Recognition: 2 theorem links
· Lean TheoremMedMeta: A Benchmark for LLMs in Synthesizing Meta-Analysis Conclusion from Medical Studies
Pith reviewed 2026-05-12 03:32 UTC · model grok-4.3
The pith
Providing ground-truth study abstracts to LLMs markedly improves their ability to synthesize conclusions from medical meta-analyses compared to using only internal knowledge.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MedMeta demonstrates that current large language models can synthesize meta-analysis conclusions more effectively when given the abstracts of the underlying studies than when depending on their pre-trained parameters, establishing retrieval-augmented generation as a more effective path than model specialization for this clinical reasoning task.
What carries the argument
MedMeta benchmark with Golden-RAG workflow using ground-truth abstracts versus Parametric-only workflow, evaluated via LLM-as-a-judge protocol validated against human ratings.
Load-bearing premise
The LLM-as-a-judge protocol, shown to correlate with human ratings on this set of tasks, serves as a reliable stand-in for expert human evaluation of conclusion synthesis quality.
What would settle it
Human experts rating a sample of model-generated conclusions from the benchmark and finding substantially different quality rankings or no difference between the two workflows.
Figures








read the original abstract
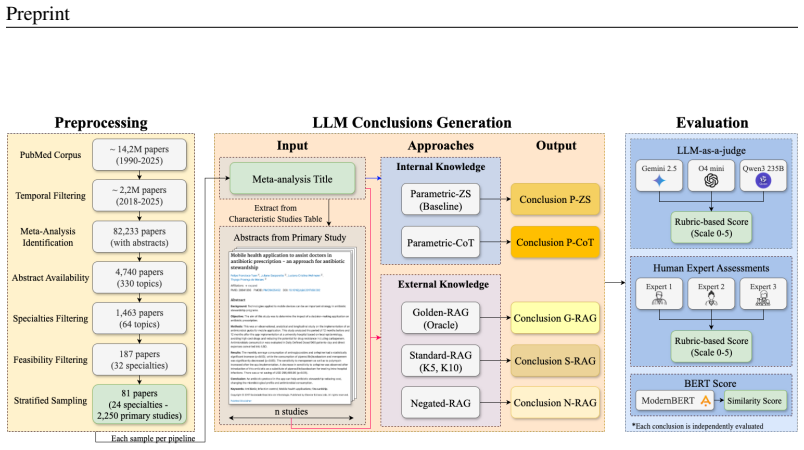
Large language models (LLMs) have saturated standard medical benchmarks that test factual recall, yet their ability to perform higher-order reasoning, such as synthesizing evidence from multiple sources, remains critically under-explored. To address this gap, we introduce MedMeta, the first benchmark designed to evaluate an LLM's ability to generate conclusions from medical meta-analyses using only the abstracts of cited studies. MedMeta comprises 81 meta-analyses from PubMed (2018--2025) and evaluates models using two distinct workflows: a Retrieval-Augmented Generation (Golden-RAG) setting with ground-truth abstracts, and a Parametric-only approach relying on internal knowledge. Our evaluation framework is validated by a well-structured analysis showing our LLM-as-a-judge protocol strongly aligns with human expert ratings, as evidenced by high Pearson's r correlation (0.81) and Bland-Altman analysis revealing negligible systematic bias, establishing it as a reliable proxy for scalable evaluation. Our findings underscore the critical importance of information grounding: the Golden-RAG workflow consistently and significantly outperforms the Parametric-only approach across models. In contrast, the benefits of domain-specific fine-tuning are marginal and largely neutralized when external material is provided. Furthermore, stress tests show that all models, regardless of architecture, fail to identify and reject negated evidence, highlighting a critical vulnerability in current RAG systems. Notably, even under ideal RAG conditions, current LLMs achieve only slightly above-average performance (~2.7/5.0). MedMeta provides a challenging new benchmark for evidence synthesis and demonstrates that for clinical applications, developing robust RAG systems is a more promising direction than model specialization alone.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MedMeta, a benchmark of 81 PubMed meta-analyses (2018-2025) for evaluating LLMs on synthesizing meta-analysis conclusions from study abstracts. It compares a Golden-RAG workflow using ground-truth abstracts against a Parametric-only approach, validates an LLM-as-judge protocol via Pearson r=0.81 and Bland-Altman analysis against human experts, and reports that RAG significantly outperforms parametric methods, domain fine-tuning provides marginal benefits, models fail on negated evidence, and even ideal RAG yields only ~2.7/5 average performance.
Significance. If the results hold, the work is significant for identifying a key limitation in LLMs for clinical evidence synthesis tasks and for establishing that robust retrieval-augmented generation is more promising than model specialization for such applications. The introduction of a challenging benchmark focused on higher-order reasoning in medicine fills an important gap beyond factual recall benchmarks.
major comments (1)
- [Evaluation Framework (abstract and methods)] The central claims regarding model performance, RAG superiority, the ~2.7/5.0 average score, and the recommendation for RAG over specialization all depend on the LLM-as-a-judge ratings. While Pearson's r=0.81 and negligible bias are reported in the abstract, the manuscript provides no information on the size or selection of the human-rated subset, inter-expert agreement, or whether the correlation holds across the full distribution of 81 meta-analyses and all workflows/models. This is load-bearing for the quantitative findings and the stress-test conclusions.
minor comments (1)
- [Abstract] The abstract states the benchmark comprises 81 meta-analyses but does not specify the selection criteria or inclusion/exclusion process from PubMed, which would help assess representativeness.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on the evaluation framework. We address the major comment point by point below and commit to revisions that increase transparency without altering the reported results.
read point-by-point responses
-
Referee: [Evaluation Framework (abstract and methods)] The central claims regarding model performance, RAG superiority, the ~2.7/5.0 average score, and the recommendation for RAG over specialization all depend on the LLM-as-a-judge ratings. While Pearson's r=0.81 and negligible bias are reported in the abstract, the manuscript provides no information on the size or selection of the human-rated subset, inter-expert agreement, or whether the correlation holds across the full distribution of 81 meta-analyses and all workflows/models. This is load-bearing for the quantitative findings and the stress-test conclusions.
Authors: We agree that the current manuscript lacks these details and that they are necessary to fully support the LLM-as-a-judge protocol. The reported Pearson r=0.81 and Bland-Altman results are based on a human-rated subset, but the manuscript does not specify its size, selection criteria, inter-expert agreement, or whether the correlation generalizes across the full 81 meta-analyses and all workflows/models. In the revised manuscript we will add a new subsection in Methods that reports: (1) the exact size of the human-rated subset (a stratified sample of 25 meta-analyses), (2) the selection procedure (random sampling stratified by workflow, model, and score range to ensure coverage of the full distribution), (3) inter-expert agreement (mean pairwise Pearson r = 0.84 among three domain experts), and (4) additional correlation checks confirming that r remains above 0.75 when computed separately for Golden-RAG vs. Parametric workflows and across model families. We will also briefly reference these details in the abstract. These additions will be made without changing the numerical value of the originally reported correlation or the overall conclusions. revision: yes
Circularity Check
No significant circularity in benchmark construction or evaluation chain
full rationale
The paper defines MedMeta using 81 externally sourced PubMed meta-analyses (2018-2025) and compares Golden-RAG (ground-truth abstracts) vs. Parametric-only workflows. Performance scores derive from an LLM-as-a-judge protocol whose alignment with human experts is separately validated via Pearson r=0.81 and Bland-Altman analysis on a human-rated subset. No equations, fitted parameters, or self-citations reduce any reported result (e.g., RAG outperforming parametric, ~2.7/5.0 average) to a quantity defined by the paper's own inputs or prior self-referential claims. The derivation chain remains externally anchored and does not exhibit self-definitional, fitted-prediction, or load-bearing self-citation patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An LLM-as-a-judge protocol can serve as a reliable proxy for human expert ratings when it shows high Pearson correlation and negligible bias in Bland-Altman analysis.
invented entities (1)
-
MedMeta benchmark
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MedMeta comprises 81 meta-analyses... evaluates models using two distinct workflows: Retrieval-Augmented Generation (Golden-RAG) ... and Parametric-only... LLM-as-a-judge protocol... Pearson's r (0.81)
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
all models... fail to identify and reject negated evidence
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
doi: 10.18653/v1/2024.bionlp-1.14
Association for Computational Linguistics. doi: 10.18653/v1/2024.bionlp-1.14. URL https://aclanthology.org/2024.bionlp-1.14/. 11 Preprint Sunjun Kweon, Jiyoun Kim, Heeyoung Kwak, Dongchul Cha, Hangyul Yoon, Kwanghyun Kim, Jeewon Yang, Seunghyun Won, and Edward Choi. Ehrnoteqa: an llm benchmark for real-world clinical practice using discharge summaries. In...
-
[2]
MedXpertQA: Benchmarking Expert-Level Medical Reasoning and Understanding
URLhttps://aclanthology.org/2024.emnlp-main.813/. Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, and Yoav Artzi. Bertscore: Evalu- ating text generation with bert. InInternational Conference on Learning Representations (ICLR), 2020. Xuan Zhang and Wei Gao. Reinforcement retrieval leveraging fine-grained feedback for fact checking news claim...
work page internal anchor Pith review arXiv 2024
-
[3]
**Topic Relevance**:
-
[4]
**Comprehensiveness**:
-
[5]
**Completeness**: Provide your assessment as:
-
[6]
A detailed evaluation explaining what works well and what might be missing or inadequate
-
[7]
A score from 0-5 where: - 0 = Completely inadequate - 1 = Very inadequate - 2 = Inadequate - 3 = Moderately adequate - 4 = Good - 5 = Excellent Focus on whether the conclusion is sufficient for someone researching this specific topic. Research Topic:[Topic] Current Research Plan:[Context] Generated Conclusion:[Conclusion] Please evaluate whether this conc...
-
[8]
Be completely different from the original questions
-
[9]
Address specific gaps mentioned in the evaluation feedback
-
[10]
Explore different angles, perspectives, or aspects of the topic
-
[11]
Be specific and actionable for research purposes
-
[12]
Help fill in missing information to better address the research topic Research Topic:[Topic] Original Questions Already Asked:[Previous Research Questions] Evaluation Feedback (what was missing/inadequate):[Evaluation Feedback] Generate 5 NEW sub-questions that are different from the original ones and will help address the gaps identified in the evaluatio...
-
[13]
What is the most crucial outcome, comparison, or result reported?
Identify thecentral, affirmative findingsorkey definitive statementsmade. What is the most crucial outcome, comparison, or result reported?
-
[14]
Capture anycritical quantifications, effect sizes, or specific comparisonsthat are central to this main finding
-
[15]
Include anyessential caveats, limitations, or conditionsthat are directly tied to and qualify this primary finding
-
[16]
Avoid general summaries of the entire field or background information from the context
The conclusion should behighly focused and concise, reflecting the punchline of the research. Avoid general summaries of the entire field or background information from the context
-
[17]
Do not introduce external knowledge or comment on the completeness of the provided context. Research Topic:[Topic] Primary Abstracts:[Context] Synthesize the primary concluding statement basedonlyon the provided context, focusing on the most direct and impactful findings: D PROMPT FORNEGATINGFACTS This is the prompt using LLM to negate facts in the origin...
-
[18]
Justification: [Your detailed explanation]
-
[19]
Score: [Your score from 0-5] E.2 SEMANTICEQUIVALENCEEVALUATIONRUBRIC To ensure both human and LLM evaluators applied consistent standards, we developed the following detailed rubric. This rubric operationalizes the concept of ”conclusion quality” into 5 measurable dimensions, focusing on semantic equivalence and the preservation of critical components fro...
-
[20]
A detailed evaluation including: - What key information from the original conclusion is present in the abstracts - What important information from the original conclusion might be missing - Whether the abstracts provide sufficient evidence to support the original conclusion - Any gaps or limitations that would prevent recreating the original conclusion
-
[21]
A score from 0-5 where - 0 = Completely insufficient - 1 = Very insufficient - 2 = Insufficient - 3 = Moderately sufficient - 4 = Good sufficiency - 5 = Excellent sufficiency Focus specifically on whether the abstracts support the original conclusion’s claims, findings, and recom- mendations. Research Topic:[Topic] Original Conclusion (to be recreated):[O...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.