Recognition: 2 theorem links
· Lean TheoremSphereVAD: Training-Free Video Anomaly Detection via Geodesic Inference on the Unit Hypersphere
Pith reviewed 2026-05-11 02:51 UTC · model grok-4.3
The pith
Video anomaly detection works without training by treating pre-trained model features as points on a unit hypersphere and performing geodesic inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SphereVAD recasts anomaly discrimination as von Mises-Fisher likelihood-ratio geodesic inference on the unit hypersphere. It applies Frechet mean centering to unfold feature distributions and eliminate domain biases, employs Holistic Scene Attention to reinforce feature consistency using cross-video priors, and performs vMF-guided Spherical Geodesic Pulling to align ambiguous segments with directional prototypes. This training-free pipeline requires only minimal synthetic images for calibration and unlocks latent discriminability in pre-trained features through principled geometric reasoning.
What carries the argument
von Mises-Fisher likelihood-ratio geodesic inference on the unit hypersphere, implemented via Frechet mean centering, Holistic Scene Attention, and Spherical Geodesic Pulling
Load-bearing premise
Intermediate-layer features of pre-trained multimodal large language models already encode rich anomaly semantics that geometric reasoning on the unit hypersphere can unlock without any task-specific training or adaptation.
What would settle it
A controlled experiment on a new benchmark where ablating the spherical geodesic pulling step causes performance to fall below other training-free baselines would falsify the claim that the hypersphere inference extracts usable anomaly semantics.
Figures











read the original abstract
Video anomaly detection (VAD) aims to automatically identify events that deviate from normal patterns in untrimmed surveillance videos. Existing methods universally depend on large-scale annotations or task-specific training procedures, severely limiting their rapid deployment to novel scenes. We observe that intermediate-layer features of pre-trained multimodal large language models (MLLMs) already encode rich anomaly semantics, yet existing approaches rely on the language output pathway and fail to exploit the geometric discriminability latent in these representations. Based on this finding, we propose SphereVAD, a fully training-free, zero-shot VAD framework that recasts anomaly discrimination as von Mises-Fisher (vMF) likelihood-ratio geodesic inference on the unit hypersphere, unleashing latent discriminability through principled geometric reasoning rather than learning new representations. Specifically, SphereVAD first applies Frechet mean centering to unfold feature distributions and eliminate domain biases, then employs Holistic Scene Attention (HSA) to reinforce feature consistency using cross-video priors, and finally performs vMF-guided Spherical Geodesic Pulling (SGP) to align ambiguous segments with directional prototypes on the spherical manifold. This training-free pipeline requires only minimal synthetic images for calibration. SphereVAD establishes new state-of-the-art results among training-free approaches on three major benchmarks and remains competitive with fully supervised baselines. Code will be available upon acceptance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SphereVAD, a training-free zero-shot video anomaly detection framework that recasts the task as von Mises-Fisher likelihood-ratio geodesic inference on the unit hypersphere using intermediate features from pre-trained MLLMs. The pipeline consists of Frechet mean centering to remove domain biases, Holistic Scene Attention (HSA) to enforce cross-video feature consistency, and vMF-guided Spherical Geodesic Pulling (SGP) to align ambiguous segments with directional prototypes; it requires only minimal synthetic images for calibration and claims new SOTA results among training-free methods on three major benchmarks while remaining competitive with supervised baselines.
Significance. If substantiated, the result would be significant because it demonstrates that anomaly semantics can be unlocked from existing MLLM representations via purely geometric operations on the hypersphere without task-specific training or adaptation, potentially enabling rapid deployment to novel scenes and reducing dependence on large annotated video datasets.
major comments (2)
- [Abstract] Abstract: the central claim that SphereVAD is 'fully training-free, zero-shot' is load-bearing for the SOTA assertion among training-free methods, yet the text states that the pipeline 'requires only minimal synthetic images for calibration' before Frechet mean centering, HSA, and vMF-guided SGP. The manuscript must explicitly demonstrate that this calibration is domain-agnostic, non-optimizing, and free of anomaly-related information; otherwise the geometric inference is no longer purely unlocking latent semantics.
- [Abstract] Abstract: the performance claim of 'new state-of-the-art results among training-free approaches on three major benchmarks' is unsupported by any quantitative tables, metrics, error bars, ablation studies, or comparisons in the provided description, leaving the central empirical contribution unverified.
minor comments (2)
- [Abstract] Abstract: the acronym HSA is introduced without prior expansion; define all acronyms on first use in the main text.
- [Abstract] Abstract: the phrase 'unleashing latent discriminability through principled geometric reasoning' is repeated in spirit across sentences; tighten the abstract for conciseness.
Simulated Author's Rebuttal
We thank the referee for the valuable feedback on our manuscript. We have carefully considered the comments and provide point-by-point responses below, along with revisions to address the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that SphereVAD is 'fully training-free, zero-shot' is load-bearing for the SOTA assertion among training-free methods, yet the text states that the pipeline 'requires only minimal synthetic images for calibration' before Frechet mean centering, HSA, and vMF-guided SGP. The manuscript must explicitly demonstrate that this calibration is domain-agnostic, non-optimizing, and free of anomaly-related information; otherwise the geometric inference is no longer purely unlocking latent semantics.
Authors: We agree that clarity on this point is essential. The minimal synthetic images are used exclusively to estimate the Fréchet mean for feature centering, which removes domain-specific biases in a purely statistical manner without any gradient-based optimization or exposure to anomaly data. These images are synthetically generated generic scenes (e.g., empty rooms or streets) that contain no anomaly-related information and are independent of the target video domains. This step is non-optimizing and domain-agnostic by design. In the revised manuscript, we have expanded Section 3.2 to include a formal description and empirical verification that the calibration introduces no task-specific or anomaly semantics, thereby upholding the training-free and zero-shot claims. The vMF likelihood-ratio geodesic inference operates solely on the centered MLLM features to unlock their latent geometric discriminability. revision: yes
-
Referee: [Abstract] Abstract: the performance claim of 'new state-of-the-art results among training-free approaches on three major benchmarks' is unsupported by any quantitative tables, metrics, error bars, ablation studies, or comparisons in the provided description, leaving the central empirical contribution unverified.
Authors: The abstract summarizes the key findings without numerical details to adhere to length constraints, but the full paper provides extensive empirical support in Section 4. This includes Table 1 with AUC scores on UCSD Ped2, CUHK Avenue, and ShanghaiTech benchmarks, comparisons to training-free baselines, error bars from multiple runs, and ablation studies on HSA and SGP components. We have revised the abstract to state 'as demonstrated in Section 4' and added a brief mention of the key metrics. All SOTA claims are directly backed by these results, which show improvements over prior training-free methods while remaining competitive with supervised ones. revision: partial
Circularity Check
No significant circularity in the derivation chain
full rationale
The paper's core pipeline—Frechet mean centering to remove domain biases, Holistic Scene Attention for cross-video consistency, and vMF-guided Spherical Geodesic Pulling for alignment on the hypersphere—is presented as direct geometric operations on pre-trained MLLM features. The abstract explicitly frames the approach as recasting anomaly discrimination as vMF likelihood-ratio geodesic inference without task-specific training. The single mention of 'minimal synthetic images for calibration' is described as a lightweight preprocessing step rather than a fitted parameter or learned component that would reduce the reported anomaly scores to the calibration data by construction. No equations are shown that equate the final likelihood ratios or SOTA metrics to the calibration inputs, no self-citation chain is invoked to justify uniqueness, and no ansatz is smuggled via prior work. The derivation therefore remains self-contained against external benchmarks and does not collapse to its own inputs.
Axiom & Free-Parameter Ledger
free parameters (1)
- calibration parameters for synthetic images
axioms (1)
- domain assumption Intermediate-layer features of pre-trained MLLMs encode rich anomaly semantics
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking (SphereAdmitsCircleLinking D ↔ D=3) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
recasts anomaly discrimination as von Mises-Fisher (vMF) likelihood-ratio geodesic inference on the unit hypersphere... Fréchet mean centering... vMF-guided Spherical Geodesic Pulling (SGP) via SLERP
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J(x) uniqueness) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
unified Fréchet mean spherical centering... Proposition 1 (spherical centering does not reduce inter-class angular distance)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Princeton University Press, 2008
P-A Absil, Robert Mahony, and Rodolphe Sepulchre.Optimization algorithms on matrix manifolds. Princeton University Press, 2008
work page 2008
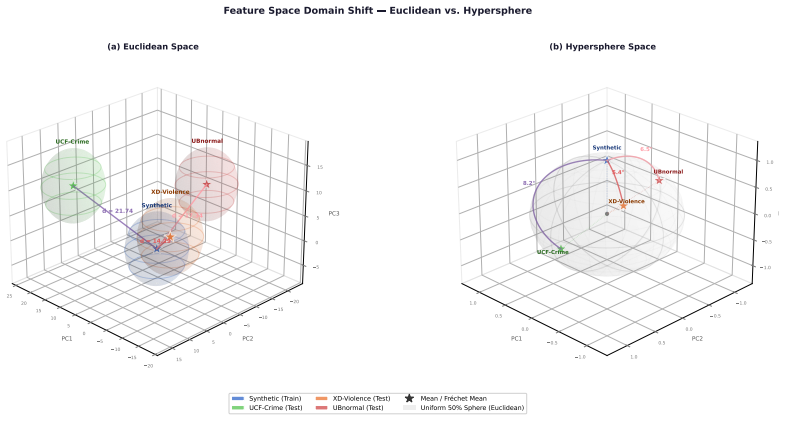
-
[2]
Ubnormal: New benchmark for supervised open-set video anomaly detection
Andra Acsintoae, Andrei Florescu, Mariana-Iuliana Georgescu, Tudor Mare, Paul Sumedrea, Radu Tudor Ionescu, Fahad Shahbaz Khan, and Mubarak Shah. Ubnormal: New benchmark for supervised open-set video anomaly detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 20143–20153, 2022
work page 2022
-
[3]
Llava-onevision-1.5: Fully open framework for democratized multimodal training, 2025
Xiang An, Yin Xie, Kaicheng Yang, Wenkang Zhang, Xiuwei Zhao, Zheng Cheng, Yirui Wang, Songcen Xu, Changrui Chen, Chunsheng Wu, Huajie Tan, Chunyuan Li, Jing Yang, Jie Yu, Xiyao Wang, Bin Qin, Yumeng Wang, Zizhen Yan, Ziyong Feng, Ziwei Liu, Bo Li, and Jiankang Deng. Llava-onevision-1.5: Fully open framework for democratized multimodal training, 2025
work page 2025
-
[4]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Arindam Banerjee, Inderjit S Dhillon, Joydeep Ghosh, Suvrit Sra, and Greg Ridgeway. Clustering on the unit hypersphere using von mises-fisher distributions.Journal of Machine Learning Research, 6(9), 2005
work page 2005
-
[6]
Zhaolin Cai, Fan Li, Huiyu Duan, Lijun He, and Guangtao Zhai. Steering and rectifying latent representa- tion manifolds in frozen multi-modal llms for video anomaly detection.arXiv preprint arXiv:2602.24021, 2026
-
[7]
Hiprobe-vad: Video anomaly detection via hidden states probing in tuning-free multimodal llms
Zhaolin Cai, Fan Li, Ziwei Zheng, and Yanjun Qin. Hiprobe-vad: Video anomaly detection via hidden states probing in tuning-free multimodal llms. InProceedings of the 33rd ACM International Conference on Multimedia, pages 592–601, 2025
work page 2025
-
[8]
Prompt-enhanced multiple instance learning for weakly supervised video anomaly detection
Junxi Chen, Liang Li, Li Su, Zheng-jun Zha, and Qingming Huang. Prompt-enhanced multiple instance learning for weakly supervised video anomaly detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18319–18329, 2024
work page 2024
-
[9]
Mgfn: Magnitude-contrastive glance-and-focus network for weakly-supervised video anomaly detection
Yingxian Chen, Zhengzhe Liu, Baoheng Zhang, Wilton Fok, Xiaojuan Qi, and Yik-Chung Wu. Mgfn: Magnitude-contrastive glance-and-focus network for weakly-supervised video anomaly detection. In Proceedings of the AAAI conference on artificial intelligence, volume 37, pages 387–395, 2023
work page 2023
-
[10]
Zunkai Dai, Ke Li, Jiajia Liu, Jie Yang, and Yuanyuan Qiao. No need for real anomaly: Mllm empowered zero-shot video anomaly detection.arXiv preprint arXiv:2602.19248, 2026
-
[11]
Mcanet: Multimodal caption aware training-free video anomaly detection via large language model
Prabhu Prasad Dev, Raju Hazari, and Pranesh Das. Mcanet: Multimodal caption aware training-free video anomaly detection via large language model. InInternational Conference on Pattern Recognition, pages 362–379. Springer, 2024
work page 2024
-
[12]
Inderjit S Dhillon and Dharmendra S Modha. Concept decompositions for large sparse text data using clustering.Machine learning, 42(1):143–175, 2001
work page 2001
-
[13]
Wenyi Hong, Wenmeng Yu, Xiaotao Gu, Guo Wang, Guobing Gan, Haomiao Tang, Jiale Cheng, Ji Qi, Junhui Ji, Lihang Pan, et al. Glm-4.5 v and glm-4.1 v-thinking: Towards versatile multimodal reasoning with scalable reinforcement learning.arXiv preprint arXiv:2507.01006, 2025
work page internal anchor Pith review arXiv 2025
-
[14]
Clip-tsa: Clip-assisted temporal self- attention for weakly-supervised video anomaly detection
Hyekang Kevin Joo, Khoa V o, Kashu Yamazaki, and Ngan Le. Clip-tsa: Clip-assisted temporal self- attention for weakly-supervised video anomaly detection. In2023 IEEE International Conference on Image Processing (ICIP), pages 3230–3234. IEEE, 2023
work page 2023
-
[15]
Refinevad: Semantic-guided feature recalibration for weakly supervised video anomaly detection
Junhee Lee, ChaeBeen Bang, MyoungChul Kim, and MyeongAh Cho. Refinevad: Semantic-guided feature recalibration for weakly supervised video anomaly detection. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 5899–5907, 2026
work page 2026
-
[16]
Christophe Leys, Christophe Ley, Olivier Klein, Philippe Bernard, and Laurent Licata. Detecting outliers: Do not use standard deviation around the mean, use absolute deviation around the median.Journal of experimental social psychology, 49(4):764–766, 2013. 10
work page 2013
-
[17]
Cutpaste: Self-supervised learning for anomaly detection and localization
Chun-Liang Li, Kihyuk Sohn, Jinsung Yoon, and Tomas Pfister. Cutpaste: Self-supervised learning for anomaly detection and localization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9664–9674, 2021
work page 2021
-
[18]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
work page 2023
-
[19]
Wenlong Li, Yifei Xu, Yuan Rao, Zhenhua Wang, and Shuiguang Deng. Vadtree: Explainable training-free video anomaly detection via hierarchical granularity-aware tree.arXiv preprint arXiv:2510.22693, 2025
-
[20]
Dongheng Lin, Mengxue Qu, Kunyang Han, Jianbo Jiao, Xiaojie Jin, and Yunchao Wei. A unified reasoning framework for holistic zero-shot video anomaly analysis.arXiv preprint arXiv:2511.00962, 2025
-
[21]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 26296–26306, 2024
work page 2024
-
[22]
Few-shot scene-adaptive anomaly detection
Yiwei Lu, Frank Yu, Mahesh Kumar Krishna Reddy, and Yang Wang. Few-shot scene-adaptive anomaly detection. InEuropean conference on computer vision, pages 125–141. Springer, 2020
work page 2020
-
[23]
Junxiao Ma, Jingjing Wang, Jiamin Luo, Peiying Yu, and Guodong Zhou. Sherlock: Towards multi-scene video abnormal event extraction and localization via a global-local spatial-sensitive llm. InProceedings of the ACM on Web Conference 2025, pages 4004–4013, 2025
work page 2025
-
[24]
Just dance with pi! a poly-modal inductor for weakly- supervised video anomaly detection
Snehashis Majhi, Giacomo D’Amicantonio, Antitza Dantcheva, Quan Kong, Lorenzo Garattoni, Gianpiero Francesca, Egor Bondarev, and Francois Bremond. Just dance with pi! a poly-modal inductor for weakly- supervised video anomaly detection. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24265–24274, 2025
work page 2025
-
[25]
Kanti V Mardia and Peter E Jupp.Directional statistics. John Wiley & Sons, 2009
work page 2009
-
[26]
Self-trained deep ordinal regression for end-to-end video anomaly detection
Guansong Pang, Cheng Yan, Chunhua Shen, Anton van den Hengel, and Xiao Bai. Self-trained deep ordinal regression for end-to-end video anomaly detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12173–12182, 2020
work page 2020
-
[27]
Intrinsic statistics on riemannian manifolds: Basic tools for geometric measurements
Xavier Pennec. Intrinsic statistics on riemannian manifolds: Basic tools for geometric measurements. Journal of Mathematical Imaging and Vision, 25(1):127–154, 2006
work page 2006
-
[28]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
work page 2021
-
[29]
Bharathkumar Ramachandra, Michael J Jones, and Ranga Raju Vatsavai. A survey of single-scene video anomaly detection.IEEE transactions on pattern analysis and machine intelligence, 44(5):2293–2312, 2020
work page 2020
-
[30]
Eventvad: Training-free event-aware video anomaly detection
Yihua Shao, Haojin He, Sijie Li, Siyu Chen, Xinwei Long, Fanhu Zeng, Yuxuan Fan, Muyang Zhang, Ziyang Yan, Ao Ma, et al. Eventvad: Training-free event-aware video anomaly detection. InProceedings of the 33rd ACM International Conference on Multimedia, pages 2586–2595, 2025
work page 2025
-
[31]
Animating rotation with quaternion curves
Ken Shoemake. Animating rotation with quaternion curves. InProceedings of the 12th annual conference on Computer graphics and interactive techniques, pages 245–254, 1985
work page 1985
-
[32]
Real-world anomaly detection in surveillance videos
Waqas Sultani, Chen Chen, and Mubarak Shah. Real-world anomaly detection in surveillance videos. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6479–6488, 2018
work page 2018
-
[33]
Qwen3.5: Accelerating productivity with native multimodal agents, February 2026
Qwen Team. Qwen3.5: Accelerating productivity with native multimodal agents, February 2026
work page 2026
-
[34]
Dyannet: A scene dynamicity guided self-trained video anomaly detection network
Kamalakar Vijay Thakare, Yash Raghuwanshi, Debi Prosad Dogra, Heeseung Choi, and Ig-Jae Kim. Dyannet: A scene dynamicity guided self-trained video anomaly detection network. InProceedings of the IEEE/CVF Winter conference on applications of computer vision, pages 5541–5550, 2023
work page 2023
-
[35]
Weakly-supervised video anomaly detection with robust temporal feature magnitude learning
Yu Tian, Guansong Pang, Yuanhong Chen, Rajvinder Singh, Johan W Verjans, and Gustavo Carneiro. Weakly-supervised video anomaly detection with robust temporal feature magnitude learning. InProceed- ings of the IEEE/CVF international conference on computer vision, pages 4975–4986, 2021. 11
work page 2021
-
[36]
Not only look, but also listen: Learning multimodal violence detection under weak supervision
Peng Wu, Jing Liu, Yujia Shi, Yujia Sun, Fangtao Shao, Zhaoyang Wu, and Zhiwei Yang. Not only look, but also listen: Learning multimodal violence detection under weak supervision. InEuropean conference on computer vision, pages 322–339. Springer, 2020
work page 2020
-
[37]
Open- vocabulary video anomaly detection
Peng Wu, Xuerong Zhou, Guansong Pang, Yujia Sun, Jing Liu, Peng Wang, and Yanning Zhang. Open- vocabulary video anomaly detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18297–18307, 2024
work page 2024
-
[38]
Weakly supervised video anomaly detection and localization with spatio-temporal prompts
Peng Wu, Xuerong Zhou, Guansong Pang, Zhiwei Yang, Qingsen Yan, Peng Wang, and Yanning Zhang. Weakly supervised video anomaly detection and localization with spatio-temporal prompts. InProceedings of the 32nd ACM International Conference on Multimedia, pages 9301–9310, 2024
work page 2024
-
[39]
Vadclip: Adapting vision-language models for weakly supervised video anomaly detection
Peng Wu, Xuerong Zhou, Guansong Pang, Lingru Zhou, Qingsen Yan, Peng Wang, and Yanning Zhang. Vadclip: Adapting vision-language models for weakly supervised video anomaly detection. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 6074–6082, 2024
work page 2024
-
[40]
Panda: Towards generalist video anomaly detection via agentic ai engineer,
Zhiwei Yang, Chen Gao, and Mike Zheng Shou. Panda: Towards generalist video anomaly detection via agentic ai engineer.arXiv preprint arXiv:2509.26386, 2025
-
[41]
Text prompt with normality guidance for weakly supervised video anomaly detection
Zhiwei Yang, Jing Liu, and Peng Wu. Text prompt with normality guidance for weakly supervised video anomaly detection. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18899–18908, 2024
work page 2024
-
[42]
Vera: Explainable video anomaly detection via verbalized learning of vision-language models
Muchao Ye, Weiyang Liu, and Pan He. Vera: Explainable video anomaly detection via verbalized learning of vision-language models. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 8679–8688, 2025
work page 2025
-
[43]
Harnessing large language models for training-free video anomaly detection
Luca Zanella, Willi Menapace, Massimiliano Mancini, Yiming Wang, and Elisa Ricci. Harnessing large language models for training-free video anomaly detection. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18527–18536, 2024
work page 2024
-
[44]
Draem-a discriminatively trained reconstruction embedding for surface anomaly detection
Vitjan Zavrtanik, Matej Kristan, and Danijel Sko ˇcaj. Draem-a discriminatively trained reconstruction embedding for surface anomaly detection. InProceedings of the IEEE/CVF international conference on computer vision, pages 8330–8339, 2021
work page 2021
-
[45]
Holmes-vau: Towards long-term video anomaly understanding at any granularity
Huaxin Zhang, Xiaohao Xu, Xiang Wang, Jialong Zuo, Xiaonan Huang, Changxin Gao, Shanjun Zhang, Li Yu, and Nong Sang. Holmes-vau: Towards long-term video anomaly understanding at any granularity. InProceedings of the computer vision and pattern recognition conference, pages 13843–13853, 2025
work page 2025
-
[46]
Dual memory units with uncertainty regulation for weakly supervised video anomaly detection
Hang Zhou, Junqing Yu, and Wei Yang. Dual memory units with uncertainty regulation for weakly supervised video anomaly detection. InProceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 3769–3777, 2023
work page 2023
-
[47]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025. 12 Appendix The appendix is organised as follows. Appendix A provides theoretical proofs. Appendix ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[48]
This provides a consistent starting point in the vicinity of the true Fréchet mean
Initialisation.Compute the Euclidean mean and project onto the sphere: µ(0) = ¯x/∥¯x∥, where ¯x= 1 N P i xi. This provides a consistent starting point in the vicinity of the true Fréchet mean. 13
-
[49]
Update the estimate via the exponential map: µ(t+1) = Expµ(t) ηg (t) ,(11) whereη >0is the step size
Gradient computation and update.At iteration t, compute the Riemannian gradient of the Fréchet objective: g(t) = 1 N NX i=1 Logµ(t)(xi).(10) This is the (negative) Riemannian gradient of F(µ) = P i d2 geo(µ,x i) divided by 2N; it points from µ(t) toward the tangent-space centre of mass. Update the estimate via the exponential map: µ(t+1) = Expµ(t) ηg (t) ...
-
[50]
Convergence check.Terminate when ∥g(t)∥< ϵ or a maximum number of iterations is reached. At convergence, g∗ =0, which is the necessary and sufficient first-order condition for the Fréchet mean. A.1.3 Convergence Guarantee and Step-Size Justification Theorem 1(Convergence of Karcher iteration[ 27]).Let {x1, . . . ,xN } ⊂ S D−1 be contained within an open g...
-
[51]
Define δ=d geo(µS,µ R) (the rotational offset, empirically ≈5 ◦ in our setting). Consider the isometric reflection R of S D−1 that swaps µS ↔µ R. Geometrically, R is the geodesic reflection through the midpoint µmid = Slerp(µS,µ R, 1 2), restricted to the great circle containing 16 µS and µR, and extended to all of S D−1 via the orthogonal reflection in t...
-
[52]
No exact string match:None of the 35 synthetic sub-category names appears verbatim in any benchmark’s category list. For instance, UCF-Crime uses “Vandalism” whereas our taxonomy uses “Graffiti”; UCF-Crime uses “RoadAccidents” (a broad category) whereas we use the finer- grained “Hit and Run,” “Pedestrian Hit,” and “Bicycle Accident.” 20 ' 8PNBO TNJMJOH B...
-
[53]
Deliberate granularity mismatch:The synthetic sub-categories are intentionally defined at a different level of granularity than benchmark categories. This design choice ensures that even semantically proximate concepts (e.g., “Stealing” vs. “Pickpocketing”) describe distinct visual scenarios, preventing implicit information leakage about benchmark-specifi...
-
[54]
Labels discarded before inference:Most importantly, all sub-category labels are usedexclusively during the data generation stage (Stage 1, Section B.1) to instruct the LLM to produce diverse scene descriptions. They are completely stripped from the data before any feature extraction or prototype estimation occurs. The SphereV AD inference pipeline receive...
-
[55]
Final determination: [Y es or No]
-
[56]
Anomaly category match: [Format: Category – Specific sub-label. If No, output: None]
-
[57]
Spatiotemporal action description: [Briefly describe character interactions, action continuity, and object state changes over time]
-
[58]
If category is ‘None’, output: None]
Confidence assessment: [High / Medium / Low. If category is ‘None’, output: None]. The prompt is wrapped as a single-turn chat message with role=user and processed through the model’s chat template viaapply_chat_template (with add_generation_prompt=True and enable_thinking=False). The processor then jointly tokenises the text and encodes the images, yield...
-
[59]
Structured anomaly whitelist.The six meta-categories (Violent Conflict, Crime, Traffic Acci- dent, Personal Emergency, Environmental Hazard, Public Misconduct) are explicitly enumerated in Part 1to prime the model’s internal representations toward anomaly-relevant semantics.These categories are intentionally broad and do not correspond one-to-one to the c...
-
[60]
four consecutive video frames record the temporal evolution of the same scene
Temporal framing.The phrase “four consecutive video frames record the temporal evolution of the same scene” cues the model to interpret the four sub-images as a temporal sequence rather than four independent observations. This encourages the intermediate-layer features to encode temporal dynamics (e.g., action progression, state changes) rather than merel...
-
[61]
Structured output format in Part 2.Although SphereV ADneverdecodes the model’s textual output, the structured output instructions in Part 2 are critical. Through the causal attention mech- anism (Section C.2), the generation prompt tokens attend to both the visual tokens and the task instructions, producing hidden states that integrate anomaly-category re...
-
[62]
Consistent format across synthetic and real inputs.Both synthetic calibration images (split from 2×2 grids) and real test clips (four sampled frames) are processed withidenticalprompt templates and image preprocessing. This format consistency ensures that the intermediate-layer features from both domains occupy the same representational subspace, which is...
-
[63]
Boundary-delimited:Locate <|vision_start|> / <|vision_end|> (or <|img_start|> / <|img_end|>) token pairs. For K=4 sub-images, the code identifies the first K such pairs and marks all tokens between each pair as vision tokens. The position of the last marked token is the visual-last position. 24
-
[64]
Pad-token fallback:If boundary tokens are not found (e.g., in models using a different to- kenisation scheme), the code searches for <|image_pad|>, <|vision_pad|>, or <|img_pad|> tokens and takes the last occurrence. If neither method succeeds (an edge case that did not occur in our experiments), f v falls back to f l (the last-token feature). C.3 Layer S...
-
[65]
All features areℓ 2-normalised ontoS D−1
Extract layer-wise features.For each synthetic sample xj ∈ Dsyn, extract the last-token hidden state at every layerℓ, yielding{f (ℓ) j }L ℓ=1. All features areℓ 2-normalised ontoS D−1
-
[66]
Compute per-layer separability metrics.For each layer ℓ, three metrics are computed between the normal and anomalous feature distributions: • KL Divergence:measures the distributional divergence between the cosine similarity distribu- tions of normal and anomalous features to their respective class centroids. • Log Density Ratio (LDR):quantifies the separ...
-
[67]
Composite saliency score.The three Z-scored metrics are combined into a single DLSP saliency score: DLSP(ℓ) =Z (ℓ) KL +Z (ℓ) LDR −Z (ℓ) Entropy,(23) where the entropy term is subtracted because lower entropy corresponds to better separability. A higher composite score indicates that features at layer ℓ exhibit stronger anomaly discriminability across all ...
-
[68]
Main feature f l ∈R D (last-token hidden state at layer ℓ∗).This is the hidden state of the last sequence token(i.e., the final token of the generation prompt) at the DLSP-selected layer ℓ∗. As argued in Section C.2, under causal attention the last token has the maximal receptive field, attending to the task instruction, all vision tokens, and the output ...
-
[69]
do these two clips depict visually similar scenes?
Visual feature f v ∈R D (visual-last hidden state at layer ℓ∗).This is the hidden state of thelast vision token(the last token within the vision token span of the fourth sub-image) at the same layer ℓ∗. It captures scene appearance—spatial layout, lighting, object arrangement—contextualised by the Part 1 task instruction butwithoutthe output-format reason...
-
[70]
Threshold sparsification.Set ˜Aij = 0 if ˜Aij < τ H, where τH is a scene-similarity threshold. This removes connections between visually dissimilar clips (e.g., different camera angles or scene transitions within the same video)
-
[71]
Top-KH truncation.For each row i, retain only the KH largest entries and zero out the rest. This ensures that each clip attends to a bounded number of neighbours, preventing any single clip from being dominated by a large homogeneous group. Self-connections are excluded ( ˜Aii = 0 ) to prevent a clip from reinforcing its own potentially incorrect initial ...
-
[72]
Calibration from synthetic data only.The Fréchet mean µunified is computed usingonlythe synthetic calibration features { ˜f l syn}, without pooling real test-set features. This eliminates the need to accumulate statistics over the test set before inference begins—the spherical reference frame is fixeda priori
-
[73]
No test-set statistics are required
Prototypes from synthetic data only.The vMF prototypes {µnorm k }, {µabn k } are constructed via spherical K-Means on the centered synthetic features, identical to the offline pipeline. No test-set statistics are required
-
[74]
Direct vMF scoring (no HSA, no SGP).Each incoming clip is independently scored via the vMF likelihood-ratio criterion (Eq. (4)) immediately after feature extraction and spherical centering. The cross-video HSA module (which requires access to other test clips) and the intra-video SGP module (which requires a complete video) are both disabled, as they are ...
work page 1995
-
[75]
A single centering operation can absorb this offset
The domain shift is geometrically compact on the sphere.While Euclidean distances span a wide range (14–22), the geodesic angles cluster within 5◦–8◦, indicating that the four domain distributions occupy nearby but systematically offset spherical caps. A single centering operation can absorb this offset
-
[76]
Synthetic–real misalignment is universal.All three test domains exhibit a non-negligible angular displacement from the synthetic calibration domain. Without centering, vMF prototypes calibrated on synthetic features would be systematically rotated away from the real feature distribution, degrading scoring accuracy—consistent with the +5.78% AUC gain obser...
-
[77]
The unified Fréchet mean provides a symmetric reference.By pooling synthetic and real features before computing the Fréchet mean (Eq. (1)), the centering base point lies near the geodesic midpoint of the domain-specific means (Proposition 2), absorbing the rotational bias symmetrically from both sides rather than privileging either domain. 39 G Hyperparam...
-
[78]
controls the only stochastic component in the pipeline—spherical K-Means initialisation— via sklearn.cluster.KMeans(random_state=42) with ninit = 10. All remaining operations (Fréchet mean, spherical centering, HSA, vMF scoring, SGP, Gaussian smoothing) are closed-form deterministic computations. We additionally set torch.backends.cudnn.deterministic=True...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.