Recognition: 2 theorem links
· Lean TheoremLAGO: Language-Guided Adaptive Object-Region Focus for Zero-Shot Visual-Text Alignment
Pith reviewed 2026-05-12 01:33 UTC · model grok-4.3
The pith
LAGO improves zero-shot visual-text alignment by adaptively focusing on object regions with confidence-controlled language guidance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LAGO first performs class-agnostic object-centric candidate discovery to obtain a stable visual initialization, and then applies adaptive language-guided refinement with the strength of semantic guidance controlled by intermediate confidence. It further combines object-level, contextual, and full-image evidence through an effective object-context dual-channel aggregation strategy, achieving state-of-the-art performance on standard zero-shot benchmarks and challenging distribution-shift settings while requiring substantially fewer candidate regions at inference time.
What carries the argument
Class-agnostic object-centric candidate discovery followed by confidence-modulated adaptive language-guided refinement and object-context dual-channel aggregation.
Load-bearing premise
Class-agnostic object-centric candidate discovery yields a stable visual initialization and modulating semantic guidance strength by intermediate confidence effectively mitigates the prediction loop error amplification.
What would settle it
An experiment that disables the confidence-based modulation on fine-grained zero-shot tasks and measures whether accuracy falls due to amplified errors from initial inaccurate predictions, or that compares region counts needed to reach prior methods' accuracy levels.
Figures














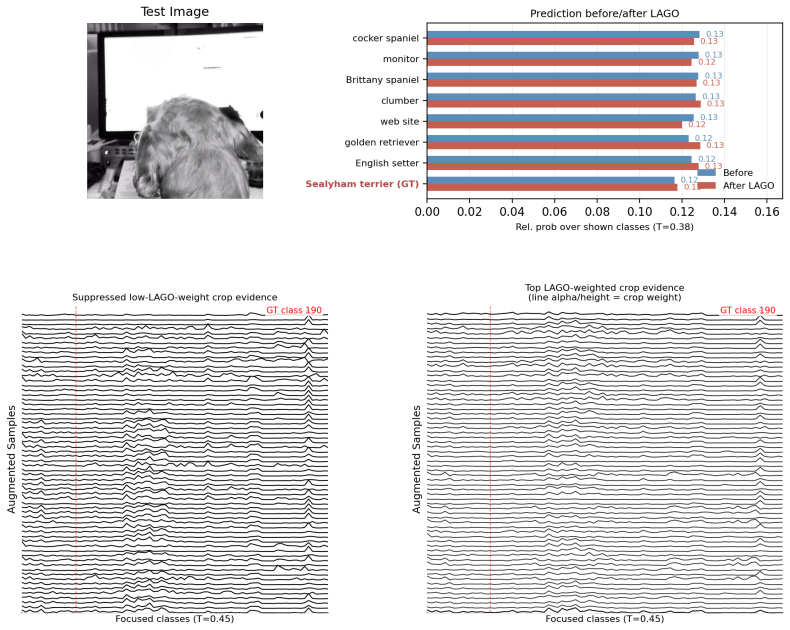









read the original abstract
Zero-shot recognition aims to classify an image by selecting the most compatible label description from a set of candidate classes without any task-specific supervision. In fine-grained settings, however, the relevant evidence often lies in localized parts, attributes, or textures rather than in the full image, making whole-image alignment suboptimal. Recent localized visual-text alignment methods address this by comparing class descriptions with multiple image regions, but they typically rely on large sets of random or redundant crops, increasing inference cost and introducing many highly redundant or weakly relevant candidates. Moreover, introducing semantic guidance too early can create an error-amplifying feedback process in which inaccurate intermediate predictions bias later localization and reinforce subsequent mistakes; we refer to this failure mode as the prediction loop. We propose LAGO (LAnguage-Guided adaptive Object-region focus), a framework for efficient and robust zero-shot localized visual-text alignment. LAGO first performs class-agnostic object-centric candidate discovery to obtain a stable visual initialization, and then applies adaptive language-guided refinement with the strength of semantic guidance controlled by intermediate confidence. It further combines object-level, contextual, and full-image evidence through an effective object-context dual-channel aggregation strategy. Extensive experiments show that LAGO consistently achieves state-of-the-art performance on standard zero-shot benchmarks and challenging distribution-shift settings, while requiring substantially fewer candidate regions at inference time.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LAGO, a framework for zero-shot visual-text alignment. It performs class-agnostic object-centric candidate discovery to obtain stable visual initialization, then applies adaptive language-guided refinement where the strength of semantic guidance is modulated by intermediate confidence to avoid an error-amplifying 'prediction loop.' Object-level, contextual, and full-image evidence are combined via an object-context dual-channel aggregation strategy. The authors claim that LAGO achieves state-of-the-art performance on standard zero-shot benchmarks and distribution-shift settings while using substantially fewer candidate regions at inference time.
Significance. If the empirical results and the effectiveness of the proposed safeguards hold, LAGO would offer a practical advance in efficient localized zero-shot recognition by lowering inference cost and addressing a documented failure mode in iterative alignment. The design choices—object-centric initialization plus confidence-controlled guidance—are well-motivated extensions of prior localized visual-text methods and could influence subsequent work on fine-grained and robust zero-shot tasks.
major comments (2)
- [Abstract and §4] Abstract and §4 (Experiments): the central claim that confidence-modulated guidance reliably prevents prediction-loop error amplification is load-bearing yet unsupported by direct evidence. No measurement of loop failure rates (fraction of cases in which an early low-confidence error propagates) or ablation that isolates the modulation component on distribution-shift data is reported. If the class-agnostic candidates already contain the correct region at high frequency, the modulation may be incidental rather than necessary.
- [§3] §3 (Method): the description of adaptive refinement and dual-channel aggregation is clear, but the paper must quantify the stability of the initial class-agnostic object-centric discovery (e.g., recall of the correct region in the candidate set) across the evaluated datasets and distribution shifts to substantiate that it provides a reliable starting point.
minor comments (2)
- [Figure 1] Figure 1: the schematic of the prediction loop would benefit from an annotated example showing how an early incorrect region selection leads to reinforced error in subsequent steps.
- [Tables 1-2] Table 1 and Table 2: report the exact number of candidate regions used by each baseline so that the efficiency claim can be directly compared.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the potential practical advance offered by LAGO. We address each of the major comments point by point below. We will revise the manuscript to include the requested quantifications and analyses.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experiments): the central claim that confidence-modulated guidance reliably prevents prediction-loop error amplification is load-bearing yet unsupported by direct evidence. No measurement of loop failure rates (fraction of cases in which an early low-confidence error propagates) or ablation that isolates the modulation component on distribution-shift data is reported. If the class-agnostic candidates already contain the correct region at high frequency, the modulation may be incidental rather than necessary.
Authors: We acknowledge that the current manuscript does not include direct measurements of prediction-loop failure rates or an ablation isolating the confidence modulation specifically on distribution-shift data. The empirical results demonstrate consistent state-of-the-art performance, but to directly address the concern that the modulation may be incidental, we will add in the revised version: (1) an analysis of loop failure rates by tracking cases where low-confidence early predictions lead to errors, and (2) an ablation study comparing LAGO with and without the modulation component on the distribution-shift benchmarks. This will provide the requested direct evidence. revision: yes
-
Referee: [§3] §3 (Method): the description of adaptive refinement and dual-channel aggregation is clear, but the paper must quantify the stability of the initial class-agnostic object-centric discovery (e.g., recall of the correct region in the candidate set) across the evaluated datasets and distribution shifts to substantiate that it provides a reliable starting point.
Authors: We agree that quantifying the stability of the class-agnostic object-centric candidate discovery is necessary to support its role as a reliable initialization. Although the method section describes the process, we did not report recall metrics for the correct region in the candidate sets. In the revised manuscript, we will add these quantifications, reporting the recall of the ground-truth region within the discovered candidates for each standard benchmark and distribution-shift setting. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper proposes LAGO as a new framework combining class-agnostic object-centric candidate discovery with adaptive confidence-modulated language guidance and dual-channel aggregation. No equations, fitted parameters renamed as predictions, or self-citation chains are present in the provided text that reduce the claimed performance gains to inputs by construction. The method is described as building on existing techniques with explicit novel adaptations for efficiency and robustness. The skeptic concern addresses empirical validation gaps rather than logical circularity in the derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pre-trained object detectors and vision-language models provide reliable initial features for zero-shot tasks.
invented entities (1)
-
Prediction loop
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning, 2021
work page 2021
-
[2]
Learning to prompt for vision-language models.International Journal of Computer Vision, 2022
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Learning to prompt for vision-language models.International Journal of Computer Vision, 2022
work page 2022
-
[3]
Conditional prompt learning for vision-language models
Kaiyang Zhou, Jingkang Yang, Chen Change Loy, and Ziwei Liu. Conditional prompt learning for vision-language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022
work page 2022
-
[4]
Visual classification via description from large language models
Sachit Menon and Carl V ondrick. Visual classification via description from large language models. In International Conference on Learning Representations, 2022
work page 2022
-
[5]
What does a platypus look like? generating customized prompts for zero-shot image classification
Sarah Pratt, Ian Covert, Rosanne Liu, and Ali Farhadi. What does a platypus look like? generating customized prompts for zero-shot image classification. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15691–15701, 2023
work page 2023
-
[6]
Visual-text cross alignment: Refining the similarity score in vision-language models
Jinhao Li, Haopeng Li, Sarah Erfani, Lei Feng, James Bailey, and Feng Liu. Visual-text cross alignment: Refining the similarity score in vision-language models. InProceedings of the 41st International Conference on Machine Learning, 2024
work page 2024
-
[7]
Sophia Koepke, Oriol Vinyals, Cordelia Schmid, and Zeynep Akata
Karsten Roth, Jae Myung Kim, A. Sophia Koepke, Oriol Vinyals, Cordelia Schmid, and Zeynep Akata. Waffling around for performance: Visual classification with random words and broad concepts. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023
work page 2023
-
[8]
Yuhao Sun, Chengyi Cai, Jiacheng Zhang, Zesheng Ye, Xingliang Yuan, and Feng Liu. Let's roll a bifta: Bi-refinement for fine-grained text-visual alignment in vision-language models.Transactions on Machine Learning Research, 2026
work page 2026
-
[9]
arXiv preprint arXiv:2505.05071 (2025) 5, 7, 9, 11, 12, 13, 20, 21, 22
Chunyu Xie, Bin Wang, Fanjing Kong, Jincheng Li, Dawei Liang, Gengshen Zhang, Dawei Leng, and Yuhui Yin. FG-CLIP: Fine-grained visual and textual alignment.arXiv preprint arXiv:2505.05071, 2025
-
[10]
Lincan Cai, Jingxuan Kang, Shuang Li, Wenxuan Ma, Binhui Xie, Zhida Qin, and Jian Liang. From local details to global context: Advancing vision-language models with attention-based selection. InProceedings of the 42nd International Conference on Machine Learning (ICML 2025), volume 267 ofProceedings of Machine Learning Research, pages 6229–6242. PMLR, 2025
work page 2025
-
[11]
Unified vision and language prompt learning.arXiv preprint arXiv:2210.07225, 2022
Yuhang Zang, Wei Li, Kaiyang Zhou, Chen Huang, and Chen Change Loy. Unified vision and language prompt learning.arXiv preprint arXiv:2210.07225, 2022
-
[12]
Yu Lu, Xiao Liu, Yuxin Zhang, Xiao Liu, and Xinmei Tian. Prompt distribution learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5206–5215, 2022
work page 2022
-
[13]
Prompt-aligned gradient for prompt tuning
Beier Zhu, Yulei Niu, Yucheng Han, Yue Wu, and Hanwang Zhang. Prompt-aligned gradient for prompt tuning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15659– 15669, 2023
work page 2023
-
[14]
Visual-language prompt tuning with knowledge-guided context optimization
Hantao Yao, Rui Zhang, and Changsheng Xu. Visual-language prompt tuning with knowledge-guided context optimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6757–6767, 2023
work page 2023
-
[15]
Maple: Multi-modal prompt learning
Muhammad Uzair Khattak, Hanoona Rasheed, Muhammad Maaz, Salman Khan, and Fahad Shahbaz Khan. Maple: Multi-modal prompt learning.arXiv preprint arXiv:2210.03117, 2023
-
[16]
Self-regulating prompts: Foundational model adaptation without forgetting
Muhammad Uzair Khattak, Hanoona Rasheed, Muhammad Maaz, Salman Khan, and Fahad Shahbaz Khan. Self-regulating prompts: Foundational model adaptation without forgetting. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2023. 10
work page 2023
-
[17]
Tcp: Textual-based class-aware prompt tuning for visual-language model
Hongming Yao, Aixi Zhang, Xiaoshan Xu, Sicong Liu, Saining Xie, and Qingming Lu. Tcp: Textual-based class-aware prompt tuning for visual-language model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
work page 2024
-
[18]
Jooyeon Kim, Eulrang Cho, Sehyung Kim, and Hyunwoo J Kim
Muhammad Uzair Khattak, Muhammad Ferjad Naeem, Muzammal Naseer, Luc Van Gool, and Federico Tombari. Learning to prompt with text only supervision for vision-language models.arXiv preprint arXiv:2401.02418, 2024
-
[19]
Contrastive localized language-image pre-training
Hong-You Chen, Zhengfeng Lai, Haotian Zhang, Xinze Wang, Marcin Eichner, Keen You, Meng Cao, Bowen Zhang, Yinfei Yang, and Zhe Gan. Contrastive localized language-image pre-training. InProceed- ings of the 42nd International Conference on Machine Learning (ICML 2025), volume 267 ofProceedings of Machine Learning Research, pages 8386–8402. PMLR, 2025
work page 2025
-
[20]
Flair: Vlm with fine-grained language-informed image representations
Rui Xiao, Sanghwan Kim, Mariana-Iuliana Georgescu, Zeynep Akata, and Stephan Alaniz. Flair: Vlm with fine-grained language-informed image representations. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2025), pages 24884–24894, 2025
work page 2025
-
[21]
Test-time prompt tuning for zero-shot generalization in vision-language models
Manli Shu, Weili Nie, De-An Huang, Zhiding Yu, Tom Goldstein, Anima Anandkumar, and Chaowei Xiao. Test-time prompt tuning for zero-shot generalization in vision-language models. InAdvances in Neural Information Processing Systems, 2022
work page 2022
-
[22]
Diverse data augmentation with diffusions for effective test-time prompt tuning
Chun-Mei Feng, Kai Yu, Yong Liu, Salman Khan, and Wangmeng Zuo. Diverse data augmentation with diffusions for effective test-time prompt tuning. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2023
work page 2023
-
[23]
Hasegawa-Johnson, Yingzhen Li, and Chang D
Hee Suk Yoon, Eunseop Yoon, Joshua Tian Jin Tee, Mark A. Hasegawa-Johnson, Yingzhen Li, and Chang D. Yoo. C-TPT: Calibrated test-time prompt tuning for vision-language models via text feature dispersion. InThe Twelfth International Conference on Learning Representations, 2024. URL https: //openreview.net/forum?id=jzzEHTBFOT
work page 2024
-
[24]
Align your prompts: Test-time prompting with distribution alignment for zero-shot generalization
Jameel Hassan Abdul Samadh, Hanan Gani, Noor Hazim Hussein, Muhammad Uzair Khattak, Muzammal Naseer, Salman Khan, and Fahad Shahbaz Khan. Align your prompts: Test-time prompting with distribution alignment for zero-shot generalization. InAdvances in Neural Information Processing Systems, 2023
work page 2023
-
[25]
Clipartt: Adaptation of clip to new domains at test time
Gustavo Adolfo Vargas Hakim, David Osowiechi, Mehrdad Noori, Milad Cheraghalikhani, Ali Bahri, Moslem Yazdanpanah, Ismail Ben Ayed, and Christian Desrosiers. Clipartt: Adaptation of clip to new domains at test time. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2025
work page 2025
-
[26]
Max Zanella, Ismail Ben Ayed, and Jose Dolz. On the test-time zero-shot generalization of vision-language models: Do we really need prompt learning? InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
work page 2024
-
[27]
O’Connor, and Kevin McGuinness
Eric Arazo, Diego Ortego, Paul Albert, Noel E. O’Connor, and Kevin McGuinness. Pseudo-labeling and confirmation bias in deep semi-supervised learning. InProceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), pages 1–8. IEEE, 2020
work page 2020
-
[28]
Debi- ased self-training for semi-supervised learning
Baixu Chen, Junguang Jiang, Ximei Wang, Pengfei Wan, Jianmin Wang, and Mingsheng Long. Debi- ased self-training for semi-supervised learning. InAdvances in Neural Information Processing Systems, volume 35, pages 32424–32437, 2022
work page 2022
-
[29]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Qing Jiang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, and Lei Zhang. Grounding dino: Marrying dino with grounded pre-training for open-set object detection.arXiv preprint arXiv:2303.05499, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Towards visual grounding: A survey.arXiv preprint arXiv:2412.20206, 2024
Linhui Xiao, Xiaoshan Yang, Xiangyuan Lan, Yaowei Wang, and Changsheng Xu. Towards visual grounding: A survey.arXiv preprint arXiv:2412.20206, 2024
-
[31]
V*: Guided visual search as a core mechanism in multimodal llms
Penghao Wu and Saining Xie. V*: Guided visual search as a core mechanism in multimodal llms. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
work page 2024
-
[32]
Qiji Zhou, Ruochen Zhou, Zike Hu, Panzhong Lu, Siyang Gao, and Yue Zhang. Image-of-thought prompt- ing for visual reasoning refinement in multimodal large language models.arXiv preprint arXiv:2405.13872, 2024
-
[33]
Xintong Zhang, Zhi Gao, Bofei Zhang, Pengxiang Li, Xiaowen Zhang, Yang Liu, Tao Yuan, Yuwei Wu, Yunde Jia, Song-Chun Zhu, and Qing Li. Chain-of-focus: Adaptive visual search and zooming for multimodal reasoning via rl.arXiv preprint arXiv:2505.15436, 2025. 11
-
[34]
VGR: Visual Grounded Reasoning
Jiacong Wang, Zijiang Kang, Haochen Wang, Haiyong Jiang, Jiawen Li, Bohong Wu, Ya Wang, Jiao Ran, Xiao Liang, Chao Feng, and Jun Xiao. Vgr: Visual grounded reasoning.arXiv preprint arXiv:2506.11991, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Licheng Yu, Zhe Lin, Xiaohui Shen, Jimei Yang, Xin Lu, Mohit Bansal, and Tamara L. Berg. Mattnet: Modular attention network for referring expression comprehension. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018
work page 2018
-
[36]
Transvg: End-to- end visual grounding with transformers
Jiajun Deng, Zhengyuan Yang, Tianlang Chen, Wengang Zhou, and Houqiang Li. Transvg: End-to- end visual grounding with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, 2021
work page 2021
-
[37]
Grounded language- image pre-training
Liunian Harold Li, Pengchuan Zhang, Haotian Zhang, Jianwei Yang, Chunyuan Li, Yiwu Zhong, Lijuan Wang, Lu Yuan, Lei Zhang, Jenq-Neng Hwang, Kai-Wei Chang, and Jianfeng Gao. Grounded language- image pre-training. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022
work page 2022
-
[38]
Zero-shot referring image segmentation with global- local context features
Seonghoon Yu, Paul Hongsuck Seo, and Jeany Son. Zero-shot referring image segmentation with global- local context features. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2023), pages 19456–19465, 2023
work page 2023
-
[39]
Zegclip: Towards adapting clip for zero-shot semantic segmentation
Ziqin Zhou, Yinjie Lei, Bowen Zhang, Lingqiao Liu, and Yifan Liu. Zegclip: Towards adapting clip for zero-shot semantic segmentation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2023), pages 11175–11185, 2023
work page 2023
-
[40]
Xu Zhao, Wenchao Ding, Yongqi An, Yinglong Du, Tao Yu, Min Li, Ming Tang, and Jinqiao Wang. Fast segment anything.arXiv preprint arXiv:2306.12156, 2023
-
[41]
Lawrence Zitnick and Piotr Dollár
C. Lawrence Zitnick and Piotr Dollár. Edge boxes: Locating object proposals from edges. InProceedings of the European Conference on Computer Vision (ECCV), pages 391–405, Cham, September 2014. Springer International Publishing
work page 2014
-
[42]
Imagenet: A large-scale hierarchical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 248–255, 2009
work page 2009
-
[43]
Peter Welinder, Steve Branson, Takeo Mita, Catherine Wah, Florian Schroff, Serge Belongie, and Pietro Perona. Caltech-ucsd birds 200. Technical Report CNS-TR-2010-001, California Institute of Technology, 2010
work page 2010
-
[44]
Parkhi, Andrea Vedaldi, Andrew Zisserman, and C
Omkar M. Parkhi, Andrea Vedaldi, Andrew Zisserman, and C. V . Jawahar. Cats and dogs. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3498–3505, 2012
work page 2012
-
[45]
Describing textures in the wild
Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sami Mohamed, and Andrea Vedaldi. Describing textures in the wild. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 3606–3613, 2014
work page 2014
-
[46]
Food-101 – mining discriminative components with random forests
Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool. Food-101 – mining discriminative components with random forests. InEuropean Conference on Computer Vision, pages 446–461, 2014
work page 2014
-
[47]
Bolei Zhou, Agata Lapedriza, Aditya Khosla, Aude Oliva, and Antonio Torralba. Places: A 10 million image database for scene recognition.IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(6):1452–1464, 2018
work page 2018
-
[48]
Benjamin Recht, Rebecca Roelofs, Ludwig Schmidt, and Vaishaal Shankar. Do imagenet classifiers generalize to imagenet? InProceedings of the 36th International Conference on Machine Learning, pages 5389–5400, 2019
work page 2019
-
[49]
The many faces of robustness: A critical analysis of out-of-distribution generalization
Dan Hendrycks, Steven Basart, Norman Mu, Sanjay Kadavath, Frank Wang, Evan Dorundo, Rahul Desai, Tyler Zhu, Samyak Parajuli, Mike Guo, Dawn Song, Jacob Steinhardt, and Justin Gilmer. The many faces of robustness: A critical analysis of out-of-distribution generalization. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8340...
work page 2021
-
[50]
Haohan Wang, Songwei Ge, Zachary Lipton, and Eric P. Xing. Learning robust global representations by penalizing local predictive power. InAdvances in Neural Information Processing Systems, volume 32, 2019
work page 2019
-
[51]
Dan Hendrycks, Kevin Zhao, Steven Basart, Jacob Steinhardt, and Dawn Song. Natural adversarial examples. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15262–15271, 2021. 12 A Additional Method Details A.1 Offline Text Construction and Text Prototype Formation Following prior description-based zero-shot works [ ...
work page 2021
-
[52]
a set of cached proposal-guided crops,
-
[53]
optional random completion crops if the target number of views has not been reached. If the number of valid crops is smaller than the fixed tensor length, we pad the remaining slots with zero crops and use a validity mask to exclude them from subsequent aggregation. This fixed-shape design significantly simplifies batching and implementation at inference ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.