Recognition: 2 theorem links
· Lean TheoremScratchpad Patching: Decoupling Compute from Patch Size in Byte-Level Language Models
Pith reviewed 2026-05-12 03:59 UTC · model grok-4.3
The pith
Scratchpad patching lets byte-level models use 16-byte patches without quality loss by refreshing context inside each patch.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Scratchpad Patching (SP) inserts transient scratchpads inside each patch, triggered by next-byte prediction entropy, to aggregate bytes seen so far and refresh patch-level context for subsequent predictions. This directly counters patch lag, the source of quality loss when patches grow larger. SP-augmented models at 16 bytes per patch match or closely approach the byte-level baseline on downstream evaluations while using a 16× smaller KV cache over patches and 3-4× less inference compute.
What carries the argument
Scratchpad Patching (SP), the insertion of transient, entropy-triggered scratchpads inside patches to aggregate observed bytes and refresh context for later byte predictions within the same patch.
If this is right
- SP-augmented models reach downstream performance comparable to byte-level baselines even when patches are 16 bytes long.
- KV cache footprint over patches shrinks by a factor of 16 at 16 bytes per patch.
- Inference-time compute drops by a factor of 3-4 relative to the byte-level baseline.
- The entropy threshold can be changed at inference time to trade extra compute for higher quality without retraining.
- Quality at any fixed patch size improves over standard patch-based models.
Where Pith is reading between the lines
- The separation of patch size from compute budget could let practitioners choose patch size for memory layout reasons and control quality via the entropy threshold alone.
- Inputs with long low-entropy regions would see especially large savings, suggesting the method may be particularly effective on structured data such as code or formatted text.
- The same mid-chunk refresh idea might apply to other autoregressive models that chunk sequences, such as those operating on audio frames or image patches.
Load-bearing premise
Patch lag is the dominant cause of quality loss at larger patch sizes, and entropy-triggered scratchpads add no net overhead or new biases that would offset the efficiency gains.
What would settle it
Measure whether disabling the scratchpads while keeping the same total compute budget restores the quality gap of ordinary patch-based models, or whether the added scratchpad steps increase wall-clock time enough to cancel the reported 3-4× inference savings.
Figures







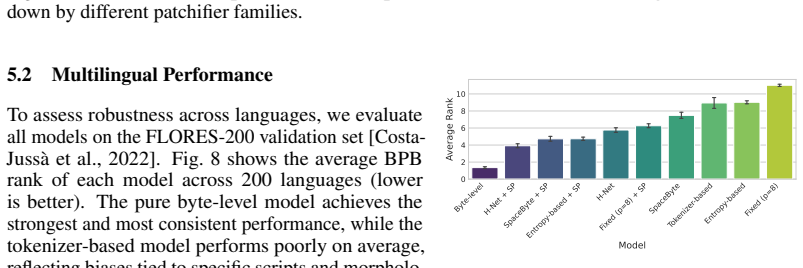







read the original abstract
Tokenizer-free language models eliminate the tokenizer step of the language modeling pipeline by operating directly on bytes; patch-based variants further aggregate contiguous byte spans into patches for efficiency. However, the average patch size chosen at the model design stage governs a tight trade-off: larger patches reduce compute and KV-cache footprint, but degrade modeling quality. We trace this trade-off to patch lag: until a patch is fully observed, byte predictions within it must rely on a stale representation from the previous patch to preserve causality; this lag widens as patches grow larger. We introduce Scratchpad Patching (SP), which inserts transient scratchpads inside each patch to aggregate the bytes seen so far and refresh patch-level context for subsequent predictions. SP triggers scratchpads using next-byte prediction entropy, selectively allocating compute to information-dense regions and enabling post-hoc adjustment of inference-time compute. Across experiments on natural language and code, SP improves model quality at the same patch size; for example, even at $16$ bytes per patch, SP-augmented models match or closely approach the byte-level baseline on downstream evaluations while using a $16\times$ smaller KV cache over patches and $3$-$4\times$ less inference compute.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Scratchpad Patching (SP) mitigates patch lag in byte-level language models by inserting transient, entropy-triggered scratchpads inside patches. This allows 16-byte patches to recover quality close to the byte-level baseline on downstream tasks while delivering a 16× smaller KV cache over patches and 3-4× less inference compute.
Significance. If the net efficiency gains survive full overhead accounting and the quality recovery is robust across ablations, the work would be significant for efficient inference in tokenizer-free models, offering a dynamic, post-hoc way to allocate compute to high-entropy regions without fixing patch size at training time.
major comments (2)
- [Abstract / efficiency analysis] Abstract and efficiency analysis: the reported 3-4× inference-compute and 16× KV-cache reductions are load-bearing for the central claim. The description does not state whether per-byte entropy computation (required to decide scratchpad insertion) and the extra autoregressive positions/KV states from inserted scratchpads are subtracted from the measured savings. If average scratchpad density exceeds a few per patch, especially in high-entropy regions, net FLOPs-per-byte could approach the byte-level baseline; a detailed breakdown (e.g., Table X or §4.3) isolating these costs is required.
- [Experiments] Experiments: the claim that SP models 'match or closely approach' the byte-level baseline at 16 bytes/patch rests on downstream evaluations, yet no specific baselines, statistical tests, or ablation on the entropy-threshold hyper-parameter are referenced. Because the threshold is a free parameter, its sensitivity must be shown to ensure the quality recovery is not an artifact of tuning.
minor comments (1)
- [Abstract] The abstract would be clearer if it named the concrete datasets and model scales used for the natural-language and code experiments.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the efficiency claims and experimental rigor in our work on Scratchpad Patching. The comments highlight important areas for clarification and strengthening. We address each major comment below and will incorporate the requested changes in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract / efficiency analysis] Abstract and efficiency analysis: the reported 3-4× inference-compute and 16× KV-cache reductions are load-bearing for the central claim. The description does not state whether per-byte entropy computation (required to decide scratchpad insertion) and the extra autoregressive positions/KV states from inserted scratchpads are subtracted from the measured savings. If average scratchpad density exceeds a few per patch, especially in high-entropy regions, net FLOPs-per-byte could approach the byte-level baseline; a detailed breakdown (e.g., Table X or §4.3) isolating these costs is required.
Authors: We agree that an explicit accounting of all overheads is essential to support the efficiency claims. The current manuscript reports end-to-end inference measurements but does not isolate the per-byte entropy computation cost or the additional positions introduced by scratchpads. In the revision, we will add a dedicated breakdown in §4.3 (including a new table) that quantifies: (i) the lightweight entropy model overhead (typically <2% of total FLOPs), (ii) average scratchpad insertion density (observed at ~1.1–1.4 per 16-byte patch across datasets), (iii) the resulting net FLOPs-per-byte after subtracting these costs, and (iv) confirmation that the 3–4× compute reduction and 16× KV-cache savings hold after full overhead inclusion. The KV-cache reduction remains unaffected because scratchpads are transient and discarded after use. revision: yes
-
Referee: [Experiments] Experiments: the claim that SP models 'match or closely approach' the byte-level baseline at 16 bytes/patch rests on downstream evaluations, yet no specific baselines, statistical tests, or ablation on the entropy-threshold hyper-parameter are referenced. Because the threshold is a free parameter, its sensitivity must be shown to ensure the quality recovery is not an artifact of tuning.
Authors: We concur that the experimental section would benefit from greater transparency on baselines, statistical validation, and hyper-parameter sensitivity. The original evaluations compare against the byte-level model and fixed-patch baselines, but do not include error bars, significance tests, or threshold ablations. In the revision we will: (1) expand the downstream results table to report means and standard deviations over 3–5 random seeds, (2) add paired statistical significance tests (e.g., t-tests) against the byte-level baseline, and (3) include a new ablation subsection varying the entropy threshold over a range (e.g., 0.8–2.5) with corresponding quality and efficiency metrics. This will demonstrate robustness and that the reported threshold is not a narrow artifact. revision: yes
Circularity Check
No significant circularity; empirical claims rest on new architecture and external evaluations
full rationale
The paper proposes Scratchpad Patching as a novel architectural intervention to mitigate patch lag in byte-level models. Efficiency and quality claims (16x KV-cache reduction, 3-4x compute savings, matching byte-level baselines) are presented as measured outcomes from downstream evaluations on natural language and code tasks. No load-bearing step reduces by construction to fitted parameters, self-referential equations, or self-citation chains; the derivation chain consists of a causal analysis of lag followed by an empirical test of the proposed fix. The method is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- entropy threshold for scratchpad insertion
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We trace this trade-off to patch lag: until a patch is fully observed, byte predictions within it must rely on a stale representation from the previous patch... SP triggers scratchpads using next-byte prediction entropy, selectively allocating compute to information-dense regions
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SP inserts transient scratchpads at selected internal byte positions... each aggregating the bytes seen so far within the patch and refreshing the trunk representation
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Orevaoghene Ahia, Sachin Kumar, Hila Gonen, Valentin Hoffman, Tomasz Limisiewicz, Yulia Tsvetkov, and Noah A Smith. Magnet: Improving the multilingual fairness of language models with adaptive gradient-based tokenization. arXiv preprint arXiv:2407.08818, 2024
-
[2]
Character-level language modeling with deeper self-attention
Rami Al-Rfou, Dokook Choe, Noah Constant, Mandy Guo, and Llion Jones. Character-level language modeling with deeper self-attention. In Proceedings of the AAAI conference on artificial intelligence, 2019
work page 2019
-
[3]
Program Synthesis with Large Language Models
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, et al. Program synthesis with large language models. arXiv preprint arXiv:2108.07732, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Relaxed recursive transformers: Effective parameter sharing with layer-wise lo RA
Sangmin Bae, Adam Fisch, Hrayr Harutyunyan, Ziwei Ji, Seungyeon Kim, and Tal Schuster. Relaxed recursive transformers: Effective parameter sharing with layer-wise lo RA . In The Thirteenth International Conference on Learning Representations, 2025 a . URL https://openreview.net/forum?id=WwpYSOkkCt
work page 2025
-
[5]
Mixture-of-recursions: Learning dynamic recursive depths for adaptive token-level computation
Sangmin Bae, Yujin Kim, Reza Bayat, Sungnyun Kim, Jiyoun Ha, Tal Schuster, Adam Fisch, Hrayr Harutyunyan, Ziwei Ji, Aaron Courville, and Se-Young Yun. Mixture-of-recursions: Learning dynamic recursive depths for adaptive token-level computation. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025 b . URL https://openreview...
work page 2025
-
[6]
Andrea Banino, Jan Balaguer, and Charles Blundell. Pondernet: Learning to ponder. In 8th ICML Workshop on Automated Machine Learning (AutoML), 2021. URL https://openreview.net/forum?id=1EuxRTe0WN
work page 2021
-
[7]
Large concept models: Language modeling in a sentence representation space
Lo \" c Barrault, Paul-Ambroise Duquenne, Maha Elbayad, Artyom Kozhevnikov, Belen Alastruey, Pierre Andrews, Mariano Coria, Guillaume Couairon, Marta R Costa-juss \`a , David Dale, et al. Large concept models: Language modeling in a sentence representation space. arXiv preprint arXiv:2412.08821, 2024
-
[8]
o ppel, Markus Spanring, Andreas Auer, Oleksandra Prudnikova, Michael K Kopp, G \
Maximilian Beck, Korbinian P \"o ppel, Markus Spanring, Andreas Auer, Oleksandra Prudnikova, Michael K Kopp, G \"u nter Klambauer, Johannes Brandstetter, and Sepp Hochreiter. x LSTM : Extended long short-term memory. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=ARAxPPIAhq
work page 2024
-
[9]
Emmanuel Bengio, Pierre-Luc Bacon, Joelle Pineau, and Doina Precup. Conditional computation in neural networks for faster models. arXiv preprint arXiv:1511.06297, 2015
-
[10]
A neural probabilistic language model
Yoshua Bengio, R \'e jean Ducharme, Pascal Vincent, and Christian Jauvin. A neural probabilistic language model. Journal of machine learning research, 2003
work page 2003
-
[11]
Piqa: Reasoning about physical commonsense in natural language
Yonatan Bisk, Rowan Zellers, Ronan Le bras, Jianfeng Gao, and Yejin Choi. Piqa: Reasoning about physical commonsense in natural language. Proceedings of the AAAI Conference on Artificial Intelligence, 2020. URL https://ojs.aaai.org/index.php/AAAI/article/view/6239
work page 2020
-
[12]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gr...
work page 2020
-
[13]
Tianle Cai, Yuhong Li, Zhengyang Geng, Hongwu Peng, Jason D. Lee, Deming Chen, and Tri Dao. Medusa: Simple LLM inference acceleration framework with multiple decoding heads. In Forty-first International Conference on Machine Learning, 2024. URL https://openreview.net/forum?id=PEpbUobfJv
work page 2024
-
[14]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[15]
Bridging the gap for tokenizer-free language models
Dokook Choe, Rami Al-Rfou, Mandy Guo, Heeyoung Lee, and Noah Constant. Bridging the gap for tokenizer-free language models. arXiv preprint arXiv:1908.10322, 2019
-
[16]
Hierarchical multiscale recurrent neural networks
Junyoung Chung, Sungjin Ahn, and Yoshua Bengio. Hierarchical multiscale recurrent neural networks. In International Conference on Learning Representations, 2017. URL https://openreview.net/forum?id=S1di0sfgl
work page 2017
-
[17]
B ool Q : Exploring the surprising difficulty of natural yes/no questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. B ool Q : Exploring the surprising difficulty of natural yes/no questions. In Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Pape...
work page 2019
-
[18]
Clark, Dan Garrette, Iulia Turc, and John Wieting
Jonathan H. Clark, Dan Garrette, Iulia Turc, and John Wieting. Canine: Pre-training an efficient tokenization-free encoder for language representation. Transactions of the Association for Computational Linguistics, 2022. URL https://aclanthology.org/2022.tacl-1.5
work page 2022
-
[19]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[20]
No Language Left Behind: Scaling Human-Centered Machine Translation
Marta R Costa-Juss \`a , James Cross, Onur C elebi, Maha Elbayad, Kenneth Heafield, Kevin Heffernan, Elahe Kalbassi, Janice Lam, Daniel Licht, Jean Maillard, et al. No language left behind: Scaling human-centered machine translation. arXiv preprint arXiv:2207.04672, 2022
work page internal anchor Pith review arXiv 2022
-
[21]
Mo EUT : Mixture-of-experts universal transformers
R \'o bert Csord \'a s, Kazuki Irie, J \"u rgen Schmidhuber, Christopher Potts, and Christopher D Manning. Mo EUT : Mixture-of-experts universal transformers. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=ZxVrkm7Bjl
work page 2024
-
[22]
Getting the most out of your tokenizer for pre-training and domain adaptation
Gautier Dagan, Gabriel Synnaeve, and Baptiste Roziere. Getting the most out of your tokenizer for pre-training and domain adaptation. arXiv preprint arXiv:2402.01035, 2024
-
[23]
Funnel-transformer: Filtering out sequential redundancy for efficient language processing
Zihang Dai, Guokun Lai, Yiming Yang, and Quoc Le. Funnel-transformer: Filtering out sequential redundancy for efficient language processing. Advances in neural information processing systems, 33: 0 4271--4282, 2020
work page 2020
-
[24]
Tri Dao and Albert Gu. Transformers are SSM s: Generalized models and efficient algorithms through structured state space duality. In Proceedings of the 41st International Conference on Machine Learning, 2024. URL https://proceedings.mlr.press/v235/dao24a.html
work page 2024
-
[25]
Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Lukasz Kaiser. Universal transformers. In International Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=HyzdRiR9Y7
work page 2019
-
[26]
BERT : Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. BERT : Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers) , pages 4171--4186, Minneap...
-
[27]
A new algorithm for data compression
Philip Gage. A new algorithm for data compression. C Users Journal, 1994
work page 1994
-
[28]
Improving language understanding from screenshots
Tianyu Gao, Zirui Wang, Adithya Bhaskar, and Danqi Chen. Improving language understanding from screenshots. arXiv preprint arXiv:2402.14073, 2024
-
[29]
Scaling up Test-Time Compute with Latent Reasoning: A Recurrent Depth Approach
Jonas Geiping, Sean McLeish, Neel Jain, John Kirchenbauer, Siddharth Singh, Brian R Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, and Tom Goldstein. Scaling up test-time compute with latent reasoning: A recurrent depth approach. arXiv preprint arXiv:2502.05171, 2025
work page internal anchor Pith review arXiv 2025
-
[30]
Lee, and Dimitris Papailiopoulos
Angeliki Giannou, Shashank Rajput, Jy-Yong Sohn, Kangwook Lee, Jason D. Lee, and Dimitris Papailiopoulos. Looped transformers as programmable computers. In Proceedings of the 40th International Conference on Machine Learning, 2023. URL https://proceedings.mlr.press/v202/giannou23a.html
work page 2023
-
[31]
Fabian Gloeckle, Badr Youbi Idrissi, Baptiste Rozi \`e re, David Lopez-Paz, and Gabriel Synnaeve. Better & faster large language models via multi-token prediction. arXiv preprint arXiv:2404.19737, 2024
-
[32]
MANT a: Efficient gradient-based tokenization for end-to-end robust language modeling
Nathan Godey, Roman Castagn \'e , \'E ric de la Clergerie, and Beno \^ t Sagot. MANT a: Efficient gradient-based tokenization for end-to-end robust language modeling. In Findings of the Association for Computational Linguistics: EMNLP 2022, 2022. URL https://aclanthology.org/2022.findings-emnlp.207
work page 2022
-
[33]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team Google, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, et al. Gemini: a family of highly capable multimodal models. arXiv preprint arXiv:2312.11805, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[34]
Think before you speak: Training language models with pause tokens
Sachin Goyal, Ziwei Ji, Ankit Singh Rawat, Aditya Krishna Menon, Sanjiv Kumar, and Vaishnavh Nagarajan. Think before you speak: Training language models with pause tokens. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=ph04CRkPdC
work page 2024
-
[35]
arXiv preprint arXiv:1308.0850 (2013) 4, 5
Alex Graves. Generating sequences with recurrent neural networks. arXiv preprint arXiv:1308.0850, 2013
-
[36]
Adaptive Computation Time for Recurrent Neural Networks
Alex Graves. Adaptive computation time for recurrent neural networks. arXiv preprint arXiv:1603.08983, 2016
work page internal anchor Pith review arXiv 2016
-
[37]
Fast and expressive multi-token prediction with probabilistic circuits, 2025
Andreas Grivas, Lorenzo Loconte, Emile van Krieken, Piotr Nawrot, Yu Zhao, Euan Wielewski, Pasquale Minervini, Edoardo Ponti, and Antonio Vergari. Fast and expressive multi-token prediction with probabilistic circuits, 2025
work page 2025
-
[38]
Mamba: Linear-time sequence modeling with selective state spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. In First Conference on Language Modeling, 2024. URL https://openreview.net/forum?id=tEYskw1VY2
work page 2024
-
[39]
Olmes: A standard for language model evaluations
Yuling Gu, Oyvind Tafjord, Bailey Kuehl, Dany Haddad, Jesse Dodge, and Hannaneh Hajishirzi. OLMES : A standard for language model evaluations. arXiv preprint arXiv:2406.08446, 2024
-
[40]
DC-DiT: Adaptive Compute and Elastic Inference for Visual Generation via Dynamic Chunking
Akash Haridas, Utkarsh Saxena, Parsa Ashrafi Fashi, Mehdi Rezagholizadeh, Vikram Appia, and Emad Barsoum. Dynamic chunking diffusion transformer. arXiv preprint arXiv:2603.06351, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[41]
General-purpose, long-context autoregressive modeling with perceiver AR
Curtis Hawthorne, Andrew Jaegle, C a t a lina Cangea, Sebastian Borgeaud, Charlie Nash, Mateusz Malinowski, Sander Dieleman, Oriol Vinyals, Matthew Botvinick, Ian Simon, Hannah Sheahan, Neil Zeghidour, Jean-Baptiste Alayrac, Joao Carreira, and Jesse Engel. General-purpose, long-context autoregressive modeling with perceiver AR . In Proceedings of the 39th...
work page 2022
-
[42]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. In International Conference on Learning Representations, 2021. URL https://openreview.net/forum?id=d7KBjmI3GmQ
work page 2021
-
[43]
Block transformer: Global-to-local language modeling for fast inference
Namgyu Ho, Sangmin Bae, Taehyeon Kim, hyunjik.jo, Yireun Kim, Tal Schuster, Adam Fisch, James Thorne, and Se-Young Yun. Block transformer: Global-to-local language modeling for fast inference. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024. URL https://openreview.net/forum?id=6osgTNnAZQ
work page 2024
-
[44]
Deep networks with stochastic depth
Gao Huang, Yu Sun, Zhuang Liu, Daniel Sedra, and Kilian Q Weinberger. Deep networks with stochastic depth. In European conference on computer vision, 2016
work page 2016
-
[45]
Conceptmoe: Adaptive token-to-concept compression for implicit compute allocation
Zihao Huang, Jundong Zhou, Xingwei Qu, Qiyang Min, and Ge Zhang. Conceptmoe: Adaptive token-to-concept compression for implicit compute allocation. arXiv preprint arXiv:2601.21420, 2026
-
[46]
Character-level language modeling with hierarchical recurrent neural networks
Kyuyeon Hwang and Wonyong Sung. Character-level language modeling with hierarchical recurrent neural networks. In 2017 IEEE international conference on acoustics, speech and signal processing (ICASSP), pages 5720--5724. IEEE, 2017
work page 2017
-
[47]
Sukjun Hwang, Brandon Wang, and Albert Gu. Dynamic chunking for end-to-end hierarchical sequence modeling. arXiv preprint arXiv:2507.07955, 2025
-
[48]
Bowen Jing, Bonnie Berger, and Tommi Jaakkola
Andrew Jaegle, Sebastian Borgeaud, Jean-Baptiste Alayrac, Carl Doersch, Catalin Ionescu, David Ding, Skanda Koppula, Daniel Zoran, Andrew Brock, Evan Shelhamer, et al. Perceiver io: A general architecture for structured inputs & outputs. arXiv preprint arXiv:2107.14795, 2021 a
-
[49]
Perceiver: General perception with iterative attention
Andrew Jaegle, Felix Gimeno, Andy Brock, Oriol Vinyals, Andrew Zisserman, and Joao Carreira. Perceiver: General perception with iterative attention. In Proceedings of the 38th International Conference on Machine Learning, 2021 b . URL https://proceedings.mlr.press/v139/jaegle21a.html
work page 2021
-
[50]
`` low-resource '' text classification: A parameter-free classification method with compressors
Zhiying Jiang, Matthew Yang, Mikhail Tsirlin, Raphael Tang, Yiqin Dai, and Jimmy Lin. `` low-resource '' text classification: A parameter-free classification method with compressors. In Findings of the Association for Computational Linguistics: ACL 2023, 2023. URL https://aclanthology.org/2023.findings-acl.426
work page 2023
-
[51]
Mrt5: Dynamic token merging for efficient byte-level language models
Julie Kallini, Shikhar Murty, Christopher D Manning, Christopher Potts, and R \'o bert Csord \'a s. Mrt5: Dynamic token merging for efficient byte-level language models. arXiv preprint arXiv:2410.20771, 2024
-
[52]
Subword regularization: Improving neural network translation models with multiple subword candidates
Taku Kudo. Subword regularization: Improving neural network translation models with multiple subword candidates. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2018. URL https://aclanthology.org/P18-1007/
work page 2018
-
[53]
Taku Kudo and John Richardson. S entence P iece: A simple and language independent subword tokenizer and detokenizer for neural text processing. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, 2018. URL https://aclanthology.org/D18-2012/
work page 2018
-
[54]
Mamba-3: Improved sequence modeling using state space principles
Aakash Lahoti, Kevin Li, Berlin Chen, Caitlin Wang, Aviv Bick, J Zico Kolter, Tri Dao, and Albert Gu. Mamba-3: Improved sequence modeling using state space principles. In The Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=HwCvaJOiCj
work page 2026
-
[55]
Sander Land and Max Bartolo. Fishing for magikarp: Automatically detecting under-trained tokens in large language models. arXiv preprint arXiv:2405.05417, 2024
-
[56]
Training llms over neurally compressed text
Brian Lester, Jaehoon Lee, Alex Alemi, Jeffrey Pennington, Adam Roberts, Jascha Sohl-Dickstein, and Noah Constant. Training llms over neurally compressed text. arXiv preprint arXiv:2404.03626, 2024
-
[57]
Datacomp- LM : In search of the next generation of training sets for language models
Jeffrey Li, Alex Fang, Georgios Smyrnis, Maor Ivgi, Matt Jordan, Samir Gadre, Hritik Bansal, Etash Guha, Sedrick Keh, Kushal Arora, et al. Datacomp-lm: In search of the next generation of training sets for language models. arXiv preprint arXiv:2406.11794, 2024
-
[58]
Myte: Morphology-driven byte encoding for better and fairer multilingual language modeling
Tomasz Limisiewicz, Terra Blevins, Hila Gonen, Orevaoghene Ahia, and Luke Zettlemoyer. Myte: Morphology-driven byte encoding for better and fairer multilingual language modeling. arXiv preprint arXiv:2403.10691, 2024
-
[59]
Alisa Liu, Jonathan Hayase, Valentin Hofmann, Sewoong Oh, Noah A. Smith, and Yejin Choi. Super BPE : Space travel for language models. In Second Conference on Language Modeling, 2025. URL https://openreview.net/forum?id=lcDRvffeNP
work page 2025
-
[60]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In International Conference on Learning Representations, 2019
work page 2019
-
[61]
Text rendering strategies for pixel language models
Jonas Lotz, Elizabeth Salesky, Phillip Rust, and Desmond Elliott. Text rendering strategies for pixel language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, 2023. URL https://aclanthology.org/2023.emnlp-main.628
work page 2023
-
[62]
Starcoder 2 and the stack v2: The next generation, 2024
Anton Lozhkov, Raymond Li, Loubna Ben Allal, Federico Cassano, Joel Lamy-Poirier, Nouamane Tazi, Ao Tang, Dmytro Pykhtar, Jiawei Liu, Yuxiang Wei, Tianyang Liu, Max Tian, Denis Kocetkov, Arthur Zucker, Younes Belkada, Zijian Wang, Qian Liu, Dmitry Abulkhanov, Indraneil Paul, Zhuang Li, Wen-Ding Li, Megan Risdal, Jia Li, Jian Zhu, Terry Yue Zhuo, Evgenii Z...
work page 2024
-
[63]
The art of prompt design: Prompt boundaries and token healing
Scott Lundberg and Marco Tulio Ribeiro. The art of prompt design: Prompt boundaries and token healing. Medium, 2023. URL https://towardsdatascience.com/the-art-of-prompt-design-prompt-boundaries-and-token-healing-3b2448b0be38
work page 2023
- [64]
-
[65]
Can a suit of armor conduct electricity? a new dataset for open book question answering
Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 2018. URL https://aclanthology.org/D18-1260
work page 2018
-
[66]
Bolmo: Byteifying the next generation of language models
Benjamin Minixhofer, Tyler Murray, Tomasz Limisiewicz, Anna Korhonen, Luke Zettlemoyer, Noah A Smith, Edoardo M Ponti, Luca Soldaini, and Valentin Hofmann. Bolmo: Byteifying the next generation of language models. arXiv preprint arXiv:2512.15586, 2025
-
[67]
Hierarchical transformers are more efficient language models
Piotr Nawrot, Szymon Tworkowski, Micha Tyrolski, Lukasz Kaiser, Yuhuai Wu, Christian Szegedy, and Henryk Michalewski. Hierarchical transformers are more efficient language models. In Findings of the Association for Computational Linguistics: NAACL 2022, 2022. URL https://aclanthology.org/2022.findings-naacl.117
work page 2022
-
[68]
Efficient transformers with dynamic token pooling
Piotr Nawrot, Jan Chorowski, Adrian Lancucki, and Edoardo Maria Ponti. Efficient transformers with dynamic token pooling. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2023. URL https://aclanthology.org/2023.acl-long.353
work page 2023
-
[69]
Pit Neitemeier, Bj \"o rn Deiseroth, Constantin Eichenberg, and Lukas Balles. Hierarchical autoregressive transformers: Combining byte-\ and word-level processing for robust, adaptable language models. arXiv preprint arXiv:2501.10322, 2025
-
[70]
OpenAI. GPT -4 technical report. arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[71]
Flexitokens: Flexible tokenization for evolving language models
Abraham Toluwase Owodunni, Orevaoghene Ahia, and Sachin Kumar. Flexitokens: Flexible tokenization for evolving language models. arXiv preprint arXiv:2507.12720, 2025
work page internal anchor Pith review arXiv 2025
-
[72]
Artidoro Pagnoni, Ram Pasunuru, Pedro Rodriguez, John Nguyen, Benjamin Muller, Margaret Li, Chunting Zhou, Lili Yu, Jason Weston, Luke Zettlemoyer, et al. Byte latent transformer: Patches scale better than tokens. arXiv preprint arXiv:2412.09871, 2024
-
[73]
Openwebmath: An open dataset of high-quality mathematical web text
Keiran Paster, Marco Dos Santos, Zhangir Azerbayev, and Jimmy Ba. Openwebmath: An open dataset of high-quality mathematical web text. In The Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=jKHmjlpViu
work page 2024
-
[74]
Dynamic large concept models: Latent reasoning in an adaptive semantic space
Xingwei Qu, Shaowen Wang, Zihao Huang, Kai Hua, Fan Yin, Rui-Jie Zhu, Jundong Zhou, Qiyang Min, Zihao Wang, Yizhi Li, et al. Dynamic large concept models: Latent reasoning in an adaptive semantic space. arXiv preprint arXiv:2512.24617, 2025
-
[75]
Learning to Generate Reviews and Discovering Sentiment
Alec Radford, Rafal Jozefowicz, and Ilya Sutskever. Learning to generate reviews and discovering sentiment. arXiv preprint arXiv:1704.01444, 2017
work page Pith review arXiv 2017
-
[76]
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21 0 (140): 0 1--67, 2020. URL http://jmlr.org/papers/v21/20-074.html
work page 2020
- [77]
-
[78]
Solidgoldmagikarp (plus, prompt generation), 2023
Jessica Rumbelow and Matthew Watkins. Solidgoldmagikarp (plus, prompt generation), 2023. URL https://www.alignmentforum.org/posts/aPeJE8bSo6rAFoLqg/solidgoldmagikarp-plus-prompt-generation
work page 2023
-
[79]
Lotz, Emanuele Bugliarello, Elizabeth Salesky, Miryam de Lhoneux, and Desmond Elliott
Phillip Rust, Jonas F. Lotz, Emanuele Bugliarello, Elizabeth Salesky, Miryam de Lhoneux, and Desmond Elliott. Language modelling with pixels. In The Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum?id=FkSp8VW8RjH
work page 2023
-
[80]
Winogrande: An adversarial winograd schema challenge at scale
Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale. Proceedings of the AAAI Conference on Artificial Intelligence, 2020. URL https://ojs.aaai.org/index.php/AAAI/article/view/6399
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.