Recognition: 2 theorem links
· Lean TheoremMTA-RL: Robust Urban Driving via Multi-modal Transformer-based 3D Affordances and Reinforcement Learning
Pith reviewed 2026-05-12 03:24 UTC · model grok-4.3
The pith
Fusing RGB and LiDAR through a transformer to predict explicit 3D affordances gives an RL policy a stable observation space that generalizes to unseen towns.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
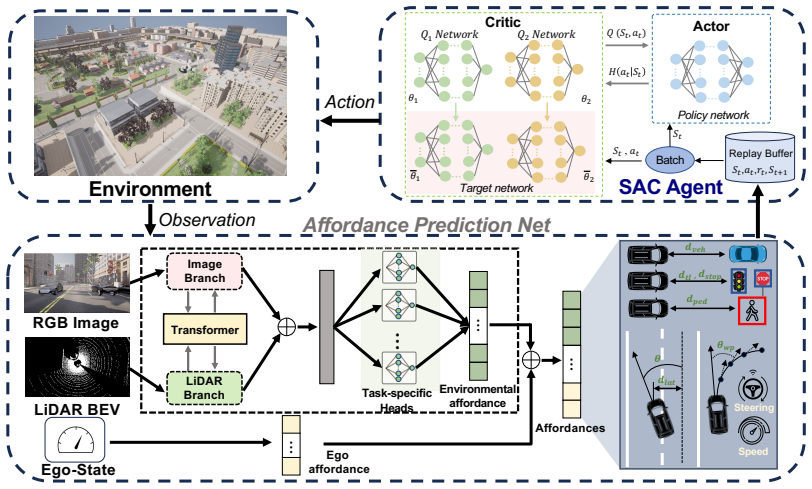
MTA-RL fuses RGB images and LiDAR point clouds in a transformer to generate explicit, geometry-aware 3D affordance representations; these structured outputs become the sole observation for an RL policy that learns driving behavior through shaped rewards, yielding policies that complete routes more reliably and violate fewer rules even in towns never seen during training.
What carries the argument
Multi-modal transformer that predicts 3D affordances: explicit geometry-aware representations of driving-relevant scene elements generated from fused RGB and point-cloud inputs and used directly as the low-dimensional observation for the RL policy.
If this is right
- The RL policy trains more efficiently and stably because it receives only compact semantic affordances rather than raw high-dimensional sensor data.
- Zero-shot transfer improves, delivering up to 9 percent higher route completion, 11 percent greater total distance, and 83.7 percent better distance per violation in unseen towns.
- Both multi-modal fusion and reward shaping are necessary; removing either one reduces performance below the full model.
- The gains hold across the full tested range of 20 to 60 background vehicles.
Where Pith is reading between the lines
- Affordance outputs could be inspected or edited independently of the driving policy, potentially simplifying safety audits.
- The same representations might serve as input to planning or imitation-learning methods that do not use reinforcement learning.
- Reducing the observation space to predicted affordances may lower the amount of real-world fine-tuning needed when moving from simulation to physical vehicles.
Load-bearing premise
The transformer-predicted 3D affordances must stay accurate and complete enough under changing traffic densities that the RL policy never encounters unrecoverable perception errors.
What would settle it
Performance metrics such as route completion and distance per violation falling below baseline levels when the same policy is tested in a town with traffic density outside the 20-60 vehicle range used in training or when affordance predictions are deliberately corrupted.
Figures

read the original abstract
Robust urban autonomous driving requires reliable 3D scene understanding and stable decision-making under dense interactions. However, existing end-to-end models lack interpretability, while modular pipelines suffer from error propagation across brittle interfaces. This paper proposes MTA-RL, the first framework that bridges perception and control through Multi-modal Transformer-based 3D Affordances and Reinforcement Learning (RL). Unlike previous fusion models that directly regress actions, RGB images and LiDAR point clouds are fused using a transformer architecture to predict explicit, geometry-aware affordance representations. These structured representations serve as a compact observation space, enabling the RL policy to operate purely on predicted driving semantics, which significantly improves sample efficiency and stability. Extensive evaluations in CARLA Town01-03 across varying densities (20-60 background vehicles) show that MTA-RL consistently outperforms state-of-the-art baselines. Trained solely on Town03, our method demonstrates superior zero-shot generalization in unseen towns, achieving up to a 9.0% increase in Route Completion, an 11.0% increase in Total Distance, and an 83.7% improvement in Distance Per Violation. Furthermore, ablation studies confirm that our multi-modal fusion and reward shaping are critical, significantly outperforming image-only and unshaped variants, demonstrating the effectiveness of MTA-RL for robust urban autonomous driving.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MTA-RL, a framework that fuses RGB images and LiDAR point clouds via a multi-modal transformer to predict explicit 3D affordance representations (e.g., drivable surfaces and obstacles), which then serve as the low-dimensional observation space for an RL policy trained for urban driving in CARLA. It reports consistent outperformance over baselines in Towns 01-03 under varying traffic densities (20-60 vehicles) and, when trained only on Town03, zero-shot generalization to unseen towns with gains of up to 9.0% in Route Completion, 11.0% in Total Distance, and 83.7% in Distance Per Violation. Ablations are presented to highlight the roles of multi-modal fusion and reward shaping.
Significance. If the central claims hold, the work offers a promising bridge between interpretable perception and stable control by replacing direct action regression with structured affordance inputs to RL, which could improve sample efficiency and robustness in dense urban scenarios. The inclusion of ablations demonstrating the necessity of multi-modal fusion and reward shaping, along with evaluations across traffic densities, strengthens the contribution by isolating key design choices.
major comments (3)
- [Abstract] Abstract: The zero-shot generalization claims (9.0% Route Completion, 11.0% Total Distance, 83.7% Distance Per Violation) rest on the assumption that transformer-predicted 3D affordances remain accurate and complete on unseen towns, yet no affordance prediction accuracy, precision-recall, or error metrics are reported for Town01/Town02; without this, it is impossible to determine whether performance gains arise from reliable observations or from policy robustness to perception errors.
- [Abstract] Abstract and evaluation results: The reported quantitative gains lack accompanying details on exact baseline implementations, number of independent evaluation runs, error bars, or statistical significance tests (e.g., t-tests or Wilcoxon), which are required to substantiate that MTA-RL 'consistently outperforms' the baselines rather than reflecting run-to-run variance.
- [Abstract] Abstract: The RL policy is described as operating 'purely on predicted driving semantics,' but no analysis is provided on how affordance prediction errors under novel map geometries (different intersections, curvatures) propagate into policy actions; this is load-bearing for the generalization result given that the observation space is entirely affordance-based.
minor comments (1)
- [Abstract] The abstract mentions 'CARLA Town01-03' but does not specify the CARLA version or simulator settings (e.g., weather, sensor noise models), which would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thorough review and valuable suggestions. We address each of the major comments below, providing clarifications and indicating where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The zero-shot generalization claims (9.0% Route Completion, 11.0% Total Distance, 83.7% Distance Per Violation) rest on the assumption that transformer-predicted 3D affordances remain accurate and complete on unseen towns, yet no affordance prediction accuracy, precision-recall, or error metrics are reported for Town01/Town02; without this, it is impossible to determine whether performance gains arise from reliable observations or from policy robustness to perception errors.
Authors: We agree that including affordance prediction metrics on the unseen towns (Town01 and Town02) would help isolate the contributions of perception accuracy versus policy robustness. Although the manuscript emphasizes end-to-end driving performance, we will add quantitative affordance evaluation results, such as mean IoU for drivable surfaces and obstacle detection precision-recall curves, evaluated on the zero-shot towns in the revised manuscript. This will provide direct evidence supporting the reliability of the predicted affordances. revision: yes
-
Referee: [Abstract] Abstract and evaluation results: The reported quantitative gains lack accompanying details on exact baseline implementations, number of independent evaluation runs, error bars, or statistical significance tests (e.g., t-tests or Wilcoxon), which are required to substantiate that MTA-RL 'consistently outperforms' the baselines rather than reflecting run-to-run variance.
Authors: We acknowledge the need for greater transparency in the experimental protocol to support the performance claims. The original submission includes descriptions of the baselines and evaluation protocol in Section 4, but we will revise to explicitly detail: the exact baseline implementations and code references, the use of 5 independent random seeds for all methods, inclusion of standard deviation error bars in all reported tables and figures, and the application of paired t-tests to confirm statistical significance of the improvements (with p-values reported). These changes will be made in the updated evaluation section. revision: yes
-
Referee: [Abstract] Abstract: The RL policy is described as operating 'purely on predicted driving semantics,' but no analysis is provided on how affordance prediction errors under novel map geometries (different intersections, curvatures) propagate into policy actions; this is load-bearing for the generalization result given that the observation space is entirely affordance-based.
Authors: This point highlights an important aspect for validating the generalization claims. While a comprehensive error propagation study (e.g., via controlled perturbation of affordance inputs) is not present in the current work, the design of the RL policy with multi-modal affordances and shaped rewards is intended to promote robustness to perception inaccuracies. The ablation results showing degradation without multi-modal fusion indirectly support this. We will add a discussion paragraph in the revised manuscript analyzing potential error sources in novel geometries and how the policy mitigates them, based on observed failure cases. A full quantitative propagation analysis would require substantial additional experiments and is noted as future work. revision: partial
Circularity Check
No significant circularity in derivation or claims
full rationale
The paper presents an empirical framework combining a multi-modal transformer for 3D affordance prediction with RL policy training in CARLA. All load-bearing claims (zero-shot generalization, performance gains) rest on simulator rollouts, ablation studies, and comparisons to external baselines rather than any self-referential fitting, self-citation chain, or definitional equivalence. No equations or sections reduce predictions to inputs by construction; affordance learning and policy optimization are standard supervised + RL pipelines whose outputs are validated externally on held-out towns and densities.
Axiom & Free-Parameter Ledger
free parameters (1)
- reward shaping weights
axioms (1)
- domain assumption Predicted 3D affordances provide a sufficient and geometry-aware state representation for stable RL policy learning
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearRGB images and LiDAR point clouds are fused using a transformer architecture to predict explicit, geometry-aware affordance representations. These structured representations serve as a compact observation space, enabling the RL policy to operate purely on predicted driving semantics
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclearR(t) = R_lane(t) + R_speed(t) + R_smooth(t) + R_prog(t) + R_rule(t) + R_event(t)
Reference graph
Works this paper leans on
-
[1]
Recent advances in reinforcement learning-based autonomous driving behav- ior planning: A survey,
J. Wu, C. Huang, H. Huang, C. Lv, Y . Wang, and F.-Y . Wang, “Recent advances in reinforcement learning-based autonomous driving behav- ior planning: A survey,”Transportation Research Part C: Emerging Technologies, vol. 164, p. 104654, 2024
work page 2024
-
[2]
End-to-end deep reinforcement learning for lane keeping assist,
A. E. Sallab, M. Abdou, E. Perot, and S. Yogamani, “End-to-end deep reinforcement learning for lane keeping assist,”arXiv preprint arXiv:1612.04340, 2016
-
[3]
L. Yan, X. Wu, C. Wei, and S. Zhao, “Human-vehicle shared steering control for obstacle avoidance: A reference-free approach with rein- forcement learning,”IEEE Transactions on Intelligent Transportation Systems, vol. 25, no. 11, pp. 17 888–17 901, 2024
work page 2024
-
[4]
M. Zhou, Y . Yu, and X. Qu, “Development of an efficient driving strat- egy for connected and automated vehicles at signalized intersections: A reinforcement learning approach,”IEEE Transactions on Intelligent Transportation Systems, vol. 21, no. 1, pp. 433–443, 2019
work page 2019
-
[5]
Z. Li, J. Gong, Z. Zhang, C. Lu, V . L. Knoop, and M. Wang, “Interactive behavior modeling for vulnerable road users with risk- taking styles in urban scenarios: A heterogeneous graph learning approach,”IEEE Transactions on Intelligent Transportation Systems, vol. 25, no. 8, pp. 8538–8555, 2024
work page 2024
-
[6]
Ethics-aware safe reinforcement learning for rare-event risk control in interactive urban driving,
D. Li and O. Okhrin, “Ethics-aware safe reinforcement learning for rare-event risk control in interactive urban driving,”arXiv preprint arXiv:2508.14926, 2025
-
[7]
Autonomous driving system: A comprehensive survey,
J. Zhao, W. Zhao, B. Deng, Z. Wang, F. Zhang, W. Zheng, W. Cao, J. Nan, Y . Lian, and A. F. Burke, “Autonomous driving system: A comprehensive survey,”Expert Systems with Applications, vol. 242, p. 122836, 2024
work page 2024
-
[8]
Au- tonomous vehicle perception: The technology of today and tomorrow,
J. Van Brummelen, M. O’brien, D. Gruyer, and H. Najjaran, “Au- tonomous vehicle perception: The technology of today and tomorrow,” Transportation research part C: emerging technologies, vol. 89, pp. 384–406, 2018
work page 2018
-
[9]
Autonomous driving small- scale cars: A survey of recent development,
D. Li, P. Auerbach, and O. Okhrin, “Autonomous driving small- scale cars: A survey of recent development,”IEEE Transactions on Intelligent Transportation Systems, vol. 26, no. 10, pp. 14 591–14 614, 2025
work page 2025
-
[10]
Concrete problems for autonomous vehicle safety: Advantages of bayesian deep learning,
R. McAllister, Y . Gal, A. Kendall, M. van der Wilk, A. Shah, R. Cipolla, and A. Weller, “Concrete problems for autonomous vehicle safety: Advantages of bayesian deep learning,” inProceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI-17, 2017, pp. 4745–4753
work page 2017
-
[11]
A survey of end-to-end driving: Architectures and training methods,
A. Tampuu, T. Matiisen, M. Semikin, D. Fishman, and N. Muhammad, “A survey of end-to-end driving: Architectures and training methods,” IEEE Transactions on Neural Networks and Learning Systems, vol. 33, no. 4, pp. 1364–1384, 2022
work page 2022
-
[12]
End-to-end autonomous driving: Challenges and frontiers,
L. Chen, P. Wu, K. Chitta, B. Jaeger, A. Geiger, and H. Li, “End-to-end autonomous driving: Challenges and frontiers,”IEEE Trans. Pattern Anal. Mach. Intell., vol. 46, no. 12, p. 10164–10183, Dec. 2024
work page 2024
-
[13]
A survey on imitation learning techniques for end-to-end autonomous vehicles,
L. Le Mero, D. Yi, M. Dianati, and A. Mouzakitis, “A survey on imitation learning techniques for end-to-end autonomous vehicles,” IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 9, pp. 14 128–14 147, 2022
work page 2022
-
[14]
R. S. Sutton, A. G. Bartoet al.,Reinforcement learning: An introduc- tion. MIT press Cambridge, 1998, vol. 1, no. 1
work page 1998
-
[15]
Deepdriving: Learning affordance for direct perception in autonomous driving,
C. Chen, A. Seff, A. Kornhauser, and J. Xiao, “Deepdriving: Learning affordance for direct perception in autonomous driving,” in2015 IEEE International Conference on Computer Vision (ICCV), 2015, pp. 2722– 2730
work page 2015
-
[16]
Conditional affordance learning for driving in urban environments,
A. Sauer, N. Savinov, and A. Geiger, “Conditional affordance learning for driving in urban environments,” inConference on robot learning. PMLR, 2018, pp. 237–252
work page 2018
-
[17]
M. Ahmed, A. Abobakr, C. P. Lim, and S. Nahavandi, “Policy-based reinforcement learning for training autonomous driving agents in urban areas with affordance learning,”IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 8, pp. 12 562–12 571, 2021
work page 2021
-
[18]
Pointpainting: Sequential fusion for 3d object detection,
S. V ora, A. H. Lang, B. Helou, and O. Beijbom, “Pointpainting: Sequential fusion for 3d object detection,”2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 4603–4611, 2019
work page 2020
-
[19]
Deep continuous fusion for multi-sensor 3d object detection,
M. Liang, B. Yang, S. Wang, and R. Urtasun, “Deep continuous fusion for multi-sensor 3d object detection,” inProceedings of the European Conference on Computer Vision (ECCV), 2018, pp. 641–656
work page 2018
-
[20]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017
work page 2017
-
[21]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby, “An image is worth 16x16 words: Transformers for image recognition at scale,”ICLR, 2021
work page 2021
-
[22]
End-to-end autonomous driving with semantic depth cloud mapping and multi-agent,
O. Natan and J. Miura, “End-to-end autonomous driving with semantic depth cloud mapping and multi-agent,”IEEE Transactions on Intelli- gent Vehicles, vol. 8, no. 1, pp. 557–571, 2022
work page 2022
-
[23]
End-to-end multi-modal sensors fusion system for urban automated driving,
I. Sobh, L. Amin, S. Abdelkarim, K. Elmadawy, M. Saeed, O. Ab- deltawab, M. Gamal, and A. El Sallab, “End-to-end multi-modal sensors fusion system for urban automated driving,” inNeurIPS 2018 Workshop on Machine Learning for Intelligent Transportation Systems (MLITS), 2018
work page 2018
-
[24]
End-to-end model-free reinforcement learning for urban driving using implicit affordances,
M. Toromanoff, E. Wirbel, and F. Moutarde, “End-to-end model-free reinforcement learning for urban driving using implicit affordances,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 7153–7162
work page 2020
-
[25]
End-to-end interpretable neural motion planner,
W. Zeng, W. Luo, S. Suo, A. Sadat, B. Yang, S. Casas, and R. Urtasun, “End-to-end interpretable neural motion planner,”2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pp. 8652–8661, 2019
work page 2019
-
[26]
Multimodal end-to-end autonomous driving,
Y . Xiao, F. Codevilla, A. Gurram, O. Urfalioglu, and A. M. L ´opez, “Multimodal end-to-end autonomous driving,”Trans. Intell. Transport. Sys., vol. 23, no. 1, p. 537–547, Jan. 2022
work page 2022
-
[27]
Transfuser: Imitation with transformer-based sensor fusion for au- tonomous driving,
K. Chitta, A. Prakash, B. Jaeger, Z. Yu, K. Renz, and A. Geiger, “Transfuser: Imitation with transformer-based sensor fusion for au- tonomous driving,”IEEE transactions on pattern analysis and machine intelligence, vol. 45, no. 11, pp. 12 878–12 895, 2022
work page 2022
-
[28]
Exploring the limitations of behavior cloning for autonomous driving,
F. Codevilla, E. Santana, A. Lopez, and A. Gaidon, “Exploring the limitations of behavior cloning for autonomous driving,” inProceed- ings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2019, pp. 9328–9337
work page 2019
-
[29]
Deep reinforcement learning for autonomous driving: A survey,
B. R. Kiran, I. Sobh, V . Talpaert, P. Mannion, A. A. A. Sallab, S. Yo- gamani, and P. P ´erez, “Deep reinforcement learning for autonomous driving: A survey,”IEEE Transactions on Intelligent Transportation Systems, vol. 23, no. 6, pp. 4909–4926, 2022
work page 2022
-
[30]
S. Yang, L. Wang, Y . Huang, and H. Chen, “A safe and efficient self- evolving algorithm for decision-making and control of autonomous driving systems,”IEEE Transactions on Intelligent Transportation Systems, vol. 26, no. 8, pp. 11 466–11 478, 2025
work page 2025
-
[31]
Soft actor- critic algorithms and applications,
T. Haarnoja, A. Zhou, K. Hartikainen, G. Tucker, S. Ha, J. Tan, V . Kumar, H. Zhu, A. Gupta, P. Abbeel, and S. Levine, “Soft actor- critic algorithms and applications,” 2019
work page 2019
-
[32]
End-to- end urban driving by imitating a reinforcement learning coach,
Z. Zhang, A. Liniger, D. Dai, F. Yu, and L. Van Gool, “End-to- end urban driving by imitating a reinforcement learning coach,” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2021
work page 2021
-
[33]
Q. Li, X. Jia, S. Wang, and J. Yan, “Think2drive: Efficient reinforce- ment learning by thinking in latent world model for quasi-realistic autonomous driving (in carla-v2),”arXiv preprint arXiv:2402.16720, 2024
-
[34]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,”2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 770–778, 2015
work page 2016
-
[35]
CARLA: An open urban driving simulator,
A. Dosovitskiy, G. Ros, F. Codevilla, A. Lopez, and V . Koltun, “CARLA: An open urban driving simulator,” inProceedings of the 1st Annual Conference on Robot Learning, 2017, pp. 1–16
work page 2017
-
[36]
Stable-baselines3: Reliable reinforcement learning im- plementations,
A. Raffin, A. Hill, A. Gleave, A. Kanervisto, M. Ernestus, and N. Dormann, “Stable-baselines3: Reliable reinforcement learning im- plementations,”Journal of Machine Learning Research, vol. 22, no. 268, pp. 1–8, 2021
work page 2021
-
[37]
Z. Huang, Z. Sheng, Y . Qu, J. You, and S. Chen, “Vlm-rl: A unified vision language models and reinforcement learning framework for safe autonomous driving,”Transportation Research Part C: Emerging Technologies, vol. 180, p. 105321, 2025
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.