Recognition: no theorem link
LegalCiteBench: Evaluating Citation Reliability in Legal Language Models
Pith reviewed 2026-05-12 03:56 UTC · model grok-4.3
The pith
Legal language models frequently generate incorrect citations when not given external sources.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
In a closed-book setting without external grounding, large language models achieve exact citation recovery scores below 7 out of 100 on retrieval and completion tasks within LegalCiteBench, while exhibiting misleading answer rates above 94 percent for 20 of 21 evaluated models.
What carries the argument
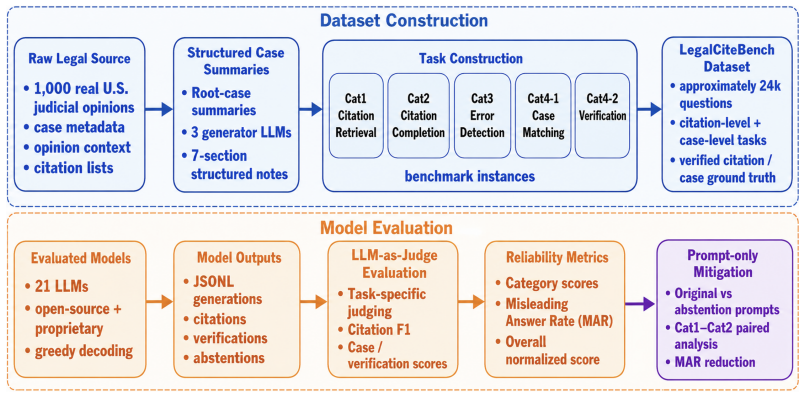
LegalCiteBench, a collection of approximately 24,000 evaluation instances spanning citation retrieval, citation completion, citation error detection, case matching, and case verification and correction, derived from 1,000 real judicial opinions.
If this is right
- Legal drafting and research workflows that use LLMs for citations must incorporate external retrieval or verification to prevent reliance on fabricated authorities.
- Explicit instructions for models to abstain when uncertain reduce some confident errors but leave citation accuracy largely unchanged.
- Neither larger model scale nor legal-domain pretraining resolves the core difficulty of closed-book citation recovery.
- Diagnostic tools focused on authority generation can help identify when models should defer to search systems rather than generate citations.
Where Pith is reading between the lines
- Legal AI systems may need mandatory integration with verified case databases to reach usable reliability levels in practice.
- The pattern of high misleading answer rates could extend to other knowledge-intensive professional domains where precise recall matters.
- Future work could test whether combining LegalCiteBench with retrieval-augmented setups measurably improves outcomes on the same tasks.
Load-bearing premise
The 24,000 instances constructed from 1,000 judicial opinions accurately capture the distribution and ambiguity of real-world legal citation tasks without introducing selection bias or overly simplified matching criteria.
What would settle it
A direct comparison of model scores on LegalCiteBench against performance by practicing lawyers or law students on the identical tasks would show whether the reported failures reflect a genuine gap in model capability.
Figures


read the original abstract
Large language models (LLMs) are increasingly integrated into legal drafting and research workflows, where incorrect citations or fabricated precedents can cause serious professional harm. Existing legal benchmarks largely emphasize statutory reasoning, contract understanding, or general legal question answering, but they do not directly study a central common-law failure mode: when asked to provide case authorities without external grounding, models may return plausible-looking but incorrect citations or cases. We introduce LegalCiteBench, a benchmark for studying closed-book citation recovery, citation verification, and case matching in legal language models. LegalCiteBench contains approximately 24K evaluation instances constructed from 1,000 real U.S. judicial opinions from the Case Law Access Project. The benchmark covers five citation-centric tasks: citation retrieval, citation completion, citation error detection, case matching, and case verification and correction. Across 21 LLMs, exact citation recovery remains highly challenging in this closed-book setting: even the strongest models score below 7/100 on citation retrieval and completion. Within the evaluated models, scale and legal-domain pretraining provide limited gains and do not resolve this difficulty. Models also frequently provide concrete but incorrect or low-overlap authorities under our evaluation protocol, with Misleading Answer Rates (MAR) exceeding 94% for 20 of 21 evaluated models on retrieval-heavy tasks. A prompt-only abstention experiment shows that explicit uncertainty instructions reduce some confident fabrication but do not improve citation correctness. LegalCiteBench is intended as a diagnostic framework for studying authority generation failures, verification behavior, and abstention when external grounding is absent, incomplete, or bypassed.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LegalCiteBench, a benchmark of ~24K instances derived from 1,000 U.S. judicial opinions, to evaluate LLMs on five closed-book citation tasks: retrieval, completion, error detection, case matching, and verification/correction. Evaluation across 21 models shows even the strongest achieve <7/100 on retrieval and completion, with Misleading Answer Rates (MAR) >94% for 20/21 models on retrieval tasks; scale and legal pretraining yield limited gains, and abstention prompts reduce some fabrication but not correctness.
Significance. If the benchmark's construction and matching rules accurately reflect genuine closed-book citation failures rather than artifacts, the results highlight a serious limitation in current LLMs for legal authority generation, with direct implications for professional use where fabricated citations pose harm. The work provides a diagnostic framework that could guide improvements in training, retrieval-augmented generation, and uncertainty handling for legal-domain models.
major comments (2)
- [Benchmark construction] Benchmark construction section: the process for selecting the 1,000 opinions and deriving the 24K instances must specify sampling strategy (e.g., random vs. stratified by jurisdiction, era, or citation density) and how multi-citation or ambiguous opinions are handled, as unrepresentative selection could make the low scores and high MAR reflect benchmark artifacts rather than model limitations.
- [Evaluation protocol] Evaluation protocol and metrics section: the criteria for scoring a citation as 'correct' or 'misleading' (including the overlap threshold for case matching and handling of low-overlap authorities) must explicitly state whether it normalizes for Bluebook variants, parallel citations, reporter differences, case name aliases, or jurisdiction-specific styles; without such normalization, models surfacing valid but non-identical authorities will be penalized, directly undermining the central claim that scores <7/100 and MAR >94% indicate absence of knowledge rather than metric strictness.
minor comments (2)
- [Experimental setup] The prompt templates for each of the five tasks should be provided in an appendix or table to allow exact reproduction of the abstention experiment and other results.
- [Results] Clarify in the results section whether the reported scores are macro-averaged across tasks or weighted, and include per-task breakdowns for all 21 models rather than aggregated MAR figures.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on LegalCiteBench. The comments highlight important areas for improving clarity in benchmark construction and evaluation details. We address each major comment below and will revise the manuscript to add the requested specifications while preserving the core claims and methodology.
read point-by-point responses
-
Referee: [Benchmark construction] Benchmark construction section: the process for selecting the 1,000 opinions and deriving the 24K instances must specify sampling strategy (e.g., random vs. stratified by jurisdiction, era, or citation density) and how multi-citation or ambiguous opinions are handled, as unrepresentative selection could make the low scores and high MAR reflect benchmark artifacts rather than model limitations.
Authors: We agree that explicit details on sampling are needed to demonstrate representativeness. The current manuscript identifies the source corpus but does not elaborate on selection. In the revised version, we will expand the Benchmark Construction section to describe the process: opinions were drawn from the Case Law Access Project to ensure coverage across federal and state jurisdictions and multiple decades, with instances generated by extracting every citation present in each opinion. Multi-citation opinions contributed multiple independent instances, and opinions with incomplete or ambiguous metadata were excluded after initial filtering to maintain data quality. These additions will allow readers to assess whether the low performance reflects model limitations rather than sampling artifacts. revision: yes
-
Referee: [Evaluation protocol] Evaluation protocol and metrics section: the criteria for scoring a citation as 'correct' or 'misleading' (including the overlap threshold for case matching and handling of low-overlap authorities) must explicitly state whether it normalizes for Bluebook variants, parallel citations, reporter differences, case name aliases, or jurisdiction-specific styles; without such normalization, models surfacing valid but non-identical authorities will be penalized, directly undermining the central claim that scores <7/100 and MAR >94% indicate absence of knowledge rather than metric strictness.
Authors: We will revise the Evaluation Protocol and Metrics section to fully specify the scoring rules, including the exact overlap threshold applied for case matching and the treatment of low-overlap outputs as misleading. Our protocol performs direct matching against the precise citation strings and case identifiers appearing in the source opinions and does not apply broad normalization for Bluebook variants, parallel citations, or aliases. This design choice is deliberate: legal practice requires accurate, usable citations, and the benchmark aims to measure whether models can produce them from internal knowledge alone. We will also add a paragraph discussing the implications of this strictness, noting that while some semantically related authorities might be scored as incorrect, the high misleading answer rates still indicate a fundamental limitation in reliable authority generation. This clarification will strengthen rather than undermine the central claims. revision: yes
Circularity Check
No circularity: purely empirical benchmark construction and evaluation
full rationale
The paper constructs LegalCiteBench from 1,000 external judicial opinions in the Case Law Access Project and reports observed performance of 21 LLMs on five citation tasks using metrics such as exact recovery scores and Misleading Answer Rates. No equations, derivations, fitted parameters, predictions, or self-citations appear that reduce any claim to its inputs by construction. All central results are direct empirical measurements against an independently sourced corpus, making the work self-contained without any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 1,000 selected U.S. judicial opinions contain citation patterns that are representative of common-law citation usage.
Reference graph
Works this paper leans on
-
[1]
ACM Transactions on Information Systems , volume=
A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions , author=. ACM Transactions on Information Systems , volume=. 2025 , publisher=
work page 2025
-
[2]
Doubling Down on Dumb: Lessons from Mata v. Avianca Inc. , author=. American Bankruptcy Institute Journal , volume=. 2023 , publisher=
work page 2023
-
[3]
arXiv preprint arXiv:2509.09969 , year=
Large language models meet legal artificial intelligence: A survey , author=. arXiv preprint arXiv:2509.09969 , year=
-
[4]
arXiv preprint arXiv:2103.06268 , year=
Cuad: An expert-annotated nlp dataset for legal contract review , author=. arXiv preprint arXiv:2103.06268 , year=
-
[5]
Advances in neural information processing systems , volume=
Legalbench: A collaboratively built benchmark for measuring legal reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[6]
Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
Lawbench: Benchmarking legal knowledge of large language models , author=. Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
work page 2024
-
[7]
Proceedings of the 31st International conference on computational linguistics , pages=
LAiW: A Chinese legal large language models benchmark , author=. Proceedings of the 31st International conference on computational linguistics , pages=
-
[8]
arXiv preprint arXiv:2505.12864 , year=
Lexam: Benchmarking legal reasoning on 340 law exams , author=. arXiv preprint arXiv:2505.12864 , year=
-
[9]
Advances in Neural Information Processing Systems , volume=
Lexeval: A comprehensive chinese legal benchmark for evaluating large language models , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
arXiv preprint arXiv:2601.16669 , year=
PLawBench: A Rubric-Based Benchmark for Evaluating LLMs in Real-World Legal Practice , author=. arXiv preprint arXiv:2601.16669 , year=
-
[11]
arXiv preprint arXiv:2511.07979 , year=
Benchmarking multi-step legal reasoning and analyzing chain-of-thought effects in large language models , author=. arXiv preprint arXiv:2511.07979 , year=
-
[12]
Lecardv2: A large-scale chinese legal case retrieval dataset , author=. Proceedings of the 47th International ACM SIGIR Conference on Research and Development in Information Retrieval , pages=
-
[13]
Proceedings of the nineteenth international conference on artificial intelligence and law , pages=
Summary of the competition on legal information, extraction/entailment (COLIEE) 2023 , author=. Proceedings of the nineteenth international conference on artificial intelligence and law , pages=
work page 2023
-
[14]
2024 IEEE International Conference on Big Data (BigData) , pages=
Myanmar law cases and proceedings retrieval with graphrag , author=. 2024 IEEE International Conference on Big Data (BigData) , pages=. 2024 , organization=
work page 2024
-
[15]
Information Processing & Management , volume=
Low-resource court judgment summarization for common law systems , author=. Information Processing & Management , volume=. 2024 , publisher=
work page 2024
-
[16]
Proceedings of the AAAI conference on artificial intelligence , volume=
Interpretable long-form legal question answering with retrieval-augmented large language models , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[17]
Computer Science Review , volume=
Large language models hallucination: A comprehensive survey , author=. Computer Science Review , volume=. 2026 , publisher=
work page 2026
-
[18]
arXiv preprint arXiv:2505.11413 , year=
Cares: Comprehensive evaluation of safety and adversarial robustness in medical llms , author=. arXiv preprint arXiv:2505.11413 , year=
-
[19]
Retrieval-Augmented Generation for Large Language Models: A Survey
Retrieval-augmented generation for large language models: A survey , author=. arXiv preprint arXiv:2312.10997 , volume=
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Journal of empirical legal studies , volume=
Hallucination-free? Assessing the reliability of leading AI legal research tools , author=. Journal of empirical legal studies , volume=. 2025 , publisher=
work page 2025
-
[21]
Nguyen, Dong and Le, Thang V. Q. and Nguyen, Nguyen P. and others , booktitle =
-
[22]
Advances in Neural Information Processing Systems , volume=
Saullm-54b & saullm-141b: Scaling up domain adaptation for the legal domain , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
Lin, Stephanie and Hilton, Jacob and Evans, Owain , booktitle =
-
[24]
Li, Junyi and Cheng, Xiaoxue and Zhao, Wayne Xin and Nie, Jian-Yun and Wen, Ji-Rong , booktitle =
-
[25]
Bang, Yejin and others , journal =
-
[26]
Advances in neural information processing systems , volume=
Judging llm-as-a-judge with mt-bench and chatbot arena , author=. Advances in neural information processing systems , volume=
-
[27]
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang , booktitle =
-
[28]
Dubey, Abhimanyu and Jauhri, Abhinav and Pandey, Abhinav and Kadian, Abhishek and others , journal =. The
-
[29]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Mixtral of experts , author=. arXiv preprint arXiv:2401.04088 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Phi-4 technical report , author=. arXiv preprint arXiv:2412.08905 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[33]
Proceedings of the 29th symposium on operating systems principles , pages=
Efficient memory management for large language model serving with pagedattention , author=. Proceedings of the 29th symposium on operating systems principles , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.