Recognition: 2 theorem links
· Lean TheoremSliced Inner Product Gromov-Wasserstein Distances
Pith reviewed 2026-05-12 01:09 UTC · model grok-4.3
The pith
The sliced inner-product Gromov-Wasserstein distance enables scalable alignment of high-dimensional heterogeneous datasets with rotational invariance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper resolves the one-dimensional closed-form issue for the inner-product Gromov-Wasserstein problem by proposing a sliced IGW distance. This distance is shown to be rotationally invariant, and its structural and computational properties are analyzed in detail, supported by numerical experiments and applications to real data.
What carries the argument
The sliced inner product Gromov-Wasserstein distance, obtained by averaging one-dimensional GW distances with inner product costs over random projections, which carries the alignment while ensuring invariance.
If this is right
- The approach scales to high-dimensional data by reducing to one-dimensional problems.
- It preserves rotational invariance, making it suitable for data without preferred orientations.
- The distance can be used for heterogeneous clustering and representation comparison.
- Computational efficiency is achieved through closed-form expressions in the sliced setting.
Where Pith is reading between the lines
- Similar slicing might apply to other GW variants if one-dimensional solutions can be derived.
- Applications could extend to more complex machine learning tasks involving distribution matching.
- Testing the method on synthetic data with known rotations would verify the invariance property.
Load-bearing premise
That combining the inner product cost with random slicing maintains the essential geometric matching properties of the original GW problem without major loss of information.
What would settle it
Finding two point clouds where the optimal alignment according to full IGW differs substantially from that found by the sliced version.
Figures






read the original abstract
The Gromov-Wasserstein (GW) problem provides a framework for aligning heterogeneous datasets by matching their intrinsic geometry, but its statistical and computational scaling remains an issue for high-dimensional problems. Slicing techniques offer an appealing route to scalability, but, unlike Wasserstein distances, GW problems do not generally admit closed-form solutions in one-dimension. We resolve this problem for the GW problem with inner product cost (IGW), propose a sliced IGW distance that enjoys a natural rotational invariance property, and comprehensively study its structural and computational properties. Numerical experiments validating our theory are presented, followed by applications to heterogeneous clustering of text data and language model representation comparison.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a sliced inner-product Gromov-Wasserstein (IGW) distance to address the computational and statistical scaling limitations of standard GW distances in high dimensions. It claims to resolve the lack of closed-form solutions for 1D GW problems when using inner-product costs, derives a sliced IGW that is rotationally invariant, provides a comprehensive theoretical study of its structural and computational properties, validates the theory with numerical experiments, and demonstrates applications to heterogeneous text clustering and language model representation comparison.
Significance. If the central claims hold, the work provides a scalable, closed-form-enabled alternative to GW distances that preserves alignment of intrinsic geometries while adding rotational invariance, which is particularly useful for high-dimensional heterogeneous data tasks. The explicit resolution of the 1D closed-form issue for IGW and the reproducible numerical validation of theory are notable strengths.
major comments (3)
- [§3.2, Eq. (7)] §3.2, Eq. (7): The closed-form solution for the 1D IGW distance is derived by reducing to a sorting-based expression, but the subsequent definition of the sliced IGW in Eq. (10) as an average over random projections lacks a quantitative bound on the approximation error to the full high-dimensional IGW; this is load-bearing for the claim that slicing resolves scalability without distorting alignments.
- [Theorem 4.1] Theorem 4.1: The rotational invariance property is established, yet the proof does not address whether the optimal couplings recovered from 1D projections match those of the original IGW for heterogeneous data; the skeptic concern about projection-induced collapse of relational structure is not directly tested via a counterexample or stability analysis.
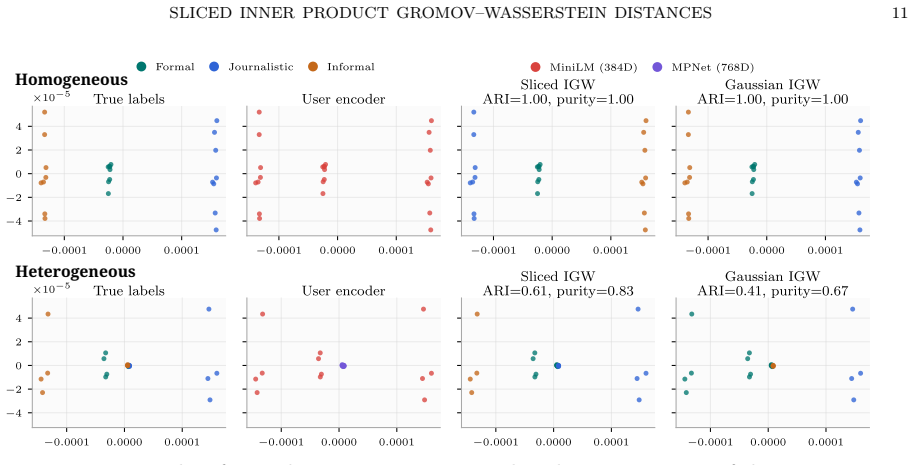
- [§5, Table 2] §5, Table 2: The language model comparison experiments report improved clustering metrics for sliced IGW, but without a direct ablation comparing sliced vs. full IGW on a low-dimensional synthetic dataset where the full distance is computable, it is unclear whether key geometric information is preserved.
minor comments (2)
- [§3.1] The notation for the projection directions in §3.1 is introduced without an explicit statement that they are drawn uniformly from the unit sphere; this should be clarified for reproducibility.
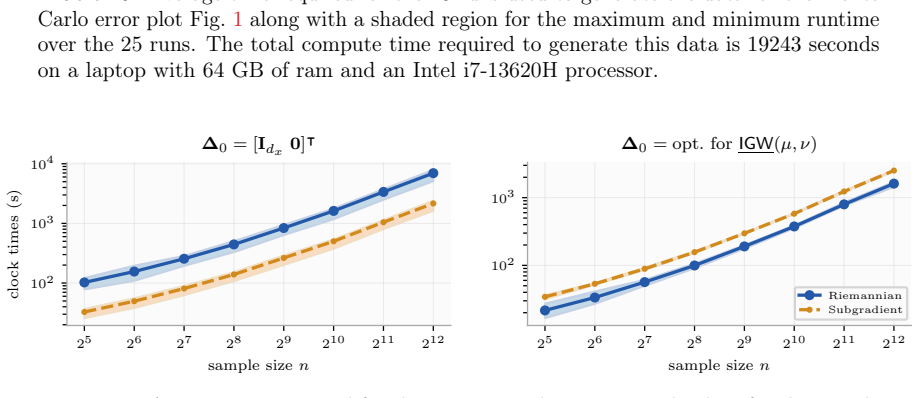
- [Figure 3] Figure 3 caption does not specify the number of random projections used in the sliced distance computation, which affects interpretation of the runtime plots.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive comments on our manuscript. We address each major point below and will revise the paper accordingly to strengthen the presentation and address the concerns.
read point-by-point responses
-
Referee: [§3.2, Eq. (7)] §3.2, Eq. (7): The closed-form solution for the 1D IGW distance is derived by reducing to a sorting-based expression, but the subsequent definition of the sliced IGW in Eq. (10) as an average over random projections lacks a quantitative bound on the approximation error to the full high-dimensional IGW; this is load-bearing for the claim that slicing resolves scalability without distorting alignments.
Authors: We appreciate the referee highlighting this aspect of the presentation. The closed-form expression in Eq. (7) follows directly from reducing the 1D IGW problem to a sorting-based optimal transport problem under the inner-product cost. For the sliced IGW in Eq. (10), the manuscript emphasizes empirical validation and the fact that the 1D closed form enables efficient computation, following the standard rationale for sliced distances. We acknowledge that an explicit quantitative bound on the approximation error to the full IGW would further support the scalability claims. In the revision we will add a dedicated remark in Section 3 discussing convergence as the number of projections increases, along with a high-probability bound derived via concentration of random projections on the inner-product structure. revision: partial
-
Referee: [Theorem 4.1] Theorem 4.1: The rotational invariance property is established, yet the proof does not address whether the optimal couplings recovered from 1D projections match those of the original IGW for heterogeneous data; the skeptic concern about projection-induced collapse of relational structure is not directly tested via a counterexample or stability analysis.
Authors: Thank you for this observation. Theorem 4.1 establishes rotational invariance of the sliced IGW distance itself, which follows because random projections commute with orthogonal transformations and the 1D IGW is invariant under sign flips. The optimal couplings used in the sliced formulation are those of the projected 1D problems; these need not coincide exactly with the couplings of the full high-dimensional IGW. This discrepancy is inherent to any projection-based approximation and does not imply collapse of relational structure, since the inner-product cost is preserved under the projections. The manuscript does not contain a counterexample or stability analysis because the primary focus was on metric properties rather than coupling recovery. We will add a short paragraph after Theorem 4.1 noting this distinction and referencing the empirical preservation of alignment observed in the experiments. revision: partial
-
Referee: [§5, Table 2] §5, Table 2: The language model comparison experiments report improved clustering metrics for sliced IGW, but without a direct ablation comparing sliced vs. full IGW on a low-dimensional synthetic dataset where the full distance is computable, it is unclear whether key geometric information is preserved.
Authors: We agree that this ablation would provide useful additional evidence. While the current experiments focus on high-dimensional heterogeneous data where the full IGW is intractable, we will include a new synthetic experiment in the revised Section 5. Specifically, we will generate low-dimensional (2D and 3D) point clouds with known geometric structure, compute both the full IGW (via standard solvers) and the sliced IGW, and report the difference in recovered alignments and clustering metrics. This will directly demonstrate that the sliced version preserves the essential geometric information. revision: yes
Circularity Check
No circularity: sliced IGW defined from standard 1D closed-form IGW and uniform projections
full rationale
The derivation introduces the sliced IGW by averaging one-dimensional inner-product GW distances over random projections on the sphere. This follows directly from the fact that the inner-product cost admits an explicit 1D solution (already established in the GW literature) and the standard construction of sliced distances; no equation reduces the new distance to a fitted parameter, a self-referential definition, or a load-bearing self-citation. Rotational invariance is a direct geometric consequence of the projection measure, not an imported uniqueness theorem. All structural and computational claims are derived from these definitions and validated by independent numerical experiments.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Inner product cost is a valid and useful choice for the Gromov-Wasserstein problem
- domain assumption Slicing preserves essential geometric alignment properties
invented entities (1)
-
Sliced IGW distance
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
IGW(µ, ν) := (inf_π∈Π(µ,ν) ∬ |⟨x,x′⟩ − ⟨y,y′⟩|² dπ⊗π )^{1/2}
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
closed-form univariate IGW via quantile functions and identity/anti-identity permutations
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
- [1]
-
[2]
Suman Adhya and Debarshi Kumar Sanyal,S2wtm: Spherical sliced-Wasserstein autoencoder for topic modeling, Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2025, pp. 23211–23225
work page 2025
-
[3]
Luigi Ambrosio, Nicola Gigli, and Giuseppe Savaré,Gradient flows: in metric spaces and in the space of probability measures, Springer Science & Business Media, 2008
work page 2008
- [4]
-
[5]
Erhan Bayraktar and Gaoyue Guo,Strong equivalence between metrics of Wasserstein type, Electronic Communi- cations in Probability26(2021), 1 – 13
work page 2021
-
[6]
Robert Beinert, Cosmas Heiss, and Gabriele Steidl,On assignment problems related to Gromov–Wasserstein distances on the real line, SIAM Journal on Imaging Sciences16(2023), no. 2, 1028–1032
work page 2023
-
[7]
March T Boedihardjo,Sharp bounds for max-sliced Wasserstein distances, Foundations of Computational Mathe- matics (2025), 1–32
work page 2025
-
[8]
Vladimir I. Bogachev,Measure theory, vol. 1, Springer, 2007
work page 2007
- [9]
-
[10]
Junyu Chen, Binh T. Nguyen, Shang Hui Koh, and Yong Sheng Soh,Semidefinite relaxations of the Gromov– Wasserstein distance, Advances in Neural Information Processing Systems (A. Globerson, L. Mackey, D. Belgrave, A. Fan, U. Paquet, J. Tomczak, and C. Zhang, eds.), vol. 37, Curran Associates, Inc., 2024, pp. 69814–69839
work page 2024
-
[11]
Pengfei Chen, Rongzhen Zhao, Tianjing He, Kongyuan Wei, and Qidong Yang,Unsupervised domain adaptation of bearing fault diagnosis based on join sliced Wasserstein distance, ISA transactions129(2022), 504–519
work page 2022
-
[12]
Samir Chowdhury and Facundo Mémoli,The Gromov–Wasserstein distance between networks and stable network invariants, Information and Inference: A Journal of the IMA8(2019), no. 4, 757–787
work page 2019
-
[13]
Clarke,Optimization and nonsmooth analysis, Society for Industrial and Applied Mathematics, 1990
Frank H. Clarke,Optimization and nonsmooth analysis, Society for Industrial and Applied Mathematics, 1990
work page 1990
-
[14]
Arman Cohan, Franck Dernoncourt, Doo Soon Kim, Trung Bui, Seokhwan Kim, Walter Chang, and Nazli Goharian, A discourse-aware attention model for abstractive summarization of long documents, Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers) ...
work page 2018
-
[15]
report, Institut de Recherche Mathématiques de Rennes, 2002
Michel Coste,An introduction to semialgebraic geometry, Tech. report, Institut de Recherche Mathématiques de Rennes, 2002. SLICED INNER PRODUCT GROMOV–WASSERSTEIN DISTANCES 27
work page 2002
- [16]
-
[17]
Damek Davis, Dmitriy Drusvyatskiy, Sham Kakade, and Jason D Lee,Stochastic subgradient method converges on tame functions, Foundations of Computational Mathematics20(2020), no. 1, 119–154
work page 2020
-
[18]
Damek Davis, Dmitriy Drusvyatskiy, Yin Tat Lee, Swati Padmanabhan, and Guanghao Ye,A gradient sampling method with complexity guarantees for lipschitz functions in high and low dimensions, Advances in Neural Information Processing Systems35(2022), 6692–6703
work page 2022
-
[19]
JulieDelon, AgnesDesolneux, andAntoineSalmona,Gromov–Wasserstein distances between Gaussian distributions, Journal of Applied Probability59(2022), no. 4, 1178–1198
work page 2022
-
[20]
Ishan Deshpande, Yuan-Ting Hu, Ruoyu Sun, Ayis Pyrros, Nasir Siddiqui, Sanmi Koyejo, Zhizhen Zhao, David A. Forsyth, and Alexander G. Schwing,Max-sliced Wasserstein distance and its use for GANs, Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 10648–10656
work page 2019
-
[21]
Ishan Deshpande, Ziyu Zhang, and Alexander G. Schwing,Generative modeling using the sliced Wasserstein distance, Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 3483–3491
work page 2018
-
[22]
Théo Dumont, Théo Lacombe, and François-Xavier Vialard,On the existence of Monge maps for the Gromov– Wasserstein problem, Foundations of Computational Mathematics (2024), 1–48
work page 2024
-
[23]
Folland,How to integrate a polynomial over a sphere, The American Mathematical Monthly108(2001), no
Gerald B. Folland,How to integrate a polynomial over a sphere, The American Mathematical Monthly108(2001), no. 5, 446–448
work page 2001
-
[24]
Ziv Goldfeld, Kengo Kato, Gabriel Rioux, and Ritwik Sadhu,Statistical inference with regularized optimal transport, Information and Inference: A Journal of the IMA13(2024), no. 1, iaad056
work page 2024
-
[25]
Antonio Gulli,Ag’s corpus of news articles, 2004,http://groups.di.unipi.it/~gulli/AG_corpus_of_news_ articles.html
work page 2004
-
[26]
Rajinder Jeet Hans-Gill, Madhu Raka, and Ranjeet Sehmi,Lecture notes on geometry of numbers, Springer, 2024
work page 2024
-
[27]
Lars Hörmander,The analysis of linear partial differential operators i: Distribution theory and fourier analysis, Springer-Verlag, 1983
work page 1983
-
[28]
Xiaoyin Hu, Nachuan Xiao, Xin Liu, and Kim-Chuan Toh,A constraint dissolving approach for nonsmooth optimization over the Stiefel manifold, IMA Journal of Numerical Analysis44(2024), no. 6, 3717–3748
work page 2024
-
[29]
Wen Huang and Ke Wei,Riemannian proximal gradient methods, Mathematical Programming194(2022), no. 1, 371–413
work page 2022
-
[30]
Lawrence Hubert and Phipps Arabie,Comparing partitions, Journal of classification2(1985), no. 1, 193–218
work page 1985
- [31]
-
[32]
Soheil Kolouri, Kimia Nadjahi, Umut Simsekli, Roland Badeau, and Gustavo Rohde,Generalized sliced Wasserstein distances, Advances in Neural Information Processing Systems (H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, eds.), vol. 32, Curran Associates, Inc., 2019
work page 2019
-
[33]
Soheil Kolouri, Phillip E. Pope, Charles E. Martin, and Gustavo K. Rohde,Sliced Wasserstein auto-encoders, International Conference on Learning Representations (ICLR), 2019
work page 2019
-
[34]
Siyu Kong and Adrian S Lewis,The cost of nonconvexity in deterministic nonsmooth optimization, Mathematics of Operations Research49(2024), no. 4, 2385–2401
work page 2024
- [35]
-
[36]
340, American Mathematical Soc., 2001
Steven George Krantz,Function theory of several complex variables, vol. 340, American Mathematical Soc., 2001
work page 2001
-
[37]
Khang Le, Dung Q Le, Huy Nguyen, Dat Do, Tung Pham, and Nhat Ho,Entropic Gromov-Wasserstein between Gaussian distributions, International Conference on Machine Learning, PMLR, 2022, pp. 12164–12203
work page 2022
-
[38]
Quentin Lhoest, Albert Villanova del Moral, Yacine Jernite, Abhishek Thakur, Patrick von Platen, Suraj Patil, Julien Chaumond, Mariama Drame, Julien Plu, Lewis Tunstall, Joe Davison, Hassan Sajjad, Gunjan Chhablani, Bhavitvya Malik, Simon Brandeis, Teven Le Scao, Victor Sanh, Canwen Xu, Nicolas Patry, Angelina McMillan- Major, Philipp Schmid, Sylvain Gugg...
work page 2021
-
[39]
Jie Li, Dan Xu, and Shaowen Yao,Sliced Wasserstein distance for neural style transfer, Computers & Graphics 102(2022), 89–98
work page 2022
-
[40]
Xiao Li, Shixiang Chen, Zengde Deng, Qing Qu, Zhihui Zhu, and Anthony Man-Cho So,Weakly convex optimization over Stiefel manifold using Riemannian subgradient-type methods, SIAM Journal on Optimization31(2021), no. 3, 1605–1634. 28 X. GONG, G. RIOUX, AND Z. GOLDFELD
work page 2021
-
[41]
Tianyi Lin, Zeyu Zheng, Elynn Chen, Marco Cuturi, and Michael I Jordan,On projection robust optimal transport: Sample complexity and model misspecification, International Conference on Artificial Intelligence and Statistics, PMLR, 2021, pp. 262–270
work page 2021
- [42]
- [43]
- [44]
-
[45]
Andrew L. Maas, Raymond E. Daly, Peter T. Pham, Dan Huang, Andrew Y. Ng, and Christopher Potts,Learning word vectors for sentiment analysis, Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies (Portland, Oregon, USA) (Dekang Lin, Yuji Matsumoto, and Rada Mihalcea, eds.), Association for Comp...
work page 2011
-
[46]
Tudor Manole, Sivaraman Balakrishnan, and Larry Wasserman,Minimax confidence intervals for the sliced Wasserstein distance, Electronic Journal of Statistics16(2022), no. 1, 2252 – 2345
work page 2022
-
[47]
Facundo Mémoli,Gromov–Wasserstein distances and the metric approach to object matching, Foundations of Computational Mathematics11(2011), 417–487
work page 2011
-
[48]
Niklas Muennighoff, Nouamane Tazi, Loïc Magne, and Nils Reimers,MTEB: Massive text embedding benchmark, arXiv preprint arXiv:2210.07316 (2022)
work page internal anchor Pith review arXiv 2022
- [49]
-
[50]
Kimia Nadjahi, Valentin De Bortoli, Alain Durmus, Roland Badeau, and Umut Şimşekli,Approximate Bayesian computation with the sliced-Wasserstein distance, ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2020, pp. 5470–5474
work page 2020
-
[51]
Kimia Nadjahi, Alain Durmus, Lénaïc Chizat, Soheil Kolouri, Shahin Shahrampour, and Umut Simsekli,Statistical and topological properties of sliced probability divergences, Advances in Neural Information Processing Systems33 (2020), 20802–20812
work page 2020
-
[52]
Kimia Nadjahi, Alain Durmus, Pierre E Jacob, Roland Badeau, and Umut Simsekli,Fast approximation of the sliced-Wasserstein distance using concentration of random projections, Advances in Neural Information Processing Systems34(2021), 12411–12424
work page 2021
-
[53]
Kimia Nadjahi, Alain Durmus, Umut Simsekli, and Roland Badeau,Asymptotic guarantees for learning generative models with the sliced-Wasserstein distance, Advances in Neural Information Processing Systems32(2019)
work page 2019
-
[54]
Khai Nguyen and Nhat Ho,Amortized projection optimization for sliced Wasserstein generative models, Advances in Neural Information Processing Systems35(2022), 36985–36998
work page 2022
- [55]
-
[56]
Khai Nguyen, Tongzheng Ren, and Nhat Ho,Markovian sliced Wasserstein distances: Beyond independent projections, Advances in Neural Information Processing Systems36(2023), 39812–39841
work page 2023
-
[57]
Sloan Nietert, Ziv Goldfeld, Ritwik Sadhu, and Kengo Kato,Statistical, robustness, and computational guarantees for sliced Wasserstein distances, Advances in Neural Information Processing Systems35(2022), 28179–28193
work page 2022
-
[58]
Jonathan Niles-Weed and Philippe Rigollet,Estimation of Wasserstein distances in the spiked transport model, Bernoulli28(2022), no. 4, 2663 – 2688
work page 2022
- [59]
-
[60]
Julien Rabin, Gabriel Peyré, Julie Delon, and Marc Bernot,Wasserstein barycenter and its application to texture mixing, Scale Space and Variational Methods in Computer Vision, Lecture Notes in Computer Science, vol. 6667, Springer, 2011, pp. 435–446
work page 2011
- [61]
- [62]
-
[63]
Tyrrell Rockafellar and Roger JB Wets,Variational analysis, Springer, 1998
R. Tyrrell Rockafellar and Roger JB Wets,Variational analysis, Springer, 1998
work page 1998
-
[64]
Filippo Santambrogio,Optimal transport for applied mathematicians, vol. 87, Springer, 2015
work page 2015
-
[65]
Meyer Scetbon, Gabriel Peyré, and Marco Cuturi,Linear-time Gromov Wasserstein distances using low rank couplings and costs, International Conference on Machine Learning, PMLR, 2022, pp. 19347–19365
work page 2022
-
[66]
SLICED INNER PRODUCT GROMOV–WASSERSTEIN DISTANCES 29
Thibault Séjourné, François-Xavier Vialard, and Gabriel Peyré,The unbalanced gromov wasserstein distance: Conic formulation and relaxation, Advances in Neural Information Processing Systems34(2021), 8766–8779. SLICED INNER PRODUCT GROMOV–WASSERSTEIN DISTANCES 29
work page 2021
- [67]
-
[68]
Justin Solomon, Gabriel Peyré, Vladimir G Kim, and Suvrit Sra,Entropic metric alignment for correspondence problems, ACM Transactions on Graphics (ToG)35(2016), no. 4, 1–13
work page 2016
-
[69]
Iulia Turc, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova,Well-read students learn better: On the importance of pre-training compact models, International Conference on Learning Representations, 2020
work page 2020
-
[70]
Titouan Vayer,A contribution to optimal transport on incomparable spaces, 2020, PhD thesis, Institut Polytechnique de Paris
work page 2020
-
[71]
Titouan Vayer, Rémi Flamary, Romain Tavenard, Laetitia Chapel, and Nicolas Courty,Sliced Gromov-Wasserstein, Advances in Neural Information Processing Systems32(2019)
work page 2019
-
[72]
Roman Vershynin,Introduction to the non-asymptotic analysis of random matrices, arXiv preprint arXiv:1011.3027 (2010)
work page Pith review arXiv 2010
-
[73]
,High-dimensional probability: An introduction with applications in data science, 2nd ed., Cambridge University Press, 2026, Available athttps://www.math.uci.edu/~rvershyn/papers/HDP-book/HDP-2.pdf
work page 2026
-
[74]
Cédric Villani,Optimal transport: old and new, vol. 338, Springer, 2008
work page 2008
- [75]
-
[76]
John von Neumann,Some matrix inequalities and metrization of matrix space, Mitt. Forschungsinst. Math. Mech. Kujbyschew-Univ. Tomsk 1, 286-300 (1937)., 1937
work page 1937
-
[77]
Martin J. Wainwright,High-dimensional statistics: A non-asymptotic viewpoint, Cambridge Series in Statistical and Probabilistic Mathematics, Cambridge University Press, 2019
work page 2019
-
[78]
Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Rémi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander M. Rush,Transformers: State-of-the-art ...
work page 2020
-
[79]
Jiaqi Xi and Jonathan Niles-Weed,Distributional convergence of the sliced Wasserstein process, Advances in Neural Information Processing Systems35(2022), 13961–13973
work page 2022
-
[80]
Nachuan Xiao, Xin Liu, and Kim-Chuan Toh,Dissolving constraints for Riemannian optimization, Mathematics of Operations Research49(2024), no. 1, 366–397
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.