Recognition: no theorem link
Weight Pruning Amplifies Bias: A Multi-Method Study of Compressed LLMs for Edge AI
Pith reviewed 2026-05-12 02:43 UTC · model grok-4.3
The pith
Activation-aware pruning preserves perplexity but produces the largest bias increases in compressed LLMs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
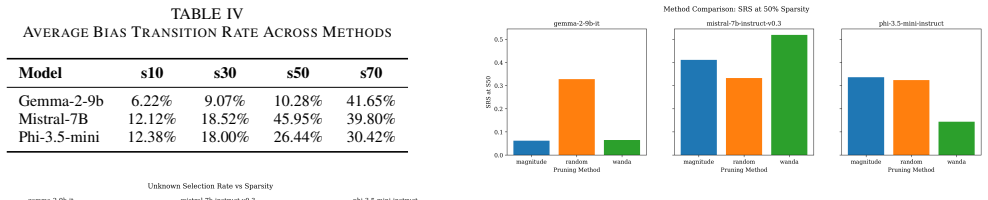
The paper establishes a Smart Pruning Paradox in which activation-aware pruning (Wanda) maintains near-original perplexity (only 3.5 percent increase at 50 percent sparsity) yet produces the highest bias amplification, with Stereotype Reliance Score rising 83.7 percent and 47-59 percent of previously unbiased items developing new stereotypical behaviors at 70 percent sparsity, while random pruning destroys language capability but keeps bias near chance levels.
What carries the argument
The empirical comparison of Random, Magnitude, and Wanda pruning across sparsity levels, tracked via perplexity, Stereotype Reliance Score, and rates of bias-state transitions on the BBQ benchmark.
If this is right
- Perplexity-based evaluation gives false assurance of behavioral equivalence after pruning.
- Pruning produces bias transition rates nearly three times higher than those reported for quantization.
- Unstructured pruning supplies zero storage savings and zero inference latency reduction on actual edge hardware.
- IoT deployment pipelines must incorporate bias-aware validation before releasing pruned models.
Where Pith is reading between the lines
- The findings imply that capability-preserving compression methods may systematically interact with alignment in ways that performance-only checks cannot detect.
- Future experiments could test whether structured pruning methods avoid the same bias amplification while still delivering hardware benefits.
- The high rate of new stereotypical behaviors suggests that pruning may be a stronger disruptor of prior safety training than other compression techniques.
Load-bearing premise
The three tested models and the BBQ benchmark items are representative enough for the observed bias amplification to appear in other models, tasks, and real-world deployments.
What would settle it
A replication on a wider range of models or a different bias benchmark that finds no consistent rise in Stereotype Reliance Score or new stereotypical behaviors after activation-aware pruning would disprove the central claim.
Figures





read the original abstract
Weight pruning is widely advocated for deploying Large Language Models on resource-constrained IoT and edge devices, yet its impact on model fairness remains poorly understood. We conduct a controlled empirical study of three instruction-tuned models (Gemma-2-9b-it, Mistral-7B-Instruct-v0.3, Phi-3.5-mini-instruct) across three pruning methods (Random, Magnitude, Wanda) at four sparsity levels (10-70%) on 12,148 BBQ bias benchmark items with 5 random seeds, totaling 2,368,860 inference records. Our results reveal a Smart Pruning Paradox: activation-aware pruning (Wanda) preserves perplexity nearly perfectly (just 3.5% increase at 50% sparsity for Mistral-7B), yet produces the highest bias amplification, with Stereotype Reliance Score increasing 83.7% and 47-59% of previously unbiased items developing new stereotypical behaviors at 70% sparsity. Random pruning destroys language capability entirely (perplexity exceeding $10^4$ and reaching $10^8$) but produces only random-chance bias. We further show that unstructured pruning provides zero storage savings and zero inference latency reduction on real edge hardware, undermining the primary motivation for its use in IoT deployment. Of 180 dense-vs-pruned comparisons, 141 (78.3%) are significant ($p < 0.05$) with mean $|h| = 0.305$. Published quantization studies report up to 21% of responses flipping between biased and unbiased states; our pruning results show transition rates nearly three times higher (47-59%), suggesting pruning poses a categorically greater risk to alignment than quantization. These findings demonstrate that perplexity-based evaluation provides false assurance of behavioral equivalence, and that IoT deployment pipelines require bias-aware validation before deploying pruned models at the edge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a controlled empirical study examining the effects of weight pruning on bias in large language models intended for edge AI applications. It evaluates three instruction-tuned models—Gemma-2-9b-it, Mistral-7B-Instruct-v0.3, and Phi-3.5-mini-instruct—using three pruning techniques (Random, Magnitude, and Wanda) at sparsity levels from 10% to 70%. The study utilizes the BBQ bias benchmark with 12,148 items, five random seeds, and reports on 2,368,860 inference records. Key findings include the 'Smart Pruning Paradox' where activation-aware pruning (Wanda) maintains near-original perplexity (e.g., 3.5% increase at 50% sparsity for Mistral-7B) but causes the largest bias amplification, including an 83.7% increase in Stereotype Reliance Score and 47-59% of items developing new stereotypical behaviors at 70% sparsity. In contrast, random pruning severely degrades perplexity but results in bias levels consistent with chance. The paper also claims that unstructured pruning yields no practical storage or latency benefits on edge hardware and that bias transition rates are nearly three times higher than those reported in quantization studies.
Significance. If the observed patterns hold, this work has significant implications for the deployment of compressed LLMs in fairness-sensitive applications on resource-limited devices. The large-scale experimental design, involving multiple models, methods, sparsity levels, and seeds, with 78.3% of 180 comparisons reaching statistical significance (mean |h| = 0.305), provides robust evidence that standard perplexity metrics can mask substantial changes in model behavior, particularly regarding bias. The explicit comparison to quantization and the hardware evaluation add practical relevance. This contributes empirical data to the discussion on model compression trade-offs, highlighting the need for bias-aware evaluation in pruning pipelines.
major comments (2)
- [Results (hardware evaluation)] Results section on hardware evaluation: The claim that unstructured pruning provides zero storage savings and zero inference latency reduction on real edge hardware is central to critiquing the motivation for pruning in IoT settings. However, the specific hardware platform, measurement tools (e.g., profiling libraries), and exact comparison metrics to dense baselines are not detailed sufficiently to allow independent verification or assessment of generalizability across edge devices.
- [Discussion] Discussion: The assertion that pruning poses a 'categorically greater risk to alignment than quantization' is supported by the higher transition rates (47-59% vs. up to 21% in published studies), but this relies on cross-study comparison without controlling for model, benchmark, or task differences. A direct head-to-head experiment on the same models and BBQ items would be needed to substantiate the categorical framing.
minor comments (3)
- [Abstract] Abstract: The Stereotype Reliance Score is referenced without a concise definition or pointer to its computation formula, which may hinder quick comprehension for readers unfamiliar with the metric.
- [Experimental setup] Experimental setup: While five random seeds are used, the manuscript should explicitly state how seed variability is aggregated in the reported means and significance tests for all bias metrics.
- [Figures] Figures: Bias transition plots would benefit from including per-seed variability (e.g., error bars) to visually convey the robustness of the 47-59% new stereotypical behavior rates.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and the recommendation for minor revision. We address each major comment point by point below, with planned changes to the manuscript where appropriate.
read point-by-point responses
-
Referee: [Results (hardware evaluation)] Results section on hardware evaluation: The claim that unstructured pruning provides zero storage savings and zero inference latency reduction on real edge hardware is central to critiquing the motivation for pruning in IoT settings. However, the specific hardware platform, measurement tools (e.g., profiling libraries), and exact comparison metrics to dense baselines are not detailed sufficiently to allow independent verification or assessment of generalizability across edge devices.
Authors: We agree that the hardware evaluation section requires greater specificity for reproducibility. In the revised manuscript we will expand this subsection to explicitly state the edge hardware platform used, the measurement tools and libraries employed for profiling storage and latency, and the exact comparison metrics (model size in bytes and end-to-end inference latency in milliseconds) against dense baselines. These additions will substantiate why unstructured pruning yields no practical benefits on the tested devices, which lack native sparse acceleration. revision: yes
-
Referee: [Discussion] Discussion: The assertion that pruning poses a 'categorically greater risk to alignment than quantization' is supported by the higher transition rates (47-59% vs. up to 21% in published studies), but this relies on cross-study comparison without controlling for model, benchmark, or task differences. A direct head-to-head experiment on the same models and BBQ items would be needed to substantiate the categorical framing.
Authors: We acknowledge the inherent limitations of cross-study comparisons. While a controlled head-to-head experiment on identical models and items would be ideal, it lies outside the scope of the present study. We will revise the Discussion to remove the 'categorically greater risk' phrasing, instead reporting that bias transition rates under pruning are substantially higher than those in the cited quantization literature while explicitly noting the uncontrolled differences in models, benchmarks, and tasks. This preserves the empirical observation without overstating the comparative claim. revision: yes
Circularity Check
No significant circularity: pure empirical measurement study
full rationale
This is a controlled empirical study that runs inference on three fixed models with three pruning methods at multiple sparsity levels, computes perplexity and Stereotype Reliance Scores on the BBQ benchmark items, and reports statistical comparisons. No equations, parameters, or derivations are present that could reduce any reported result to a fitted input or self-citation. All claims rest on new experimental data collection (2.3M+ records) and direct measurement rather than any self-referential construction. Self-citations, if any, are not load-bearing for the central observations.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The BBQ benchmark provides a reliable proxy for stereotypical bias in model outputs
- standard math Statistical significance at p<0.05 with the reported effect size is sufficient to establish the observed differences
Reference graph
Works this paper leans on
-
[1]
Large Language Model Deployment on Resource-Constrained Edge Devices: A Practitioner’s Survey,
R. Maliakkal, Y . Makin, P. Rath, R. Jain, and A. Sadhoo, “Large Language Model Deployment on Resource-Constrained Edge Devices: A Practitioner’s Survey,” inProc. IEEE 16th Annu. Computing and Communication Workshop and Conf. (CCWC), 2026
work page 2026
-
[2]
B. Aregawi, X. Zhang,et al., “Sustainable LLM Inference for Edge AI: Evaluating Quantized LLMs for Energy Efficiency, Output Accuracy, and Inference Latency,”ACM Transactions on Internet of Things, 2025
work page 2025
-
[3]
Large Language Models: A Survey
S. Minaee, T. Mikolov,et al., “Large Language Models: A Survey,” arXiv preprint arXiv:2402.06196, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[4]
A Survey of Model Compression Techniques: Past, Present, and Future,
Z. Liaoet al., “A Survey of Model Compression Techniques: Past, Present, and Future,”Frontiers in Robotics and AI, vol. 12, 2025
work page 2025
-
[5]
A Survey on Model Com- pression for Large Language Models,
X. Zhu, J. Li, Y . Liu, C. Ma, and W. Wang, “A Survey on Model Com- pression for Large Language Models,”Transactions of the Association for Computational Linguistics, vol. 12, pp. 1556–1577, 2024
work page 2024
-
[6]
A Simple and Effective Pruning Approach for Large Language Models,
M. Sun, Z. Liu, A. Bair, and J. Z. Kolter, “A Simple and Effective Pruning Approach for Large Language Models,” inProc. ICLR, 2024
work page 2024
-
[7]
SparseGPT: Massive Language Models Can Be Accurately Pruned in One-Shot,
E. Frantar and D. Alistarh, “SparseGPT: Massive Language Models Can Be Accurately Pruned in One-Shot,” inProc. ICML, 2023
work page 2023
-
[8]
What Do Compressed Deep Neural Networks Forget?
S. Hooker, A. Courville, G. Clark, Y . Dauphin, and A. Frome, “What Do Compressed Deep Neural Networks Forget?”arXiv preprint arXiv:1911.05248, 2019
-
[9]
Charac- terising Bias in Compressed Models,
S. Hooker, N. Moorosi, G. Clark, S. Bengio, and E. Denton, “Charac- terising Bias in Compressed Models,”arXiv preprint arXiv:2010.03058, 2020
-
[10]
Beyond Perplexity: Multi-dimensional Safety Evaluation of LLM Compression,
Z. Xu, A. Gupta, T. Li, O. Bentham, and V . Srikumar, “Beyond Perplexity: Multi-dimensional Safety Evaluation of LLM Compression,” inFindings of EMNLP, 2024
work page 2024
-
[11]
Learning Both Weights and Connections for Efficient Neural Networks,
S. Han, J. Pool, J. Tran, and W. Dally, “Learning Both Weights and Connections for Efficient Neural Networks,” inProc. NeurIPS, pp. 1135–1143, 2015
work page 2015
-
[12]
S. Han, H. Mao, and W. J. Dally, “Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding,” inProc. ICLR, 2016
work page 2016
-
[13]
A Fast Post-Training Pruning Framework for Transformers,
W. Kwon, S. Kim, M. W. Mahoney, J. Hassoun, K. Keutzer, and A. Gho- lami, “A Fast Post-Training Pruning Framework for Transformers,” in Proc. NeurIPS, 2022
work page 2022
-
[14]
The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks,
J. Frankle and M. Carlin, “The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks,” inProc. ICLR, 2019
work page 2019
-
[15]
Bias and Fairness in Large Language Models: A Survey,
I. O. Gallegos, R. A. Rossi,et al., “Bias and Fairness in Large Language Models: A Survey,”Computational Linguistics, vol. 50, no. 3, pp. 1097– 1179, 2024
work page 2024
-
[16]
BBQ: A Hand-Built Bias Benchmark for Question Answering,
A. Parrish, A. Chen, N. Nangia,et al., “BBQ: A Hand-Built Bias Benchmark for Question Answering,” inFindings of ACL, pp. 2086– 2105, 2022
work page 2086
-
[17]
Pruning Has a Disparate Impact on Model Accuracy,
C. Tran, F. Fioretto, J.-E. Kim, and R. Naidu, “Pruning Has a Disparate Impact on Model Accuracy,” inProc. NeurIPS, 2022
work page 2022
-
[18]
Bias in Pruned Vision Models: In-Depth Analysis and Countermeasures,
E. Iofinova, A. Peste, and D. Alistarh, “Bias in Pruned Vision Models: In-Depth Analysis and Countermeasures,” inProc. CVPR, pp. 24364– 24373, 2023
work page 2023
-
[19]
The Other Side of Compres- sion: Measuring Bias in Pruned Transformers,
I. Proskurina, G. Metzler, and J. Velcin, “The Other Side of Compres- sion: Measuring Bias in Pruned Transformers,” inProc. IDA, 2023
work page 2023
-
[20]
Decoding Compressed Trust: Scru- tinizing the Trustworthiness of Efficient LLMs Under Compression,
J. Hong, J. Duan, C. Zhang,et al., “Decoding Compressed Trust: Scru- tinizing the Trustworthiness of Efficient LLMs Under Compression,” in Proc. ICML, 2024
work page 2024
-
[21]
Assessing the Brittleness of Safety Alignment via Pruning and Low-Rank Modifications,
B. Wei, K. Huang, Y . Huang,et al., “Assessing the Brittleness of Safety Alignment via Pruning and Low-Rank Modifications,” inProc. ICML, pp. 52588–52610, 2024
work page 2024
-
[22]
A Comparative Study on the Impact of Model Compression Techniques on Fairness in Language Models,
K. Ramesh, A. Chavan, S. Pandit, and S. Sitaram, “A Comparative Study on the Impact of Model Compression Techniques on Fairness in Language Models,” inProc. ACL, pp. 15762–15782, 2023
work page 2023
-
[23]
S. Dutta, A. Pandey, S. Chattopadhyay, T. Sinha, and S. Chakraborty, “Accuracy is Not All You Need,”arXiv preprint arXiv:2407.09141, 2024
-
[24]
Uncertainty Drives Social Bias Changes in Quantized Large Language Models,
S. Z. Hua, S. Lotfi, and I. Y . Chen, “Uncertainty Drives Social Bias Changes in Quantized Large Language Models,”arXiv preprint arXiv:2602.06181, 2026
-
[25]
Efficient Large Language Models: A Survey,
Z. Wan, X. Wang, C. Liu,et al., “Efficient Large Language Models: A Survey,”Transactions on Machine Learning Research, 2024
work page 2024
-
[26]
Wanda++: Pruning Large Language Models via Regional Gradients,
Y . Yang, K. Zhen, B. Ganesh, A. Galstyan,et al., “Wanda++: Pruning Large Language Models via Regional Gradients,” inFindings of ACL, pp. 4321–4333, 2025
work page 2025
-
[27]
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer,
C. Raffel, N. Shazeer, A. Roberts,et al., “Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer,”JMLR, vol. 21, pp. 1–67, 2020
work page 2020
-
[28]
Cohen,Statistical Power Analysis for the Behavioral Sciences, 2nd ed
J. Cohen,Statistical Power Analysis for the Behavioral Sciences, 2nd ed. Lawrence Erlbaum Associates, 1988
work page 1988
-
[29]
MLX: An Array Framework for Apple Silicon,
Apple Inc., “MLX: An Array Framework for Apple Silicon,” GitHub, 2023
work page 2023
-
[30]
DecodingTrust: A Comprehensive Assessment of Trustworthiness in GPT Models,
B. Wang, W. Chen, H. Pei,et al., “DecodingTrust: A Comprehensive Assessment of Trustworthiness in GPT Models,” inProc. NeurIPS, 2023
work page 2023
-
[31]
V . Kharinaevet al., “Investigating the Impact of Quantization Methods on the Safety and Reliability of Large Language Models,”arXiv preprint arXiv:2502.15799, 2025
-
[32]
Less Is More? Examining Fairness in Pruned Large Language Models for Summarizing Opinions,
P. Huanget al., “Less Is More? Examining Fairness in Pruned Large Language Models for Summarizing Opinions,” 2024
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.