Recognition: 2 theorem links
· Lean TheoremSelf-Play Enhancement via Advantage-Weighted Refinement in Online Federated LLM Fine-Tuning with Real-Time Feedback
Pith reviewed 2026-05-11 02:12 UTC · model grok-4.3
The pith
SPEAR uses feedback-guided self-play to create contrastive pairs for online federated LLM fine-tuning without ground-truth data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SPEAR utilizes a feedback-guided self-play loop to construct naturally contrastive pairs per prompt which are utilized to be trained on (i) standard maximum likelihood on correct completions and (ii) confidence-weighted unlikelihood on tail tokens of incorrect completions. Without the need of expensive group generations and ground-truth contexts for training (i.e., only partial, non-answer feedback), in contrast with existing works, SPEAR can be trained both online and in a resource-efficient manner.
What carries the argument
The feedback-guided self-play loop for constructing contrastive pairs from partial feedback, trained via maximum likelihood on correct outputs and confidence-weighted unlikelihood on incorrect tail tokens.
If this is right
- LLM fine-tuning can proceed online in federated networks using only partial, non-answer feedback from users.
- Resource-constrained devices can participate in model improvement without requiring ground-truth contexts or multiple generations.
- Models achieve superior performance compared to state-of-the-art baselines across benchmark datasets.
- Self-improvement becomes feasible in real-time settings without offline data collection phases.
Where Pith is reading between the lines
- Such methods could enable models to adapt to individual user preferences while keeping data decentralized.
- Extending the partial feedback mechanism might apply to other alignment tasks beyond fine-tuning.
- Collective feedback from many users could accelerate convergence in federated self-play systems.
Load-bearing premise
Partial non-answer feedback reliably identifies correct versus incorrect completions to build useful contrastive pairs.
What would settle it
Running SPEAR on a benchmark where partial feedback is provided but the model fails to improve over baselines that use full supervision would indicate the method does not work as claimed.
Figures






read the original abstract
Recent works have advanced feedback-based learning systems, whereby a foundation model is able to intake incoming feedback (e.g., a user) to self-improve, creating a self-loop system of training. However, existing works are limited in needing to consider an offline setup to allow for such feedback-based methods, and are further limited in the need of requiring privileged ground-truth contexts for training. Moreover, there is limited consideration of federated learning (FL), which is particularly well-suited for incorporating external feedback across large networks of end users, for example, but requires methods to be efficient for training on resource-constrained edge devices. Therefore, we introduce SPEAR (Self-Play Enhancement via Advantage-Weighted Refinement), an efficient online learning algorithm for federated LLM fine-tuning. SPEAR utilizes a feedback-guided self-play loop to construct naturally contrastive pairs per prompt which are utilized to be trained on (i) standard maximum likelihood on correct completions and (ii) confidence-weighted unlikelihood on tail tokens of incorrect completions. Without the need of expensive group generations and ground-truth contexts for training (i.e., only partial, non-answer feedback), in contrast with existing works, SPEAR can be trained both online and in a resource-efficient manner. We validate SPEAR across various benchmark datasets, demonstrating its superior performance in comparison to state-of-the-art baselines. The implementation code is publicly available at https://github.com/lee3296/SPEAR.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SPEAR, an online federated LLM fine-tuning algorithm that uses a feedback-guided self-play loop to build contrastive pairs per prompt from partial, non-answer user feedback. These pairs drive training via (i) standard maximum likelihood on completions labeled correct and (ii) confidence-weighted unlikelihood on tail tokens of completions labeled incorrect. The method claims to eliminate the need for group generations or ground-truth contexts, enabling resource-efficient online training on edge devices in a federated setting, and reports superior performance versus state-of-the-art baselines across benchmark datasets. Public code is provided.
Significance. If the core claims hold, SPEAR would offer a practical route to real-time, feedback-driven self-improvement of LLMs under federated constraints where ground-truth data and heavy computation are unavailable. The public implementation supports reproducibility, which is a clear strength. The result would be most impactful for edge-device and privacy-sensitive applications, but its significance remains provisional given the absence of detailed validation of the feedback-to-label mapping that underpins the training signal.
major comments (2)
- [Method description (abstract and §3)] The central premise—that partial, non-answer feedback alone suffices to reliably label completions as correct or incorrect and to assign confidence weights for unlikelihood training—is load-bearing yet undescribed. No algorithm, threshold, or error model is given for converting feedback into binary labels or token-level penalties; any systematic mislabeling would directly produce harmful gradients in the online federated loop. This issue must be addressed with a concrete procedure and robustness analysis before the efficiency and superiority claims can be evaluated.
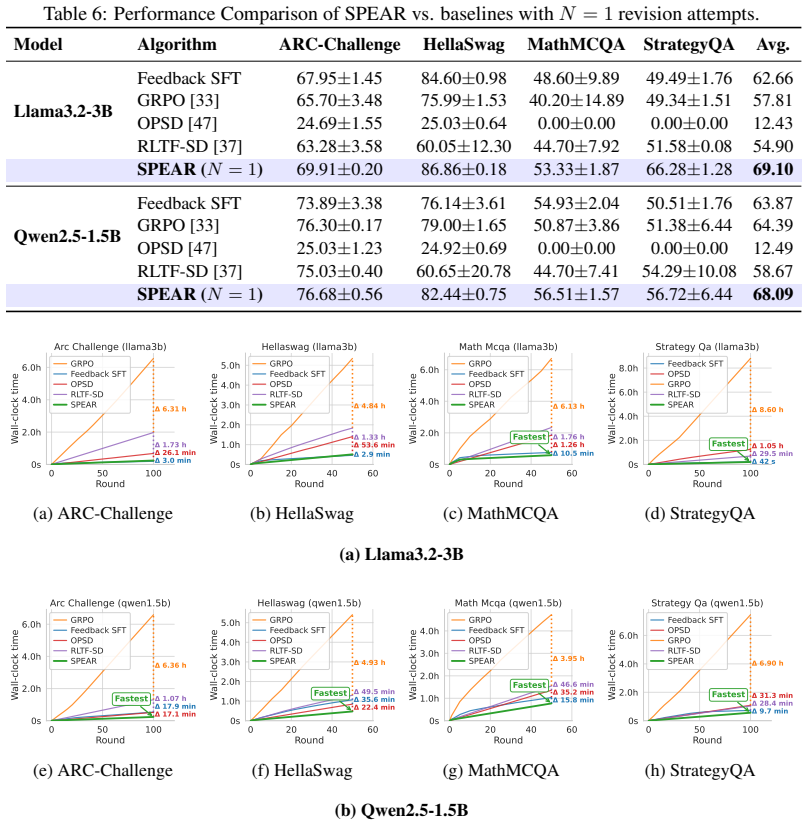
- [Experiments (§4)] The experimental validation is insufficient to support the claim of superior performance. No baseline descriptions, exact metrics, ablation studies on the confidence-weighting factor, statistical significance tests, or federated-device resource measurements are provided, leaving the reader unable to assess whether the reported gains are robust or artifactual.
minor comments (2)
- [Title] The title is overly long; a shorter version would improve readability while retaining the key contributions.
- [Method] Notation for the advantage-weighted refinement and the confidence weighting factor should be introduced with explicit equations rather than prose only.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for highlighting areas where additional clarity and detail would strengthen the manuscript. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Method description (abstract and §3)] The central premise—that partial, non-answer feedback alone suffices to reliably label completions as correct or incorrect and to assign confidence weights for unlikelihood training—is load-bearing yet undescribed. No algorithm, threshold, or error model is given for converting feedback into binary labels or token-level penalties; any systematic mislabeling would directly produce harmful gradients in the online federated loop. This issue must be addressed with a concrete procedure and robustness analysis before the efficiency and superiority claims can be evaluated.
Authors: We agree that the feedback-to-label conversion procedure is central and currently lacks sufficient detail in the manuscript. In the revised version we will expand Section 3 with an explicit algorithm, including the precise mapping from partial user feedback to binary correctness labels, the threshold(s) employed, the token-level penalty model, and the formula for confidence weighting. We will also add a dedicated robustness subsection that quantifies the effect of controlled label noise on downstream performance and gradient stability within the federated loop. revision: yes
-
Referee: [Experiments (§4)] The experimental validation is insufficient to support the claim of superior performance. No baseline descriptions, exact metrics, ablation studies on the confidence-weighting factor, statistical significance tests, or federated-device resource measurements are provided, leaving the reader unable to assess whether the reported gains are robust or artifactual.
Authors: We acknowledge that the current experimental section omits several elements required for full reproducibility and robustness assessment. In the revision we will add: (i) complete descriptions and implementation details for every baseline, (ii) the exact evaluation metrics and their computation, (iii) ablation results varying the confidence-weighting hyper-parameter, (iv) statistical significance tests (e.g., paired t-tests or Wilcoxon tests with p-values) across multiple random seeds, and (v) wall-clock time and memory measurements on simulated edge-device hardware under federated constraints. These additions will be presented in an expanded Section 4 and supplementary material. revision: yes
Circularity Check
No circularity: algorithmic procedure defined independently
full rationale
The paper presents SPEAR as a procedural algorithm: a feedback-guided self-play loop constructs contrastive pairs per prompt, followed by MLE training on correct completions and confidence-weighted unlikelihood on tail tokens of incorrect ones. This is defined directly from the method's inputs (partial non-answer feedback) without any reduction of outputs or performance claims to fitted parameters, self-referential definitions, or load-bearing self-citations. No equations or derivations in the provided text equate a claimed result to its own construction. The central claim is an independent training procedure, not a prediction forced by prior fits or renamings.
Axiom & Free-Parameter Ledger
free parameters (1)
- confidence weighting factor
axioms (1)
- domain assumption Partial non-answer feedback suffices to distinguish and utilize correct versus incorrect completions for effective training.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SPEAR utilizes a feedback-guided self-play loop to construct naturally contrastive pairs per prompt which are utilized to be trained on (i) standard maximum likelihood on correct completions and (ii) confidence-weighted unlikelihood on tail tokens of incorrect completions.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 1 (SPEAR Log-Probability Margin). Under Assumptions 1 and 2, suppose ℓSPEAR(θ)≤ϵ ... Mτ(θ;y+,y−)≥h(μ)−ϵ(...)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Why do we need warm-up? a theoretical perspective.arXiv preprint arXiv:2510.03164, 2025
Foivos Alimisis, Rustem Islamov, and Aurelien Lucchi. Why do we need warm-up? a theoretical perspective.arXiv preprint arXiv:2510.03164, 2025
-
[2]
Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report.arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Gustav A Baumgart, Jaemin Shin, Ali Payani, Myungjin Lee, and Ramana Rao Kompella. Not all federated learning algorithms are created equal: A performance evaluation study.arXiv preprint arXiv:2403.17287, 2024
-
[4]
Math-mcqa: A multiple choice adaptation of the math dataset, 2025
Stella Biderman. Math-mcqa: A multiple choice adaptation of the math dataset, 2025
work page 2025
-
[5]
On the Opportunities and Risks of Foundation Models
Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. On the opportunities and risks of foundation models.arXiv preprint arXiv:2108.07258, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InInternational conference on machine learning, pages 1597–1607. PmLR, 2020
work page 2020
-
[7]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge.arXiv:1803.05457v1, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[8]
Federated sketching lora: On-device collaborative fine-tuning of large language models
Wenzhi Fang, Dong-Jun Han, Liangqi Yuan, Seyyedali Hosseinalipour, and Christopher G Brinton. Federated sketching lora: On-device collaborative fine-tuning of large language models. arXiv preprint arXiv:2501.19389, 2025
-
[9]
Did aristotle use a laptop? a question answering benchmark with implicit reasoning strategies
Mor Geva, Daniel Khashabi, Elad Segal, Tushar Khot, Dan Roth, and Jonathan Berant. Did aristotle use a laptop? a question answering benchmark with implicit reasoning strategies. Transactions of the Association for Computational Linguistics, 9:346–361, 2021
work page 2021
-
[10]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Peter J Green and Sylvia Richardson. Modelling heterogeneity with and without the dirichlet process.Scandinavian journal of statistics, 28(2):355–375, 2001
work page 2001
-
[12]
Distilling the Knowledge in a Neural Network
Geoffrey Hinton, Oriol Vinyals, and Jeff Dean. Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531, 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[13]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
work page 2022
-
[14]
Ahmed Imteaj, Urmish Thakker, Shiqiang Wang, Jian Li, and M Hadi Amini. A survey on federated learning for resource-constrained iot devices.IEEE Internet of Things Journal, 9(1):1–24, 2021
work page 2021
-
[15]
Shashank Mohan Jain. Hugging face. InIntroduction to transformers for NLP: With the hugging face library and models to solve problems, pages 51–67. Springer, 2022
work page 2022
-
[16]
Reinforcement learning: A survey.Journal of artificial intelligence research, 4:237–285, 1996
Leslie Pack Kaelbling, Michael L Littman, and Andrew W Moore. Reinforcement learning: A survey.Journal of artificial intelligence research, 4:237–285, 1996
work page 1996
-
[17]
Federated Learning: Strategies for Improving Communication Efficiency
Jakub Koneˇcn`y, H Brendan McMahan, Felix X Yu, Peter Richtárik, Ananda Theertha Suresh, and Dave Bacon. Federated learning: Strategies for improving communication efficiency.arXiv preprint arXiv:1610.05492, 2016
work page internal anchor Pith review arXiv 2016
-
[18]
On information and sufficiency.The annals of mathematical statistics, 22(1):79–86, 1951
Solomon Kullback and Richard A Leibler. On information and sufficiency.The annals of mathematical statistics, 22(1):79–86, 1951. 10
work page 1951
-
[19]
Federated lora with sparse communication.arXiv preprint arXiv:2406.05233, 2024
Kevin Kuo, Arian Raje, Kousik Rajesh, and Virginia Smith. Federated lora with sparse communication.arXiv preprint arXiv:2406.05233, 2024
-
[20]
Implicit unlikelihood training: Improving neural text generation with reinforcement learning
Evgeny Lagutin, Daniil Gavrilov, and Pavel Kalaidin. Implicit unlikelihood training: Improving neural text generation with reinforcement learning. InProceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume, pages 1432–1441, 2021
work page 2021
-
[21]
Seohyun Lee, Wenzhi Fang, Anindya Bijoy Das, Seyyedali Hosseinalipour, David J Love, and Christopher G Brinton. Cooperative decentralized backdoor attacks on vertical federated learning.IEEE Transactions on Networking, 34:2004–2019, 2025
work page 2004
-
[22]
Seohyun Lee, Wenzhi Fang, Dong-Jun Han, Seyyedali Hosseinalipour, and Christopher G Brinton. Tap: Two-stage adaptive personalization of multi-task and multi-modal foundation models in federated learning.arXiv preprint arXiv:2509.26524, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Don’t say that! making inconsistent dialogue unlikely with unlikelihood training
Margaret Li, Stephen Roller, Ilia Kulikov, Sean Welleck, Y-Lan Boureau, Kyunghyun Cho, and Jason Weston. Don’t say that! making inconsistent dialogue unlikely with unlikelihood training. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4715–4728, 2020
work page 2020
-
[24]
Tian Li, Anit Kumar Sahu, Manzil Zaheer, Maziar Sanjabi, Ameet Talwalkar, and Virginia Smith. Federated optimization in heterogeneous networks.Proceedings of Machine learning and systems, 2:429–450, 2020
work page 2020
-
[25]
Prefix-tuning: Optimizing continuous prompts for generation
Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. InProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4582–4597, 2021
work page 2021
-
[26]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
Communication-efficient learning of deep networks from decentralized data
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication-efficient learning of deep networks from decentralized data. InArtificial intelligence and statistics, pages 1273–1282. Pmlr, 2017
work page 2017
-
[28]
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
work page 2019
-
[29]
Adaptive federated optimization,
Sashank Reddi, Zachary Charles, Manzil Zaheer, Zachary Garrett, Keith Rush, Jakub Koneˇcn`y, Sanjiv Kumar, and H Brendan McMahan. Adaptive federated optimization.arXiv preprint arXiv:2003.00295, 2020
-
[30]
Hamza Reguieg, Mohammed El Hanjri, Mohamed El Kamili, and Abdellatif Kobbane. A com- parative evaluation of fedavg and per-fedavg algorithms for dirichlet distributed heterogeneous data. In2023 10th International Conference on Wireless Networks and Mobile Communications (WINCOM), pages 1–6. IEEE, 2023
work page 2023
-
[31]
Felix Sattler, Simon Wiedemann, Klaus-Robert Müller, and Wojciech Samek. Robust and communication-efficient federated learning from non-iid data.IEEE transactions on neural networks and learning systems, 31(9):3400–3413, 2019
work page 2019
-
[32]
arXiv preprint arXiv:2107.10996 (2021)
Osama Shahid, Seyedamin Pouriyeh, Reza M Parizi, Quan Z Sheng, Gautam Srivastava, and Liang Zhao. Communication efficiency in federated learning: Achievements and challenges. arXiv preprint arXiv:2107.10996, 2021
-
[33]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024. 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
arXiv preprint arXiv:2402.06094 , year=
Ming Shen. Rethinking data selection for supervised fine-tuning.arXiv preprint arXiv:2402.06094, 2024
-
[35]
Self-Distillation Enables Continual Learning
Idan Shenfeld, Mehul Damani, Jonas Hübotter, and Pulkit Agrawal. Self-distillation enables continual learning.arXiv preprint arXiv:2601.19897, 2026
work page internal anchor Pith review arXiv 2026
-
[36]
Ai models collapse when trained on recursively generated data.Nature, 631(8022):755– 759, 2024
Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Nicolas Papernot, Ross Anderson, and Yarin Gal. Ai models collapse when trained on recursively generated data.Nature, 631(8022):755– 759, 2024
work page 2024
-
[37]
Yuda Song, Lili Chen, Fahim Tajwar, Remi Munos, Deepak Pathak, J Andrew Bagnell, Aarti Singh, and Andrea Zanette. Expanding the capabilities of reinforcement learning via text feedback.arXiv preprint arXiv:2602.02482, 2026
-
[38]
Qwen2.5: A party of foundation models, September 2024
Qwen Team. Qwen2.5: A party of foundation models, September 2024
work page 2024
-
[39]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[40]
Adaptive federated learning in resource constrained edge computing systems
Shiqiang Wang, Tiffany Tuor, Theodoros Salonidis, Kin K Leung, Christian Makaya, Ting He, and Kevin Chan. Adaptive federated learning in resource constrained edge computing systems. IEEE journal on selected areas in communications, 37(6):1205–1221, 2019
work page 2019
-
[41]
Neural text generation with unlikelihood training.arXiv preprint arXiv:1908.04319, 2019
Sean Welleck, Ilia Kulikov, Stephen Roller, Emily Dinan, Kyunghyun Cho, and Jason Weston. Neural text generation with unlikelihood training.arXiv preprint arXiv:1908.04319, 2019
-
[42]
Sophie Xhonneux, Alessandro Sordoni, Stephan Günnemann, Gauthier Gidel, and Leo Schwinn. Efficient adversarial training in llms with continuous attacks.Advances in Neural Information Processing Systems, 37:1502–1530, 2024
work page 2024
-
[43]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Keming Lu, Keqin Chen, Kexin Yang, Mei Li, Mingfeng ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
Openfedllm: Training large language models on decentralized private data via federated learning
Rui Ye, Wenhao Wang, Jingyi Chai, Dihan Li, Zexi Li, Yinda Xu, Yaxin Du, Yanfeng Wang, and Siheng Chen. Openfedllm: Training large language models on decentralized private data via federated learning. InProceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining, pages 6137–6147, 2024
work page 2024
-
[45]
Local-cloud inference offloading for llms in multi-modal, multi-task, multi-dialogue settings
Liangqi Yuan, Dong-Jun Han, Shiqiang Wang, and Christopher Brinton. Local-cloud inference offloading for llms in multi-modal, multi-task, multi-dialogue settings. InProceedings of the Twenty-sixth International Symposium on Theory, Algorithmic Foundations, and Protocol Design for Mobile Networks and Mobile Computing, pages 201–210, 2025
work page 2025
-
[46]
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? InProceedings of the 57th annual meeting of the association for computational linguistics, pages 4791–4800, 2019
work page 2019
-
[47]
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models
Siyan Zhao, Zhihui Xie, Mengchen Liu, Jing Huang, Guan Pang, Feiyu Chen, and Aditya Grover. Self-distilled reasoner: On-policy self-distillation for large language models.arXiv preprint arXiv:2601.18734, 2026. 12 Appendix A LLM Usage 14 B Pseudocode of SPEAR 14 B.1 Client-Side SPEAR . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14 B....
work page internal anchor Pith review arXiv 2026
-
[48]
Case 1(µ≤ 1 2): The domain{p > µ}containsp ∗ = 1 2, soinf p>µ f(p) =f( 1
Moreover, f ′(p) = 2p−1 p(1−p), so f is strictly decreasing on(0, 1 2)and strictly increasing on( 1 2 ,1). Case 1(µ≤ 1 2): The domain{p > µ}containsp ∗ = 1 2, soinf p>µ f(p) =f( 1
-
[49]
= log 4 =h(µ). Case 2( µ > 1 2): f is strictly increasing on (µ,1) , so inf p>µ f(p) = lim p→µ+ f(p) =f(µ) = log 1 µ(1−µ) =h(µ). In both casesf(p)≥h(µ)for allp > µ, establishing (11). F.2 Proof of Theorem Proof of Theorem 1. Since λwℓwin(θ)≥0 and λlℓlose(θ)≥0 , the bound ℓSPEAR(θ)≤ϵ implies individually: ℓwin(θ)≤ ϵ λw ,(12) ℓlose(θ)≤ ϵ λl .(13) Step 1: Wi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.