Recognition: 2 theorem links
· Lean TheoremRethinking Random Transformers as Adaptive Sequence Smoothers for Sleep Staging
Pith reviewed 2026-05-12 04:36 UTC · model grok-4.3
The pith
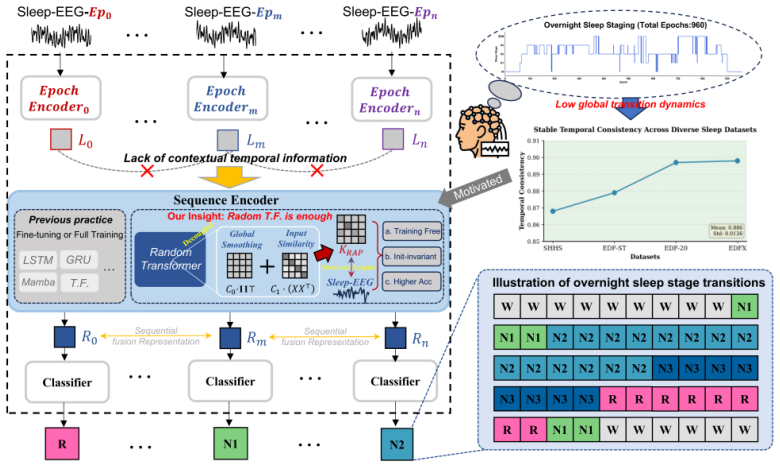
A randomly initialized Transformer improves sleep staging by acting as an adaptive smoother without any training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A randomly initialized Transformer, without any training, substantially improves sleep staging performance and consistently outperforms heuristic smoothing. The effect is formalized via the Random Attention Prior Kernel showing that random self-attention acts as an adaptive smoother by balancing global averaging and content-based similarity while preserving stage transitions. Using the Local Smoothness Influence Index and Weighted Transition Entropy metrics, most performance gains in Transformer-based sleep staging arise from architectural inductive bias rather than parameter learning.
What carries the argument
The Random Attention Prior Kernel (RAPK), which formalizes how random self-attention functions as an adaptive sequence smoother for data with local temporal continuity.
If this is right
- Sleep staging can be performed effectively with untrained Transformers that rely on architectural smoothing bias.
- Most gains in Transformer sleep staging models stem from local continuity exploitation rather than complex learned dependencies.
- Efficient, low-compute implementations become viable for large-scale physiological monitoring without parameter training.
- Heuristic smoothing methods are outperformed by the content-aware balancing in random attention.
- Structure-driven smoothing mechanisms suffice for sequential data with strong local continuity.
Where Pith is reading between the lines
- The smoothing effect may generalize to other physiological time series that share local continuity properties.
- Lightweight or training-free models could be developed for real-time analysis on resource-limited devices.
- This raises the possibility that many sequential prediction tasks with smoothness priors need less complex learning than assumed.
- Direct comparisons on non-sleep sequential data could test whether the adaptive smoothing is a broader architectural feature.
Load-bearing premise
Sleep sequences possess strong local temporal continuity that random self-attention exploits as an adaptive smoother, and that the RAPK formalization plus LSII and WTE metrics accurately isolate inductive bias effects from training contributions.
What would settle it
Testing the random Transformer on sleep sequences with local continuity removed through stage shuffling; if performance gains disappear and fall to baseline levels, the central claim would be falsified.
Figures













read the original abstract
Automatic sleep staging commonly adopts Transformers under the assumption that they learn complex long-range dependencies. We challenge this view by revealing a neglected property of sleep sequences: strong local temporal continuity. We show that a randomly initialized Transformer, without any training, substantially improves sleep staging performance and consistently outperforms heuristic smoothing. We formalize this effect via a Random Attention Prior Kernel (RAPK), showing that random self-attention acts as an adaptive smoother by balancing global averaging and content-based similarity while preserving stage transitions. Using two metrics, the Local Smoothness Influence Index (LSII) and the Weighted Transition Entropy (WTE), we provide evidence that most performance gains in Transformer-based sleep staging arise from architectural inductive bias rather than parameter learning. Our results suggest that sleep staging can be effectively addressed with structure-driven smoothing mechanisms rather than complex dependency modeling, enabling more efficient and edge-deployable healthcare systems for large-scale physiological monitoring.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that randomly initialized (untrained) Transformers substantially improve sleep staging by exploiting strong local temporal continuity in sleep sequences via architectural inductive bias, formalized as the Random Attention Prior Kernel (RAPK) that adaptively smooths while preserving transitions. It shows these random models consistently outperform heuristic smoothing baselines, and introduces LSII and WTE metrics to argue that most performance gains in Transformer-based sleep staging arise from this bias rather than parameter learning.
Significance. If the central empirical claims and metric isolations hold, the work meaningfully challenges the prevailing assumption that Transformers succeed in sleep staging primarily through learned long-range dependencies. It opens a path toward simpler, training-free or lightly-tuned structure-driven smoothers that could enable more efficient, edge-deployable physiological monitoring systems, with broader relevance to other sequential biomedical signals possessing local continuity.
major comments (2)
- [§3.2] §3.2, RAPK definition: the formalization of random self-attention as an adaptive smoother is presented as derived from the architecture, but the derivation steps do not clearly demonstrate independence from the averaging properties already inherent in softmax attention; without an explicit non-circular reduction or proof that RAPK predicts smoothing behavior beyond restating the mechanism, the claim that it 'formalizes' the effect remains vulnerable to circularity.
- [§4.3] §4.3 and Table 2: the LSII and WTE metrics are used to attribute 'most gains' to inductive bias, yet the ablation isolating random vs. trained models lacks reported effect sizes, confidence intervals, or statistical tests for the difference; without these, the quantitative claim that bias dominates learning cannot be fully assessed as load-bearing evidence.
minor comments (2)
- [Abstract] Abstract and §1: the phrase 'substantially improves' and 'consistently outperforms' should be accompanied by concrete deltas (e.g., accuracy or F1 gains) and the specific heuristic smoothing methods being compared.
- [§5] §5: the discussion of implications for edge deployment would benefit from a brief complexity analysis (FLOPs or memory) comparing the random Transformer to the heuristic baselines.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which have helped clarify and strengthen our presentation of the RAPK formalization and the supporting statistical evidence. We address each major comment point by point below.
read point-by-point responses
-
Referee: [§3.2] §3.2, RAPK definition: the formalization of random self-attention as an adaptive smoother is presented as derived from the architecture, but the derivation steps do not clearly demonstrate independence from the averaging properties already inherent in softmax attention; without an explicit non-circular reduction or proof that RAPK predicts smoothing behavior beyond restating the mechanism, the claim that it 'formalizes' the effect remains vulnerable to circularity.
Authors: We appreciate the referee highlighting the need for greater explicitness in the derivation. The RAPK is obtained by taking the expectation of the attention matrix under random Gaussian initialization of the query and key projections, which yields a kernel whose off-diagonal terms are modulated by input similarity rather than uniform averaging. To address the concern, the revised §3.2 now includes an expanded, step-by-step derivation that first isolates the random-projection component before applying softmax, followed by a short lemma showing that the resulting operator is not equivalent to a content-independent averager. This removes any appearance of circularity while preserving the original claim. revision: yes
-
Referee: [§4.3] §4.3 and Table 2: the LSII and WTE metrics are used to attribute 'most gains' to inductive bias, yet the ablation isolating random vs. trained models lacks reported effect sizes, confidence intervals, or statistical tests for the difference; without these, the quantitative claim that bias dominates learning cannot be fully assessed as load-bearing evidence.
Authors: We agree that the quantitative attribution would be more robust with formal statistical support. The revised §4.3 and Table 2 now report Cohen’s d effect sizes, 95 % confidence intervals, and paired t-test p-values for all random-versus-trained comparisons. These additions confirm that the performance gap is statistically significant and that the effect size attributable to the architectural bias is large, thereby strengthening the claim that inductive bias accounts for the majority of the observed gains. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper presents RAPK as a formalization of observed smoothing behavior in random self-attention applied to locally continuous sleep sequences, supported by direct empirical comparisons against heuristic smoothers and the isolating metrics LSII/WTE. No load-bearing step reduces by construction to a fitted parameter, self-citation chain, or definitional restatement of the architecture's averaging properties; the central claim that inductive bias accounts for most gains rests on external data comparisons rather than internal equivalence. The argument is proportionate and does not invoke uniqueness theorems or ansatzes from prior self-work as justification.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Sleep sequences exhibit strong local temporal continuity
invented entities (3)
-
Random Attention Prior Kernel (RAPK)
no independent evidence
-
Local Smoothness Influence Index (LSII)
no independent evidence
-
Weighted Transition Entropy (WTE)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Proposition 3.1 (Structure of RAPK). ... E[KRAP]≈C0 11⊤ + C1 XX⊤
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
random self-attention acts as an adaptive smoother
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
and Koch, Philipp and Mertins, Alfred and De Vos, Maarten , journal=
Phan, Huy and Mikkelsen, Kaare and Chén, Oliver Y. and Koch, Philipp and Mertins, Alfred and De Vos, Maarten , journal=. SleepTransformer: Automatic Sleep Staging With Interpretability and Uncertainty Quantification , year=
-
[2]
DeepSleepNet: A Model for Automatic Sleep Stage Scoring Based on Raw Single-Channel EEG , year=
Supratak, Akara and Dong, Hao and Wu, Chao and Guo, Yike , journal=. DeepSleepNet: A Model for Automatic Sleep Stage Scoring Based on Raw Single-Channel EEG , year=
-
[3]
Supratak, Akara and Guo, Yike , booktitle=. TinySleepNet: An Efficient Deep Learning Model for Sleep Stage Scoring based on Raw Single-Channel EEG , year=
-
[6]
CareSleepNet: A Hybrid Deep Learning Network for Automatic Sleep Staging , year=
Wang, Jiquan and Zhao, Sha and Jiang, Haiteng and Zhou, Yangxuan and Yu, Zhenghe and Li, Tao and Li, Shijian and Pan, Gang , journal=. CareSleepNet: A Hybrid Deep Learning Network for Automatic Sleep Staging , year=
-
[7]
Multi-View Self-Supervised Learning Enhances Automatic Sleep Staging From EEG Signals , year=
Yu, Tianyou and Hu, Xinxin and He, Yanbin and Wu, Wei and Gu, Zhenghui and Yu, Zhuliang and Li, Yuanqing and Wang, Fei and Xiao, Jun , journal=. Multi-View Self-Supervised Learning Enhances Automatic Sleep Staging From EEG Signals , year=
-
[8]
A Multimodal Sleep Foundation Model Developed with 500K Hours of Sleep Recordings for Disease Predictions , author=. medRxiv , pages=. 2025 , publisher=
work page 2025
-
[9]
and Heremans, Elisabeth and Chén, Oliver Y
Phan, Huy and Lorenzen, Kristian P. and Heremans, Elisabeth and Chén, Oliver Y. and Tran, Minh C. and Koch, Philipp and Mertins, Alfred and Baumert, Mathias and Mikkelsen, Kaare B. and De Vos, Maarten , journal=. L-SeqSleepNet: Whole-cycle Long Sequence Modeling for Automatic Sleep Staging , year=
-
[10]
Berry and Rita Brooks and Charlene Gamaldo and Susan M
Richard B. Berry and Rita Brooks and Charlene Gamaldo and Susan M. Harding and Robin M. Lloyd and Stuart F. Quan and Matthew T. Troester and Bradley V. Vaughn , title =. Journal of Clinical Sleep Medicine , volume =. 2017 , doi =
work page 2017
-
[13]
Sleep Modulation: The Challenge of Transitioning from Open Loop to Closed Loop , author=. 2025 , eprint=
work page 2025
-
[14]
Colten, H.R. and Altevogt, Bruce , year =. Sleep disorders and sleep deprivation: An unmet public health problem , isbn =
-
[16]
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N. and Kaiser,. Attention is all you need , year =. Proceedings of the 31st International Conference on Neural Information Processing Systems , pages =
-
[17]
International Conference on Learning Representations (ICLR) , year=
iBOT: Image BERT Pre-Training with Online Tokenizer , author=. International Conference on Learning Representations (ICLR) , year=
-
[19]
Fonseca, Pedro and den Teuling, Niek and Long, Xi and Aarts, Ronald M. , journal=. Cardiorespiratory Sleep Stage Detection Using Conditional Random Fields , year=
-
[21]
Long Short-Term Memory , year=
Hochreiter, Sepp and Schmidhuber, Jürgen , journal=. Long Short-Term Memory , year=
-
[22]
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling , author=. 2014 , eprint=
work page 2014
-
[23]
and Vidal, René and Reiter, Austin and Hager, Gregory D
Lea, Colin and Flynn, Michael D. and Vidal, René and Reiter, Austin and Hager, Gregory D. , booktitle=. Temporal Convolutional Networks for Action Segmentation and Detection , year=
-
[24]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces , author=. 2024 , eprint=
work page 2024
-
[27]
Proceedings of the 38th International Conference on Machine Learning , pages =
Attention is not all you need: pure attention loses rank doubly exponentially with depth , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , editor =
work page 2021
-
[29]
Lempitsky, Victor and Vedaldi, Andrea and Ulyanov, Dmitry , booktitle=. Deep Image Prior , year=
-
[30]
and De Vos, Maarten , journal=
Phan, Huy and Andreotti, Fernando and Cooray, Navin and Chén, Oliver Y. and De Vos, Maarten , journal=. SeqSleepNet: End-to-End Hierarchical Recurrent Neural Network for Sequence-to-Sequence Automatic Sleep Staging , year=
-
[31]
Eldele, Emadeldeen and Chen, Zhenghua and Liu, Chengyu and Wu, Min and Kwoh, Chee-Keong and Li, Xiaoli and Guan, Cuntai , journal=. An Attention-Based Deep Learning Approach for Sleep Stage Classification With Single-Channel EEG , year=
- [33]
-
[35]
Pradeepkumar, Jathurshan and Anandakumar, Mithunjha and Kugathasan, Vinith and Suntharalingham, Dhinesh and Kappel, Simon L. and De Silva, Anjula C. and Edussooriya, Chamira U. S. , journal=. Toward Interpretable Sleep Stage Classification Using Cross-Modal Transformers , year=
-
[36]
Ciudad, Javier García and Mørup, Morten and Kornum, Birgitte Rahbek and Zahid, Alexander Neergaard , booktitle=. Evaluating the Influence of Temporal Context on Automatic Mouse Sleep Staging through the Application of Human Models , year=
-
[38]
Biomedical signal processing and control , volume=
Intra-and inter-epoch temporal context network (IITNet) using sub-epoch features for automatic sleep scoring on raw single-channel EEG , author=. Biomedical signal processing and control , volume=. 2020 , publisher=
work page 2020
-
[39]
Coon, William G. and Ogg, Mattson , booktitle=. Laying the Foundation: Modern Transformers for Gold-Standard Sleep Analysis and Beyond , year=
-
[40]
Proceedings of the 21st International Conference on Neural Information Processing Systems , pages =
Rahimi, Ali and Recht, Benjamin , title =. Proceedings of the 21st International Conference on Neural Information Processing Systems , pages =. 2007 , isbn =
work page 2007
-
[41]
Deep Echo State Network (DeepESN): A Brief Survey , author=. 2020 , eprint=
work page 2020
- [42]
-
[43]
Infinite attention: NNGP and NTK for deep attention networks , author=. 2020 , eprint=
work page 2020
-
[44]
Anti-Oversmoothing in Deep Vision Transformers via the Fourier Domain Analysis: From Theory to Practice , author=. 2022 , eprint=
work page 2022
-
[45]
AnySleep: a channel-agnostic deep learning system for high-resolution sleep staging in multi-center cohorts , author=. 2025 , eprint=
work page 2025
-
[48]
Physiological measurement , volume=
Automatic sleep staging of EEG signals: recent development, challenges, and future directions , author=. Physiological measurement , volume=. 2022 , publisher=
work page 2022
-
[49]
Faith S. Luyster, Jr. Strollo, Patrick J., Phyllis C. Zee, and James K. Walsh. Sleep: A health imperative. Sleep, 35 0 (6): 0 727--734, 06 2012. ISSN 0161-8105. doi:10.5665/sleep.1846. URL https://doi.org/10.5665/sleep.1846
-
[50]
Automatic sleep staging of eeg signals: recent development, challenges, and future directions
Huy Phan and Kaare Mikkelsen. Automatic sleep staging of eeg signals: recent development, challenges, and future directions. Physiological measurement, 43 0 (4): 0 04TR01, 2022
work page 2022
-
[51]
Large-scale automated sleep staging
Haoqi Sun, Jian Jia, Balaji Goparaju, Guang-Bin Huang, Olga Sourina, Matt Travis Bianchi, and M Brandon Westover. Large-scale automated sleep staging. Sleep, 40 0 (10): 0 zsx139, 09 2017. ISSN 0161-8105. doi:10.1093/sleep/zsx139. URL https://doi.org/10.1093/sleep/zsx139
-
[52]
Sleep modulation: The challenge of transitioning from open loop to closed loop, 2025
Guisong Liu, Jiansong Zhang, Yinpei Luo, Guoliang Wei, Shuqing Sun, Shiyang Deng, Pengfei Wei, and Nanxi Chen. Sleep modulation: The challenge of transitioning from open loop to closed loop, 2025. URL https://arxiv.org/abs/2512.03784
-
[53]
o fer, Alejandra Alonso, Luciana Besedovsky, Keith Murphy, Emma Peters, Karolina Raczek, Bj\
Elena Krugliakova, Friederike Breuer, Nico Adelh\" o fer, Alejandra Alonso, Luciana Besedovsky, Keith Murphy, Emma Peters, Karolina Raczek, Bj\" o rn Rasch, Leila Salvesen, Sophia Snipes, Sarah Schoch, Thomas Schreiner, Rick Wassing, Til Ole Bergmann, and Martin Dresler. Hacking the functions of sleep: noninvasive approaches to stimulate sleep neurophysio...
-
[54]
Lorenzen, Elisabeth Heremans, Oliver Y
Huy Phan, Kristian P. Lorenzen, Elisabeth Heremans, Oliver Y. Chén, Minh C. Tran, Philipp Koch, Alfred Mertins, Mathias Baumert, Kaare B. Mikkelsen, and Maarten De Vos. L-seqsleepnet: Whole-cycle long sequence modeling for automatic sleep staging. IEEE Journal of Biomedical and Health Informatics, 27 0 (10): 0 4748--4757, 2023. doi:10.1109/JBHI.2023.3303197
-
[55]
H.R. Colten and Bruce Altevogt. Sleep disorders and sleep deprivation: An unmet public health problem. National Academies Press, 10 2006. ISBN 9780309101110. doi:10.17226/11617
-
[56]
Berry, Rita Brooks, Charlene Gamaldo, Susan M
Richard B. Berry, Rita Brooks, Charlene Gamaldo, Susan M. Harding, Robin M. Lloyd, Stuart F. Quan, Matthew T. Troester, and Bradley V. Vaughn. Aasm scoring manual updates for 2017 (version 2.4). Journal of Clinical Sleep Medicine, 13 0 (05): 0 665--666, 2017. doi:10.5664/jcsm.6576. URL https://jcsm.aasm.org/doi/abs/10.5664/jcsm.6576
-
[57]
Lightsleepnet: Design of a personalized portable sleep staging system based on single-channel eeg
Yiqiao Liao, Chao Zhang, Milin Zhang, Zhihua Wang, and Xiang Xie. Lightsleepnet: Design of a personalized portable sleep staging system based on single-channel eeg. IEEE Transactions on Circuits and Systems II: Express Briefs, 69 0 (1): 0 224–228, January 2022. ISSN 1558-3791. doi:10.1109/tcsii.2021.3086981. URL http://dx.doi.org/10.1109/TCSII.2021.3086981
-
[58]
Micro sleepnet: efficient deep learning model for mobile terminal real-time sleep staging
Guisong Liu, Guoliang Wei, Shuqing Sun, Dandan Mao, Jiansong Zhang, Dechun Zhao, Xuelong Tian, Xing Wang, and Nanxi Chen. Micro sleepnet: efficient deep learning model for mobile terminal real-time sleep staging. Frontiers in Neuroscience, Volume 17 - 2023, 2023. ISSN 1662-453X. doi:10.3389/fnins.2023.1218072. URL https://www.frontiersin.org/journals/neur...
-
[59]
Deepsleepnet: A model for automatic sleep stage scoring based on raw single-channel eeg
Akara Supratak, Hao Dong, Chao Wu, and Yike Guo. Deepsleepnet: A model for automatic sleep stage scoring based on raw single-channel eeg. IEEE Transactions on Neural Systems and Rehabilitation Engineering, 25 0 (11): 0 1998--2008, 2017. doi:10.1109/TNSRE.2017.2721116
-
[60]
Alberto Borghese, and Simona Ferrante
Akara Supratak and Yike Guo. Tinysleepnet: An efficient deep learning model for sleep stage scoring based on raw single-channel eeg. In 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC), pages 641--644, 2020. doi:10.1109/EMBC44109.2020.9176741
-
[61]
Multi-view self-supervised learning enhances automatic sleep staging from eeg signals
Tianyou Yu, Xinxin Hu, Yanbin He, Wei Wu, Zhenghui Gu, Zhuliang Yu, Yuanqing Li, Fei Wang, and Jun Xiao. Multi-view self-supervised learning enhances automatic sleep staging from eeg signals. IEEE Transactions on Biomedical Engineering, 72 0 (10): 0 3056--3070, 2025. doi:10.1109/TBME.2025.3561228
-
[62]
Rahul Thapa, Magnus Ruud Kj r, Bryan He, Ian Covert, Hyatt Moore, Umaer Hanif, Gauri Ganjoo, Brandon M Westover, Poul Jennum, Andreas Brink-Kj r, et al. A multimodal sleep foundation model developed with 500k hours of sleep recordings for disease predictions. medRxiv, pages 2025--02, 2025
work page 2025
-
[63]
An attention-based deep learning approach for sleep stage classification with single-channel eeg
Emadeldeen Eldele, Zhenghua Chen, Chengyu Liu, Min Wu, Chee-Keong Kwoh, Xiaoli Li, and Cuntai Guan. An attention-based deep learning approach for sleep stage classification with single-channel eeg. IEEE Transactions on Neural Systems and Rehabilitation Engineering, 29: 0 809--818, 2021. doi:10.1109/TNSRE.2021.3076234
-
[64]
Chén, Philipp Koch, Alfred Mertins, and Maarten De Vos
Huy Phan, Kaare Mikkelsen, Oliver Y. Chén, Philipp Koch, Alfred Mertins, and Maarten De Vos. Sleeptransformer: Automatic sleep staging with interpretability and uncertainty quantification. IEEE Transactions on Biomedical Engineering, 69 0 (8): 0 2456--2467, 2022. doi:10.1109/TBME.2022.3147187
-
[65]
A unified flexible large psg model for sleep staging and brain disorder diagnosis
Guifeng Deng, Mengfan Niu, Shuying Rao, Yuxi Luo, Jianjia Zhang, Junyi Xie, Zhenghe Yu, Wenjuan Liu, Junhang Zhang, Sha Zhao, Gang Pan, Xiaojing Li, Wei Deng, Wanjun Guo, Yaoyun Zhang, Tao Li, and Haiteng Jiang. A unified flexible large psg model for sleep staging and brain disorder diagnosis. medRxiv, 2024. doi:10.1101/2024.12.11.24318815. URL https://ww...
-
[66]
Caresleepnet: A hybrid deep learning network for automatic sleep staging
Jiquan Wang, Sha Zhao, Haiteng Jiang, Yangxuan Zhou, Zhenghe Yu, Tao Li, Shijian Li, and Gang Pan. Caresleepnet: A hybrid deep learning network for automatic sleep staging. IEEE Journal of Biomedical and Health Informatics, 28 0 (12): 0 7392--7405, 2024. doi:10.1109/JBHI.2024.3426939
-
[67]
Sleepdifformer: Sleep stage classification via multivariate differential transformer
Benjamin Wei Hao Chin, Yuin Torng Yew, Haocheng Wu, Lanxin Liang, Chow Khuen Chan, Norita Mohd Zain, Siti Balqis Samdin, and Sim Kuan Goh. Sleepdifformer: Sleep stage classification via multivariate differential transformer. arXiv preprint arXiv:2508.15215, 2025
-
[68]
Yanchen Guo, Maciej Nowakowski, and Weiying Dai. FlexSleepTransformer : a transformer-based sleep staging model with flexible input channel configurations. 14 0 (1): 0 26312, 2024. ISSN 2045-2322. doi:10.1038/s41598-024-76197-0. URL https://doi.org/10.1038/s41598-024-76197-0
-
[69]
Explainable vision transformer for automatic visual sleep staging on multimodal PSG signals
Hyojin Lee, You Rim Choi, Hyun Kyung Lee, Jaemin Jeong, Joopyo Hong, Hyun-Woo Shin, and Hyung-Sin Kim. Explainable vision transformer for automatic visual sleep staging on multimodal PSG signals. 8 0 (1): 0 55, 2025. ISSN 2398-6352. doi:10.1038/s41746-024-01378-0. URL https://doi.org/10.1038/s41746-024-01378-0
-
[70]
William G. Coon and Mattson Ogg. Laying the foundation: Modern transformers for gold-standard sleep analysis and beyond. In 2024 46th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), pages 1--7, 2024. doi:10.1109/EMBC53108.2024.10782964
-
[71]
Javier García Ciudad, Morten Mørup, Birgitte Rahbek Kornum, and Alexander Neergaard Zahid. Evaluating the influence of temporal context on automatic mouse sleep staging through the application of human models. In 2024 46th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), pages 1--4, 2024. doi:10.1109/EMBC5310...
-
[72]
Jathurshan Pradeepkumar, Mithunjha Anandakumar, Vinith Kugathasan, Dhinesh Suntharalingham, Simon L. Kappel, Anjula C. De Silva, and Chamira U. S. Edussooriya. Toward interpretable sleep stage classification using cross-modal transformers. IEEE Transactions on Neural Systems and Rehabilitation Engineering, 32: 0 2893--2904, 2024. doi:10.1109/TNSRE.2024.3438610
-
[73]
Gomez, ukasz Kaiser, and Illia Polosukhin
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS'17, page 6000–6010, Red Hook, NY, USA, 2017. Curran Associates Inc. ISBN 9781510860964
work page 2017
-
[74]
Huy Phan, Fernando Andreotti, Navin Cooray, Oliver Y. Chén, and Maarten De Vos. Seqsleepnet: End-to-end hierarchical recurrent neural network for sequence-to-sequence automatic sleep staging. IEEE Transactions on Neural Systems and Rehabilitation Engineering, 27 0 (3): 0 400--410, 2019. doi:10.1109/TNSRE.2019.2896659
-
[75]
Reservoir computing approaches to recurrent neural network training
Mantas Lukoševičius and Herbert Jaeger. Reservoir computing approaches to recurrent neural network training. 3 0 (3): 0 127--149. ISSN 1574-0137. doi:https://doi.org/10.1016/j.cosrev.2009.03.005. URL https://www.sciencedirect.com/science/article/pii/S1574013709000173
-
[76]
Hogeon Seo, Seunghyeok Back, Seongju Lee, Deokhwan Park, Tae Kim, and Kyoobin Lee. Intra-and inter-epoch temporal context network (iitnet) using sub-epoch features for automatic sleep scoring on raw single-channel eeg. Biomedical signal processing and control, 61: 0 102037, 2020
work page 2020
-
[77]
Random features for large-scale kernel machines
Ali Rahimi and Benjamin Recht. Random features for large-scale kernel machines. In Proceedings of the 21st International Conference on Neural Information Processing Systems, NIPS'07, page 1177–1184, Red Hook, NY, USA, 2007. Curran Associates Inc. ISBN 9781605603520
work page 2007
-
[78]
Deep echo state network (deepesn): A brief survey, 2020
Claudio Gallicchio and Alessio Micheli. Deep echo state network (deepesn): A brief survey, 2020. URL https://arxiv.org/abs/1712.04323
-
[79]
Victor Lempitsky, Andrea Vedaldi, and Dmitry Ulyanov. Deep image prior. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9446--9454, 2018. doi:10.1109/CVPR.2018.00984
-
[80]
Rethinking Attention with Performers
Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamas Sarlos, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, et al. Rethinking attention with performers. arXiv preprint arXiv:2009.14794, 2020
work page internal anchor Pith review arXiv 2009
-
[81]
Random feature attention.arXiv preprint arXiv:2103.02143,
Hao Peng, Nikolaos Pappas, Dani Yogatama, Roy Schwartz, Noah A. Smith, and Lingpeng Kong. Random feature attention, 2021. URL https://arxiv.org/abs/2103.02143
-
[82]
Yao-Hung Hubert Tsai, Shaojie Bai, Makoto Yamada, Louis-Philippe Morency, and Ruslan Salakhutdinov. Transformer dissection: An unified understanding for transformer ' s attention via the lens of kernel. In Kentaro Inui, Jing Jiang, Vincent Ng, and Xiaojun Wan, editors, Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing ...
-
[83]
arXiv preprint arXiv:2202.06709 , year=
Namuk Park and Songkuk Kim. How do vision transformers work?, 2022. URL https://arxiv.org/abs/2202.06709
-
[84]
Peihao Wang, Wenqing Zheng, Tianlong Chen, and Zhangyang Wang. Anti-oversmoothing in deep vision transformers via the fourier domain analysis: From theory to practice, 2022. URL https://arxiv.org/abs/2203.05962
-
[85]
Neural tangent kernel: convergence and generalization in neural networks (invited paper)
Arthur Jacot, Franck Gabriel, and Cl\' e ment Hongler. Neural tangent kernel: convergence and generalization in neural networks (invited paper). In Proceedings of the 53rd Annual ACM SIGACT Symposium on Theory of Computing, STOC 2021, page 6, New York, NY, USA, 2021. Association for Computing Machinery. ISBN 9781450380539. doi:10.1145/3406325.3465355. URL...
-
[86]
Infinite attention: Nngp and ntk for deep attention networks, 2020
Jiri Hron, Yasaman Bahri, Jascha Sohl-Dickstein, and Roman Novak. Infinite attention: Nngp and ntk for deep attention networks, 2020. URL https://arxiv.org/abs/2006.10540
-
[87]
Ary L. Goldberger, Luis A. N. Amaral, Leon Glass, Jeffrey M. Hausdorff, Plamen Ch. Ivanov, Roger G. Mark, Joseph E. Mietus, George B. Moody, Chung-Kang Peng, and H. Eugene Stanley. Physiobank, physiotoolkit, and physionet. Circulation, 101 0 (23): 0 e215--e220, 2000. doi:10.1161/01.CIR.101.23.e215. URL https://www.ahajournals.org/doi/abs/10.1161/01.CIR.10...
-
[88]
Stuart F. Quan, Barbara V. Howard, Conrad Iber, James P. Kiley, F. Javier Nieto, George T. O'Connor, David M. Rapoport, Susan Redline, John Robbins, Jonathan M. Samet, and ‡Patricia W. Wahl. The sleep heart health study: Design, rationale, and methods. Sleep, 20 0 (12): 0 1077--1085, 12 1997. ISSN 0161-8105. doi:10.1093/sleep/20.12.1077. URL https://doi.o...
-
[89]
ibot: Image bert pre-training with online tokenizer
Jinghao Zhou, Chen Wei, Huiyu Wang, Wei Shen, Cihang Xie, Alan Yuille, and Tao Kong. ibot: Image bert pre-training with online tokenizer. International Conference on Learning Representations (ICLR), 2022
work page 2022
-
[90]
Neural Computation 9(8), 1735–1780 (1997)
Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory. Neural Computation, 9 0 (8): 0 1735--1780, 1997. doi:10.1162/neco.1997.9.8.1735
-
[91]
Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling
Junyoung Chung, Caglar Gulcehre, KyungHyun Cho, and Yoshua Bengio. Empirical evaluation of gated recurrent neural networks on sequence modeling, 2014. URL https://arxiv.org/abs/1412.3555
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[92]
Flynn, René Vidal, Austin Reiter, and Gregory D
Colin Lea, Michael D. Flynn, René Vidal, Austin Reiter, and Gregory D. Hager. Temporal convolutional networks for action segmentation and detection. In 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1003--1012, 2017. doi:10.1109/CVPR.2017.113
-
[93]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces, 2024. URL https://arxiv.org/abs/2312.00752
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[94]
Niklas Grieger, Jannik Raskob, Siamak Mehrkanoon, and Stephan Bialonski. Anysleep: a channel-agnostic deep learning system for high-resolution sleep staging in multi-center cohorts, 2025. URL https://arxiv.org/abs/2512.14461
-
[95]
Pedro Fonseca, Niek den Teuling, Xi Long, and Ronald M. Aarts. Cardiorespiratory sleep stage detection using conditional random fields. IEEE Journal of Biomedical and Health Informatics, 21 0 (4): 0 956--966, 2017. doi:10.1109/JBHI.2016.2550104
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.