Recognition: 2 theorem links
· Lean TheoremMicroWorld: Empowering Multimodal Large Language Models to Bridge the Microscopic Domain Gap with Multimodal Attribute Graph
Pith reviewed 2026-05-12 03:03 UTC · model grok-4.3
The pith
MicroWorld builds a 111K-node graph from image captions to boost MLLM performance on microscope reasoning tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
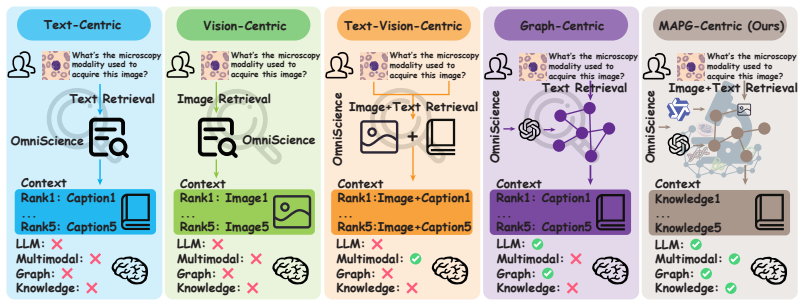
By assembling a knowledge graph of approximately 111K nodes and 346K typed edges from image-caption corpora and injecting retrieved graph context into MLLM prompts at inference, MicroWorld bridges the domain gap for microscopic reasoning, achieving state-of-the-art results on specialized benchmarks without any domain-specific fine-tuning.
What carries the argument
The multimodal attributed property graph (MAPG), which encodes entities, relations, and image-entity alignments extracted via scispaCy or LLM-based mining and aligned using Qwen3-VL-Embedding, serving as a structured knowledge base for retrieval-augmented generation.
If this is right
- MLLMs can achieve significant gains on domain-specific scientific tasks by leveraging external structured knowledge at inference time.
- The method generalizes across different MLLM architectures, as shown by consistent improvements.
- Large-scale scientific corpora can be transformed into usable knowledge graphs for prompt augmentation.
- Qualitative analysis reveals mechanisms and failure modes that inform better knowledge injection strategies.
Where Pith is reading between the lines
- This method could extend to other data-scarce scientific domains like astronomy or materials science if similar image-caption corpora exist.
- Improving the accuracy of entity extraction and alignment in the MAPG construction would likely amplify the performance gains.
- Integrating this graph retrieval with other techniques like chain-of-thought prompting might compound the benefits.
Load-bearing premise
The extracted entities, relations, and image-entity alignments in the MAPG are sufficiently accurate and relevant that their injection into prompts reliably improves reasoning rather than introducing noise or incorrect facts.
What would settle it
Running the MicroWorld retrieval on the MicroVQA benchmark and observing no improvement or a decrease in performance for the base Qwen3-VL-8B-Instruct model, or finding that a large portion of the graph's triplets contain factual errors upon manual verification.
Figures













read the original abstract
Multimodal large language models (MLLMs) show remarkable potential for scientific reasoning, yet their performance in specialized domains such as microscopy remains limited by the scarcity of domain-specific training data and the difficulty of encoding fine-grained expert knowledge into model parameters. To bridge the gap, we introduce MicroWorld, a framework that constructs a multimodal attributed property graph (MAPG) from large-scale scientific image--caption corpora and leverages it to augment MLLM reasoning at inference time without any domain-specific fine-tuning. MicroWorld extracts biomedical entities and relations via scispaCy or LLM-based triplet mining, aligns images and entities in a shared embedding space using Qwen3-VL-Embedding, and assembles a knowledge graph comprising approximately 111K nodes and 346K typed edges spanning eight relation categories. At inference time, a graph-augmented retrieval pipeline matches query entities to the MAPG and injects structured knowledge context into the MLLM prompt. On the MicroVQA benchmark, MicroWorld improves the reasoning performance of Qwen3-VL-8B-Instruct by 37.5%, outperforming GPT-5 by 13.0% to achieve a new state-of-the-art. Furthermore, it yields a 6.0% performance gain on the MicroBench benchmark. Extensive experiments demonstrate the enhanced generalization capability introduced by MicroWorld. A qualitative case study further reveals both the mechanisms through which structured knowledge improves reasoning and the failure modes that point to promising future directions. Code and data are available at https://github.com/ieellee/MicroWorld.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MicroWorld, a framework that constructs a Multimodal Attributed Property Graph (MAPG) with approximately 111K nodes and 346K typed edges from large-scale scientific image-caption corpora. Entities and relations are extracted via scispaCy or LLM-based triplet mining, images and entities are aligned using Qwen3-VL-Embedding, and at inference time a graph-augmented retrieval pipeline injects structured knowledge into MLLM prompts without any domain-specific fine-tuning. The central claims are a 37.5% improvement in reasoning performance of Qwen3-VL-8B-Instruct on the MicroVQA benchmark (outperforming GPT-5 by 13% for a new SOTA) and a 6.0% gain on MicroBench, supported by qualitative case studies on mechanisms and failure modes.
Significance. If the reported gains hold under rigorous controls, the work would be significant for demonstrating a scalable, training-free approach to bridging domain gaps in MLLMs for microscopy and other specialized scientific fields via structured multimodal knowledge injection. The release of code and data at the provided GitHub link is a clear strength that supports reproducibility and community follow-up.
major comments (2)
- [Method] The MAPG construction (described in the method) reports no precision, recall, human validation, or error analysis for entity/relation extraction accuracy or image-entity alignments. This is load-bearing for the central claim, as the 37.5% MicroVQA and 6% MicroBench gains rest on the assumption that injected knowledge is reliable rather than noisy or spurious.
- [Experiments] The experimental results provide no details on baseline prompt formulations, statistical significance testing, or controls for prompt length and retrieval quality when reporting the 37.5% gain on MicroVQA (Qwen3-VL-8B-Instruct) and 6% on MicroBench. Without these, the attribution of improvements specifically to MAPG augmentation cannot be evaluated.
minor comments (1)
- [Abstract] The abstract mentions eight relation categories but does not enumerate them or provide examples; adding this would improve clarity of the MAPG structure.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas where additional rigor will strengthen the manuscript. We address each major comment below and commit to revisions that directly respond to the concerns while preserving the core contributions.
read point-by-point responses
-
Referee: [Method] The MAPG construction (described in the method) reports no precision, recall, human validation, or error analysis for entity/relation extraction accuracy or image-entity alignments. This is load-bearing for the central claim, as the 37.5% MicroVQA and 6% MicroBench gains rest on the assumption that injected knowledge is reliable rather than noisy or spurious.
Authors: We agree that direct validation metrics for the MAPG construction are important for substantiating the reliability of the injected knowledge. The manuscript currently relies on downstream task improvements as indirect evidence. In the revised version, we will add a dedicated error analysis subsection in Section 3, reporting precision and recall for entity/relation extraction on a randomly sampled set of 1,000 triplets annotated by domain experts, as well as alignment accuracy for image-entity pairs on a held-out set of 500 examples. We will also discuss observed error types and their potential impact on retrieval. revision: yes
-
Referee: [Experiments] The experimental results provide no details on baseline prompt formulations, statistical significance testing, or controls for prompt length and retrieval quality when reporting the 37.5% gain on MicroVQA (Qwen3-VL-8B-Instruct) and 6% on MicroBench. Without these, the attribution of improvements specifically to MAPG augmentation cannot be evaluated.
Authors: We appreciate this observation. The baselines used the standard zero-shot prompts from the Qwen3-VL-8B-Instruct model card. To strengthen the experimental section, the revision will include: (i) the exact baseline and augmented prompt templates in Appendix B, (ii) statistical significance via paired t-tests and standard deviations computed over five retrieval seeds, (iii) prompt-length controls by padding baseline prompts with neutral text to match token counts, and (iv) an ablation comparing MAPG retrieval against random retrieval and no-retrieval conditions. These additions will appear in Section 4 and the appendix. revision: yes
Circularity Check
No circularity: empirical pipeline with external corpus construction
full rationale
The paper presents an empirical framework that constructs a MAPG from large-scale image-caption corpora via scispaCy/LLM triplet extraction, Qwen3-VL embedding alignment, and retrieval-time prompt injection. No mathematical derivations, equations, or fitted parameters are described that reduce to their own inputs by construction. Performance gains on MicroVQA and MicroBench are measured against external benchmarks rather than being tautological. No self-citation load-bearing uniqueness theorems or ansatz smuggling appear in the provided text. The method is self-contained as a data-driven augmentation technique whose validity rests on the (unvalidated in the excerpt) accuracy of the extracted graph, not on definitional circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Entities and relations extracted by scispaCy or LLM-based mining faithfully capture expert biomedical knowledge from captions.
- domain assumption Qwen3-VL-Embedding produces alignments between images and entities that are useful for downstream retrieval.
invented entities (1)
-
Multimodal Attributed Property Graph (MAPG)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
constructs a multimodal attributed property graph (MAPG) ... 111K nodes and 346K typed edges ... graph-augmented retrieval pipeline matches query entities to the MAPG and injects structured knowledge context
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
On the MicroVQA benchmark, MicroWorld improves ... by 37.5%
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Scaling deep learning for materials discovery.Nature, 624(7990):80–85, 2023
Amil Merchant, Simon Batzner, Samuel S Schoenholz, Muratahan Aykol, Gowoon Cheon, and Ekin Dogus Cubuk. Scaling deep learning for materials discovery.Nature, 624(7990):80–85, 2023
work page 2023
-
[2]
Equivariant diffusion for molecule generation in 3d
Emiel Hoogeboom, Vıctor Garcia Satorras, Clément Vignac, and Max Welling. Equivariant diffusion for molecule generation in 3d. InInternational conference on machine learning, pages 8867–8887. PMLR, 2022
work page 2022
-
[3]
scgpt: toward building a foundation model for single-cell multi-omics using generative ai
Haotian Cui, Chloe Wang, Hassaan Maan, Kuan Pang, Fengning Luo, Nan Duan, and Bo Wang. scgpt: toward building a foundation model for single-cell multi-omics using generative ai. Nature methods, 21(8):1470–1480, 2024
work page 2024
-
[4]
Josh Abramson, Jonas Adler, Jack Dunger, Richard Evans, Tim Green, Alexander Pritzel, Olaf Ronneberger, Lindsay Willmore, Andrew J Ballard, Joshua Bambrick, et al. Accurate structure prediction of biomolecular interactions with alphafold 3.Nature, 630(8016):493–500, 2024
work page 2024
-
[5]
Highly accurate protein structure prediction with alphafold.nature, 596(7873):583–589, 2021
John Jumper, Richard Evans, Alexander Pritzel, Tim Green, Michael Figurnov, Olaf Ron- neberger, Kathryn Tunyasuvunakool, Russ Bates, Augustin Žídek, Anna Potapenko, et al. Highly accurate protein structure prediction with alphafold.nature, 596(7873):583–589, 2021
work page 2021
-
[6]
Pranav Rajpurkar, Emma Chen, Oishi Banerjee, and Eric J Topol. Ai in health and medicine. Nature medicine, 28(1):31–38, 2022
work page 2022
-
[7]
Martin Weigert, Uwe Schmidt, Tobias Boothe, Andreas Müller, Alexandr Dibrov, Akanksha Jain, Benjamin Wilhelm, Deborah Schmidt, Coleman Broaddus, Siân Culley, et al. Content- aware image restoration: pushing the limits of fluorescence microscopy.Nature methods, 15(12):1090–1097, 2018
work page 2018
-
[8]
Wei Ouyang, Andrey Aristov, Mickaël Lelek, Xian Hao, and Christophe Zimmer. Deep learning massively accelerates super-resolution localization microscopy.Nature biotechnology, 36(5):460–468, 2018
work page 2018
-
[9]
Autonomous chemical research with large language models.Nature, 624(7992):570–578, 2023
Daniil A Boiko, Robert MacKnight, Ben Kline, and Gabe Gomes. Autonomous chemical research with large language models.Nature, 624(7992):570–578, 2023
work page 2023
-
[10]
Nathan J Szymanski, Bernardus Rendy, Yuxing Fei, Rishi E Kumar, Tanjin He, David Milsted, Matthew J McDermott, Max Gallant, Ekin Dogus Cubuk, Amil Merchant, et al. An autonomous laboratory for the accelerated synthesis of inorganic materials.Nature, 624(7990):86, 2023
work page 2023
-
[11]
Chunyuan Li, Cliff Wong, Sheng Zhang, Naoto Usuyama, Haotian Liu, Jianwei Yang, Tristan Naumann, Hoifung Poon, and Jianfeng Gao. Llava-med: Training a large language-and-vision assistant for biomedicine in one day.Advances in Neural Information Processing Systems, 36:28541–28564, 2023
work page 2023
-
[12]
Multimodal large language models for bioimage analysis.nature methods, 21(8):1390–1393, 2024
Shanghang Zhang, Gaole Dai, Tiejun Huang, and Jianxu Chen. Multimodal large language models for bioimage analysis.nature methods, 21(8):1390–1393, 2024
work page 2024
-
[13]
arXiv preprint arXiv:2309.10105 , year=
Suhas Kotha, Jacob Mitchell Springer, and Aditi Raghunathan. Understanding catastrophic forgetting in language models via implicit inference.arXiv preprint arXiv:2309.10105, 2023
-
[14]
Yun Luo, Zhen Yang, Fandong Meng, Yafu Li, Jie Zhou, and Yue Zhang. An empirical study of catastrophic forgetting in large language models during continual fine-tuning.IEEE Transactions on Audio, Speech and Language Processing, 2025. 10
work page 2025
-
[15]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks.Advances in neural information processing systems, 33:9459–9474, 2020
work page 2020
-
[16]
Yue Yu, Wei Ping, Zihan Liu, Boxin Wang, Jiaxuan You, Chao Zhang, Mohammad Shoeybi, and Bryan Catanzaro. Rankrag: Unifying context ranking with retrieval-augmented generation in llms.Advances in Neural Information Processing Systems, 37:121156–121184, 2024
work page 2024
-
[17]
Almanac—retrieval- augmented language models for clinical medicine.Nejm ai, 1(2):AIoa2300068, 2024
Cyril Zakka, Rohan Shad, Akash Chaurasia, Alex R Dalal, Jennifer L Kim, Michael Moor, Robyn Fong, Curran Phillips, Kevin Alexander, Euan Ashley, et al. Almanac—retrieval- augmented language models for clinical medicine.Nejm ai, 1(2):AIoa2300068, 2024
work page 2024
-
[18]
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
Qizheng Zhang, Changran Hu, Shubhangi Upasani, Boyuan Ma, Fenglu Hong, Vamsidhar Ka- manuru, Jay Rainton, Chen Wu, Mengmeng Ji, Hanchen Li, et al. Agentic context engineering: Evolving contexts for self-improving language models.arXiv preprint arXiv:2510.04618, 2025
work page internal anchor Pith review arXiv 2025
-
[19]
Retrieval-Augmented Generation for Large Language Models: A Survey
Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinliu Pan, Yuxi Bi, Yixin Dai, Jiawei Sun, Haofen Wang, Haofen Wang, et al. Retrieval-augmented generation for large language models: A survey.arXiv preprint arXiv:2312.10997, 2(1):32, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Haoyi Tao, Chaozheng Huang, Nan Wang, Han Lyu, Linfeng Zhang, Guolin Ke, and Xi Fang. Omniscience: A large-scale multi-modal dataset for scientific image understanding.arXiv preprint arXiv:2602.13758, 2026
-
[21]
Alejandro Lozano, Jeffrey Nirschl, James Burgess, Sanket R Gupte, Yuhui Zhang, Alyssa Unell, and Serena Yeung-Levy. Micro-bench: A microscopy benchmark for vision-language understanding.Advances in Neural Information Processing Systems, 37:30670–30685, 2024
work page 2024
-
[22]
Microvqa: A multimodal reasoning benchmark for microscopy-based scientific research
James Burgess, Jeffrey J Nirschl, Laura Bravo-Sánchez, Alejandro Lozano, Sanket Rajan Gupte, Jesus G Galaz-Montoya, Yuhui Zhang, Yuchang Su, Disha Bhowmik, Zachary Coman, et al. Microvqa: A multimodal reasoning benchmark for microscopy-based scientific research. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19...
work page 2025
-
[23]
Weizhe Lin, Jinghong Chen, Jingbiao Mei, Alexandru Coca, and Bill Byrne. Fine-grained late- interaction multi-modal retrieval for retrieval augmented visual question answering.Advances in Neural Information Processing Systems, 36:22820–22840, 2023
work page 2023
-
[24]
Visrag: Vision-based retrieval-augmented generation on multi-modality documents
Shi Yu, Chaoyue Tang, Bokai Xu, Junbo Cui, Junhao Ran, Yukun Yan, Zhenghao Liu, Shuo Wang, Xu Han, Zhiyuan Liu, et al. Visrag: Vision-based retrieval-augmented generation on multi-modality documents.arXiv preprint arXiv:2410.10594, 2024
-
[25]
ColPali: Efficient Document Retrieval with Vision Language Models
Manuel Faysse, Hugues Sibille, Tony Wu, Bilel Omrani, Gautier Viaud, Céline Hudelot, and Pierre Colombo. Colpali: Efficient document retrieval with vision language models.arXiv preprint arXiv:2407.01449, 2024
work page internal anchor Pith review arXiv 2024
-
[26]
Ziniu Hu, Ahmet Iscen, Chen Sun, Zirui Wang, Kai-Wei Chang, Yizhou Sun, Cordelia Schmid, David A Ross, and Alireza Fathi. Reveal: Retrieval-augmented visual-language pre-training with multi-source multimodal knowledge memory. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 23369–23379, 2023
work page 2023
-
[27]
AHM Rezaul Karim and Ozlem Uzuner. Masonnlp at mediqa-wv 2025: Multimodal retrieval- augmented generation with large language models for medical vqa. InProceedings of the 7th Clinical Natural Language Processing Workshop, pages 84–94, 2025
work page 2025
-
[28]
Peng Xia, Kangyu Zhu, Haoran Li, Tianze Wang, Weijia Shi, Sheng Wang, Linjun Zhang, James Zou, and Huaxiu Yao. Mmed-rag: Versatile multimodal rag system for medical vision language models.arXiv preprint arXiv:2410.13085, 2024
-
[29]
Yinan Wu, Yuming Lu, Yan Zhou, Yifan Ding, Jingping Liu, and Tong Ruan. Mkgf: A multi- modal knowledge graph based rag framework to enhance lvlms for medical visual question answering.Neurocomputing, 635:129999, 2025. 11
work page 2025
-
[30]
arXiv preprint arXiv:2602.06965 (2026)
Ankan Deria, Komal Kumar, Adinath Madhavrao Dukre, Eran Segal, Salman Khan, and Imran Razzak. Medmo: Grounding and understanding multimodal large language model for medical images.arXiv preprint arXiv:2602.06965, 2026
-
[31]
Sanghyun Woo, Dahun Kim, Donghyeon Cho, and In So Kweon. Linknet: Relational embedding for scene graph.Advances in neural information processing systems, 31, 2018
work page 2018
-
[32]
Michelle M Li, Kexin Huang, and Marinka Zitnik. Graph representation learning in biomedicine and healthcare.Nature biomedical engineering, 6(12):1353–1369, 2022
work page 2022
-
[33]
Belinda Mo, Kyssen Yu, Joshua Kazdan, Joan Cabezas, Proud Mpala, Lisa Yu, Chris Cundy, Charilaos Kanatsoulis, and Sanmi Koyejo. Kggen: Extracting knowledge graphs from plain text with language models.arXiv preprint arXiv:2502.09956, 2025
-
[34]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. From local to global: A graph rag approach to query-focused summarization.arXiv preprint arXiv:2404.16130, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[35]
LightRAG: Simple and Fast Retrieval-Augmented Generation
Zirui Guo, Lianghao Xia, Yanhua Yu, Tian Ao, and Chao Huang. Lightrag: Simple and fast retrieval-augmented generation.arXiv preprint arXiv:2410.05779, 2(3), 2024
work page internal anchor Pith review arXiv 2024
-
[36]
Scispacy: fast and robust models for biomedical natural language processing
Mark Neumann, Daniel King, Iz Beltagy, and Waleed Ammar. Scispacy: fast and robust models for biomedical natural language processing. InProceedings of the 18th BioNLP workshop and shared task, pages 319–327, 2019
work page 2019
-
[37]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
Mingxin Li, Yanzhao Zhang, Dingkun Long, Keqin Chen, Sibo Song, Shuai Bai, Zhibo Yang, Pengjun Xie, An Yang, Dayiheng Liu, et al. Qwen3-vl-embedding and qwen3-vl-reranker: A unified framework for state-of-the-art multimodal retrieval and ranking.arXiv preprint arXiv:2601.04720, 2026
work page internal anchor Pith review arXiv 2026
-
[39]
Eric W Sayers, Jeffrey Beck, Evan E Bolton, Devon Bourexis, James R Brister, Kathi Canese, Donald C Comeau, Kathryn Funk, Sunghwan Kim, William Klimke, et al. Database resources of the national center for biotechnology information.Nucleic acids research, 49(D1):D10–D17, 2021
work page 2021
-
[40]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[42]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, et al. Openai o1 system card.arXiv preprint arXiv:2412.16720, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [43]
-
[44]
Openai o3 and o4-mini system card, 2025
OpenAI. Openai o3 and o4-mini system card, 2025
work page 2025
-
[45]
spacy: Industrial- strength natural language processing in python
Matthew Honnibal, Ines Montani, Sofie Van Landeghem, Adriane Boyd, et al. spacy: Industrial- strength natural language processing in python. 2020
work page 2020
-
[46]
Using of jaccard coefficient for keywords similarity
Suphakit Niwattanakul, Jatsada Singthongchai, Ekkachai Naenudorn, and Supachanun Wanapu. Using of jaccard coefficient for keywords similarity. InProceedings of the international multiconference of engineers and computer scientists, volume 1, pages 380–384, 2013
work page 2013
-
[47]
John W. Ratcliff and David Metzener. Pattern matching: The gestalt approach.Dr. Dobb’s Journal, page 46, 1988. 12
work page 1988
-
[48]
A statistical interpretation of term specificity and its application in retrieval
Karen Sparck Jones. A statistical interpretation of term specificity and its application in retrieval. Journal of documentation, 28(1):11–21, 1972
work page 1972
-
[49]
George Kingsley Zipf.The psycho-biology of language: An introduction to dynamic philology. Routledge, 2013
work page 2013
-
[50]
George Kingsley Zipf.Human behavior and the principle of least effort: An introduction to human ecology. Ravenio books, 2016. 13 A Ethics Ethical Use of Biomedical Data.Our work utilizes data sampled from the OmniScience dataset. OmniScience aggregates biomedical images and associated textual captions extracted from open- access scientific literature. All...
work page 2016
-
[51]
To enhance the secretion of lysosomal enzymes
-
[52]
To assemble multi-organellar units that aid in adapting to foreign pathogens; ✅
-
[53]
To increase the fusion rate with phagosomes; ❌
-
[54]
To initiate apoptotic signaling pathways Figure 5:Upgrade Case 1(Hypothesis Generation):Misconception correction.Question: After macrophage exposure to heat-killedS. aureus, lysosomes exhibit ring-like arrangements. What is the underlying cause?Baselineselects Option 3 (increased phagosome fusion rate) ✗;KC-augmented selects Option 2 (assembly of multi-or...
-
[55]
Dye Specks; ✅ Figure 6:Upgrade Case 2(Perception):Terminology disambiguation.Question: In a Pap-smear bright-field image, which artifact is primarily caused by staining and introduces visual noise?Baseline selects Option 1 (Stain Aggregates) ✗;KC-augmentedselects Option 5 (Dye Specks) ✓. The KG provides:“Dye specks are non-biological particles generated d...
-
[56]
Employ low-dose imaging protocols to reduce sample alterations; ❌
-
[57]
Refine contrast enhancement methods to improve visibility of details
-
[58]
Optimize sample growth conditions prior to cryoEM analysis
-
[59]
Adjust image processing algorithms to standardize outputs
-
[60]
Implement enhanced purification steps to maintain sample integrity; ✅ Figure 7:Upgrade Case 3(Experiment Proposal):Domain-specific knowledge injection.Question: Unexpected asymmetry observed in cryo-EM of Chikungunya virus (CHIKV), which strategy best determines whether this is an artifact?Baselineselects Option 1 (low-dose imaging to reduce radiation dam...
-
[61]
Virus surface proteins undergo structural changes upon antibody exposure, potentially affecting symmetries.; ❌
-
[62]
Traditional detection methods may inaccurately portray viruses due to inherent technical constraints
-
[63]
The geometric integrity of alphaviruses such as chikungunya could be more adaptable than initially thought.; ✅
-
[64]
Data interpretation techniques might compromise reliability when assessing certain antibody responses
-
[65]
The standard cryoEM technique might occasionally overestimate viral structural variations.; Figure 8:Upgrade Case 4(Perception):Reasoning level elevation.Question: After neutralizing antibody treatment, CHIKV loses icosahedral symmetry. What does this imply?Baselineselects Option 1 (surface protein conformational changes affect symmetry) ✗;KC-augmentedsel...
-
[66]
Increased cortical actin due to external stimuli promoting cell surface reorganization;✅
-
[67]
Localized actin adaptations for efficient internal nutrient transport
-
[68]
Redistribution of actin to conserve energy resources under stress; ❌
-
[69]
Enhanced actin dynamics to maintain structural equilibrium on the cell perimeter
-
[70]
Reinforced actin positioning to support intracellular signaling pathways targeting organelles", Figure 9:Upgrade Case 5(Hypothesis Generation):Logical chain correction.Question: In mtDNA- deficient cells, actin concentrates at the cell periphery. What is the most likely cause?Baselineselects Option 3 (actin redistribution to conserve energy)✗;KC-augmented...
-
[71]
not confined to discrete structures
Chromatin aggregates ❌ Figure 10:Downgrade Case 1(Perception):Knowledge overriding visual evidence.Question: Identify the subcellular localization of green puncta within MCF-7 cell nuclei.Baselinecorrectly selects Option 1 (Nucleoli) ✓, based on direct visual assessment of bright, discrete intranuclear foci consistent with nucleolar morphology.KC-augmente...
-
[72]
Colocalization indicates enhanced wound closure through potentially novel biochemical interactions.; ✅
-
[73]
The overlapping signals are likely due to misalignment of imaging channels, without biological value
-
[74]
The presence of these biomarkers could represent cross-reactivity, complicating precise labeling.; ❌
-
[75]
This pattern suggests a misinterpretation, potentially leading to incorrect assumptions in data analysis
-
[76]
Detection of Ly6G signal in platelets should raise concern for antibody cross-reactivity
There is a heightened immune response involving CD41 elements, triggering migratory behavior. Questions: In images of hepatic tissue obtained via fluorescence microscopy, we observe colocalization of magenta-marked CD41 elements and yellow-labeled Ly6G structures at the boundary of tissue repair. Without the specific visual information, what might this co...
-
[77]
Antibody cross-reactivity causing Ly6G binding to unwanted targets; ✅
-
[78]
Internal synthesis of Ly6G in platelets under certain stimuli
-
[79]
Platelets engulfing neutrophil byproducts causing Ly6G presence; ❌
-
[80]
Technical imaging errors leading to misinterpretation
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.