, and Y . C. Eldar, “Over-the-air federated learning from heterogeneous data,”IEEE Trans. Signal Process., vol. 69, pp. 3796–3811, 2021
work page 2021
-
[11]
Over-the-air computation for 6G: Foundations, technologies, and applications,
Z. Wanget al., “Over-the-air computation for 6G: Foundations, technologies, and applications,”IEEE Internet Things J., vol. 11, no. 14, pp. 24 634–24 658, 2024
work page 2024
-
[12]
Over-the-air federated learning: Status quo, open challenges, and future directions,
B. Xiao, X. Yu, W. Ni, X. Wang, and H. V . Poor, “Over-the-air federated learning: Status quo, open challenges, and future directions,”Fundam. Res., vol. 5, no. 4, pp. 1710–1724, 2025
work page 2025
-
[13]
Optimized power control design for over-the-air federated edge learning,
X. Cao, G. Zhu, J. Xu, Z. Wang, and S. Cui, “Optimized power control design for over-the-air federated edge learning,”IEEE J. Sel. Areas Commun., vol. 40, no. 1, pp. 342–358, 2022
work page 2022
-
[14]
Transmission power control for over-the-air federated averaging at network edge,
X. Cao, G. Zhu, J. Xu, and S. Cui, “Transmission power control for over-the-air federated averaging at network edge,”IEEE J. Sel. Areas Commun., vol. 40, no. 5, pp. 1571–1586, 2022
work page 2022
-
[15]
Waveforms for computing over the air: A groundbreaking approach that redefines data aggregation,
A. I. Pérez-Neiraet al., “Waveforms for computing over the air: A groundbreaking approach that redefines data aggregation,”IEEE Signal Process. Mag., vol. 42, no. 2, pp. 57–77, Mar. 2025
work page 2025
-
[16]
Over-the-air federated learning via weighted aggregation,
S. M. Azimi-Abarghouyi and L. Tassiulas, “Over-the-air federated learning via weighted aggregation,”IEEE Trans. Wireless Commun., vol. 23, no. 12, pp. 18 240–18 253, 2024
work page 2024
-
[17]
Random orthogonalization for federated learning in massive MIMO systems,
X. Wei, C. Shen, J. Yang, and H. V . Poor, “Random orthogonalization for federated learning in massive MIMO systems,” inProc. IEEE Int. Conf. Commun., 2022, pp. 3382–3387
work page 2022
-
[18]
Blind federated learning via over-the-airq-QAM,
S. Razavikia, J. M. Barros da Silva Jr., and C. Fischione, “Blind federated learning via over-the-airq-QAM,”IEEE Trans. Wireless Commun., vol. 23, no. 12, pp. 19 570–19 586, 2024
work page 2024
-
[19]
Blind over-the-air computation and data fusion via provable wirtinger flow,
J. Dong, Y . Shi, and Z. Ding, “Blind over-the-air computation and data fusion via provable wirtinger flow,” 2018
work page 2018
-
[20]
signSGD: Compressed optimisation for non-convex problems,
J. Bernstein, Y .-X. Wang, K. Azizzadenesheli, and A. Anandkumar, “signSGD: Compressed optimisation for non-convex problems,” inProc. 35th Int. Conf. Mach. Learn., ser. Proc. Mach. Learn. Res., vol. 80, 2018, pp. 560–569
work page 2018
-
[21]
G. Zhu, Y . Du, D. Gündüz, and K. Huang, “One-bit over-the-air aggregation for communication-efficient federated edge learning: Design and convergence analysis,”IEEE Trans. Wireless Commun., vol. 20, no. 3, pp. 2120–2135, 2021
work page 2021
-
[22]
Distributed learning over a wireless network with non-coherent majority vote computation,
A. ¸ Sahin, “Distributed learning over a wireless network with non-coherent majority vote computation,”IEEE Trans. Wireless Commun., vol. 22, no. 11, pp. 8020–8034, 2023
work page 2023
-
[23]
One-bit aggregation for over-the-air federated learning against byzantine attacks,
Y . Miao, W. Ni, and H. Tian, “One-bit aggregation for over-the-air federated learning against byzantine attacks,”IEEE Signal Process. Lett., vol. 31, pp. 1024–1028, 2024
work page 2024
-
[24]
Non-coherent over-the-air decentralized gradient descent,
N. Michelusi, “Non-coherent over-the-air decentralized gradient descent,”IEEE Trans. Signal Process., vol. 72, pp. 4618–4634, 2024
work page 2024
-
[25]
Distributed average consensus via noisy and noncoherent over-the-air aggregation,
H. Yang, X. Chen, L. Huang, S. Dey, and L. Shi, “Distributed average consensus via noisy and noncoherent over-the-air aggregation,”IEEE Trans. Control Netw. Syst., vol. 12, no. 1, pp. 64–73, 2025
work page 2025
-
[26]
NCAirFL: CSI-free over-the-air federated learning based on non-coherent detection,
H. Wen, N. Michelusi, O. Simeone, and H. Xing, “NCAirFL: CSI-free over-the-air federated learning based on non-coherent detection,” inProc. IEEE Int. Conf. Commun., 2025, pp. 3443–3448
work page 2025
-
[27]
Over-the-air federated learning and optimization,
J. Zhuet al., “Over-the-air federated learning and optimization,”IEEE Internet Things J., vol. 11, no. 10, pp. 16 996–17 020, 2024
work page 2024
-
[28]
Gradient-based learning applied to document recognition,
Y . LeCun, L. Bottou, Y . Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,”Proceedings of the IEEE, vol. 86, no. 11, pp. 2278–2324, Nov. 1998
work page 1998
-
[29]
Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms,
H. Xiao, K. Rasul, and R. V ollgraf, “Fashion-mnist: A novel image dataset for benchmarking machine learning algorithms,” 2017
work page 2017
-
[30]
On the convergence of FedAvg on non-IID data,
X. Li, K. Huang, W. Yang, S. Wang, and Z. Zhang, “On the convergence of FedAvg on non-IID data,” inProc. Int. Conf. Learn. Represent., 2020
work page 2020
-
[31]
Federated optimization in heterogeneous networks,
T. Li, A. K. Sahu, M. Zaheer, M. Sanjabi, A. Talwalkar, and V . Smith, “Federated optimization in heterogeneous networks,” inProc. Mach. Learn. Syst., 2020
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.