Recognition: 2 theorem links
· Lean TheoremWhat Concepts Lie Within? Detecting and Suppressing Risky Content in Diffusion Transformers
Pith reviewed 2026-05-12 04:32 UTC · model grok-4.3
The pith
Attention heads in diffusion transformers show concept-specific sensitivity that lets risky content be detected and suppressed at inference time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that attention heads in Diffusion Transformers exhibit concept-specific sensitivity. This property is formalized by representing each textual token as an Attention Head Vector (AHV) that records its sensitivity profile across all heads. During inference a momentum-based tracker maintains token-wise AHVs over denoising steps, and a sensitivity-guided adaptive suppression step lowers the attention weights of tokens whose AHVs match risky concepts, all without model updates.
What carries the argument
The Attention Head Vector (AHV), a per-token sensitivity profile across attention heads that serves as a discriminative signature for detecting and suppressing risky generation tendencies.
If this is right
- Sexual, violent, and copyright-protected content can be suppressed inside state-of-the-art DiT models at inference time without retraining.
- The same head-sensitivity mechanism transfers across different DiT-based text-to-image architectures.
- Robustness to adversarial prompts is achieved by dynamic momentum tracking of AHVs rather than static thresholds.
- Image quality remains intact because suppression is applied only to identified risky attention weights in a head-specific manner.
Where Pith is reading between the lines
- The same sensitivity-tracking idea could be tested on other transformer-based generative models such as video or audio diffusion transformers.
- If AHV signatures prove stable, they might support broader concept-level editing operations beyond safety filtering.
- Model developers could embed AHV monitoring as a lightweight default safeguard in future DiT releases.
Load-bearing premise
The sensitivity patterns that mark risky concepts stay stable enough across prompts and models to allow reliable detection and suppression without creating false positives or degrading image quality.
What would settle it
An experiment that finds a set of adversarial prompts whose risky tokens produce AHVs indistinguishable from safe tokens, or that shows clear drops in visual fidelity when suppression is applied to safe prompts, would falsify the claim.
Figures












read the original abstract
The rise of text-to-image (T2I) models has increasingly raised concerns regarding the generation of risky content, such as sexual, violent, and copyright-protected images, highlighting the need for effective safeguards within the models themselves. Although existing methods have been proposed to eliminate risky concepts from T2I models, they are primarily developed for earlier U-Net architectures, leaving the state-of-the-art Diffusion-Transformer-based T2I models inadequately protected. This gap stems from a fundamental architectural shift: Diffusion Transformers (DiTs) entangle semantic injection and visual synthesis via joint attention, which makes it difficult to isolate and erase risky content within the generation. To bridge this gap, we investigate how semantic concepts are represented in DiTs and discover that attention heads exhibit concept-specific sensitivity. This property enables both the detection and suppression of risky content. Building on this discovery, we propose AHV-D\&S, a training-free inference-time safeguard for image generation in DiTs. Specifically, AHV-D\&S quantifies each textual token's sensitivity across all attention heads as an Attention Head Vector (AHV), which serves as a discriminative signature for detecting risky generation tendencies. In the inference stage, we propose a momentum-based strategy to dynamically track token-wise AHVs across denoising steps, and a sensitivity-guided adaptive suppression strategy that suppresses the attention weights of identified risky tokens based on head-specific risk scores. Extensive experiments demonstrate that AHV-D\&S effectively suppresses sexual, copyrighted-style, and various harmful content while preserving visual quality, and further exhibits strong robustness against adversarial prompts and transferability across different DiT-based T2I models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that attention heads in Diffusion Transformers exhibit concept-specific sensitivity, enabling the definition of Attention Head Vectors (AHVs) as token-wise signatures for risky content detection. Building on this, it introduces the training-free AHV-D&S method, which uses momentum-based tracking of AHVs across denoising steps and sensitivity-guided adaptive suppression of attention weights for risky tokens. Extensive experiments are reported to show effective suppression of sexual, violent, and copyrighted content while preserving image quality, plus robustness to adversarial prompts and transferability across DiT models.
Significance. If the core empirical discovery and method hold under broader conditions, this would represent a meaningful advance in inference-time safety for state-of-the-art DiT-based text-to-image models, addressing the architectural gap versus prior U-Net-focused approaches and offering a practical, training-free intervention with potential for broader use in controlling generative outputs.
major comments (2)
- [Abstract / Experiments] The central claim depends on AHV signatures being sufficiently invariant to prompt phrasing and denoising timestep. The abstract and described experiments use fixed prompt sets without reported tests for early timesteps (near-noise inputs), where semantic sensitivity may be weak or shifted; this directly risks unreliable detection or unintended suppression and must be addressed with targeted ablation or cross-timestep analysis.
- [Method description] The momentum-based tracking and head-specific risk scores are load-bearing for the suppression strategy, yet the abstract provides no quantitative details on how AHV is computed (e.g., exact aggregation across heads or normalization), making it impossible to verify whether the approach is truly parameter-free or how it avoids degrading non-risky content.
minor comments (2)
- [Abstract] The acronym AHV-D&S is used before its expansion; a brief parenthetical definition on first use would improve readability.
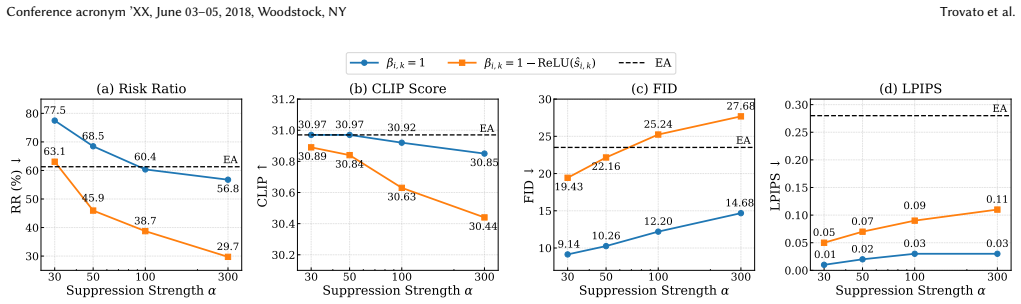
- [Figures/Tables] Figure or table captions should explicitly state the metrics used for 'preserving visual quality' (e.g., FID, CLIP score) to allow direct comparison with baselines.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive feedback. We address each major comment below with clarifications from the manuscript and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract / Experiments] The central claim depends on AHV signatures being sufficiently invariant to prompt phrasing and denoising timestep. The abstract and described experiments use fixed prompt sets without reported tests for early timesteps (near-noise inputs), where semantic sensitivity may be weak or shifted; this directly risks unreliable detection or unintended suppression and must be addressed with targeted ablation or cross-timestep analysis.
Authors: We appreciate this observation on the importance of timestep invariance for reliable detection. The manuscript reports robustness experiments across diverse prompts and applies the full AHV-D&S pipeline throughout the denoising trajectory, with momentum tracking intended to stabilize signatures. However, we did not include a dedicated cross-timestep ablation isolating early timesteps. We will add a new analysis subsection with AHV cosine-similarity matrices across timesteps and an ablation measuring detection/suppression accuracy when intervening only at early, middle, or late stages. revision: yes
-
Referee: [Method description] The momentum-based tracking and head-specific risk scores are load-bearing for the suppression strategy, yet the abstract provides no quantitative details on how AHV is computed (e.g., exact aggregation across heads or normalization), making it impossible to verify whether the approach is truly parameter-free or how it avoids degrading non-risky content.
Authors: We agree the abstract is too concise on these mechanics. Section 3.2 defines AHV as the per-token vector of attention weights across heads, aggregated by mean and L2-normalized; the risk score is the dot product against a fixed concept vector derived from a small set of reference prompts; suppression is applied adaptively per head using a sensitivity-derived threshold. Momentum is a simple exponential moving average (decay 0.9) with no learned parameters. We have expanded the abstract with a single sentence summarizing AHV construction and the adaptive suppression rule to improve verifiability while preserving the training-free claim. revision: partial
Circularity Check
No circularity: empirical discovery of attention-head sensitivity is independent of AHV-D&S construction
full rationale
The paper's central claim is an empirical observation that attention heads in DiTs exhibit concept-specific sensitivity, discovered via investigation of semantic representations. This observation directly motivates the definition of AHV as a quantification of token-wise sensitivity across heads, followed by momentum tracking and adaptive suppression at inference time. No equations, fitted parameters, or self-citations reduce the discovery or the method to its own inputs by construction; the approach is presented as training-free and validated through experiments on suppression effectiveness. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Attention heads in Diffusion Transformers exhibit concept-specific sensitivity to semantic tokens
invented entities (1)
-
Attention Head Vector (AHV)
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
attention heads exhibit concept-specific sensitivity... quantified... as an Attention Head Vector (AHV)... momentum-based strategy to dynamically track token-wise AHVs across denoising steps, and a sensitivity-guided adaptive suppression strategy
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
t-SNE visualization of AHVs... distinct cluster structures... 98.73% classification accuracy
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Praneeth Bedapudi. 2019. NudeNet: Neural Nets for Nudity Detection and Cen- soring. https://github.com/bedapudi6788/NudeNet. Python package, version 1.1.0
work page 2019
-
[2]
Black Forest Labs. 2025. FLUX.1 [dev] — Model Card. https://huggingface.co/ black-forest-labs/FLUX.1-dev
work page 2025
-
[3]
Huanqia Cai, Sihan Cao, Ruoyi Du, Peng Gao, Steven Hoi, Zhaohui Hou, Shijie Huang, Dengyang Jiang, Xin Jin, Liangchen Li, et al. 2025. Z-image: An efficient image generation foundation model with single-stream diffusion transformer. arXiv preprint arXiv:2511.22699(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Qi Cai, Yehao Li, Yingwei Pan, Ting Yao, and Tao Mei. 2025. HiDream-I1: An Open-Source High-Efficient Image Generative Foundation Model. InProceedings of the 33rd ACM International Conference on Multimedia. 13636–13639
work page 2025
-
[5]
Junsong Chen, Jincheng Yu, Chongjian Ge, Lewei Yao, Enze Xie, Yue Wu, Zhong- dao Wang, James Kwok, Ping Luo, Huchuan Lu, et al. 2023. Pixart-alpha: Fast training of diffusion transformer for photorealistic text-to-image synthesis.arXiv preprint arXiv:2310.00426(2023)
work page internal anchor Pith review arXiv 2023
- [6]
-
[7]
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. 2025. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. 2009. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition. Ieee, 248–255
work page 2009
-
[9]
Prafulla Dhariwal and Alexander Nichol. 2021. Diffusion models beat gans on image synthesis.Advances in neural information processing systems34 (2021), 8780–8794
work page 2021
-
[10]
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. 2024. Scaling rectified flow transformers for high-resolution image synthesis. InForty- first International Conference on Machine Learning
work page 2024
-
[11]
Rohit Gandikota, Joanna Materzynska, Jaden Fiotto-Kaufman, and David Bau
-
[12]
InProceedings of the IEEE/CVF international conference on computer vision
Erasing concepts from diffusion models. InProceedings of the IEEE/CVF international conference on computer vision. 2426–2436
-
[14]
Rohit Gandikota, Hadas Orgad, Yonatan Belinkov, Joanna Materzyńska, and David Bau. 2024. Unified concept editing in diffusion models. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 5111–5120
work page 2024
-
[15]
Daiheng Gao, Shilin Lu, Wenbo Zhou, Jiaming Chu, Jie Zhang, Mengxi Jia, Bang Zhang, Zhaoxin Fan, and Weiming Zhang. 2025. Eraseanything: Enabling concept erasure in rectified flow transformers. InForty-second International Conference on Machine Learning
work page 2025
-
[16]
Chao Gong, Kai Chen, Zhipeng Wei, Jingjing Chen, and Yu-Gang Jiang. 2024. Re- liable and efficient concept erasure of text-to-image diffusion models. InEuropean Conference on Computer Vision. Springer, 73–88
work page 2024
-
[17]
Google. 2026. Gemini. https://gemini.google.com/app. Accessed: 2026-04-29
work page 2026
- [18]
-
[19]
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. 2022. Prompt-to-prompt image editing with cross attention control. arXiv preprint arXiv:2208.01626(2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[20]
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. 2021. Clipscore: A reference-free evaluation metric for image captioning. InProceedings of the 2021 conference on empirical methods in natural language processing. 7514– 7528
work page 2021
-
[21]
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. 2017. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems30 (2017)
work page 2017
-
[22]
Internet Watch Foundation. 2026. Harm without limits: AI child sexual abuse material through the eyes of our Analysts. https://www.iwf.org.uk/about- us/why-we-exist/our-research/how-ai-is-being-abused-to-create-child- sexual-abuse-imagery/. Accessed: 2026-04-18
work page 2026
- [23]
-
[24]
Nupur Kumari, Bingliang Zhang, Sheng-Yu Wang, Eli Shechtman, Richard Zhang, and Jun-Yan Zhu. 2023. Ablating concepts in text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 22691– 22702
work page 2023
- [25]
- [26]
-
[27]
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. 2014. Microsoft coco: Common objects in context. InEuropean conference on computer vision. Springer, 740–755
work page 2014
- [28]
-
[29]
Shilin Lu, Zilan Wang, Leyang Li, Yanzhu Liu, and Adams Wai-Kin Kong. 2024. Mace: Mass concept erasure in diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 6430–6440
work page 2024
-
[30]
Zhengyao Lv, Tianlin Pan, Chenyang Si, Zhaoxi Chen, Wangmeng Zuo, Ziwei Liu, and Kwan-Yee K Wong. 2025. Rethinking cross-modal interaction in multimodal diffusion transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision. 5934–5943
work page 2025
-
[31]
Jungwon Park, Jungmin Ko, Dongnam Byun, Jangwon Suh, and Wonjong Rhee
-
[32]
InThe Thirteenth International Conference on Learning Representations
Cross-Attention Head Position Patterns Can Align with Human Visual Concepts in Text-to-Image Generative Models. InThe Thirteenth International Conference on Learning Representations
- [33]
-
[34]
Peigui Qi, Kunsheng Tang, Wenbo Zhou, Weiming Zhang, Nenghai Yu, Tianwei Zhang, Qing Guo, and Jie Zhang. 2025. SafeGuider: Robust and practical content safety control for text-to-image models. InProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security. 2818–2832
work page 2025
-
[35]
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10684–10695
work page 2022
-
[36]
Patrick Schramowski, Manuel Brack, Björn Deiseroth, and Kristian Kersting
-
[37]
InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Safe latent diffusion: Mitigating inappropriate degeneration in diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 22522–22531
- [38]
-
[39]
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng- ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, et al . 2025. Qwen-image technical report.arXiv preprint arXiv:2508.02324(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [40]
-
[41]
Jinheng Xie, Zhenheng Yang, and Mike Zheng Shou. 2025. Show-o2: Improved native unified multimodal models.arXiv preprint arXiv:2506.15564(2025)
work page internal anchor Pith review arXiv 2025
-
[42]
Fuyi Yang, Chenyu Zhang, and Lanjun Wang. 2025. Culture-based Adversar- ial Attack on Text-to-Image Models. In2025 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 1–6
work page 2025
-
[43]
Yijun Yang, Ruiyuan Gao, Xiaosen Wang, Tsung-Yi Ho, Nan Xu, and Qiang Xu
-
[44]
InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
MMA-Diffusion: MultiModal Attack on Diffusion Models. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)
- [45]
- [46]
-
[47]
Chenyu Zhang, Lanjun Wang, Yiwen Ma, Wenhui Li, Guoqing Jin, and Anan Liu
-
[48]
In Proceedings of the AAAI Conference on Artificial Intelligence, Vol
Reason2attack: Jailbreaking text-to-image models via llm reasoning. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 36030–36038
-
[49]
Chenyu Zhang, Tairen Zhang, Lanjun Wang, Ruidong Chen, Wenhui Li, and Anan Liu. 2026. T2I-RiskyPrompt: A Benchmark for Safety Evaluation, Attack, and Defense on Text-to-Image Model. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 40. 36039–36047
work page 2026
-
[50]
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang
-
[51]
InProceedings of the IEEE conference on computer vision and pattern recognition
The unreasonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition. 586–595
-
[52]
Yimeng Zhang, Jinghan Jia, Xin Chen, Aochuan Chen, Yihua Zhang, Jiancheng Liu, Ke Ding, and Sijia Liu. 2024. To generate or not? safety-driven unlearned diffusion models are still easy to generate unsafe images... for now.European Conference on Computer Vision (ECCV)(2024)
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.