Recognition: no theorem link
SkillMaster: Toward Autonomous Skill Mastery in LLM Agents
Pith reviewed 2026-05-13 07:26 UTC · model grok-4.3
The pith
LLM agents can learn to autonomously create, refine, and select their own skills from task trajectories instead of relying on external ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
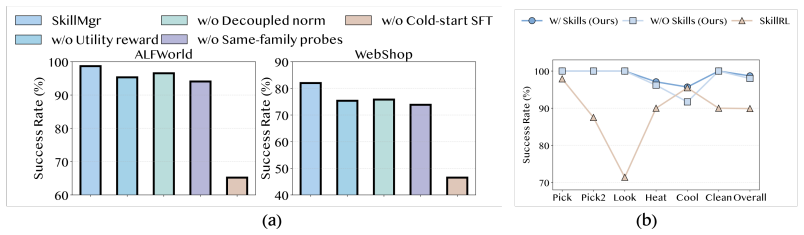
SkillMaster equips LLM agents with three integrated mechanisms: trajectory-informed skill review, in which agents decide whether to add, revise, or retain skills using evidence from finished episodes; counterfactual utility evaluation, which scores each candidate skill edit by its projected benefit on related probe tasks; and DualAdv-GRPO, which computes separate advantage estimates for ordinary task actions and for skill-editing decisions so that both can be optimized in one training loop. When trained this way, agents on ALFWorld and WebShop reach the highest success rates among tested methods and demonstrate the ability to spot skill failures, extract procedural improvements from past run
What carries the argument
DualAdv-GRPO, a reinforcement learning estimator that separately computes advantages for task-solving actions and for skill-editing decisions to allow stable joint optimization of both.
If this is right
- Agents reach 8.8 percent higher success rate on ALFWorld household tasks.
- Agents reach 9.3 percent higher success rate on WebShop shopping tasks.
- Agents learn to detect when a stored skill has failed and to revise it from trajectory evidence.
- Improvements transfer to new tasks using only a small number of skill-bank edits.
- Agents shift from external skill invocation to internal, self-updating skill repertoires.
Where Pith is reading between the lines
- If the skill-editing decisions generalize, the same loop could be applied to other sequential decision domains such as code generation or scientific experiment design.
- Over many episodes the size of the explicit skill bank could shrink as agents internalize common procedures directly into their policy.
- The probe-task evaluation step might be replaced by cheaper synthetic tasks without losing the learning signal, making the method more scalable.
Load-bearing premise
The measured gains come specifically from the autonomous skill creation and editing process rather than from extra training compute, joint optimization alone, or tuning to the two tested environments.
What would settle it
Run an ablation that keeps the joint training procedure but disables the skill-editing decisions; if success rates drop by less than the reported margins, the central claim is falsified.
Figures








read the original abstract
Skills provide an effective mechanism for improving LLM agents on complex tasks, yet in existing agent frameworks, their creation, refinement, and selection are typically governed by external teachers, hand-designed rules, or auxiliary modules. As a result, skills remain external resources to be invoked, rather than capabilities that agents can develop, adapt, and internalize through experience. To endow LLM agents with autonomous skill mastery, we propose SkillMaster, a training framework that teaches agents to create new skills, refine existing skills, and select accumulated skills during task solving. This capability is achieved through three key designs. First, we train agents through trajectory-informed skill review, teaching agents to propose, update, or retain skills based on evidence from completed episodes. Second, each candidate skill edit is designed to be evaluated by its counterfactual utility on related probe tasks, providing a direct learning signal for training skill-editing decisions. Third, we introduce DualAdv-GRPO, which separately estimates advantages for task-solving actions and skill-editing decisions, stabilizing joint training across task solving and skill management. Experiments on ALFWorld and WebShop show that SkillMaster improves the overall success rate over state-of-the-art baselines by 8.8% and 9.3%, respectively, achieving the best performance among all compared methods. Further analysis reveals a marked shift in agent capability: agents trained with SkillMaster can identify skill failures, refine procedural knowledge from trajectory evidence, and transfer improvements to future tasks with limited skill-bank edits. Overall, SkillMaster moves LLM agents beyond mere skill use toward self-improving agents capable of developing, adapting, and applying their own skill repertoires.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SkillMaster, a framework enabling LLM agents to autonomously create, refine, and select skills via trajectory-informed review, counterfactual utility evaluation on probe tasks, and DualAdv-GRPO for joint optimization of task actions and skill edits. It claims this yields 8.8% and 9.3% success-rate gains over SOTA baselines on ALFWorld and WebShop, with evidence of skill failure identification, procedural refinement, and transfer to future tasks via limited skill-bank edits.
Significance. If the performance gains are shown to arise specifically from autonomous skill internalization rather than the joint training procedure, the work would advance self-improving agent paradigms by moving skills from external resources to internalized, experience-driven capabilities.
major comments (2)
- [§4] §4 (Experiments): The ablation studies do not include a control that retains DualAdv-GRPO and joint training but disables candidate skill proposals and counterfactual probes; without this, the 8.8%/9.3% gains cannot be attributed to autonomous skill mastery rather than stabilized multi-objective RL.
- [§4.3] §4.3 (Transfer analysis): The claim that improvements transfer to future tasks with limited skill-bank edits lacks a non-editing joint-training baseline, leaving open whether transfer stems from skill refinement or from the overall training regime.
minor comments (2)
- [Abstract] Abstract: Experimental details (baselines, statistical tests, number of runs, environment specifics) are absent, making the performance claims difficult to assess from the summary alone.
- [§3.2] Notation: The definition of counterfactual utility on probe tasks should be formalized with an equation to clarify how it provides a learning signal independent of the main task reward.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for highlighting the need for tighter controls to attribute performance gains specifically to autonomous skill mastery. We agree that the suggested ablations would strengthen the paper and will incorporate them in the revision. We address each major comment below.
read point-by-point responses
-
Referee: [§4] §4 (Experiments): The ablation studies do not include a control that retains DualAdv-GRPO and joint training but disables candidate skill proposals and counterfactual probes; without this, the 8.8%/9.3% gains cannot be attributed to autonomous skill mastery rather than stabilized multi-objective RL.
Authors: We agree that this specific control ablation is necessary to isolate the contribution of candidate skill proposals and counterfactual utility evaluation from the stabilizing effects of DualAdv-GRPO. Our current ablations separately remove DualAdv-GRPO or the counterfactual probes, but they do not retain the full joint-training procedure while disabling skill-proposal generation. In the revised manuscript we will add this exact control (DualAdv-GRPO + joint training with skill proposals and counterfactual probes disabled) and report the resulting success rates on both ALFWorld and WebShop. This will allow direct quantification of how much of the reported 8.8%/9.3% gains stems from the autonomous skill-editing pathway versus the multi-objective RL stabilization. revision: yes
-
Referee: [§4.3] §4.3 (Transfer analysis): The claim that improvements transfer to future tasks with limited skill-bank edits lacks a non-editing joint-training baseline, leaving open whether transfer stems from skill refinement or from the overall training regime.
Authors: We acknowledge that the current transfer analysis does not include a non-editing joint-training baseline, which leaves the source of transfer ambiguous. To resolve this, we will add a control condition in §4.3 in which agents receive identical DualAdv-GRPO joint training but are prohibited from performing any skill-bank edits or refinements during evaluation on held-out future tasks. Comparing this baseline against the full SkillMaster setting (limited skill-bank edits allowed) will demonstrate whether the observed transfer gains arise specifically from the autonomous skill-refinement mechanism rather than from the training regime alone. revision: yes
Circularity Check
No significant circularity; empirical results are externally measured
full rationale
The paper introduces SkillMaster as a training framework with three explicit designs (trajectory-informed skill review, counterfactual utility evaluation on probe tasks, and DualAdv-GRPO for joint advantage estimation). The reported 8.8% and 9.3% success-rate gains on ALFWorld and WebShop are presented as measured experimental outcomes against external baselines, not as quantities derived from the method's own parameters or equations by construction. No self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations appear in the described chain. The central claims rest on benchmark performance and capability-shift observations that remain falsifiable outside the fitted values.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models.arXiv preprint arXiv:2305.16291,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Evaluating cultural and social awareness of llm web agents
Haoyi Qiu, Alexander Richard Fabbri, Divyansh Agarwal, Kung-Hsiang Huang, Sarah Tan, Nanyun Peng, and Chien-Sheng Wu. Evaluating cultural and social awareness of llm web agents. In Findings of the Association for Computational Linguistics: NAACL 2025, pages 3978–4005,
work page 2025
-
[3]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Bowen Jin, Hansi Zeng, Zhenrui Yue, Jinsung Yoon, Sercan Arik, Dong Wang, Hamed Zamani, and Jiawei Han. Search-r1: Training llms to reason and leverage search engines with reinforcement learning.arXiv preprint arXiv:2503.09516,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Evolvesearch: An iterative self-evolving search agent
Ding-Chu Zhang, Yida Zhao, Jialong Wu, Liwen Zhang, Baixuan Li, Wenbiao Yin, Yong Jiang, Yu-Feng Li, Kewei Tu, Pengjun Xie, et al. Evolvesearch: An iterative self-evolving search agent. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 13134–13147,
work page 2025
-
[5]
Search-o1: Agentic search-enhanced large reasoning models
Xiaoxi Li, Guanting Dong, Jiajie Jin, Yuyao Zhang, Yujia Zhou, Yutao Zhu, Peitian Zhang, and Zhicheng Dou. Search-o1: Agentic search-enhanced large reasoning models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 5420–5438,
work page 2025
-
[6]
Coding agents with multimodal browsing are generalist problem solvers
Aditya Bharat Soni, Boxuan Li, Xingyao Wang, Valerie Chen, and Graham Neubig. Coding agents with multimodal browsing are generalist problem solvers. InFindings of the Association for Computational Linguistics: EACL 2026, pages 6052–6069,
work page 2026
-
[7]
Muhammad Shihab Rashid, Christian Bock, Yuan Zhuang, Alexander Buchholz, Tim Esler, Simon Valentin, Luca Franceschi, Martin Wistuba, Prabhu Teja Sivaprasad, Woo Jung Kim, et al. Swe- polybench: A multi-language benchmark for repository level evaluation of coding agents.arXiv preprint arXiv:2504.08703,
-
[8]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
Peng Xia, Jianwen Chen, Hanyang Wang, Jiaqi Liu, Kaide Zeng, Yu Wang, Siwei Han, Yiyang Zhou, Xujiang Zhao, Haifeng Chen, et al. Skillrl: Evolving agents via recursive skill-augmented reinforcement learning.arXiv preprint arXiv:2602.08234,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory.arXiv preprint arXiv:2504.19413,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
arXiv preprint arXiv:2601.02553 , year=
Jiaqi Liu, Yaofeng Su, Peng Xia, Siwei Han, Zeyu Zheng, Cihang Xie, Mingyu Ding, and Huaxiu Yao. Simplemem: Efficient lifelong memory for llm agents.arXiv preprint arXiv:2601.02553,
-
[11]
11 Junda Wang, Zonghai Tao, Hansi Zeng, Zhichao Yang, Hamed Zamani, and Hong Yu. Tarse: Test-time adaptation via retrieval of skills and experience for reasoning agents.arXiv preprint arXiv:2603.01241,
-
[12]
SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks
Xiangyi Li, Wenbo Chen, Yimin Liu, Shenghan Zheng, Xiaokun Chen, Yifeng He, Yubo Li, Bingran You, Haotian Shen, Jiankai Sun, et al. Skillsbench: Benchmarking how well agent skills work across diverse tasks.arXiv preprint arXiv:2602.12670, 2026a. Yanna Jiang, Delong Li, Haiyu Deng, Baihe Ma, Xu Wang, Qin Wang, and Guangsheng Yu. Sok: Agentic skills–beyond ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Skillreducer: Optimizing llm agent skills for token efficiency.arXiv preprint arXiv:2603.29919,
Yudong Gao, Zongjie Li, Zimo Ji, Pingchuan Ma, Shuai Wang, et al. Skillreducer: Optimizing llm agent skills for token efficiency.arXiv preprint arXiv:2603.29919,
- [14]
-
[15]
Yu Li, Rui Miao, Zhengling Qi, and Tian Lan
Ac- cessed: 2026-05-07. Yu Li, Rui Miao, Zhengling Qi, and Tian Lan. Arise: Agent reasoning with intrinsic skill evolution in hierarchical reinforcement learning.arXiv preprint arXiv:2603.16060, 2026b. Haozhen Zhang, Quanyu Long, Jianzhu Bao, Tao Feng, Weizhi Zhang, Haodong Yue, and Wenya Wang. Memskill: Learning and evolving memory skills for self-evolvi...
-
[16]
Jiongxiao Wang, Qiaojing Yan, Yawei Wang, Yijun Tian, Soumya Smruti Mishra, Zhichao Xu, Megha Gandhi, Panpan Xu, and Lin Lee Cheong. Reinforcement learning for self-improving agent with skill library.arXiv preprint arXiv:2512.17102,
-
[17]
CoEvoSkills: Self-Evolving Agent Skills via Co-Evolutionary Verification
Hanrong Zhang, Shicheng Fan, Henry Peng Zou, Yankai Chen, Zhenting Wang, Jiayu Zhou, Chengze Li, Wei-Chieh Huang, Yifei Yao, Kening Zheng, et al. Coevoskills: Self-evolving agent skills via co-evolutionary verification.arXiv preprint arXiv:2604.01687, 2026b. John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy opt...
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathemat- ical reasoning in open language models.arXiv preprint arXiv:2402.03300,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025b. Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. Group-in-group policy optimization for llm agent training.arXiv preprint ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Yifan Wei, Xiaoyan Yu, Yixuan Weng, Tengfei Pan, Angsheng Li, and Li Du. Autotir: Autonomous tools integrated reasoning via reinforcement learning.arXiv preprint arXiv:2507.21836,
-
[21]
Zhaiyu Fang and Ruipeng Sun. Adatir: Adaptive tool-integrated reasoning via difficulty-aware policy optimization.arXiv preprint arXiv:2601.14696,
-
[22]
Yirong Zeng, Xiao Ding, Yufei Liu, Yuxian Wang, Qunyao Du, Yutai Hou, Wu Ning, Haonan Song, Duyu Tang, Dandan Tu, et al. Autotool: Automatic scaling of tool-use capabilities in rl via decoupled entropy constraints.arXiv preprint arXiv:2603.13348,
-
[23]
Xuqin Zhang, Quan He, Zhenrui Zheng, Zongzhang Zhang, Xu He, and Dong Li. Aster: Agentic scaling with tool-integrated extended reasoning.arXiv preprint arXiv:2602.01204, 2026c. Shengtao Zhang, Jiaqian Wang, Ruiwen Zhou, Junwei Liao, Yuchen Feng, Zhuo Li, Yujie Zheng, Weinan Zhang, Ying Wen, Zhiyu Li, et al. Memrl: Self-evolving agents via runtime reinforc...
-
[24]
EvolveR: Self-Evolving LLM Agents through an Experience-Driven Lifecycle
Rong Wu, Xiaoman Wang, Jianbiao Mei, Pinlong Cai, Daocheng Fu, Cheng Yang, Licheng Wen, Xuemeng Yang, Yufan Shen, Yuxin Wang, et al. Evolver: Self-evolving llm agents through an experience-driven lifecycle.arXiv preprint arXiv:2510.16079, 2025b. Richard S Sutton, Doina Precup, and Satinder Singh. Between mdps and semi-mdps: A framework for temporal abstra...
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
13 A Skill-Review Prompt Templates Figures 5 and 6 show the full skill-review prompt templates used in SKILLMASTERfor ALFWorld and WebShop, respectively. The prompts are constructed by build_skill_management_prompt in skill_management.py. Placeholders ( {task}, {category}, etc.) are filled per-episode with the task description, inferred skill category, re...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.