Recognition: 2 theorem links
· Lean TheoremCausal Parametric Drift Simulation: A Digital Twin Framework for Classifier Robustness Evaluation
Pith reviewed 2026-05-12 04:50 UTC · model grok-4.3
The pith
Structural causal models serve as digital twins to simulate concept drift and expose classifier vulnerabilities that standard tests overlook.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that Structural Causal Models can act as digital twins of data-generating processes, supporting Causal Parametric Drift Simulation through targeted parametric interventions that preserve causal structure and thereby reveal latent classifier vulnerabilities invisible to static test sets, noise perturbations, or post-hoc correlation tools.
What carries the argument
Structural Causal Models used as digital twins to enable Causal Parametric Drift Simulation while maintaining causal dependencies during drift testing.
If this is right
- Classifiers can be evaluated against specific causal changes instead of generic noise or static holdouts.
- Pre-deployment testing becomes possible for vulnerabilities that correlation-based tools like SHAP and LIME do not capture.
- Standard drift detection can be complemented by proactive simulation of plausible future drifts.
- More reliable model selection and monitoring follow for tabular data in dynamic environments.
Where Pith is reading between the lines
- The same digital-twin approach could be applied to generate causally consistent training augmentations that improve robustness.
- Integration with online monitoring systems might allow continuous simulation of emerging drifts to trigger retraining.
- Validation on synthetic data with known ground-truth causal graphs would test whether the simulated drifts match actual shifts.
- Extension to non-tabular domains such as images or sequences would require adapting the structural models to those data types.
Load-bearing premise
The structural causal models constructed for a dataset accurately represent its true causal data-generating process and the chosen parametric interventions match meaningful real-world drifts.
What would settle it
A real-world deployment where a classifier's observed performance drop does not align with the specific vulnerabilities flagged by the simulation on matching data would disprove the method's ability to expose true latent weaknesses.
Figures





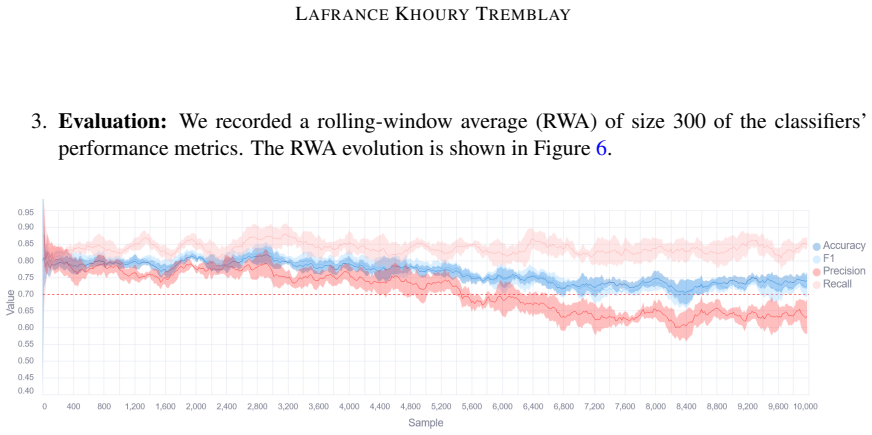







read the original abstract
Machine learning classifiers in dynamic environments face concept drift -- changes in the data-generating process that degrade performance. Conventional evaluation via static test sets or noise perturbations fails to preserve causal dependencies in tabular data, often producing causally invalid assessments. Post-hoc tools like SHAP and LIME offer correlational insights that may not reflect the causal mechanisms driving model failure. We propose a framework that complements existing drift detection by leveraging Structural Causal Models as "Digital Twins" of data-generating processes, enabling precise causal interventions while preserving structural dependencies. Our technique, Causal Parametric Drift Simulation, stress-tests classifiers to identify vulnerabilities before deployment. Experiments on the Open Sourcing Mental Illness (OSMH) dataset demonstrate that this approach exposes latent vulnerabilities invisible to standard statistical monitors.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Causal Parametric Drift Simulation, a framework that uses Structural Causal Models (SCMs) as digital twins of data-generating processes to enable precise causal interventions for stress-testing ML classifiers under concept drift in tabular data. It claims this preserves structural dependencies better than static test sets or noise perturbations and outperforms post-hoc tools like SHAP/LIME for identifying failure mechanisms. Experiments on the Open Sourcing Mental Illness (OSMH) dataset are presented as demonstrating that the method exposes latent vulnerabilities invisible to standard statistical monitors.
Significance. If the SCMs are shown to be faithful and the interventions meaningful, the approach could provide a useful complement to existing drift detection by enabling controlled, causally valid robustness evaluation before deployment. The digital-twin framing is conceptually appealing for dynamic environments, but its significance hinges on verifiable empirical support that is not yet detailed.
major comments (2)
- Abstract: the claim that 'experiments on the OSMH dataset demonstrate that this approach exposes latent vulnerabilities invisible to standard statistical monitors' is unsupported because the abstract (and by extension the manuscript) supplies no information on SCM construction, parameter estimation, chosen interventions, baselines, metrics, or statistical tests, rendering the central empirical claim unverifiable.
- Methods/Experiments sections: the manuscript provides no description of how the Structural Causal Model for the OSMH dataset was constructed or validated (structure learning algorithm, parameter fitting procedure, goodness-of-fit diagnostics, or sensitivity checks). Without this, it cannot be established that the parametric drifts correspond to plausible real-world concept drift or that the SCM accurately represents the true data-generating process, which is load-bearing for the 'invisible vulnerabilities' claim.
minor comments (1)
- Abstract: the distinction between 'Causal Parametric Drift Simulation' and conventional drift detection could be clarified with a brief sentence on what 'parametric' specifically adds beyond standard SCM interventions.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. We agree that the original manuscript lacked sufficient methodological transparency to support the central empirical claims, and we have revised the paper to include the requested details on SCM construction, validation, interventions, baselines, metrics, and statistical procedures. These changes make the 'invisible vulnerabilities' claim verifiable while preserving the core contribution of the digital-twin framework. We address each major comment below.
read point-by-point responses
-
Referee: Abstract: the claim that 'experiments on the OSMH dataset demonstrate that this approach exposes latent vulnerabilities invisible to standard statistical monitors' is unsupported because the abstract (and by extension the manuscript) supplies no information on SCM construction, parameter estimation, chosen interventions, baselines, metrics, or statistical tests, rendering the central empirical claim unverifiable.
Authors: We accept this criticism. The original abstract was overly concise and omitted key supporting information. In the revised manuscript we have expanded the abstract to briefly state the SCM construction approach (PC algorithm for structure learning with α=0.01 followed by MLE parameter fitting under linear-Gaussian assumptions), the interventions (targeted parametric shifts on causal parents), the baselines (ADWIN, Page-Hinkley, and static test sets), the metrics (ΔF1, ΔAUC, and vulnerability-identification precision), and the statistical tests (bootstrap confidence intervals and paired t-tests). We have also replaced 'demonstrate' with 'suggest' to reflect the scope of the evidence. The full technical details now appear in the new 'SCM Construction and Validation' and 'Experimental Setup' subsections, rendering the claim verifiable from the manuscript. revision: yes
-
Referee: Methods/Experiments sections: the manuscript provides no description of how the Structural Causal Model for the OSMH dataset was constructed or validated (structure learning algorithm, parameter fitting procedure, goodness-of-fit diagnostics, or sensitivity checks). Without this, it cannot be established that the parametric drifts correspond to plausible real-world concept drift or that the SCM accurately represents the true data-generating process, which is load-bearing for the 'invisible vulnerabilities' claim.
Authors: We agree that these details were missing from the original submission and that they are essential for the claim. The revised manuscript adds a complete 'SCM Construction and Validation' subsection that specifies: (i) structure learning via the PC algorithm with conditional-independence tests at α=0.01 on the OSMH feature set; (ii) parameter estimation by ordinary least squares under linear-Gaussian SCM assumptions; (iii) goodness-of-fit diagnostics consisting of d-separation checks for all implied conditional independencies and Kolmogorov-Smirnov tests on model residuals; and (iv) sensitivity analyses that vary edge coefficients by ±20 % and re-evaluate intervention outcomes. We further justify plausibility by linking the chosen parametric drifts (e.g., mean shifts in survey-response variables) to documented real-world changes in mental-health reporting patterns. These additions directly substantiate that the simulated drifts are causally meaningful and that the SCM is a faithful digital twin. revision: yes
Circularity Check
No circularity; framework proposal is self-contained with no load-bearing reductions
full rationale
The paper introduces Causal Parametric Drift Simulation as a framework that uses Structural Causal Models as digital twins to enable causal interventions for classifier stress-testing. No equations, parameter-fitting steps, derivations, or self-citations appear in the provided text that would reduce the central claim (exposure of latent vulnerabilities on OSMH) to its own inputs by construction. The experiments are presented as empirical demonstrations rather than tautological outputs of fitted parameters or renamed known results. The accuracy of the SCMs is an external assumption about the data-generating process, not a definitional or self-referential step internal to the derivation. This is the normal case of a proposal whose validity can be checked against independent benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a framework that complements existing drift detection by leveraging Structural Causal Models as 'Digital Twins' of data-generating processes, enabling precise causal interventions while preserving structural dependencies.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Causal Parametric Drift Simulation... incrementally shifts specific causal mechanisms to expose latent vulnerabilities
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
M. S. Abdul Razak , C. R. Nirmala, B. R. Sreenivasa, Husam Lahza, and Hassan Fareed M. Lahza. A survey on detecting healthcare concept drift in AI / ML models from a finance perspective. Frontiers in Artificial Intelligence, 5, April 2023. ISSN 2624-8212. doi:10.3389/frai.2022.955314. Publisher: Frontiers
-
[2]
Martin Arjovsky, L \'e on Bottou, Ishaan Gulrajani, and David Lopez-Paz. Invariant risk minimization. arXiv preprint arXiv:1907.02893, 2019
work page internal anchor Pith review arXiv 1907
-
[3]
Assuring the Machine Learning Lifecycle : Desiderata , Methods , and Challenges
Rob Ashmore, Radu Calinescu, and Colin Paterson. Assuring the Machine Learning Lifecycle : Desiderata , Methods , and Challenges . ACM Computing Surveys, 54 0 (5): 0 1--39, June 2022. ISSN 0360-0300, 1557-7341. doi:10.1145/3453444
-
[4]
Patrick Bl \"o baum, Peter G \"o tz, Kailash Budhathoki, Atalanti A. Mastakouri, and Dominik Janzing. Dowhy-gcm: An extension of dowhy for causal inference in graphical causal models. Journal of Machine Learning Research, 25 0 (147): 0 1--7, 2024. URL http://jmlr.org/papers/v25/22-1258.html
work page 2024
-
[5]
Estimating and Explaining Model Performance When Both Covariates and Labels Shift
Lingjiao Chen, Matei Zaharia, and James Zou. Estimating and Explaining Model Performance When Both Covariates and Labels Shift . 2022. doi:10.48550/ARXIV.2209.08436
-
[6]
Tianqi Chen and Carlos Guestrin. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD '16, page 785–794, New York, NY, USA, 2016. Association for Computing Machinery. ISBN 9781450342322. doi:10.1145/2939672.2939785. URL https://doi.org/10.1145/2939672.2939785
-
[7]
Framework for Testing Robustness of Machine Learning - Based Classifiers
Joshua Chuah, Uwe Kruger, Ge Wang, Pingkun Yan, and Juergen Hahn. Framework for Testing Robustness of Machine Learning - Based Classifiers . Journal of Personalized Medicine, 12 0 (8): 0 1314, August 2022. ISSN 2075-4426. doi:10.3390/jpm12081314. Number: 8 Publisher: Multidisciplinary Digital Publishing Institute
-
[8]
Statistical Power Analysis for the Behavioral Sciences
Jacob Cohen. Statistical Power Analysis for the Behavioral Sciences. Lawrence Erlbaum Associates, 2nd edition, 1988
work page 1988
-
[9]
Lucas: Lung cancer screening with multimodal biomarkers
Laura Daza, Angela Castillo, Mar\' a Escobar, Sergio Valencia, Bibiana Pinz\' o n, and Pablo Arbel\' a ez. Lucas: Lung cancer screening with multimodal biomarkers. In Multimodal Learning for Clinical Decision Support and Clinical Image-Based Procedures: 10th International Workshop, ML-CDS 2020, and 9th International Workshop, CLIP 2020, Held in Conjunctio...
-
[10]
Kolmogorov--Smirnov Test, pages 283--287
Yadolah Dodge. Kolmogorov--Smirnov Test, pages 283--287. Springer New York, New York, NY, 2008. ISBN 978-0-387-32833-1. doi:10.1007/978-0-387-32833-1_214. URL https://doi.org/10.1007/978-0-387-32833-1_214
-
[11]
Asymmetric shapley values: incorporating causal knowledge into model-agnostic explainability
Christopher Frye, Colin Rowat, and Ilya Feige. Asymmetric shapley values: incorporating causal knowledge into model-agnostic explainability. Advances in neural information processing systems, 33: 0 1229--1239, 2020
work page 2020
-
[12]
An overview of unsupervised drift detection methods
Rosana Noronha Gemaque, Albert Fran c a Josu \'a Costa, Rafael Giusti, and Eulanda Miranda Dos Santos. An overview of unsupervised drift detection methods. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery, 10 0 (6): 0 e1381, 2020
work page 2020
-
[13]
Review of Causal Discovery Methods Based on Graphical Models
Clark Glymour, Kun Zhang, and Peter Spirtes. Review of Causal Discovery Methods Based on Graphical Models . Frontiers in Genetics, 10, June 2019. ISSN 1664-8021. doi:10.3389/fgene.2019.00524. Publisher: Frontiers
-
[14]
Paulo M. Gonçalves, Silas G.T. De Carvalho Santos, Roberto S.M. Barros, and Davi C.L. Vieira. A comparative study on concept drift detectors. Expert Systems with Applications, 41 0 (18): 0 8144--8156, December 2014. ISSN 09574174. doi:10.1016/j.eswa.2014.07.019
-
[15]
Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron C
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron C. Courville, and Yoshua Bengio. Generative adversarial nets. In Neural Information Processing Systems, 2014. URL https://api.semanticscholar.org/CorpusID:261560300
work page 2014
-
[16]
Mario Grassi, Fernando Palluzzi, and Barbara Tarantino. Semgraph: an r package for causal network inference of high-throughput data with structural equation models. Bioinformatics, 38 0 (20): 0 4829--4830, 08 2022. ISSN 1367-4811. doi:10.1093/bioinformatics/btac567. URL https://doi.org/10.1093/bioinformatics/btac567
-
[17]
Digital twins: past, present, and future
Michael W Grieves. Digital twins: past, present, and future. In The digital twin, pages 97--121. Springer, 2023
work page 2023
-
[18]
Concept Drift Evolution In Machine Learning Approaches : A Systematic Literature Review
Manzoor Ahmed Hashmani, Syed Muslim Jameel, Mobashar Rehman, and Atsushi Inoue. Concept Drift Evolution In Machine Learning Approaches : A Systematic Literature Review . International Journal on Smart Sensing and Intelligent Systems, 13 0 (1): 0 1--16, January 2020. doi:10.21307/ijssis-2020-029
-
[19]
Miguel A Hern \'a n and James M Robins. Causal Inference: What If. Chapman & Hall/CRC, 2020
work page 2020
-
[20]
Daire Hooper, Joseph Coughlan, and Michael R. Mullen. Structural equation modelling: guidelines for determining model fit. 2008. URL https://api.semanticscholar.org/CorpusID:32672489
work page 2008
-
[21]
Feature relevance quantification in explainable ai: A causal problem
Dominik Janzing, Lenon Minorics, and Patrick Bl \"o baum. Feature relevance quantification in explainable ai: A causal problem. In International Conference on artificial intelligence and statistics, pages 2907--2916. PMLR, 2020
work page 2020
-
[22]
Addressing concept drift in machine learning-based monitoring of manufacturing processes
Nicolas Jourdan. Addressing concept drift in machine learning-based monitoring of manufacturing processes. 2024
work page 2024
-
[23]
Auto-Encoding Variational Bayes
Diederik P. Kingma and Max Welling. Auto-encoding variational bayes. CoRR, abs/1312.6114, 2013. URL https://api.semanticscholar.org/CorpusID:216078090
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[24]
Dimakis, and Sriram Vishwanath
Murat Kocaoglu, Christopher Snyder, Alexandros G. Dimakis, and Sriram Vishwanath. CausalGAN : Learning causal implicit generative models with adversarial training. In International Conference on Learning Representations, 2018
work page 2018
-
[25]
Indra Elizabeth Kumar, Suresh Venkatasubramanian, Carlos Eduardo Scheidegger, and Sorelle A. Friedler. Problems with shapley-value-based explanations as feature importance measures. In International Conference on Machine Learning, 2020. URL https://api.semanticscholar.org/CorpusID:211296386
work page 2020
-
[26]
Jie Lu, Anjin Liu, Fan Dong, Feng Gu, Joao Gama, and Guangquan Zhang. Learning under Concept Drift : A Review . IEEE Transactions on Knowledge and Data Engineering, 2018. ISSN 1041-4347, 1558-2191, 2326-3865. doi:10.1109/TKDE.2018.2876857. arXiv:2004.05785 [cs, stat]
-
[27]
Scott M. Lundberg and Su-In Lee. A Unified Approach to Interpreting Model Predictions . May 2017
work page 2017
-
[28]
The chi-square test of independence
Mary McHugh. The chi-square test of independence. Biochemia medica, 23: 0 143--9, 06 2013. doi:10.11613/BM.2013.018
-
[29]
Stefan Mihai, Mahnoor Yaqoob, Dang V. Hung, William Davis, Praveer Towakel, Mohsin Raza, Mehmet Karamanoglu, Balbir Barn, Dattaprasad Shetve, Raja V. Prasad, Hrishikesh Venkataraman, Ramona Trestian, and Huan X. Nguyen. Digital Twins : A Survey on Enabling Technologies , Challenges , Trends and Future Prospects . IEEE Communications Surveys & Tutorials, 2...
-
[30]
Bo Bernhard Nielsen and Jose M. Cortina. Calculating and reporting degrees of freedom in structural equation modeling: an empirical generalization study. Journal of International Business Studies, April 2025. ISSN 1478-6990. doi:10.1057/s41267-025-00781-3. URL https://doi.org/10.1057/s41267-025-00781-3
-
[31]
Nick Pawlowski, Daniel C. Castro, and Ben Glocker. Deep structural causal models for tractable counterfactual inference. In Advances in Neural Information Processing Systems, 2020
work page 2020
-
[32]
Causal inference in statistics: An overview
Judea Pearl. Causal inference in statistics: An overview. 2009 a
work page 2009
-
[33]
Causality: Models , Reasoning and Inference
Judea Pearl. Causality: Models , Reasoning and Inference . Cambridge University Press, USA, 2nd edition, August 2009 b . ISBN 978-0-521-89560-6
work page 2009
-
[34]
F. Pedregosa, G. Varoquaux, A. Gramfort, V. Michel, B. Thirion, O. Grisel, M. Blondel, P. Prettenhofer, R. Weiss, V. Dubourg, J. Vanderplas, A. Passos, D. Cournapeau, M. Brucher, M. Perrot, and E. Duchesnay. Scikit-learn: Machine learning in P ython. Journal of Machine Learning Research, 12: 0 2825--2830, 2011
work page 2011
-
[35]
Ridho Rahmadi, Perry Groot, Marianne Heins, Hans Knoop, Tom Heskes, et al. Causality on cross-sectional data: Stable specification search in constrained structural equation modeling. Applied Soft Computing, 52: 0 687--698, 2017
work page 2017
-
[36]
Chapter 3 - calculus and optimization
Jingli Ren and Haiyan Wang. Chapter 3 - calculus and optimization. In Jingli Ren and Haiyan Wang, editors, Mathematical Methods in Data Science, pages 51--89. Elsevier, 2023. ISBN 978-0-443-18679-0. doi:https://doi.org/10.1016/B978-0-44-318679-0.00009-0. URL https://www.sciencedirect.com/science/article/pii/B9780443186790000090
-
[37]
Marco Tulio Ribeiro, Sameer Singh, and Carlos Guestrin. " Why Should I Trust You ?": Explaining the Predictions of Any Classifier . Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pages 1135--1144, August 2016. doi:10.1145/2939672.2939778. Conference Name: KDD '16: The 22nd ACM SIGKDD International Confe...
-
[38]
Karin Schermelleh-Engel, Helfried Moosbrugger, and Hans M \"u ller. Evaluating the fit of structural equation models: Tests of significance and descriptive goodness-of-fit measures. Methods of Psychological Research, 2003
work page 2003
-
[39]
Toward causal representation learning
Bernhard Sch \"o lkopf, Francesco Locatello, Stefan Bauer, Nan Rosemary Ke, Nal Kalchbrenner, Anirudh Goyal, and Yoshua Bengio. Toward causal representation learning. Proceedings of the IEEE, 109 0 (5): 0 612--634, 2021
work page 2021
-
[40]
Vikash Sehwag, Saeed Mahloujifar, Tinashe Handina, Sihui Dai, Chong Xiang, Mung Chiang, and Prateek Mittal. Robust Learning Meets Generative Models : can Proxy Distributions Improve Adversarial Robustness ? 2022
work page 2022
-
[41]
Data cards: Purposeful and transparent dataset documentation for responsible AI
Lesia Semenova, Cynthia Rudin, and Ronald Parr. On the Existence of Simpler Machine Learning Models . In Proceedings of the 2022 ACM Conference on Fairness , Accountability , and Transparency , FAccT '22, pages 1827--1858, New York, NY, USA, June 2022. Association for Computing Machinery. ISBN 978-1-4503-9352-2. doi:10.1145/3531146.3533232
-
[42]
Dowhy: An end-to-end library for causal inference, 2020
Amit Sharma and Emre Kiciman. Dowhy: An end-to-end library for causal inference, 2020. URL https://arxiv.org/abs/2011.04216
-
[43]
Hoyer, Aapo Hyv&\#228, rinen, and Antti Kerminen
Shohei Shimizu, Patrik O. Hoyer, Aapo Hyv&\#228, rinen, and Antti Kerminen. A Linear Non - Gaussian Acyclic Model for Causal Discovery . Journal of Machine Learning Research, 7 0 (72): 0 2003--2030, 2006. ISSN 1533-7928
work page 2003
-
[44]
A survey of outlier detection in high dimensional data streams
Imen Souiden, Mohamed Nazih Omri, and Zaki Brahmi. A survey of outlier detection in high dimensional data streams. Computer Science Review, 44: 0 100463, 2022. ISSN 1574-0137. doi:https://doi.org/10.1016/j.cosrev.2022.100463. URL https://www.sciencedirect.com/science/article/pii/S1574013722000107
-
[45]
Causation, Prediction , and Search
Peter Spirtes, Clark Glymour, and Richard Scheines. Causation, Prediction , and Search . The MIT Press, January 2001. ISBN 978-0-262-28415-8. doi:10.7551/mitpress/1754.001.0001
-
[46]
Sullivan, Merrill Warkentin, and Linda Wallace
Joe H. Sullivan, Merrill Warkentin, and Linda Wallace. So many ways for assessing outliers: What really works and does it matter? Journal of Business Research, 132: 0 530--543, 2021. ISSN 0148-2963
work page 2021
-
[47]
The problem of concept drift: Definitions and related work
Alexey Tsymbal. The problem of concept drift: Definitions and related work. Computer Science Department, Trinity College Dublin, 106 0 (2): 0 58, 2004
work page 2004
-
[48]
Jodie B Ullman and Peter M Bentler. Structural equation modeling. Handbook of psychology, second edition, 2, 2012
work page 2012
-
[49]
Ben Van Calster, Gary S. Collins, Andrew J. Vickers, Laure Wynants, Kathleen F. Kerr, Lasai Barrene \ n ada, Ga \"e l Varoquaux, Karandeep Singh, Karel G. M. Moons, Tina Hernandez-Boussard, Dirk Timmerman, David J. McLernon, Maarten van Smeden, and Ewout W. Steyerberg. Evaluation of performance measures in predictive artificial intelligence models to supp...
-
[50]
Mlops in practice: A framework for scalable ai model deployment, monitoring, and retraining
Vidyasagar Vangala. Mlops in practice: A framework for scalable ai model deployment, monitoring, and retraining. International Journal of Machine Learning Research in Cybersecurity and Artificial Intelligence, 13 0 (01): 0 740--753, 2022
work page 2022
-
[51]
Causal- TGAN : Generating tabular data using causal generative adversarial networks
Bingyang Wen, Luis Oala Colon, Ronny Hansch, and Brinnae Walsh. Causal- TGAN : Generating tabular data using causal generative adversarial networks. arXiv preprint arXiv:2104.10680, 2021
-
[52]
As uncertainty remains, anxiety and stress reach a tipping point at work: AI at work 2020 study
Workplace Intelligence . As uncertainty remains, anxiety and stress reach a tipping point at work: AI at work 2020 study. White paper, Oracle Corporation, October 2020. URL https://www.oracle.com/a/ocom/docs/applications/hcm/ai-at-work-2020.pdf
work page 2020
-
[53]
Modeling tabular data using conditional gan
Lei Xu, Maria Skoularidou, Alfredo Cuesta-Infante, and Kalyan Veeramachaneni. Modeling tabular data using conditional gan. Advances in neural information processing systems, 32, 2019
work page 2019
-
[54]
Bayesian autoencoders for drift detection in industrial environments
Bang Xiang Yong, Yasmin Fathy, and Alexandra Brintrup. Bayesian autoencoders for drift detection in industrial environments. In 2020 IEEE international workshop on metrology for industry 4.0 & IoT, pages 627--631. IEEE, 2020
work page 2020
-
[55]
Addt--a digital twin framework for proactive safety validation in autonomous driving systems
Bo Yu, Chaoran Yuan, Zishen Wan, Jie Tang, Fadi Kurdahi, and Shaoshan Liu. Addt--a digital twin framework for proactive safety validation in autonomous driving systems. arXiv preprint arXiv:2504.09461, 2025
-
[56]
Xiaoge Zhang, Xiao-Lin Wang, Fenglei Fan, Yiu-Ming Cheung, and Indranil Bose. Enhancing the performance of neural networks through causal discovery and integration of domain knowledge. arXiv preprint arXiv:2311.17303, 2023
-
[57]
Xun Zheng, Bryon Aragam, Pradeep Ravikumar, and Eric P. Xing. DAGs with NO TEARS : Continuous optimization for structure learning. In Advances in Neural Information Processing Systems, 2018
work page 2018
-
[58]
An overview of concept drift applications
Indr \.e Z liobait \.e . An overview of concept drift applications. In Big Data Analysis: New Algorithms for a New Society, pages 91--114. Springer, 2016
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.