Recognition: 2 theorem links
· Lean TheoremHBEE: Human Behavioral Entropy Engine -- Pre-Registered Multi-Agent LLM Simulation of Peer-Suspicion-Based Detection Inversion
Pith reviewed 2026-05-11 01:56 UTC · model grok-4.3
The pith
In an LLM-driven multi-agent simulation, an adaptive insider ends up with lower peer suspicion than innocent agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
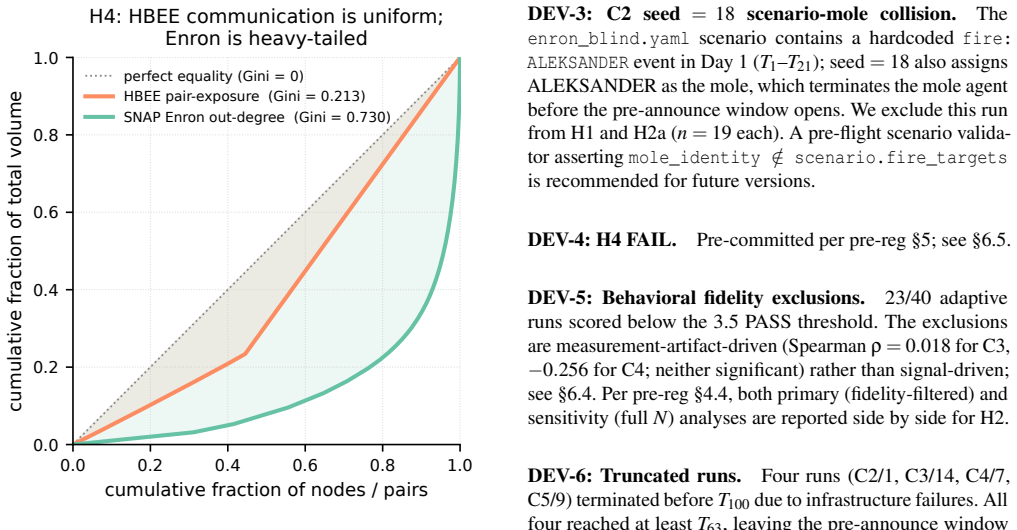
The pre-registered study isolates defender mode and adversary type and finds a detection inversion at T_60: the adaptive mole's suspicion in-degree is lower than that of a randomly selected innocent agent (Cliff's delta = -0.694). Equivalence tests show no shift in the mole's UEBA rank under either defender mode. The peer-suspicion graph and UEBA signals decouple under adaptive OPSEC. A pre-registered Gini calibration check fails because the simulator's message-exposure distribution diverges from the SNAP Enron reference.
What carries the argument
The HBEE multi-agent simulator in which LLM agents exchange messages, report suspicions, and generate in-degree scores on a peer graph while one agent follows adaptive OPSEC directives.
If this is right
- Peer-suspicion cascade detection can invert against an adaptive adversary.
- UEBA rank and peer suspicion become independent signals when the adversary adapts.
- Adaptive OPSEC produces no detectable change in the insider's UEBA rank.
- Generalization beyond the simulator is bounded because the message-exposure distribution does not match real organizational email data.
Where Pith is reading between the lines
- Detection systems may need separate mechanisms for AI-assisted adaptive evasion rather than relying on either signal alone.
- Simulator-based testing can surface counterintuitive failure modes before deployment in live environments.
- Improving the match between simulated communication patterns and empirical data would strengthen claims about real-world applicability.
Load-bearing premise
LLM directives can produce human-like adaptive operational security behavior and the resulting message graph creates suspicion dynamics comparable to real organizations.
What would settle it
Replace the LLM agents with human participants instructed to follow the same adaptive OPSEC rules and re-measure whether the adaptive insider still receives lower suspicion in-degree than innocents.
Figures





read the original abstract
Insider threat detection assumes that an adaptive insider leaves behavioral residue distinguishing them from legitimate users. We test this assumption against an LLM-driven adaptive insider in a controlled multi-agent simulator. Our pre-registered five-condition study isolates defender mode (cascade vs. blind UEBA) crossed with adversary type (naive vs. adaptive OPSEC) plus a no-mole control, across 100 runs (95 valid after pre-committed exclusions). The primary finding is a detection inversion: at T_60, the adaptive mole's suspicion in-degree is statistically lower than a randomly selected innocent agent (Cliff's delta = -0.694, 95% BCa CI [-0.855, -0.519], Mann-Whitney p << 0.01). The pre-registered prediction was the opposite direction. A pre-registered equivalence test (H2) shows adaptive OPSEC produces no detectable shift in the mole's UEBA rank under either defender mode. The two detection signals (peer suspicion graph in-degree and per-agent UEBA rank) decouple under adaptive adversary behavior. We bound generalization explicitly: a pre-registered Gini calibration check (H4) returns FAIL, with HBEE pairwise message-exposure Gini (0.213) diverging from the SNAP Enron reference (0.730) by |Delta Gini| = 0.52, exceeding the equivalence bound by 5x. The paper makes a narrow but surprising claim: in a controlled environment where adaptive OPSEC is implementable as an LLM directive, peer-suspicion-cascade detection inverts. We release the simulator, pre-registration document, frozen scenarios, raw telemetry, and analysis pipeline under an open-source license.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports a pre-registered five-condition multi-agent LLM simulation (HBEE) of insider-threat detection, crossing defender mode (cascade vs. blind UEBA) with adversary type (naive vs. adaptive OPSEC) plus control, across 100 runs (95 valid). The primary result is a detection inversion at T_60: the adaptive mole's suspicion in-degree is lower than a random innocent agent's (Cliff's delta = -0.694, 95% BCa CI [-0.855, -0.519], Mann-Whitney p << 0.01), contrary to the pre-registered directional prediction. Equivalence testing shows no UEBA-rank shift under adaptive OPSEC; the two signals decouple. A pre-registered Gini calibration (H4) against SNAP Enron fails (|Delta Gini| = 0.52, 5x over bound), and the authors explicitly bound generalization while releasing the simulator, pre-registration, data, and pipeline.
Significance. If the simulation faithfully reproduces human-like adaptive OPSEC and suspicion dynamics, the inversion and decoupling would challenge the core assumption that adaptive insiders necessarily produce detectable behavioral residue in peer-suspicion graphs, with potential implications for UEBA and cascade detectors. Strengths include the pre-registration, explicit equivalence testing, confidence intervals, and open release of code and materials. However, the result's bearing on real insider-threat detection is limited by the unvalidated LLM fidelity and the large divergence from the Enron reference graph.
major comments (2)
- [H4 calibration check] H4 calibration check: |Delta Gini| = 0.52 (HBEE 0.213 vs. Enron 0.730) exceeds the pre-registered equivalence bound by 5x. Because the headline suspicion in-degree outcome is generated from the pairwise message-exposure graph, this divergence means the observed inversion may not reflect dynamics comparable to real organizations.
- [Methods on LLM prompt templates for adaptive OPSEC] Methods on LLM prompt templates for adaptive OPSEC: the central statistical claim (lower suspicion in-degree for the adaptive mole) rests on the untested assumption that the LLM directives produce human-comparable OPSEC behavior. No human-subject validation, ablation on prompt variants, or external behavioral benchmark is reported to rule out simulation artifact.
minor comments (1)
- [Abstract] The abstract states the pre-registered prediction was opposite the observed inversion but does not quote the exact directional hypothesis; adding the verbatim pre-registered wording would improve transparency.
Simulated Author's Rebuttal
We thank the referee for the careful review and constructive feedback on our pre-registered simulation study. We address each major comment below. The manuscript already explicitly reports the H4 calibration failure and bounds its claims accordingly; we make no broader assertions about real-world organizations.
read point-by-point responses
-
Referee: [H4 calibration check] H4 calibration check: |Delta Gini| = 0.52 (HBEE 0.213 vs. Enron 0.730) exceeds the pre-registered equivalence bound by 5x. Because the headline suspicion in-degree outcome is generated from the pairwise message-exposure graph, this divergence means the observed inversion may not reflect dynamics comparable to real organizations.
Authors: We agree that the |Delta Gini| = 0.52 divergence shows the HBEE message-exposure graph does not match the Enron reference structure. This is precisely why H4 was pre-registered as a calibration check and why the manuscript states that the check fails, explicitly bounding generalization to the controlled LLM simulation rather than claiming equivalence to real organizations. The core result is the detection inversion observed inside this reproducible environment, supported by open release of the simulator, prompts, data, and pipeline. No changes to the manuscript are needed because the limitation is already disclosed in the abstract, results, and discussion. revision: no
-
Referee: [Methods on LLM prompt templates for adaptive OPSEC] Methods on LLM prompt templates for adaptive OPSEC: the central statistical claim (lower suspicion in-degree for the adaptive mole) rests on the untested assumption that the LLM directives produce human-comparable OPSEC behavior. No human-subject validation, ablation on prompt variants, or external behavioral benchmark is reported to rule out simulation artifact.
Authors: We acknowledge that the adaptive OPSEC behavior is implemented via LLM directives without human-subject validation, prompt ablations, or external behavioral benchmarks. The study is framed as a controlled, pre-registered simulation to isolate the effect of adaptive OPSEC directives on detection signals, with all materials released to support independent scrutiny or extension. We have added a clarifying sentence in the limitations section noting the absence of human validation and the consequent need for caution in extrapolating to human insiders. This addresses the comment while preserving the narrow scope of the pre-registered claims. revision: partial
Circularity Check
No significant circularity: simulation outcomes and pre-registered checks are independent of internal fits or self-citations
full rationale
The paper reports results from a pre-registered multi-agent LLM simulation study with explicit statistical comparisons (Cliff's delta, Mann-Whitney) and a failed external calibration check (H4 Gini against SNAP Enron). No equations, parameters, or derivations reduce by construction to the target claims; the inversion finding is an empirical outcome from the runs, not a fitted input renamed as prediction. No self-citations are load-bearing for the central claim, no ansatz is smuggled, and no uniqueness theorems or renamings of known results appear. The explicit bounding via calibration failure further separates the narrow simulation claim from any internal circular loop. The derivation chain is self-contained against the simulation telemetry.
Axiom & Free-Parameter Ledger
free parameters (1)
- LLM prompt templates for adaptive OPSEC
axioms (2)
- domain assumption LLM agents can simulate human behavioral entropy and adaptive OPSEC
- domain assumption Suspicion in-degree and UEBA rank are valid, independent detection signals
invented entities (1)
-
HBEE (Human Behavioral Entropy Engine)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
primary finding is a detection inversion: at T_60, the adaptive mole's suspicion in-degree is statistically lower than a randomly selected innocent agent (Cliff's delta = -0.694)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Insider threat test dataset (r4.2), 2016
Carnegie Mellon University CERT Division. Insider threat test dataset (r4.2), 2016
work page 2016
-
[2]
Norman Cliff. Dominance statistics: Ordinal analyses to answer ordinal questions.Psychological Bulletin, 114(3):494–509, 1993
work page 1993
-
[3]
GLM: General language model pretraining with autoregressive blank infilling
Zhengxiao Du, Yujie Qian, Xiao Liu, Ming Ding, Jiezhong Qiu, Zhilin Yang, and Jie Tang. GLM: General language model pretraining with autoregressive blank infilling. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL), 2022
work page 2022
-
[4]
Tibshirani.An Introduction to the Bootstrap
Bradley Efron and Robert J. Tibshirani.An Introduction to the Bootstrap. Number 57 in Monographs on Statis- tics and Applied Probability. Chapman & Hall/CRC, 1993
work page 1993
- [5]
-
[6]
Operational deployment guidance; available at https://github.com/Vix0007/hbee-v40
-
[7]
HBEE V40 deviation log (V40_DEVIATIONS.md), 2026
Vickson Ferrel. HBEE V40 deviation log (V40_DEVIATIONS.md), 2026. DEV-1 through DEV-6; available at https://github.com/Vix0007/ hbee-v40
work page 2026
-
[8]
HBEE V40 Gini saturation-ceiling diag- nostic (gini_diagnostic.py), 2026
Vickson Ferrel. HBEE V40 Gini saturation-ceiling diag- nostic (gini_diagnostic.py), 2026. Supplementary diagnostic for DEV-4; available at https://github. com/Vix0007/hbee-v40
work page 2026
-
[9]
HBEE V40 pre-registration protocol (V40_PREREG.md), 2026
Vickson Ferrel. HBEE V40 pre-registration protocol (V40_PREREG.md), 2026. Frozen by SHA256 prior to first campaign run; available at https://github.com/ Vix0007/hbee-v40
work page 2026
-
[10]
OrgForge-IT: A verifiable synthetic bench- mark for LLM-based insider threat detection, 2026
Jeffrey Flynt. OrgForge-IT: A verifiable synthetic bench- mark for LLM-based insider threat detection, 2026
work page 2026
-
[11]
John J. Horton. Large language models as simulated eco- nomic agents: What can we learn from Homo Silicus? Technical Report 31122, National Bureau of Economic Research, 2023
work page 2023
-
[12]
Gonza- lez, Hao Zhang, and Ion Stoica
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonza- lez, Hao Zhang, and Ion Stoica. Efficient memory man- agement for large language model serving with Page- dAttention. InProceedings of the 29th ACM Symposium on Operating Systems Principles (SOSP), 2023
work page 2023
-
[13]
Daniël Lakens. Equivalence tests: A practical primer for t tests, correlations, and meta-analyses.Social Psycho- logical and Personality Science, 8(4):355–362, 2017
work page 2017
-
[14]
SNAP datasets: Stan- ford large network dataset collection, 2014
Jure Leskovec and Andrej Krevl. SNAP datasets: Stan- ford large network dataset collection, 2014. Email- Enron network used as H4 calibration reference. 13
work page 2014
-
[15]
Ritchie, Sören Mindermann, Evan Hubinger, Ethan Perez, and Kevin K
Aengus Lynch, Benjamin Wright, Caleb Larson, Stu- art J. Ritchie, Sören Mindermann, Evan Hubinger, Ethan Perez, and Kevin K. Troy. Agentic misalignment: How LLMs could be insider threats, 2025
work page 2025
-
[16]
Brian A. Nosek, Emorie D. Beck, Lorne Campbell, Jes- sica K. Flake, Tom E. Hardwicke, David T. Mellor, Anna E. van ’t Veer, and Simine Vazire. Preregistration is hard, and worthwhile.Trends in Cognitive Sciences, 23(10):815–818, 2019
work page 2019
-
[17]
Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior. InProceedings of the 36th Annual ACM Symposium on User Interface Software and Tech- nology (UIST), 2023
work page 2023
-
[18]
Jinghua Piao, Yuwei Yan, Jun Zhang, Nian Li, Junbo Yan, Xiaochong Lan, Zhihong Lu, Zhiheng Zheng, Jing Yi Wang, Di Zhou, Chen Gao, Fengli Xu, Fang Zhang, Ke Rong, Jun Su, and Yong Li. AgentSociety: Large-scale simulation of LLM-driven generative agents advances understanding of human behaviors and society, 2025
work page 2025
-
[19]
Joelle Pineau, Philippe Vincent-Lamarre, Koustuv Sinha, Vincent Larivière, Alina Beygelzimer, Florence d’Alché Buc, Emily Fox, and Hugo Larochelle. Improving repro- ducibility in machine learning research (A report from the NeurIPS 2019 reproducibility program).Journal of Machine Learning Research, 22(164):1–20, 2021
work page 2019
-
[20]
User and entity behavior analytics for enterprise secu- rity
Madhu Shashanka, Min-Yi Shen, and Jisheng Wang. User and entity behavior analytics for enterprise secu- rity. InProceedings of the 2016 IEEE International Conference on Big Data, 2016
work page 2016
-
[21]
Audit-LLM: Multi- agent collaboration for log-based insider threat detection, 2024
Chengyu Song, Linru Ma, Jianming Zheng, Jinzhi Liao, Hongyu Kuang, and Lin Yang. Audit-LLM: Multi- agent collaboration for log-based insider threat detection, 2024
work page 2024
-
[22]
ChatGLM: A family of large language models from GLM-130B to GLM-4 All Tools, 2024
Team GLM, Aohan Zeng, Bin Xu, Bowen Wang, Chen- hui Zhang, Da Yin, et al. ChatGLM: A family of large language models from GLM-130B to GLM-4 All Tools, 2024
work page 2024
-
[23]
Petter Törnberg, Diliara Valeeva, Justus Uitermark, and Christopher Bail. Simulating social media using large language models to evaluate alternative news feed algo- rithms, 2023
work page 2023
-
[24]
Multimodal safety evaluation in generative agent social simulations, 2025
Alhim Vera, Karen Sanchez, Carlos Hinojosa, Haidar Bin Hamid, Donghoon Kim, and Bernard Ghanem. Multimodal safety evaluation in generative agent social simulations, 2025
work page 2025
-
[25]
Chimera: Harnessing multi-agent LLMs for automatic insider threat simulation
Jiongchi Yu, Yuhan Ma, Xiaofei Xie, Qiang Hu, and Ziming Zhao. Chimera: Harnessing multi-agent LLMs for automatic insider threat simulation. InProceedings of the 33rd Network and Distributed System Security Symposium (NDSS), 2026. arXiv:2508.07745
-
[26]
Deep learning for insider threat detection: Review, challenges and opportunities
Shuhan Yuan and Xintao Wu. Deep learning for insider threat detection: Review, challenges and opportunities. Computers & Security, 104:102221, 2021. 14
work page 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.