Recognition: 2 theorem links
· Lean TheoremSeeing Across Skies and Streets: Feedforward 3D Reconstruction from Satellite, Drone, and Ground Images
Pith reviewed 2026-05-11 03:01 UTC · model grok-4.3
The pith
A single UAV image supplies cues for 6-DoF poses and 3D structure in feed-forward reconstruction from satellite and ground views.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
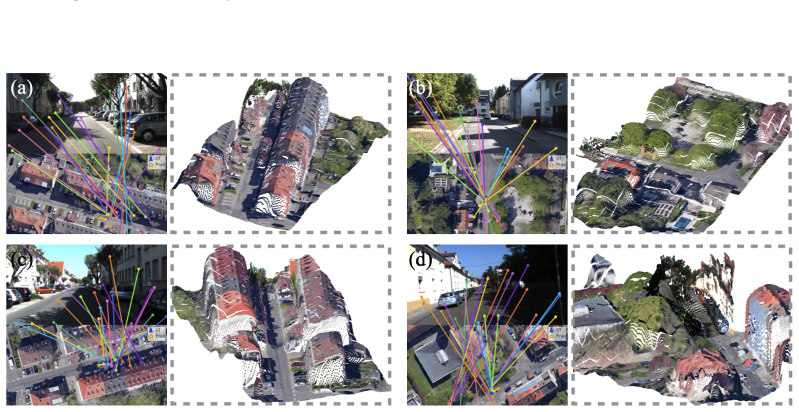
Cross3R ingests a satellite tile together with a UAV image, a ground image, or both, and in a single forward pass recovers a cross-view 3D point cloud, the 6-DoF poses of every input camera, and the on-tile (x,y) position and yaw of each perspective camera.
What carries the argument
The Cross3R feed-forward model, which jointly processes satellite, UAV, and ground images to estimate 3D points and full 6-DoF poses without requiring known relative pose between views.
Load-bearing premise
That one UAV image with only spatial overlap is enough to supply reliable roll, pitch, altitude, and 3D structure cues that the satellite view lacks, and that the model trained on CrossGeo generalizes to new scenes without domain-specific retraining.
What would settle it
Measure the model's estimated roll and pitch errors on a held-out set of images from sloped terrain with independent IMU ground truth; if the 6-DoF errors are no smaller than those of a 3-DoF baseline restricted to planar motion, the central claim does not hold.
Figures













read the original abstract
Cross-view localization classically asks: where does this ground image lie on the satellite tile? Existing methods are typically limited to 3-DoF estimates -- an $(x,y)$ position and a yaw angle -- because nadir satellite imagery provides no direct cues for roll, pitch, or altitude, forcing a reliance on planar-motion and zero-tilt assumptions. These assumptions break on real terrain with slopes, ramps, and tilted camera mounts. To overcome this, we introduce a single UAV image as an intermediate viewpoint: it reveals the 3D structure invisible from nadir, supplies the cues for roll, pitch, and altitude that the satellite alone cannot provide, and needs only spatial overlap with the ground camera -- no known relative pose is required. Building on this insight, we propose **Cross3R**, a flexible feed-forward model that ingests a satellite tile together with a UAV image, a ground image, or both, and, in a single forward pass, recovers a cross-view 3D point cloud, the 6-DoF poses of every input camera, and the on-tile $(x,y)$ position and yaw of each perspective camera. For training and evaluation, we also construct **CrossGeo**, a 278K-image tri-view dataset spanning 85 scenes across every continent except Antarctica. On CrossGeo, Cross3R consistently outperforms feed-forward 3D baselines in point-cloud reconstruction, 6-DoF camera-pose estimation, and cross-view localization. On KITTI, it outperforms dedicated cross-view methods trained on KITTI on most metrics, despite having no KITTI training itself.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Cross3R, a flexible feed-forward model that ingests a satellite tile with optional UAV and/or ground images to recover, in one forward pass, a cross-view 3D point cloud, 6-DoF poses for all input cameras, and the on-tile (x,y) position plus yaw for each perspective camera. It introduces the CrossGeo dataset (278K tri-view images across 85 global scenes) for training and evaluation, claiming consistent outperformance over feed-forward 3D baselines on CrossGeo for point-cloud reconstruction, 6-DoF pose estimation, and cross-view localization, plus generalization to KITTI without KITTI-specific training.
Significance. If the empirical claims hold after detailed validation, the work offers a meaningful advance in cross-view 3D reconstruction by using an intermediate UAV view to relax planar-motion and zero-tilt assumptions, enabling full 6-DoF recovery from nadir satellite imagery. The large-scale, multi-continent CrossGeo dataset is a clear contribution. The feed-forward, input-flexible design is practically attractive for applications in localization and mapping.
major comments (2)
- [Abstract] Abstract: the claims of outperformance on CrossGeo and KITTI are presented without any architectural details, loss functions, training procedure, or error analysis. These omissions are load-bearing because the central contribution is an empirical demonstration of a new model on a new dataset; without them, reproducibility and the source of gains cannot be assessed.
- [Abstract] Abstract and introduction: the key modeling assumption that a single UAV image with only spatial overlap (no known relative pose) supplies reliable cues for roll, pitch, altitude, and 3D structure is stated but not accompanied by ablations, sensitivity analysis, or failure-case discussion. This assumption directly underpins the 6-DoF claims and generalization statements.
minor comments (1)
- [Abstract] Abstract: the phrasing of the KITTI generalization result (outperforms dedicated methods 'on most metrics') would be clearer if the specific metrics and the magnitude of improvement were summarized.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract and the central modeling assumption. We address each major comment below, clarifying where the full manuscript already provides the requested details and proposing targeted revisions to improve accessibility and explicitness.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claims of outperformance on CrossGeo and KITTI are presented without any architectural details, loss functions, training procedure, or error analysis. These omissions are load-bearing because the central contribution is an empirical demonstration of a new model on a new dataset; without them, reproducibility and the source of gains cannot be assessed.
Authors: The abstract is intentionally concise as a high-level overview. The full manuscript provides the architectural details in Section 3, the loss functions and training procedure in Section 4, and error analysis together with ablation studies in Section 5. To directly address the concern about assessing reproducibility and sources of gains from the abstract, we will revise it to include a brief outline of the model components, training approach, and key evaluation metrics. revision: yes
-
Referee: [Abstract] Abstract and introduction: the key modeling assumption that a single UAV image with only spatial overlap (no known relative pose) supplies reliable cues for roll, pitch, altitude, and 3D structure is stated but not accompanied by ablations, sensitivity analysis, or failure-case discussion. This assumption directly underpins the 6-DoF claims and generalization statements.
Authors: The assumption is central and is supported by empirical evidence already present in the manuscript. Section 5.2 contains ablations isolating the UAV view's contribution to 6-DoF recovery, Section 5.3 provides sensitivity analysis across overlap ratios and pose variations, and Section 5.4 discusses failure cases where the UAV cue is insufficient. To make this linkage more explicit in the introduction (as requested), we will add a short paragraph summarizing these results while retaining the existing detailed analysis in the experiments section. revision: partial
Circularity Check
No significant circularity
full rationale
The paper introduces a new feed-forward model (Cross3R) and a new tri-view dataset (CrossGeo) for joint 3D reconstruction and pose estimation from satellite/UAV/ground images. All central claims rest on training the model on CrossGeo and reporting empirical metrics on CrossGeo plus zero-shot generalization to KITTI. No equations, derivations, fitted parameters, or self-citations are presented that reduce any output to the inputs by construction. The argument is self-contained as a standard empirical ML contribution.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A neural network trained on multi-view image pairs can infer 3D structure and 6-DoF poses from spatial overlap alone
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Cross3R ... recovers a cross-view 3D point cloud, the 6-DoF poses of every input camera, and the on-tile (x,y) position and yaw ... via orthographic geometric prior ... per-sample altitude redefinition
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Loss functions ... Lgeo ... Lnorm ... Lcam
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Pearson correlation coefficient
Jacob Benesty, Jingdong Chen, Yiteng Huang, and Israel Cohen. Pearson correlation coefficient. InNoise reduction in speech processing, pages 1–4. Springer, 2009
work page 2009
-
[2]
Eric Brachmann, Jamie Wynn, Shuai Chen, Tommaso Cavallari, Áron Monszpart, Daniyar Turmukhambetov, and Victor Adrian Prisacariu. Scene coordinate reconstruction: Posing of image collections via incremental learning of a relocalizer. InECCV, 2024
work page 2024
-
[3]
Deepvideomvs: Multi-view stereo on video with recurrent spatio-temporal fusion
Arda Duzceker, Silvano Galliani, Christoph V ogel, Pablo Speciale, Mihai Dusmanu, and Marc Pollefeys. Deepvideomvs: Multi-view stereo on video with recurrent spatio-temporal fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15324–15333, 2021
work page 2021
-
[4]
David Eigen, Christian Puhrsch, and Rob Fergus. Depth map prediction from a single image using a multi-scale deep network.Advances in neural information processing systems, 27, 2014
work page 2014
-
[5]
Light3r-sfm: Towards feed-forward structure- from-motion
Sven Elflein, Qunjie Zhou, and Laura Leal-Taixé. Light3r-sfm: Towards feed-forward structure- from-motion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16774–16784, 2025
work page 2025
-
[6]
Yasutaka Furukawa and Carlos Hernández. Multi-view stereo: A tutorial.Foundations and Trends in Computer Graphics and Vision, 9(1-2):1–148, 2015
work page 2015
-
[7]
Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The kitti dataset.The international journal of robotics research, 32(11):1231–1237, 2013
work page 2013
-
[8]
Panovggt: Feed-forward 3d reconstruction from panoramic imagery, 2026
Yijing Guo, Mengjun Chao, Luo Wang, Tianyang Zhao, Haizhao Dai, Yingliang Zhang, Jingyi Yu, and Yujiao Shi. Panovggt: Feed-forward 3d reconstruction from panoramic imagery.arXiv preprint arXiv:2603.17571, 2026
-
[9]
Towards high- resolution large-scale multi-view stereo
Vu Hoang Hiep, Renaud Keriven, Patrick Labatut, and Jean-Philippe Pons. Towards high- resolution large-scale multi-view stereo. In2009 IEEE conference on computer vision and pattern recognition, pages 1430–1437. IEEE, 2009
work page 2009
-
[10]
Mvsany- where: Zero-shot multi-view stereo
Sergio Izquierdo, Mohamed Sayed, Michael Firman, Guillermo Garcia-Hernando, Daniyar Tur- mukhambetov, Javier Civera, Oisin Mac Aodha, Gabriel Brostow, and Jamie Watson. Mvsany- where: Zero-shot multi-view stereo. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 11493–11504, 2025
work page 2025
-
[11]
Large scale multi-view stereopsis evaluation
Rasmus Jensen, Anders Dahl, George V ogiatzis, Engin Tola, and Henrik Aanæs. Large scale multi-view stereopsis evaluation. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 406–413, 2014
work page 2014
-
[12]
Game4loc: A uav geo-localization benchmark from game data
Yuxiang Ji, Boyong He, Zhuoyue Tan, and Liaoni Wu. Game4loc: A uav geo-localization benchmark from game data. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 3913–3921, 2025
work page 2025
-
[13]
Yuhe Jin, Dmytro Mishkin, Anastasiia Mishchuk, Jiri Matas, Pascal Fua, Kwang Moo Yi, and Eduard Trulls. Image matching across wide baselines: From paper to practice.International Journal of Computer Vision, 129(2):517–547, 2021. 10
work page 2021
-
[14]
Neil Joshi, Joshua Carney, Nathanael Kuo, Homer Li, Cheng Peng, and Myron Brown. Ultrra challenge 2025, 2024. URLhttps://dx.doi.org/10.21227/2zs6-ht63
-
[15]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
Nikhil Keetha, Norman Müller, Johannes Schönberger, Lorenzo Porzi, Yuchen Zhang, Tobias Fischer, Arno Knapitsch, Duncan Zauss, Ethan Weber, Nelson Antunes, et al. Mapanything: Universal feed-forward metric 3d reconstruction.arXiv preprint arXiv:2509.13414, 2025
work page internal anchor Pith review arXiv 2025
-
[16]
Pidloc: Cross-view pose optimization network inspired by pid controllers
Wooju Lee, Juhye Park, Dasol Hong, Changki Sung, Youngwoo Seo, Dongwan Kang, and Hyun Myung. Pidloc: Cross-view pose optimization network inspired by pid controllers. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 21981–21990, 2025
work page 2025
-
[17]
Slicematch: Geometry-guided aggregation for cross-view pose estimation
Ted Lentsch, Zimin Xia, Holger Caesar, and Julian FP Kooij. Slicematch: Geometry-guided aggregation for cross-view pose estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17225–17234, 2023
work page 2023
-
[18]
Grounding image matching in 3d with mast3r
Vincent Leroy, Yohann Cabon, and Jérôme Revaud. Grounding image matching in 3d with mast3r. InEuropean conference on computer vision, pages 71–91. Springer, 2024
work page 2024
-
[19]
Yaxuan Li, Yewei Huang, Bijay Gaudel, Hamidreza Jafarnejadsani, and Brendan Englot. Cvd- sfm: A cross-view deep front-end structure-from-motion system for sparse localization in multi-altitude scenes. In2025 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 10741–10748. IEEE, 2025
work page 2025
-
[20]
Zhiqi Li, Wenhai Wang, Hongyang Li, Enze Xie, Chonghao Sima, Tong Lu, Qiao Yu, and Jifeng Dai. Bevformer: learning bird’s-eye-view representation from lidar-camera via spatiotemporal transformers.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(3):2020– 2036, 2024
work page 2020
-
[21]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Junhao Liew, Donny Y Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[22]
Pixel-perfect structure-from-motion with featuremetric refinement
Philipp Lindenberger, Paul-Edouard Sarlin, Viktor Larsson, and Marc Pollefeys. Pixel-perfect structure-from-motion with featuremetric refinement. InProceedings of the IEEE/CVF interna- tional conference on computer vision, pages 5987–5997, 2021
work page 2021
-
[23]
Lending orientation to neural networks for cross-view geo- localization
Liu Liu and Hongdong Li. Lending orientation to neural networks for cross-view geo- localization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5624–5633, 2019
work page 2019
-
[24]
Slam3r: Real-time dense scene reconstruction from monocular rgb videos
Yuzheng Liu, Siyan Dong, Shuzhe Wang, Yingda Yin, Yanchao Yang, Qingnan Fan, and Baoquan Chen. Slam3r: Real-time dense scene reconstruction from monocular rgb videos. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 16651–16662, 2025
work page 2025
-
[25]
Nerf: Representing scenes as neural radiance fields for view synthesis
Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoor- thi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 65(1):99–106, 2021
work page 2021
-
[26]
Global structure- from-motion revisited
Linfei Pan, Dániel Baráth, Marc Pollefeys, and Johannes L Schönberger. Global structure- from-motion revisited. InEuropean Conference on Computer Vision, pages 58–77. Springer, 2024
work page 2024
-
[27]
OrienterNet: Visual Localization in 2D Public Maps with Neural Matching
Paul-Edouard Sarlin, Daniel DeTone, Tsun-Yi Yang, Armen Avetisyan, Julian Straub, Tomasz Malisiewicz, Samuel Rota Bulo, Richard Newcombe, Peter Kontschieder, and Vasileios Balntas. OrienterNet: Visual Localization in 2D Public Maps with Neural Matching. InCVPR, 2023
work page 2023
-
[28]
Paul-Edouard Sarlin, Eduard Trulls, Marc Pollefeys, Jan Hosang, and Simon Lynen. Snap: Self-supervised neural maps for visual positioning and semantic understanding.Advances in Neural Information Processing Systems, 36:7697–7729, 2023. 11
work page 2023
-
[29]
Structure-from-motion revisited
Johannes L Schonberger and Jan-Michael Frahm. Structure-from-motion revisited. InProceed- ings of the IEEE conference on computer vision and pattern recognition, pages 4104–4113, 2016
work page 2016
-
[30]
A vote-and-verify strategy for fast spatial verification in image retrieval
Johannes Lutz Schönberger, True Price, Torsten Sattler, Jan-Michael Frahm, and Marc Pollefeys. A vote-and-verify strategy for fast spatial verification in image retrieval. InAsian Conference on Computer Vision (ACCV), 2016
work page 2016
-
[31]
A multi-view stereo benchmark with high-resolution images and multi-camera videos
Thomas Schops, Johannes L Schonberger, Silvano Galliani, Torsten Sattler, Konrad Schindler, Marc Pollefeys, and Andreas Geiger. A multi-view stereo benchmark with high-resolution images and multi-camera videos. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 3260–3269, 2017
work page 2017
-
[32]
Beyond cross-view image retrieval: Highly accurate vehicle localization using satellite image
Yujiao Shi and Hongdong Li. Beyond cross-view image retrieval: Highly accurate vehicle localization using satellite image. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 17010–17020, 2022
work page 2022
-
[33]
Yujiao Shi, Xin Yu, Liu Liu, Dylan Campbell, Piotr Koniusz, and Hongdong Li. Accurate 3-dof camera geo-localization via ground-to-satellite image matching.IEEE transactions on pattern analysis and machine intelligence, 45(3):2682–2697, 2022
work page 2022
-
[34]
Weakly-supervised camera localization by ground-to-satellite image registration
Yujiao Shi, Hongdong Li, Akhil Perincherry, and Ankit V ora. Weakly-supervised camera localization by ground-to-satellite image registration. InEuropean Conference on Computer Vision, pages 39–57. Springer, 2024
work page 2024
-
[35]
Zhenbo Song, Jianfeng Lu, Yujiao Shi, et al. Learning dense flow field for highly-accurate cross-view camera localization.Advances in Neural Information Processing Systems, 36: 70612–70625, 2023
work page 2023
-
[36]
Geodistill: Geometry- guided self-distillation for weakly supervised cross-view localization
Shaowen Tong, Zimin Xia, Alexandre Alahi, Xuming He, and Yujiao Shi. Geodistill: Geometry- guided self-distillation for weakly supervised cross-view localization. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 25357–25366, 2025
work page 2025
-
[37]
Aerialmegadepth: Learning aerial-ground reconstruction and view synthesis
Khiem Vuong, Anurag Ghosh, Deva Ramanan, Srinivasa Narasimhan, and Shubham Tulsiani. Aerialmegadepth: Learning aerial-ground reconstruction and view synthesis. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21674–21684, 2025
work page 2025
-
[38]
Vggsfm: Visual geometry grounded deep structure from motion
Jianyuan Wang, Nikita Karaev, Christian Rupprecht, and David Novotny. Vggsfm: Visual geometry grounded deep structure from motion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 21686–21697, 2024
work page 2024
-
[39]
Vggt: Visual geometry grounded transformer
Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, and David Novotny. Vggt: Visual geometry grounded transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5294–5306, 2025
work page 2025
-
[40]
Continuous 3d perception model with persistent state
Qianqian Wang, Yifei Zhang, Aleksander Holynski, Alexei A Efros, and Angjoo Kanazawa. Continuous 3d perception model with persistent state. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 10510–10522, 2025
work page 2025
-
[41]
Qiwei Wang, Shaoxun Wu, and Yujiao Shi. Bevsplat: Resolving height ambiguity via feature- based gaussian primitives for weakly-supervised cross-view localization.arXiv preprint arXiv:2502.09080, 2025
-
[42]
View from above: Orthogonal-view aware cross-view localization
Shan Wang, Chuong Nguyen, Jiawei Liu, Yanhao Zhang, Sundaram Muthu, Fahira Afzal Maken, Kaihao Zhang, and Hongdong Li. View from above: Orthogonal-view aware cross-view localization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14843–14852, 2024
work page 2024
-
[43]
Dust3r: Geometric 3d vision made easy
Shuzhe Wang, Vincent Leroy, Yohann Cabon, Boris Chidlovskii, and Jerome Revaud. Dust3r: Geometric 3d vision made easy. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20697–20709, 2024. 12
work page 2024
-
[44]
Xiaolong Wang, Runsen Xu, Zhuofan Cui, Zeyu Wan, and Yu Zhang. Fine-grained cross- view geo-localization using a correlation-aware homography estimator.Advances in Neural Information Processing Systems, 36:5301–5319, 2023
work page 2023
-
[45]
$\pi^3$: Permutation-Equivariant Visual Geometry Learning
Yifan Wang, Jianjun Zhou, Haoyi Zhu, Wenzheng Chang, Yang Zhou, Zizun Li, Junyi Chen, Jiangmiao Pang, Chunhua Shen, and Tong He. π3: Permutation-equivariant visual geometry learning.arXiv preprint arXiv:2507.13347, 2025
work page internal anchor Pith review arXiv 2025
-
[46]
Depth anything with any prior.arXiv preprint arXiv:2505.10565, 2025
Zehan Wang, Siyu Chen, Lihe Yang, Jialei Wang, Ziang Zhang, Hengshuang Zhao, and Zhou Zhao. Depth anything with any prior.arXiv preprint arXiv:2505.10565, 2025
-
[47]
Zhaoying Wang, Xingxing Zuo, and Wei Dong. Flying co-stereo: Enabling long-range aerial dense mapping via collaborative stereo vision of dynamic-baseline.IEEE Transactions on Robotics, 2026
work page 2026
-
[48]
Fcos: Fully convolutional one-stage object detection
Scott Workman, Richard Souvenir, and Nathan Jacobs. Wide-area image geolocalization with aerial reference imagery. InIEEE International Conference on Computer Vision (ICCV), pages 1–9, 2015. doi: 10.1109/ICCV .2015.451. Acceptance rate: 30.3%
-
[49]
Fgˆ 2: Fine-grained cross-view localization by fine-grained feature matching
Zimin Xia and Alexandre Alahi. Fgˆ 2: Fine-grained cross-view localization by fine-grained feature matching. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6362–6372, 2025
work page 2025
-
[50]
Zimin Xia, Olaf Booij, and Julian FP Kooij. Convolutional cross-view pose estimation.IEEE Transactions on Pattern Analysis and Machine Intelligence, 46(5):3813–3831, 2023
work page 2023
-
[51]
Uav-visloc: A large-scale dataset for uav visual localization,
Wenjia Xu, Yaxuan Yao, Jiaqi Cao, Zhiwei Wei, Chunbo Liu, Jiuniu Wang, and Mugen Peng. Uav-visloc: A large-scale dataset for uav visual localization.arXiv preprint arXiv:2405.11936, 2024
-
[52]
Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass
Jianing Yang, Alexander Sax, Kevin J Liang, Mikael Henaff, Hao Tang, Ang Cao, Joyce Chai, Franziska Meier, and Matt Feiszli. Fast3r: Towards 3d reconstruction of 1000+ images in one forward pass. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 21924–21935, 2025
work page 2025
-
[53]
Articulated pose estimation with flexible mixtures-of-parts
Yi Yang and Deva Ramanan. Articulated pose estimation with flexible mixtures-of-parts. In CVPR 2011, pages 1385–1392. IEEE, 2011
work page 2011
-
[54]
Mvsnet: Depth inference for unstructured multi-view stereo
Yao Yao, Zixin Luo, Shiwei Li, Tian Fang, and Long Quan. Mvsnet: Depth inference for unstructured multi-view stereo. InProceedings of the European conference on computer vision (ECCV), pages 767–783, 2018
work page 2018
-
[55]
Yibin Ye, Xichao Teng, Shuo Chen, Zhang Li, Leqi Liu, Qifeng Yu, and Tao Tan. Exploring the best way for uav visual localization under low-altitude multi-view observation condition: a benchmark.arXiv preprint arXiv:2503.10692, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Learning to find good correspondences
Kwang Moo Yi, Eduard Trulls, Yuki Ono, Vincent Lepetit, Mathieu Salzmann, and Pascal Fua. Learning to find good correspondences. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2666–2674, 2018
work page 2018
-
[57]
Diffusionsfm: Predicting structure and motion via ray origin and endpoint diffusion
Qitao Zhao, Amy Lin, Jeff Tan, Jason Y Zhang, Deva Ramanan, and Shubham Tulsiani. Diffusionsfm: Predicting structure and motion via ray origin and endpoint diffusion. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 6317–6326, 2025
work page 2025
-
[58]
University-1652: A multi-view multi-source benchmark for drone-based geo-localization
Zhedong Zheng, Yunchao Wei, and Yi Yang. University-1652: A multi-view multi-source benchmark for drone-based geo-localization. InProceedings of the 28th ACM international conference on Multimedia, pages 1395–1403, 2020
work page 2020
-
[59]
Runzhe Zhu, Ling Yin, Mingze Yang, Fei Wu, Yuncheng Yang, and Wenbo Hu. Sues-200: A multi-height multi-scene cross-view image benchmark across drone and satellite.IEEE Transactions on Circuits and Systems for Video Technology, pages 1–1, 2023. doi: 10.1109/ TCSVT.2023.3249204. 13
-
[60]
Sijie Zhu, Taojiannan Yang, and Chen Chen. Vigor: Cross-view image geo-localization beyond one-to-one retrieval. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3640–3649, 2021. 14 Supplementary Contents A Related Work 15 B CrossGeo Dataset Details 16 B.1 Dataset Overview . . . . . . . . . . . . . . . . . . . . ....
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.