Recognition: 1 theorem link
· Lean TheoremImplicit Compression Regularization: Concise Reasoning via Internal Shorter Distributions in RL Post-Training
Pith reviewed 2026-05-11 01:09 UTC · model grok-4.3
The pith
Reinforcement learning for LLM reasoning can shorten traces by favoring the shortest correct responses already present in each rollout group.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When the length-accuracy correlation remains negative, the shortest correct responses in a rollout group are shorter than the group average in expectation and therefore serve as natural, on-policy compression targets. Implicit Compression Regularization formalizes this observation into an on-policy regularization term that encourages the policy to assign higher probability to those shorter correct trajectories, keeping the correlation from flipping positive and thereby avoiding underthinking.
What carries the argument
Implicit Compression Regularization (ICR), a regularization method that constructs a virtual shorter distribution from the shortest correct responses within each on-policy rollout group and uses it to guide the policy toward concise yet correct trajectories.
If this is right
- The length-accuracy correlation stays negative longer during training, preventing the policy from entering the underthinking regime.
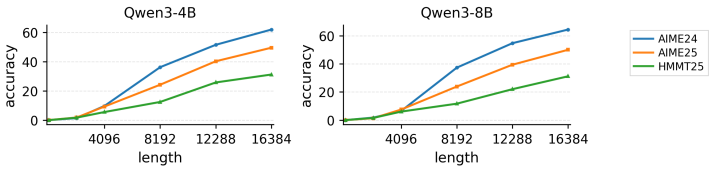
- Response lengths decrease on both mathematical and knowledge-intensive tasks while accuracy is preserved or improved.
- The accuracy-length Pareto frontier improves compared with length-penalty and early-exit baselines across three different reasoning backbones.
- The compression signal is obtained entirely from existing on-policy rollouts, requiring no additional sampling or external supervision.
Where Pith is reading between the lines
- The same correlation-monitoring idea could be used as a diagnostic to decide when to stop or adjust other RL fine-tuning runs before underthinking sets in.
- If shortest-correct responses remain reliable targets, similar regularization might reduce verbosity in non-reasoning domains such as code generation or long-form question answering.
- The approach suggests that overthinking is detectable from rollout statistics alone, opening the possibility of adaptive regularization schedules that activate only while the correlation is negative.
Load-bearing premise
The shortest correct responses inside each rollout group form a safe, unbiased compression target that does not introduce new failure modes or bias the policy away from correct reasoning.
What would settle it
A controlled training run on a held-out mathematical benchmark in which ICR produces measurably shorter average responses yet shows a statistically significant drop in final accuracy relative to the unregularized baseline.
Figures





read the original abstract
Reinforcement learning with verifiable rewards improves LLM reasoning but often induces overthinking, where models generate unnecessarily long reasoning traces. Existing methods mainly rely on length penalties or early-exit strategies; however, the former may degrade accuracy and induce underthinking, whereas the latter assumes that substantial portions of reasoning traces can be safely truncated. To obtain a compression signal without these limitations, we revisit the training dynamics of existing compression methods. We observe that the length--accuracy correlation is initially negative but continually increases during compression, indicating that shorter responses are initially more likely to be correct but gradually lose this property as the policy moves toward underthinking. Based on this observation, we formalize overthinking: a negative correlation indicates an overthinking regime, while a positive one indicates underthinking. When overthinking, the shortest correct responses are shorter than the group-average response length in expectation, making them natural compression targets already present in on-policy rollouts. We therefore propose \emph{Implicit Compression Regularization} (ICR), an on-policy regularization method whose compression signal comes from a virtual shorter distribution induced by the shortest correct responses in rollout groups, guiding the policy toward concise yet correct trajectories. Training dynamics show that ICR maintains a better length--accuracy correlation during compression, indicating that short responses remain better aligned with correctness instead of drifting toward underthinking. Experiments on three reasoning backbones and multiple mathematical and knowledge-intensive benchmarks show that ICR consistently shortens responses while preserving or improving accuracy, achieving a stronger accuracy--length Pareto frontier.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Implicit Compression Regularization (ICR), an on-policy RL method for LLM reasoning post-training. It observes that length-accuracy correlation begins negative (overthinking regime) and rises during compression, formalizes overthinking as negative correlation and underthinking as positive, and uses the shortest correct responses within rollout groups to induce a virtual shorter distribution as the compression target. This is claimed to maintain a favorable correlation regime, shorten responses, preserve or improve accuracy, and yield a stronger accuracy-length Pareto frontier across three reasoning backbones and multiple math/knowledge benchmarks.
Significance. If the central empirical claim holds, ICR offers a lightweight, penalty-free regularization approach that exploits existing on-policy rollout statistics to compress reasoning traces without inducing underthinking. The multi-backbone, multi-benchmark evaluation is a strength, providing evidence that the method can improve the efficiency frontier for verifiable-reward RL on reasoning tasks.
major comments (1)
- [Experiments] Experiments section: the central claim of a stronger accuracy-length Pareto frontier rests on reported consistent improvements, yet the manuscript provides no details on baseline implementations, statistical significance testing, hyperparameter sensitivity, or exact rollout and reward controls. This absence is load-bearing for assessing whether the observed shortening is attributable to ICR rather than uncontrolled factors.
minor comments (2)
- [Introduction / §2] The ad-hoc axiom that negative length-accuracy correlation indicates overthinking (and positive indicates underthinking) is introduced observationally; a short paragraph clarifying its empirical grounding versus potential alternative interpretations would strengthen the motivation.
- [Method] Notation for the virtual shorter distribution induced by shortest correct responses is introduced in the abstract and methods but would benefit from an explicit equation or pseudocode block for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive assessment and constructive feedback. We address the major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the central claim of a stronger accuracy-length Pareto frontier rests on reported consistent improvements, yet the manuscript provides no details on baseline implementations, statistical significance testing, hyperparameter sensitivity, or exact rollout and reward controls. This absence is load-bearing for assessing whether the observed shortening is attributable to ICR rather than uncontrolled factors.
Authors: We agree that the current manuscript would benefit from expanded experimental details to strengthen reproducibility and attribution of results to ICR. In the revised version, we will add: (1) precise descriptions of all baseline implementations, including any adaptations of standard on-policy RL algorithms and their hyperparameters; (2) statistical significance testing, such as bootstrap confidence intervals or paired tests on accuracy and length metrics across seeds; (3) hyperparameter sensitivity analysis focused on the implicit regularization strength and rollout group size; and (4) exact specifications of rollout configurations, reward computation, and control conditions. These additions will clarify that the observed Pareto frontier improvements stem from ICR rather than implementation artifacts. revision: yes
Circularity Check
No significant circularity; derivation grounded in on-policy observations
full rationale
The paper's derivation begins with an empirical observation of length-accuracy correlation dynamics during RL training, which is used to motivate a definitional formalization of overthinking (negative correlation) versus underthinking (positive correlation) regimes. From this, the ICR method selects the shortest correct response within each on-policy rollout group as the compression target, inducing a virtual shorter distribution for regularization. This selection is directly extracted from independently sampled rollouts rather than fitted parameters, self-referential equations, or prior self-citations. No load-bearing uniqueness theorem, ansatz smuggling, or renaming of known results is present; the central claim of a stronger accuracy-length Pareto frontier is supported by experiments across backbones and benchmarks, keeping the chain self-contained without reduction to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Reinforcement learning with verifiable rewards improves LLM reasoning capabilities
- ad hoc to paper Negative length-accuracy correlation indicates overthinking while positive indicates underthinking
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We formalize overthinking by the expected group-wise correlation between correctness and response length... ICR uses the shortest correct responses within rollout groups to induce a virtual shorter distribution
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
work page 2022
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Kimi Team, Angang Du, Bofei Gao, Bowei Xing, Changjiu Jiang, Cheng Chen, Cheng Li, Chenjun Xiao, Chenzhuang Du, Chonghua Liao, et al. Kimi k1. 5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Y Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[5]
Jinyan Su, Jennifer Healey, Preslav Nakov, and Claire Cardie. Between underthinking and overthinking: An empirical study of reasoning length and correctness in llms.arXiv preprint arXiv:2505.00127, 2025
-
[6]
Reasoning on a budget: A survey of adaptive and controllable test-time compute in llms
Mohammad Ali Alomrani, Yingxue Zhang, Derek Li, Qianyi Sun, Soumyasundar Pal, Zhanguang Zhang, Yaochen Hu, Rohan Deepak Ajwani, Antonios Valkanas, Raika Karimi, et al. Reasoning on a budget: A survey of adaptive and controllable test-time compute in llms. arXiv preprint arXiv:2507.02076, 2025
-
[7]
Do NOT Think That Much for 2+3=? On the Overthinking of o1-Like LLMs
Xingyu Chen, Jiahao Xu, Tian Liang, Zhiwei He, Jianhui Pang, Dian Yu, Linfeng Song, Qiuzhi Liu, Mengfei Zhou, Zhuosheng Zhang, et al. Do not think that much for 2+ 3=? on the overthinking of o1-like llms.arXiv preprint arXiv:2412.21187, 2024
work page internal anchor Pith review arXiv 2024
-
[8]
Stop Overthinking: A Survey on Efficient Reasoning for Large Language Models
Yang Sui, Yu-Neng Chuang, Guanchu Wang, Jiamu Zhang, Tianyi Zhang, Jiayi Yuan, Hongyi Liu, Andrew Wen, Shaochen Zhong, Na Zou, et al. Stop overthinking: A survey on efficient reasoning for large language models.arXiv preprint arXiv:2503.16419, 2025
work page internal anchor Pith review arXiv 2025
-
[9]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[10]
Jingyang Yi, Jiazheng Wang, and Sida Li. Shorterbetter: Guiding reasoning models to find optimal inference length for efficient reasoning.arXiv preprint arXiv:2504.21370, 2025
-
[11]
Fanfan Liu, Youyang Yin, Peng Shi, Siqi Yang, Zhixiong Zeng, and Haibo Qiu. Length-unbiased sequence policy optimization: Revealing and controlling response length variation in rlvr.arXiv preprint arXiv:2602.05261, 2026
-
[12]
On the optimal reasoning length for rl-trained language models.arXiv preprint arXiv:2602.09591, 2026
Daisuke Nohara, Taishi Nakamura, and Rio Yokota. On the optimal reasoning length for rl-trained language models.arXiv preprint arXiv:2602.09591, 2026
-
[13]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model? arXiv preprint arXiv:2504.13837, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[14]
Muzhi Dai, Chenxu Yang, and Qingyi Si. S-grpo: Early exit via reinforcement learning in reasoning models.arXiv preprint arXiv:2505.07686, 2025
-
[15]
Yi Bin, Tianyi Jiang, Yujuan Ding, Kainian Zhu, Fei Ma, Jingkuan Song, Yang Yang, and Heng Tao Shen. Explore briefly, then decide: Mitigating llm overthinking via cumulative entropy regulation.arXiv preprint arXiv:2510.02249, 2025. 10
-
[16]
Optimizing length compression in large reasoning models
Zhengxiang Cheng, Dongping Chen, Mingyang Fu, and Tianyi Zhou. Optimizing length compression in large reasoning models.arXiv preprint arXiv:2506.14755, 2025
-
[17]
arXiv preprint arXiv:2504.06514 , year=
Chenrui Fan, Ming Li, Lichao Sun, and Tianyi Zhou. Missing premise exacerbates overthinking: Are reasoning models losing critical thinking skill?arXiv preprint arXiv:2504.06514, 2025
-
[18]
Renfei Dang, Zhening Li, Shujian Huang, and Jiajun Chen. The first impression problem: Internal bias triggers overthinking in reasoning models.arXiv preprint arXiv:2505.16448, 2025
-
[19]
Alejandro Cuadron, Dacheng Li, Wenjie Ma, Xingyao Wang, Yichuan Wang, Siyuan Zhuang, Shu Liu, Luis Gaspar Schroeder, Tian Xia, Huanzhi Mao, et al. The danger of overthinking: Examining the reasoning-action dilemma in agentic tasks.arXiv preprint arXiv:2502.08235, 2025
-
[20]
Training language models to reason efficiently.ArXiv, abs/2502.04463, 2025
Daman Arora and Andrea Zanette. Training language models to reason efficiently.arXiv preprint arXiv:2502.04463, 2025
-
[21]
Wei Liu, Ruochen Zhou, Yiyun Deng, Yuzhen Huang, Junteng Liu, Yuntian Deng, Yizhe Zhang, and Junxian He. Learn to reason efficiently with adaptive length-based reward shaping.arXiv preprint arXiv:2505.15612, 2025
-
[22]
Qin-Wen Luo, Sheng Ren, Xiang Chen, Rui Liu, Jun Fang, Naiqiang Tan, and Sheng-Jun Huang. Compress the easy, explore the hard: Difficulty-aware entropy regularization for efficient llm reasoning.arXiv preprint arXiv:2602.22642, 2026
-
[23]
Tian Liang, Wenxiang Jiao, Zhiwei He, Jiahao Xu, Haitao Mi, and Dong Yu. Deepcompress: A dual reward strategy for dynamically exploring and compressing reasoning chains.arXiv preprint arXiv:2510.27419, 2025
-
[24]
Chenzhi Hu, Qinzhe Hu, Yuhang Xu, Junyi Chen, Ruijie Wang, Shengzhong Liu, Jianxin Li, Fan Wu, and Guihai Chen. Smartthinker: Progressive chain-of-thought length calibration for efficient large language model reasoning.arXiv preprint arXiv:2603.08000, 2026
-
[25]
Jinyan Su and Claire Cardie. Thinking fast and right: Balancing accuracy and reasoning length with adaptive rewards.arXiv preprint arXiv:2505.18298, 2025
-
[26]
Adaptthink: Reasoning models can learn when to think
Jiajie Zhang, Nianyi Lin, Lei Hou, Ling Feng, and Juanzi Li. Adaptthink: Reasoning models can learn when to think. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 3716–3730, 2025
work page 2025
-
[27]
Silei Xu, Wenhao Xie, Lingxiao Zhao, and Pengcheng He
Silei Xu, Wenhao Xie, Lingxiao Zhao, and Pengcheng He. Chain of draft: Thinking faster by writing less.arXiv preprint arXiv:2502.18600, 2025
-
[28]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Easyr1: An efficient, scalable, multi-modality rl training framework
Zheng Yaowei, Lu Junting, Wang Shenzhi, Feng Zhangchi, Kuang Dongdong, and Xiong Yuwen. Easyr1: An efficient, scalable, multi-modality rl training framework. https://github.com/ hiyouga/EasyR1, 2025
work page 2025
-
[30]
Hybridflow: A flexible and efficient rlhf framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. In Proceedings of the Twentieth European Conference on Computer Systems, pages 1279–1297, 2025
work page 2025
-
[31]
MathArena: Evaluating LLMs on Uncontaminated Math Competitions
Mislav Balunovi´c, Jasper Dekoninck, Ivo Petrov, Nikola Jovanovi´c, and Martin Vechev. Math- arena: Evaluating llms on uncontaminated math competitions.arXiv preprint arXiv:2505.23281, 2025
work page internal anchor Pith review arXiv 2025
-
[32]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step.arXiv preprint arXiv:2305.20050, 2023. 11
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[34]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[35]
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.Advances in Neural Information Processing Systems, 37:95266–95290, 2024
work page 2024
-
[36]
Xinrun Du, Yifan Yao, Kaijing Ma, Bingli Wang, Tianyu Zheng, King Zhu, Minghao Liu, Yiming Liang, Xiaolong Jin, Zhenlin Wei, et al. Supergpqa: Scaling llm evaluation across 285 graduate disciplines.arXiv preprint arXiv:2502.14739, 2025. A Limitations A limitation of this work lies in the granularity of our definition of overthinking and underthinking. To ...
-
[37]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.