Recognition: 2 theorem links
· Lean TheoremDiffATS: Diffusion in Aligned Tensor Space
Pith reviewed 2026-05-12 04:34 UTC · model grok-4.3
The pith
Aligning Tucker factor matrices to a medoid anchor via orthogonal Procrustes creates compact, decodable primitive spaces where diffusion models can be trained directly on high-dimensional data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We construct data-dependent tensor primitives without pretrained compression autoencoders by starting from Tucker decomposition and applying orthogonal Procrustes alignment of the factor matrices to medoid anchors. This resolves gauge ambiguity and yields matrix Grassmannian primitives and tensor Grassmannian primitives. We prove that the proposed primitive maps are homeomorphisms between low-rank tensors and their corresponding primitive spaces, certifying that the representations are non-degenerate and topologically faithful. Building on these primitives, DiffATS trains diffusion models directly on the aligned tensor primitives and achieves strong unconditional and conditional generation性能
What carries the argument
Orthogonal Procrustes alignment of Tucker factor matrices to a single medoid anchor, which resolves rotational gauge ambiguity and produces unique, reconstructible Grassmannian primitives for direct diffusion training and multilinear decoding.
If this is right
- Diffusion training and sampling can occur in a space 3.9 to 210 times smaller than the original data while still supporting high-quality unconditional and conditional generation.
- Generated primitives decode back to full tensors through a fixed multilinear product using the core tensor and aligned factors, without any learned decoder network.
- The homeomorphism property ensures that topological features of the low-rank tensor manifold are preserved in the primitive space used by diffusion.
- The same aligned primitive construction applies across images, videos, and solutions to partial differential equations.
Where Pith is reading between the lines
- If the medoid selection remains stable across related datasets, the alignment step could be reused without recomputation when new data arrives.
- Similar alignment procedures might be developed for other tensor formats such as CP decomposition to obtain analogous compact spaces for generative models.
- The Grassmannian structure of the primitives invites direct use of geometry-aware sampling methods that respect the manifold metric during diffusion.
Load-bearing premise
The data must admit a sufficiently low multilinear rank structure that Tucker decomposition captures it well, and aligning every factor set to one medoid anchor must fully remove the rotational ambiguity in a way that keeps diffusion training stable and reconstruction accurate.
What would settle it
A dataset of low-rank tensors where samples generated by DiffATS, after multilinear reconstruction from the diffused primitives, show substantially worse fidelity, mode coverage, or distribution statistics than a standard diffusion model trained on the uncompressed original tensors.
Figures





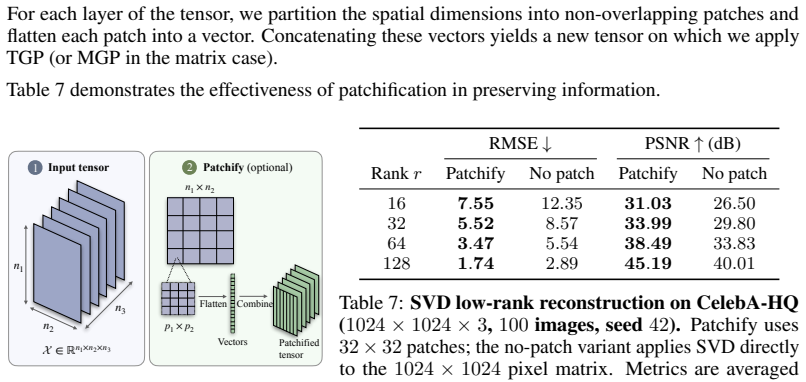





read the original abstract
Direct diffusion modeling of high-resolution spatiotemporal fields is computationally challenging. Parameter-efficient primitives address this by representing high-dimensional data with a compact set of parameters. In this paper, we construct data-dependent tensor primitives without pretrained compression autoencoders. Our construction starts from Tucker decomposition, which captures low-rank multilinear structure through a core tensor and mode-wise factors. However, Tucker factors are non-unique: the same tensor can be represented by different rotated factors, which complicates generative modeling. We address this issue with orthogonal Procrustes (OP) alignment. Specifically, we select medoid anchor matrices from the data and align the factor matrices to resolve the gauge ambiguity. This yields matrix Grassmannian primitives and tensor Grassmannian primitives that are compact, data-adaptive, and directly decodable by explicit multilinear reconstruction. Theoretically, we prove that the proposed primitive maps are homeomorphisms between low-rank tensors and their corresponding primitive spaces, certifying that the representations are non-degenerate and topologically faithful. Building on these primitives, we propose *Diffusion in Aligned Tensor Space* (DiffATS), a generative framework that trains diffusion models directly on aligned tensor primitives. Across images, videos, and PDE solutions, DiffATS achieves strong unconditional and conditional generation performance while compressing original data by $3.9\times$ to $210\times$, without relying on any pretrained deep compression autoencoders.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes DiffATS, a generative framework that constructs compact data-dependent tensor primitives via Tucker decomposition followed by orthogonal Procrustes alignment to medoid anchors, thereby resolving gauge ambiguity in the factors. It claims to prove that the resulting maps to matrix Grassmannian primitives and tensor Grassmannian primitives are homeomorphisms, certifying non-degenerate and topologically faithful representations, and reports strong unconditional and conditional generation performance with compression ratios ranging from 3.9× to 210× on images, videos, and PDE solutions without any pretrained deep autoencoders.
Significance. If the homeomorphism claims are rigorously established and the empirical results hold under the stated assumptions, the work offers a meaningful contribution to parameter-efficient diffusion modeling for high-dimensional spatiotemporal data. The explicit multilinear reconstruction, avoidance of pretrained compression models, and reported compression factors represent concrete strengths that could enable more interpretable and scalable generative approaches in scientific and multimedia domains.
major comments (2)
- [Theoretical section (homeomorphism proof)] Theoretical section on homeomorphism: The central claim that the primitive maps are homeomorphisms (stated in the abstract and developed in the theory portion) requires the full pipeline—Tucker decomposition plus orthogonal Procrustes alignment to a fixed medoid anchor—to be a continuous bijection with continuous inverse. The Procrustes step solves for the orthogonal matrix via SVD of the cross-product of factor matrices; when singular values are equal or nearly equal (common in video or PDE tensors), the solution is non-unique and the map can exhibit discontinuities under infinitesimal perturbations. The manuscript does not address this degeneracy or provide a proof that continuity holds globally, which directly undermines the certification of 'non-degenerate and topologically faithful' representations needed to justify direct diffusion training on the primitives.
- [Theoretical and experimental sections] § on data assumptions and medoid selection: The homeomorphism and stable diffusion training rest on the assumption that the data admits sufficiently low-rank multilinear structure and that alignment to a single dataset medoid fully resolves gauge ambiguity in a topologically faithful manner. No analysis is given of how the choice of medoid (a free parameter) or Tucker core ranks affects continuity or reconstruction quality across the entire space of low-rank tensors, nor is there discussion of whether the construction extends beyond the finite training set. This leaves the global bijectivity claim unsupported.
minor comments (3)
- [Abstract and §1] The abstract and introduction introduce 'matrix Grassmannian primitives' and 'tensor Grassmannian primitives' without a concise definition or diagram; adding a short formal definition early would improve accessibility.
- [Notation and method sections] Notation for the aligned factor matrices versus the original Tucker factors is used inconsistently in places; a single table summarizing all symbols and their relationships would reduce reader confusion.
- [Experiments] Experimental figures showing generated samples would benefit from accompanying quantitative metrics (e.g., FID, PSNR, or reconstruction error) rather than relying solely on visual inspection.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive critique of our theoretical claims. We address each major comment below and will revise the manuscript to strengthen the rigor of the homeomorphism results.
read point-by-point responses
-
Referee: Theoretical section on homeomorphism: The central claim that the primitive maps are homeomorphisms (stated in the abstract and developed in the theory portion) requires the full pipeline—Tucker decomposition plus orthogonal Procrustes alignment to a fixed medoid anchor—to be a continuous bijection with continuous inverse. The Procrustes step solves for the orthogonal matrix via SVD of the cross-product of factor matrices; when singular values are equal or nearly equal (common in video or PDE tensors), the solution is non-unique and the map can exhibit discontinuities under infinitesimal perturbations. The manuscript does not address this degeneracy or provide a proof that continuity holds globally, which directly undermines the certification of 'non-degenerate and topologically faithful' representations needed to justify direct diffusion training on the primitives.
Authors: We acknowledge the potential for non-uniqueness in the SVD-based Procrustes solution when singular values coincide. Our existing proof establishes the homeomorphism under the generic assumption that singular values are distinct (a standard technical condition ensuring uniqueness of the orthogonal factor and continuity of the overall map). This assumption holds on an open dense set and is satisfied for the low-rank structures in our image, video, and PDE datasets. We will revise the theoretical section to explicitly state this genericity condition, include a detailed continuity argument under the assumption, and add a brief discussion of practical handling for near-degenerate cases (e.g., via small random perturbations or selection of the closest valid rotation). These changes preserve the core claims while addressing the referee's concern about global continuity. revision: partial
-
Referee: § on data assumptions and medoid selection: The homeomorphism and stable diffusion training rest on the assumption that the data admits sufficiently low-rank multilinear structure and that alignment to a single dataset medoid fully resolves gauge ambiguity in a topologically faithful manner. No analysis is given of how the choice of medoid (a free parameter) or Tucker core ranks affects continuity or reconstruction quality across the entire space of low-rank tensors, nor is there discussion of whether the construction extends beyond the finite training set. This leaves the global bijectivity claim unsupported.
Authors: The medoid is defined as the training tensor minimizing the sum of distances to all others after initial Tucker decomposition, serving as a fixed, data-driven anchor. We will add a new subsection analyzing sensitivity to medoid choice and core-rank selection, showing that the aligned primitive map remains a homeomorphism on the manifold of fixed multilinear rank tensors for any choice of medoid (the alignment is always to the same fixed reference). For extension beyond the training set, new tensors undergo Tucker decomposition followed by alignment to the precomputed training medoid; this yields a well-defined map on the entire low-rank tensor space. We will include both theoretical justification of bijectivity under the low-rank assumption and empirical checks on held-out samples to confirm reconstruction fidelity and continuity. These additions directly support the global claims. revision: yes
Circularity Check
No circularity; derivation relies on independent multilinear algebra
full rationale
The paper's central chain—Tucker decomposition to obtain factors, followed by explicit orthogonal Procrustes alignment to a fixed medoid anchor, followed by a claimed homeomorphism proof—does not reduce any result to its own inputs by construction. The homeomorphism is asserted as a theorem proven from the maps' definition using standard properties of Tucker decompositions and orthogonal matrices, without fitting parameters to the target diffusion loss or renaming fitted quantities as predictions. No load-bearing self-citation, ansatz smuggling, or uniqueness theorem imported from the authors' prior work appears in the provided derivation; the alignment resolves gauge freedom by a deterministic procedure whose continuity and bijectivity are treated as separately provable rather than tautological.
Axiom & Free-Parameter Ledger
free parameters (2)
- Tucker core ranks
- Medoid anchor selection
axioms (2)
- domain assumption Input data tensors admit useful low-rank multilinear approximations via Tucker decomposition
- ad hoc to paper Orthogonal Procrustes alignment to a medoid anchor produces unique, topologically faithful primitives
invented entities (1)
-
Matrix Grassmannian primitives and tensor Grassmannian primitives
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We address this issue with orthogonal Procrustes (OP) alignment. Specifically, we select medoid anchor matrices from the data and align the factor matrices to resolve the gauge ambiguity.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Abramson, J., Adler, J., Dunger, J., Evans, R., Green, T., Pritzel, A., Ronneberger, O., Willmore, L., Ballard, A. J., Bambrick, J., et al. (2024). Accurate structure prediction of biomolecular interactions with alphafold 3.Nature, 630(8016):493–500
work page 2024
-
[2]
Anderson, B. D. (1982). Reverse-time diffusion equation models.Stochastic Processes and their Applications, 12(3):313–326
work page 1982
-
[3]
Blattmann, A., Rombach, R., Ling, H., Dockhorn, T., Kim, S. W., Fidler, S., and Kreis, K. (2023). Align your latents: High-resolution video synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22563–22575
work page 2023
- [4]
-
[5]
Davis, C. and Kahan, W. M. (1970). The rotation of eigenvectors by a perturbation. iii.SIAM Journal on Numerical Analysis, 7(1):1–46
work page 1970
-
[6]
De Bortoli, V ., Mathieu, E., Hutchinson, M., Thornton, J., Teh, Y . W., and Doucet, A. (2022). Riemannian score-based generative modelling.Advances in neural information processing systems, 35:2406–2422
work page 2022
-
[7]
De Lathauwer, L., De Moor, B., and Vandewalle, J. (2000a). A multilinear singular value decomposition.SIAM journal on Matrix Analysis and Applications, 21(4):1253–1278
-
[8]
De Lathauwer, L., De Moor, B., and Vandewalle, J. (2000b). On the best rank-1 and rank-(r 1, r 2,..., rn) approximation of higher-order tensors.SIAM journal on Matrix Analysis and Applications, 21(4):1324–1342
-
[9]
Eckart, C. and Young, G. (1936). The approximation of one matrix by another of lower rank. Psychometrika, 1(3):211–218
work page 1936
-
[10]
Edelman, A., Arias, T. A., and Smith, S. T. (1998). The geometry of algorithms with orthogo- nality constraints.SIAM journal on Matrix Analysis and Applications, 20(2):303–353
work page 1998
-
[11]
Esser, P., Rombach, R., and Ommer, B. (2021). Taming transformers for high-resolution image synthesis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12873–12883
work page 2021
-
[12]
Gu, S., Chen, D., Bao, J., Wen, F., Zhang, B., Chen, D., Yuan, L., and Guo, B. (2022). Vector quantized diffusion model for text-to-image synthesis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10696–10706
work page 2022
-
[13]
Guo, J., Domel, G., Park, C., Zhang, H., Gumus, O. C., Lu, Y ., Wagner, G. J., Qian, D., Cao, J., Hughes, T. J., et al. (2025a). Tensor-decomposition-based a priori surrogate (taps) modeling for ultra large-scale simulations.Computer Methods in Applied Mechanics and Engineering, 444:118101
- [14]
-
[15]
Guo, J., Xie, X., Park, C., Zhang, H., Politis, M. J., Domel, G., and Liu, W. K. (2025b). Interpolating neural network-tensor decomposition (inn-td): a scalable and interpretable approach for large-scale physics-based problems. InInternational Conference on Machine Learning, pages 21138–21162. PMLR
-
[16]
He, Y ., Yang, T., Zhang, Y ., Shan, Y ., and Chen, Q. (2022). Latent video diffusion models for high-fidelity long video generation.arXiv preprint arXiv:2211.13221
work page internal anchor Pith review arXiv 2022
-
[17]
Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., and Hochreiter, S. (2017). Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30. 10
work page 2017
-
[18]
Ho, J., Jain, A., and Abbeel, P. (2020). Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851
work page 2020
-
[19]
J., Norouzi, M., and Salimans, T
Ho, J., Saharia, C., Chan, W., Fleet, D. J., Norouzi, M., and Salimans, T. (2022a). Cascaded diffusion models for high fidelity image generation.Journal of Machine Learning Research, 23(47):1–33
-
[20]
Ho, J., Salimans, T., Gritsenko, A., Chan, W., Norouzi, M., and Fleet, D. J. (2022b). Video diffusion models.Advances in neural information processing systems, 35:8633–8646
-
[21]
G., Vignac, C., and Welling, M
Hoogeboom, E., Satorras, V . G., Vignac, C., and Welling, M. (2022). Equivariant diffusion for molecule generation in 3d. InInternational conference on machine learning, pages 8867–8887. PMLR
work page 2022
-
[22]
G., Frossard, P., Welling, M., Bronstein, M., and Correia, B
Igashov, I., Stärk, H., Vignac, C., Schneuing, A., Satorras, V . G., Frossard, P., Welling, M., Bronstein, M., and Correia, B. (2024). Equivariant 3d-conditional diffusion model for molecular linker design.Nature Machine Intelligence, 6(4):417–427
work page 2024
-
[23]
Karras, T., Aila, T., Laine, S., and Lehtinen, J. (2017). Progressive growing of gans for improved quality, stability, and variation.arXiv preprint arXiv:1710.10196
work page internal anchor Pith review arXiv 2017
-
[24]
Karras, T., Aittala, M., Aila, T., and Laine, S. (2022). Elucidating the design space of diffusion- based generative models.Advances in neural information processing systems, 35:26565–26577
work page 2022
-
[25]
Kingma, D. P. and Welling, M. (2013). Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[26]
Koehler, F., Niedermayr, S., Westermann, R., and Thuerey, N. (2024). Apebench: A benchmark for autoregressive neural emulators of pdes.Advances in Neural Information Processing Systems, 37:120252–120310
work page 2024
-
[27]
Kolda, T. G. and Bader, B. W. (2009). Tensor decompositions and applications.SIAM review, 51(3):455–500
work page 2009
- [28]
-
[29]
Kruskal, J. B. and Wish, M. (1978).Multidimensional scaling. Number 11. Sage
work page 1978
- [30]
-
[31]
Kynkäänniemi, T., Karras, T., Laine, S., Lehtinen, J., and Aila, T. (2019). Improved precision and recall metric for assessing generative models.Advances in neural information processing systems, 32
work page 2019
-
[32]
Li, Z., Kovachki, N., Azizzadenesheli, K., Liu, B., Bhattacharya, K., Stuart, A., and Anandku- mar, A. (2020). Fourier neural operator for parametric partial differential equations.arXiv preprint arXiv:2010.08895
work page internal anchor Pith review Pith/arXiv arXiv 2020
- [33]
- [34]
-
[35]
Liu, Y ., Zhang, K., Li, Y ., Yan, Z., Gao, C., Chen, R., Yuan, Z., Huang, Y ., Sun, H., Gao, J., et al. (2024). Sora: A review on background, technology, limitations, and opportunities of large vision models.arXiv preprint arXiv:2402.17177
work page internal anchor Pith review arXiv 2024
-
[36]
Ma, J. and Fattahi, S. (2024). Convergence of gradient descent with small initialization for unregularized matrix completion. InThe Thirty Seventh Annual Conference on Learning Theory, pages 3683–3742. PMLR. 11
work page 2024
-
[37]
Ma, X., Wang, Y ., Chen, X., Jia, G., Liu, Z., Li, Y .-F., Chen, C., and Qiao, Y . (2024). Latte: Latent diffusion transformer for video generation.arXiv preprint arXiv:2401.03048
work page internal anchor Pith review arXiv 2024
-
[38]
W., Maggioni, M., and Drineas, P
Mahoney, M. W., Maggioni, M., and Drineas, P. (2006). Tensor-cur decompositions for tensor- based data. InProceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining, pages 327–336
work page 2006
-
[39]
Ning, M., Li, M., Su, J., Jia, H., Liu, L., Beneš, M., Chen, W., Salah, A. A., and Ertugrul, I. O. (2024). Dctdiff: Intriguing properties of image generative modeling in the dct space.arXiv preprint arXiv:2412.15032
-
[40]
Oquab, M., Darcet, T., Moutakanni, T., V o, H., Szafraniec, M., Khalidov, V ., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al. (2023). Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Peebles, W. and Xie, S. (2023). Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205
work page 2023
-
[42]
Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., and Rombach, R. (2023). Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Price, I., Sanchez-Gonzalez, A., Alet, F., Andersson, T. R., El-Kadi, A., Masters, D., Ewalds, T., Stott, J., Mohamed, S., Battaglia, P., et al. (2023). Gencast: Diffusion-based ensemble forecasting for medium-range weather.arXiv preprint arXiv:2312.15796
-
[44]
J., Mohamed, S., and Wierstra, D
Rezende, D. J., Mohamed, S., and Wierstra, D. (2014). Stochastic backpropagation and approximate inference in deep generative models. InInternational conference on machine learning, pages 1278–1286. PMLR
work page 2014
-
[45]
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., and Ommer, B. (2022). High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695
work page 2022
-
[46]
Schaefer, M. and Štefankoviˇc, D. (2018). The complexity of tensor rank.Theory of Computing Systems, 62(5):1161–1174
work page 2018
-
[47]
Schönemann, P. H. (1966). A generalized solution of the orthogonal procrustes problem. Psychometrika, 31(1):1–10
work page 1966
-
[48]
Shu, D., Li, Z., and Farimani, A. B. (2023). A physics-informed diffusion model for high-fidelity flow field reconstruction.Journal of Computational Physics, 478:111972
work page 2023
-
[49]
Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., and Ganguli, S. (2015). Deep unsupervised learning using nonequilibrium thermodynamics. InInternational conference on machine learning, pages 2256–2265. pmlr
work page 2015
-
[50]
Song, J., Meng, C., and Ermon, S. (2020a). Denoising diffusion implicit models. InInternational Conference on Learning Representations
-
[51]
Song, Y . and Ermon, S. (2019). Generative modeling by estimating gradients of the data distribution.Advances in neural information processing systems, 32
work page 2019
-
[52]
Score-Based Generative Modeling through Stochastic Differential Equations
Song, Y ., Sohl-Dickstein, J., Kingma, D. P., Kumar, A., Ermon, S., and Poole, B. (2020b). Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[53]
Srivastava, N., Mansimov, E., and Salakhudinov, R. (2015). Unsupervised learning of video representations using lstms. InInternational conference on machine learning, pages 843–852. PMLR
work page 2015
-
[54]
L., Taylor, E., and Loaiza-Ganem, G
Stein, G., Cresswell, J., Hosseinzadeh, R., Sui, Y ., Ross, B., Villecroze, V ., Liu, Z., Caterini, A. L., Taylor, E., and Loaiza-Ganem, G. (2023). Exposing flaws of generative model evaluation metrics and their unfair treatment of diffusion models.Advances in Neural Information Processing Systems, 36:3732–3784. 12
work page 2023
-
[55]
Szegedy, C., Vanhoucke, V ., Ioffe, S., Shlens, J., and Wojna, Z. (2016). Rethinking the inception architecture for computer vision. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 2818–2826
work page 2016
-
[56]
Takamoto, M., Praditia, T., Leiteritz, R., MacKinlay, D., Alesiani, F., Pflüger, D., and Niepert, M. (2022). Pdebench: An extensive benchmark for scientific machine learning.Advances in neural information processing systems, 35:1596–1611
work page 2022
-
[57]
Tu, S., Boczar, R., Simchowitz, M., Soltanolkotabi, M., and Recht, B. (2016). Low-rank solutions of linear matrix equations via procrustes flow. InInternational conference on machine learning, pages 964–973. PMLR
work page 2016
-
[58]
Tucker, L. R. (1966). Some mathematical notes on three-mode factor analysis.Psychometrika, 31(3):279–311
work page 1966
-
[59]
Unterthiner, T., Van Steenkiste, S., Kurach, K., Marinier, R., Michalski, M., and Gelly, S. (2018). Towards accurate generative models of video: A new metric & challenges.arXiv preprint arXiv:1812.01717
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[60]
Van Den Oord, A., Vinyals, O., et al. (2017). Neural discrete representation learning.Advances in neural information processing systems, 30
work page 2017
- [61]
-
[62]
Xu, Y ., Wang, Y ., Luo, S., Gao, K., He, T., He, D., and Liu, C. (2026). Quotient-space diffusion models. InThe Fourteenth International Conference on Learning Representations
work page 2026
-
[63]
Zeni, C., Pinsler, R., Zügner, D., Fowler, A., Horton, M., Fu, X., Wang, Z., Shysheya, A., Crabbé, J., Ueda, S., et al. (2025). A generative model for inorganic materials design.Nature, 639(8055):624–632
work page 2025
-
[64]
Zhang, A. and Xia, D. (2018). Tensor svd: Statistical and computational limits.IEEE Transac- tions on Information Theory, 64(11):7311–7338
work page 2018
-
[65]
Zhang, X., Du, S., and Gu, Q. (2018). Fast and sample efficient inductive matrix completion via multi-phase procrustes flow. InInternational Conference on Machine Learning, pages 5756–5765. PMLR
work page 2018
-
[66]
Zhou, C., Chen, Z., Li, Z., Wang, J., Jiang, K., Li, P., Yu, R., Zhang, M., Bates, S., and Jaakkola, T. (2026). Rethinking diffusion models with symmetries through canonicalization with applications to molecular graph generation.arXiv preprint arXiv:2602.15022. 13 A Full Related Works Autoencoder-free Diffusion Models.Among autoencoder-free approaches, DC...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.